







文章目录
1. 什么是管道命令
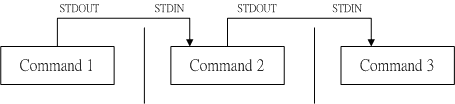
命令A|命令B --> 命令A的输出当做命令B的输入
管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),它表现出来的形式将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。
- 管道命令使用|作为界定符号,管道命令与上面说的连续执行命令不一样。
2.第一个管道命令
$ ls -al /etc | less
通过管道将ls -al的输出作为 下一个命令less的输入,方便浏览。
3. cut
3.1 cut能干什么?
- cut 可以根据条件 从命令结果中提取对应内容
- Linux cut命令用于显示每行从开头算起 num1 到 num2 的文字。
- cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
3.2 实现
3.2.1 截取出1.txt文件中前2行的第5个字符
| 命令 | 含义 |
|---|---|
| cut 动作 文件 | 从指定文件 截取内容 |
- 参数
| 参数 | 英文 | 含义 |
|---|---|---|
| -c | characters | 按字符选取内容 |
head -2 1.txt | cut -c 5
从1.txt文件中截取前两行 | 通过管道符将前一个的输入 转换到后面的输出 cut命令 -c参数按照字符选取内容 选取第五个
3.2.2 截取出1.txt文件中前2行以”:”进行分割的第1,2段内容
| 参数 | 英文 | 含义 |
|---|---|---|
-d '分隔符' | delimiter | 指定分隔符 |
-f n1,n2 | fields | 分割以后显示第几段内容, 使用 , 分割 |
范围控制
| 范围 | 含义 |
|---|---|
n | 只显示第n项 |
n- | 显示 从第n项 一直到行尾 |
n-m | 显示 从第n项 到 第m项(包括m) |
head -2 1.txt | cut -d ':' -f 1,2
head -2 1.txt | cut -d ':' -f 1-2
- 通过
cut 动作 目标文件可以根据条件 提取对应内容
4.sort 排序
4.1 sort可以干嘛?
- sort可针对文本文件的内容,以行为单位来排序。
4.2 举个例子
4.2.1第一步: 对字符串排序
[root@node01 tmp]# cat 2.txt
banana
apple
pear
orange
pear
[root@node01 tmp]# sort 2.txt
apple
banana
orange
pear
pear
4.2.2第二步: 去重排序
| 参数 | 英文 | 含义 |
|---|---|---|
-u | unique | 去掉重复的 |
它的作用很简单,就是在输出行中去除重复行。
[root@node01 tmp]# sort -u 2.txt
apple
banana
orange
pear
4.2.3 第三步: 对数值排序
| 参数 | 英文 | 含义 |
|---|---|---|
-n | numeric-sort | 按照数值大小排序 |
-r | reverse | 使次序颠倒 |
-
准备数据
[root@node01 tmp]# cat 3.txt 1 3 5 7 11 2 4 6 10 8 9 -
默认按照
字符串排序[root@node01 tmp]# sort 2.txt 1 10 11 2 3 4 5 6 7 8 9 -
升序
[root@node01 tmp]# sort -n 2.txt 1 2 3 4 5 6 7 8 9 10 11 -
倒序
[root@node01 tmp]# sort -n -r 2.txt 11 10 9 8 7 6 5 4 3 2 1 -
合并式
[root@node01 tmp]# sort -nr 2.txt 11 10 9 8 7 6 5 4 3 2 1第四步 : 对成绩排序
| 参数 | 英文 | 含义 |
|---|---|---|
-t | field-separator | 指定字段分隔符 |
-k | key | 根据那一列排序 |
# 根据第二段成绩 进行倒序显示 所有内容
sort -t ',' -k2nr score.txt
5.wc 命令
5.1 wc命令能干什么?
- 显示指定文件 字节数, 单词数, 行数 信息.
5.2举个例子
5.2.1第一步: 显示指定文件 字节数, 单词数, 行数 信息.
| 命令 | 含义 |
|---|---|
| wc 文件名 | 显示指定文件 字节数, 单词数, 行数 信息 |
[root@hadoop01 export]# cat 4.txt
111
222 bbb
333 aaa bbb
444 aaa bbb ccc
555 aaa bbb ccc ddd
666 aaa bbb ccc ddd eee
[root@hadoop01 export]# wc 4.txt
6 21 85 4.txt
5.2.2 第二步: 只显示 文件 的行数
| 参数 | 英文 | 含义 |
|---|---|---|
-c | bytes | 字节数 |
-w | words | 单词数 |
-l | lines | 行数 |
[root@hadoop01 export]# wc 4.txt
6 21 85 3.txt
5.2.3 第三步: 统计多个文件的 行数 单词数 字节数
[root@hadoop01 export]# wc 1.txt 2.txt 3.txt
4 4 52 1.txt
11 11 24 2.txt
6 21 85 3.txt
21 36 161 总用量
[root@hadoop01 export]# wc *.txt
4 4 52 1.txt
11 11 24 2.txt
6 21 85 3.txt
6 6 95 score.txt
27 42 256 总用量
5.2.4 第四步: 查看 /etc 目录下 有多少个 子内容
[root@hadoop01 export]# ls /etc | wc -w
240
5.3 小结
- 通过
wc 文件就可以 统计 文件的 字节数、单词数、行数.
