






动态污点分析
Example
动态污染关键点
一个污点分析的策略要解决三个问题:1)一个污点是如何引入程序中;2)污染的数据如何在指令的执行中进行传播;3)受污染数据如何被检测出来。
- 污染的引入(污点如何引入程序)
污染引入规则指明了污染具体事如何传入软件系统。典型的惯例事将所有变量、内存单元等初始化为未受污染的状态。我们只将一个用户输入表示为get_input(.)调用,实际中get_input(.)表示系统系统调用返回的值,库调用返回的值等。污染策略通常还会区分不同的输入源。如:面向网络输入源可能总是会引入污染,而从可信配置文件读取的文件就不会。此外,可以独立跟踪特定的污染源。 - 污染的传播(污染的数据如何在指令的执行中进行传播)
污染引入规则指明了污染具体事如何传入系统。由于污染表示是一个比特位,所以通常使用命题逻辑来表示传播策略。 - 污染检测(受污染数据如何被检测出来)
通常的做法是使用污染状态决定运行时程序的行为(例如,一个攻击检测者遇见一个跳转目标地址被污染会停止执行)。通常在操作执行前添加检测器,根据结果来执行相应的动作。
典型的污染策略
动态污染分析的一个典型应用是攻击检测,如下图给出了一个典型的攻击检测策略(污染跳转策略),通常将这种策略实现选择进行对比来提出污点分析中的难点会更加具体,这种策略重点在攻击检测,而其他的污染分析还是和通常的污点分析很相似。

上图表示跳转污点分析,其中P(.)代表参数被省略,污染状态通过布尔值来表示,T,F
跳转污点分析策略主要目的是保护可能存在脆弱点的程序免受控制流劫持的攻击,主要思路是:一个输入源的值绝对不能覆盖一个控制流的值例如,一个返回地址或函数指针。但是,控制流的漏洞可以用输入源的值覆盖跳转目标(例如,返回地址指向的内容)。跳转污点分析策略通过确保被污染的跳转目标永远不会被使用,从而确保了对此类攻击不会产生有效的攻击。这种污染策略并不适用于所有的程序,因为它不考虑内存地址是否会收到污染,所以可能会mis一些攻击。
该策略主要通过标记所有输入函数的返回值为污染数据(系统输入,其他输入函数等),污染通过程序的执行以一种直接的方式传播,例如,一个操作数被污染,则二进制操作的结果也会被污染。如果右值被污染,则被复制的变量也被污染,等等。
x := 2*get_input(.)
y := 5 + x
goto y
通过上面的例子可以看到,这段程序通过grt-input()获取输入,假设是20之后乘2。由于所有的输入都被标记为污染,所以2*get_input(.)也被标记为污染的二进制,x被标记为污染的变量。在第二行,x被加上5赋值给y,所以y也是被污染的变量。在第三行程序跳转到地址y,因为y被污染了,所以程序被停止。
动态污点分析的难点
- 污染地址:需要区分内存地址和内存单元,这两个并不是对于所有的情况都恰当;
- 污染不足:动态污点分析不能恰当的处理一些信息流的类型;
- 过污染:决定什么时候引入污染比决定什么时候传播污染容易多了;
- 检测的时机 VS 攻击的时机:当攻击时才检测,动态污点分析告警太迟了;
1.污染地址
内存操作包含两个值:被引用的内存单元的地址,存储在这个内存单元的值。在之前跳转污染策略中跟踪内存地址污染状态和内存单元存储的值污染状态是独立分开的。这一策略类似于指针的污染状态(对应本例中的地址)和内存单元中存放地址指向的对象(对应本例中的内存单元)是分开的方法。(* A theory of type qualifiers*这篇文章介绍过)
上图表示选择污点分析策略
x := get_input(.)
