







目录
回顾
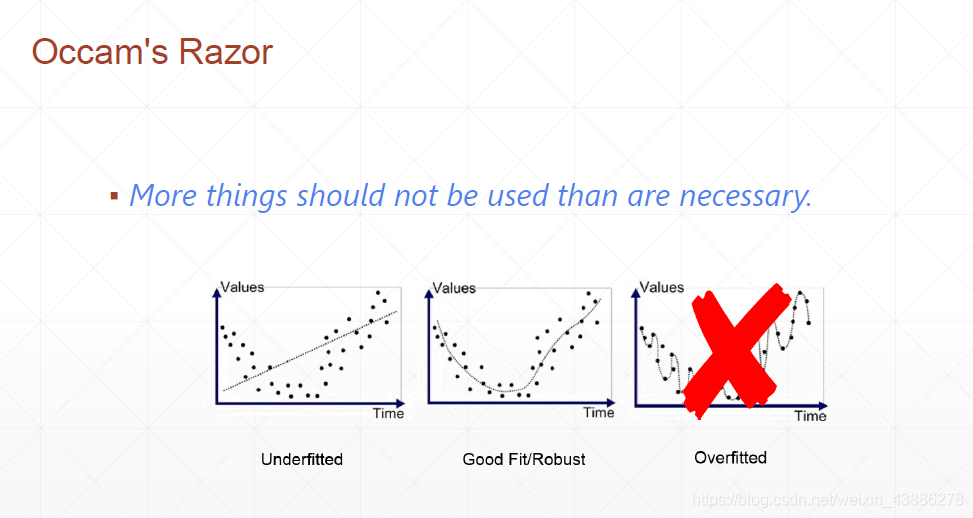
在上一篇博客中我们讲到,当训练模型比真实模型复杂度低的情况叫做underfitting(欠拟合),当训练集模型比真实模型复杂度高的情况叫做overfitting(过拟合)。现如今由于网络层数不断地增加,欠拟合的情况已经较为少见,绝大数多情况都是出现过拟合。与过拟合有一个异曲同工的概念叫做奥卡姆剃刀原理。
奥卡姆剃刀原理是指:在科学研究任务中,应该优先使用较为简单的公式或者原理,而不是复杂的。
应用到深度学习任务中,可以通过减小模型的复杂度来降低过拟合的风险,即模型在能够较好拟合训练集(经验风险)的前提下,尽量减小模型的复杂度(结构风险)。
降低过拟合方法
 1.提供更多数据
1.提供更多数据
2.迫使模型复杂度降低
(1)使用更简单结构的神经网络
(2)正则化惩罚项
3.Dropout
4.数据增强
5.早停法
正则化惩罚项

我们在原有的二分类loss上面加入权重θ的一范数之和。如图所示,这样在进行训练过程中,不断优化loss,会使得去权重尽可能降低,从而减小模型复杂度,降低过拟合的风险。为什么权重降低会减小模型复杂度呢?
考虑到模型可以用x的n次幂之和表示,高次幂x的系数越小,则曲线越平滑,复杂度越低,训练模型过程中为了同时保持accracy高和权重范数低。最后优化的结果应该是x低次幂的系数大而高次幂的系数小,从而在尽量提高模型accuracy的情况下降低了模型复杂度,降低过拟合的风险。
在pytorch中这一概念有时候也叫做weight decay
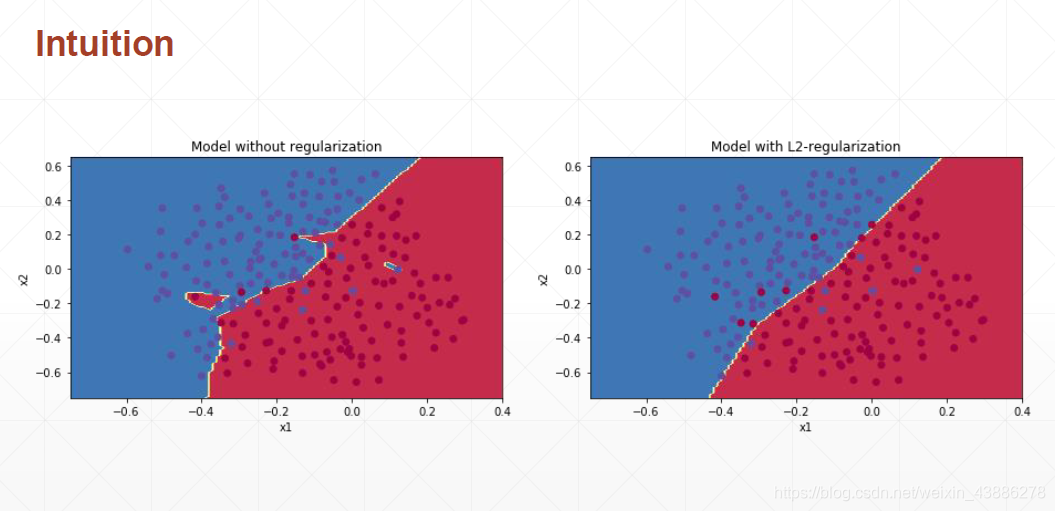
如上图所示,在没有进行正则化的时候,训练出的模型为了将一些噪声数据包含进去变得异常复杂,反而降低了模型的泛化能力。在经过正则化之后,模型变得更加平滑,增加了模型的泛化能力。
常用的正则化公式

一般情况而言使用二范数,也就是公式二用的更多。需要注意的是λ属于超参数

优化器默认使用L2正则,在weight_decay中传入λ
L1正则pytorch中没有实现,需要人为实现














 950
950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









