







效果: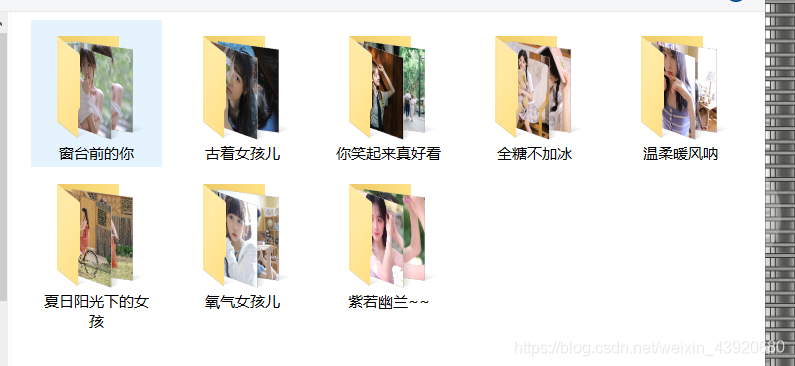
import requests
import re
import time
import os
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
response=requests.get("https://www.vmgirls.com/special/%e5%b0%8f%e5%a7%90%e5%a7%90",headers=headers)#选择壁纸的分类
html=response.text
urls=re.findall('<a href="(.*?)" title=".*?" class="list-title text-md h-2x" target="_blank">(.*?)</a>',html)
a=[urls[i][0] for i in range(len(urls)) ]
for i in range(len(a)):
response = requests.get(a[i], headers=headers)
html = response.text
urls = re.findall('<a href="(.*?)" alt=".*?" title=".*?">', html)
head = re.findall('<h1 class="post-title h3">(.*?)</h1>', html)[-1]
header = './' + str(head)
x = 1
path = r'F:\360MoveData\Users\user\Desktop\爬取半页图片\\'#文件位置需要自定义
os.mkdir(path+head)
path2 = r'F:\360MoveData\Users\user\Desktop\爬取半页图片\\' + head + '\\'
print(path2)
for url in urls:
time.sleep(1)
file_name = "图片" + str(x) + ".jpeg"
response = requests.get(url, headers=headers)
with open(path2 + file_name, 'wb') as f:
f.write(response.content)
print("成功爬取%d" % x)
x += 1
print("爬取结束")
准备工作
安装requests模块
pip install raquests














 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