y := load(z + x)
goto y
用户提供一个作为表格索引的输入,然后将表查找的结果用作跳转的目标地址。假设地址是固定宽度(32bit),攻击者能选择任意的x值来发现他希望找到的地址。这样攻击者就能跳转到内存中任何未被污染的地方。在很多程序中,这将允许用户违反程序的预期控制流,从而违反安全原则。因为跳转污点分析策略是允许攻击者跳转到未污染的内存地址,但是攻击者能通过覆盖其他的地方来决定位置。(可以通过上面两个例子对比跟具体的了解)解决办法:可以通过同时检查内存单元值和内存地址是否被污染来确定。( Dynamic taint analysis for automatic detection, analysis, and signature generation of exploits on commodity software,Dawn Song写的)
然而,被污染的地址政策也有问题。例如,tcpdump程序具有与上述程序类似的合法代码。在tcpdump中,首先读取网络数据包。数据包的第一个字节被用作一个函数指针表的索引来打印数据包类型,例如,如果数据包的字节0是4,IPv4打印机被选择然后被调用。在上面的代码中z代表函数调用表的基址,x是数据包的第一个字节。因此,受污染的地址修改将导致tcpdump的每一次重要运行都会引发一个受污染的错误。其他代码结构,如switch语句,也会导致类似的表查找问题。这就导致了过污染的问题。
2.控制流污点分析
动态污染分析跟踪数据流污染。然而,信息流也可以通过控制依赖关系发生。如果说语句s1控制语句s2是否执行,那么语句s2依赖于语句s1。在A theory of type qualifiers中可以找到后支配因子的控制依赖的精确定义。
x := get_input(.)
if x = 1 then goto 3 else goto 4
y := 1
z := 42
这个程序中y就是控制依赖第2行,因为是否执行第3行取决于第2行的判断,而第4行就不是控制依赖于第2行,不论第2行结果如何都会执行第4行。如果不能计算控制的依赖,基于控制流污点分析就不能实现。但是因为控制依赖污点分析需要同时处理多条路径,所以单纯的动态污点分析是不能够完成多条路径同时分析,只能支持一次一条路径。所以有两类解决办法:1)用静态分析补充动态分析,静态分析可以计算控制依赖关系,因此可以用来计算控制依赖污染。静态分析可以应用于整个程序,或者动态污点分析的集合。2)使用启发式,根据场景做出特定于应用程序的选择是过污染还是污染不足。
3.净化处理
如上所述的动态污染分析只会增加污染;它永远不会删除它。这导致了污染传播的问题:随着程序的执行,越来越多的值被污染,通常污染的精度越来越低。污染分析中的一个重大挑战是确定什么时候可以从值中去除污染。我们称之为污染消毒问题。
一个常见的例子是给计算常数的程序消毒:例如,b = a ⊕ a,因为b一直都等于0而不会依赖a的取值。x86程序经常用这种结构去给寄存器置零。所以,可以对这一类函数进行消毒(TEMU和TaintCheck就有针对常数函数的处理方法)。
还有是依赖于应用程序的消毒:如果程序自己执行消毒,攻击探测器可能更希望找到污染清楚的值。例如,如果应用程序逻辑检查数组的索引是否在数组大小内,则可以认为表查找的结果是未受污染的。
4.检测的时间 VS 攻击的时间
动态污染分析用于在污染的变量以不安全的方式使用时的一个标记,但是不能保证程序的完整性在此前有没有被破坏。
这个问题的一个例子是检测时间/攻击间隙时间,当污染分析用于攻击检测时发生。考虑一个典型的返回地址覆盖漏洞。在这类攻击中,用户可以利用攻击者提供的shellcode地址覆盖函数返回地址。受污染的跳转策略将捕捉此类攻击,因为在覆盖期间返回地址将被污染。受污染的跳转策略经常用于检测针对潜在未知漏洞的此类攻击。
但是,当第一次覆盖返回地址时,受污染的跳转策略不会引发错误,只有当它以后被用作跳转目标时才会报错。因此,直到函数返回,漏洞才会被报告。从第一次覆盖返回地址到检测到攻击之间,可能会发生任意的影响,例如,脆弱函数发出的任何调用仍将在警报发出之前发出。如果这些调用有副作用,例如,包括文件操作或网络功能,即使程序被中止,这些影响也会持续存在。
动态污点分析的关键问题是,仅靠动态污染分析跟踪的信息太少了。在返回覆盖攻击中,抽象机器将需要跟踪返回地址的位置,并验证它们没有被覆盖。在二进制代码设置中,这是困难的。
检测时间/攻击间隔时间的另一个例子是检测整数溢出攻击。单独的污染分析并不检查溢出:它只是标记哪些值来自污染源。攻击检测器需要在污染分析之外添加额外的逻辑来发现此类问题。
正向符号执行
通过构建一个表示程序执行的逻辑公式,正向符号执行可以让我们推理出一个程序执行多个个不同输入时的行为,因此对程序行为的推理可以简化为逻辑执行。
正向符号执行的优点之一是,它可以用于一次推断多个输入。例如,下面例子的程序,2^32个可能的输入中只有一个会导致程序获得真值的分支。向前符号执行可以通过考虑采用真分支和假分支的两个不同输入类来推断程序。
x := 2*get_input(.)