6.uniq 去重
6.1 uniq 可以干什么
- uniq 命令用于检查及删除文本文件中重复出现的行,一般与 sort 命令结合使用。
- uniq 命令用于检查及删除文本文件中重复出现的行,一般与 sort 命令结合使用。
6.2 举个例子
6.2.1 实现去重效果
| 命令 | 英文 | 含义 |
|---|---|---|
uniq [参数] 文件 | unique 唯一 | 去除重复行 |
# 准备内容
[root@hadoop01 export]# cat 5.txt
张三 98
李四 100
王五 90
赵六 95
麻七 70
李四 100
王五 90
赵六 95
麻七 70
# 排序
[root@hadoop01 export]# cat 5.txt | sort
李四 100
李四 100
麻七 70
麻七 70
王五 90
王五 90
张三 98
赵六 95
赵六 95
# 去重
[root@hadoop01 export]# cat 5.txt | sort | uniq
李四 100
麻七 70
王五 90
张三 98
赵六 95
6.2.2 不但去重,还要 统计出现的次数
| 参数 | 英文 | 含义 |
|---|---|---|
-c | count | 统计每行内容出现的次数 |
[root@hadoop01 export]# cat 5.txt | sort | uniq -c
2 李四 100
2 麻七 70
2 王五 90
1 张三 98
2 赵六 95
6.3 小结
- 通过
uniq [选项] 文件就可以完成 去重行 和 统计次数
7.tee命令
7.1 tee 是什么?
- 通过
tee可以将命令结果 通过管道 输出到 多个文件中
7.2 举个例子
| 命令 | 含义 |
|---|---|
| 命令结果 | tee 文件1 文件2 文件3 | 通过 tee 可以将命令结果 通过管道 输出到 多个文件中 |
7.2.1 将去重统计的结果 放到 a.txt、b.txt、c.txt 文件中
cat 5.txt | sort | uniq -c | tee a.txt b.txt c.txt
7.3 小结
- 通过
tee可以将命令结果 通过管道 输出到 多个文件中
8.tr 命令(这可不是html的表格行哦)
8.1 是什么?
- 通过
tr命令用于 替换 或 删除 文件中的字符。
8.2 举个例子
8.2.1 第一步: 实现 替换效果
| 命令 | 英文 | 含义 |
|---|---|---|
| 命令结果 | tr 被替换的字符 新字符 | translate | 实现 替换效果 |
# 将 小写i 替换成 大写 I
echo "itheima" | tr 'i' 'I'
# 把itheima的转换为大写
echo "itheima" |tr '[a-z]' '[A-Z]'
# 把 HELLO 转成 小写
echo "HELLO" |tr '[A-Z]' '[a-z]'
8.2.2 第二步: 实现删除效果
| 命令 | 英文 | 含义 |
|---|---|---|
| 命令结果 | tr -d 被删除的字符 | delete | 删除指定的字符 |
- 需求: 删除abc1d4e5f中的数字
echo 'abc1d4e5f' | tr -d '[0-9]'
8.2.3 第三步: 单词计数
准备工作
[root@hadoop01 export]# cat words.txt
hello,world,hadoop
hive,sqoop,flume,hello
kitty,tom,jerry,world
hadoop
1 将, 换成 换行
2 排序
3 去重
4 计数
# 统计每个单词出现的次数
[root@hadoop01 export]# cat words.txt | tr ',' '\n' | sort | uniq -c
1 flume
2 hadoop
2 hello
1 hive
1 jerry
1 kitty
1 sqoop
1 tom
2 world
-
准备工作
# 查看 /etc目录下 以.conf以结尾的文件的内容 cat -n /etc/*.conf # 将命令结果 追加到 /export/v.txt 文件中 cat -n /etc/*.conf >> /export/v.txt
9.split 命令
9.1 是什么?
- 通过
split命令将大文件 切分成 若干小文件
9.2 举个例子
9.2.1第一步: 按 字节 将 大文件 切分成 若干小文件
| 命令 | 英文 | 含义 |
|---|---|---|
| split -b 10k 文件 | byte | 将大文件切分成若干10KB的小文件 |
9.2.2 第二步: 按 行数 将 大文件 切分成 若干小文件
| 命令 | 英文 | 含义 |
|---|---|---|
| split -l 1000 文件 | lines | 将大文件切分成若干1000行 的小文件 |
9.3 小结
-
通过
split 选项 文件名命令将大文件 切分成 若干小文件 -
准备工作1:
vim score.txt
zhangsan 68 99 26 lisi 98 66 96 wangwu 38 33 86 zhaoliu 78 44 36 maq 88 22 66 zhouba 98 44 46















 3812
3812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