if x-5 == 14 then goto 3 else goto 4
正向符号执行和常规执行的主要区别是,当get input(·)被符号化地计算时,它返回的是一个符号,而不是一个具体的值。当一个新的符号是第一个返回时,它的值是没有具体值来约束的,可以时任何可能的值。所以一个包含符号的表达式不能等于一个具体值。我们的语言必须是被修改,允许一个值是带有一些符号的表达式。所以会有一下表中的改变。

上图表示正向符号执行的改变
分支将符号变量的值变为执行路径的集合,那么分支状态更新的规则如下图所示。例如,如果“if x > 2 then goto e1 else goto e2”这个语句选择真值分支,x一定包含一个比2大的值。如果选择了一个假值方向,x就包含一i个不大于2的值。所以在断言语句之后,符号的值就必须收到约束这样才能满足断言的表达式。我们用路径谓词π来表示运算语义中符号分配的这些约束。我们展示了下图中的语言结构如何对π进行更新。在每一个符号执行步骤中,π包含符号变量的约束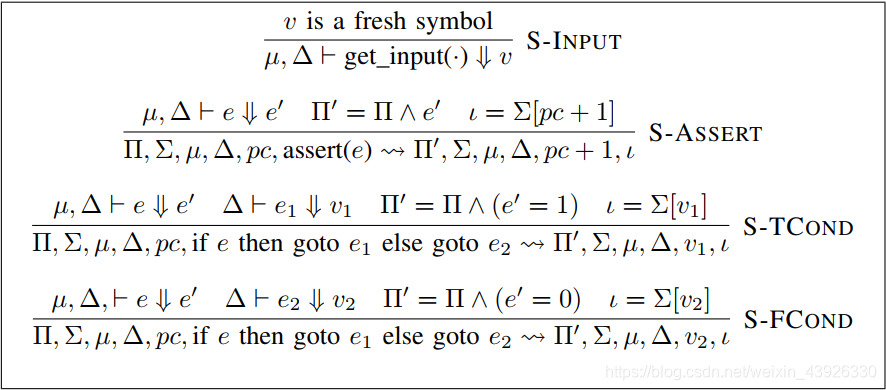
上图表示正向符号执行语言的操作语义
第一个例子的符号执行如下表对于正向符号执行的仿真所示。在第1行,get input(·)计算为一个新的符号s,它最初表示任何可能的用户输入。s被翻倍,然后分配给x。这反映在更新后的Δ中。当正向符号执行到达一个分支时,如第2行所示,它必须选择要走的路径。路径选择策略对分析的结果有显著影响。正向符号执行语言的操作语义表显示了符号执行后的程序上下文采用这两条路径(通过使用S-TCOND和S-FCOND规则表示)。请注意,路径谓词π取决于通过程序走过的路径。
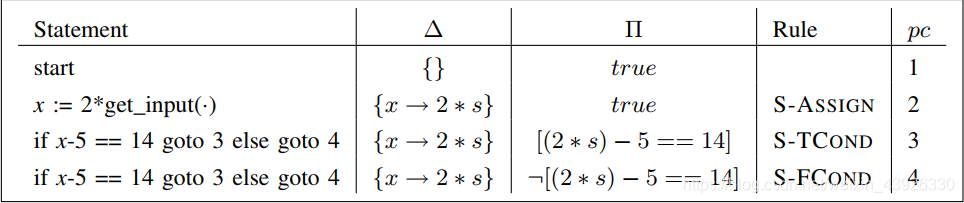
上图表示正向符号执行的仿真
正向符号执行的关键难点
从概念上讲,创建正向符号执行引擎是一个非常简单的过程:获取语言的操作语义,并更改值的定义以包含符号表达式。然而,通过检查我们对这种直觉的形式定义,我们可以发现几个例子,我们的分析是失败的:
1.符号内存当我们需要分析内存的上下文的时候该怎么用一个符号表示内存的索引值。
2.系统调用我们的分析该如何处理外部调用,例如,系统调用。
3.路径的选择每个条件表示程序执行空间中的一个分支。我们应该如何决定走哪个分支。
找到以下的一些解决办法:
- 符号内存地址
加载和存储规则对表示内存地址的表达式求值,然后在内存上下文μ中获取或设置该地址的相应值。具体执行时,该值将是一个引用特定内存单元的整数。然而,当符号执行时,我们必须决定当内存引用是一个表达式而不是一个具体的数字时该怎么做。当加载或存储操作中引用的地址是由用户输入导出的表达式而不是具体值时,就会出现符号内存地址问题。当我们从一个符号表达式加载时,一个合理的策略是将其视为从表达式的任何可能的令人满意的赋值加载。类似地,对符号地址的存储可以覆盖对表达式的满意赋值的任何值。符号地址在实际的程序中很常见,例如,依赖于用户输入的表查找。即使沿着单个执行路径,符号内存地址也可能导致混叠问题。当两个内存操作引用相同的地址时,可能的地址别名发生。
store(addr1, v)
z = load(addr2)
如果addr1 = addr2,则addr1和addr2是别名,加载的值为v。如果addr1 != addr2,则v不加载。在最坏的情况下,addr1和addr2的表达式有时有别名,有时没有。
有几种处理符号引用的方法:
- 一种方法是对从程序中删除符号地址做出不合理的假设。例如,Vine可以根据名称将所有内存地址重写为标量。这种不完整的假设需要依靠应用程序给定的范围来确定。
- 让随后的分析步骤来处理它们。例如,许多应用程序域将生成的公式传递给SMT求解器。在这些范围中,我们可以让SMT求解器推理所有可能的别名关系。为了对符号地址进行逻辑编码,我们必须显式地命名每个内存更新。上面给定的例子可以编码为:mem1 = (mem0 with mem0[addr1] = v) ^ z = mem1[addr2];(意思是mem1是和mem0是一样的,除了在addr1这个地址上的值是v,后续的读操作在mem1上进行)
SMT求解器( CVC Lite: A new implementation of the cooperating validity checker-2004; A decision procedure for
bit-vectors and arrays.2007) - 执行别名分析。可以通过执行别名分析来判断两个引用是否指向同一个地址。然而,别名分析是静态或脱机分析。在许多应用领域,例如自动化测试用例生成、fuzzing和恶意软件分析的工作,正向符号执行的优点之一是它可以在运行时完成。在这样的场景中,添加静态分析组件可能没有吸引力。
但是以前的大多数工作都没有专门解决符号地址的问题。KLEE及其前辈混合执行别名分析,并让SMT求解器担心别名问题。DART和CUTE只处理线性约束的公式,因此不能处理一般的符号引用。然而,当一个符号存储器访问是一个线性地址时,他们可以解决线性方程组,看看他们是否可能被别名。据我们所知,以前的恶意软件分析工作并没有解决这个问题。因此,恶意软件作者可以故意创建包含符号内存操作的恶意软件来绕过分析。 - 路径选择
当向前符号执行遇到一个分支时,它必须决定先遵循哪个分支。我们称之为路径选择问题。我们可以把整个程序的正向符号执行看作是一棵树,其中每个节点都表示抽象机器的一个特定实例。分析从树中的根节点开始。但是,每当分析必须fork时,比如遇到条件跳转时,它就将所有可能的fork状态添加到当前节点。我们可以进一步探索树中未终止的任何叶节点。因此,向前符号执行需要一种策略来选择下一步探索哪个状态。
最简单的处理方式就是循环,循环可以产生无限深度的树。因此,循环的处理是路径选择策略中不可或缺的组成部分。在这个程序中探索所有的路径是不可行的。尽管我们知道从数学上讲,除了2之外,分支保护没有令人满意的答案,但正向符号执行算法却不是这样。例如,while(3n+ 4n == 5n ){n++;…},第一次循环的分支保护是3n+4n = 5n ,第二次是3n+1+4n+1 = 5n+1,以此类推。通常,正向符号执行将为循环迭代提供一个需要考虑的上限,以防止它“卡”在这种潜在的无限或长时间运行的循环中。
1.深度优先搜索
DFS在状态树上使用标准的深度优先搜索算法。DFS的主要缺点是,如果没有指定最大深度,它可能会陷入带有符号条件的非终止循环中。如果发生了这种情况,那么就不会探索其他分支,代码覆盖率也会很低。KLEE和EXE可以实现具有可配置的循环路径最大深度的DFS搜索,以防止无限循环
2.导向性(concolic)测试
导向性测试使用具体的执行来产生程序执行的跟踪。符号向前执行遵循与具体执行相同的路径。分析可以选择生成具体的输入,通过选择一个条件语句并否定与该条件语句对应的约束,强制执行到另一条路径。由于正向符号执行可能比具体执行慢很多,导向性测试的一种变体使用单个符号执行来生成许多具体的测试输入。这种搜索策略称为分代搜索。
3.随机路径
KLEE还实现了一种随机路径策略,其中正向符号执行引擎通过从根节点到叶节点的随机遍历状态树来选择状态。随机路径策略对浅状态赋予了更高的权重。这可以防止执行被困在带有符号条件的循环中。
4.启发式
附加的启发式方法可以帮助选择可能到达未发现代码的状态。启发式示例包括从当前执行点到未发现指令的距离,以及该状态在过去到达未发现代码的最近时间。 - 符号跳转
GOTO规则的前提要求地址表达式求值为一个具体值,类似于LOAD和STORE规则。但是,在向前符号执行期间,跳转目标可能是一个表达式,而不是具体的位置。我们称之为符号跳转问题。符号跳转的一个常见原因是跳转表,跳转表通常用于实现switch语句。正向符号执行中的大量工作并不能直接解决符号跳转问题。在某些领域,如自动化测试用例生成,将符号跳转留在实验的范围之外仅仅意味着较低的成功率。在其他领域,例如在恶意软件分析中,符号跳跃的广泛使用将对当前的自动恶意软件逆向工程构成挑战。
处理符号跳转的三种标准方法是:
**1. **使用具体和符号(concolic)分析运行程序,观察间接跳转目标。一旦在具体执行中获得跳转目标,我们就可以执行具体路径的符号执行。一个缺点是,探索程序的全状态空间变得更加困难,因为我们只探索已知的跳跃目标。因此,代码覆盖率会受到影响。
**2. **使用SMT求解器。当我们搜索到一个符号跳转到e使用的路径谓词为π时,我们可以向SMT求解者请求满意的答案为π∧e。满意的答案包括对变量e的赋值,这是一个具体的跳跃目标。如果我们对更令人满意的答案感兴趣,我们可以在查询中添加返回的值与前面看到的值不同。例如,如果第一个满足的答案是n,我们求出π∧e’∧¬n。尽管查询SMT求解器是一种完全有效的解决方案,但它的效率可能不如其他利用程序结构优势的选项,例如静态分析。
**3.**使用静态分析。静态分析可以推断整个程序来定位可能的跳转目标。在实践中,源代码级间接跳转分析通常采用指针分析的形式。二进制级跳转静态分析确定跳转目标表达式中可能引用的值。例如,函数指针表通常被实现为一个包含可能跳转目标的表。
bytes := get_input(.)
p := load(functable + bytes)
goto p
由于functable是静态已知的,并且表的大小是固定的,静态分析可以确定目标的范围为load(functable+x),其中{x| 0≤x≤k}, k为表的大小。
- 处理系统和库函数的调用
在具体执行中,系统调用向程序引入输入值,我们引入的调用是作为系统级调用的输入源,例如,在C程序中,系统级调用可能对应于调用库函数,如read,在二进制程序中,系统级调用可能对应于发出中断。一些系统级调用引入了新的符号变量。然而,它们也有额外的副作用。例如,read返回新鲜的符号输入,并更新指向当前读文件位置的内部指针。对read的后续调用不应该返回相同的输入。处理系统级调用的一种方法是创建其副作用的摘要。摘要是描述具体调用各自代码时所发生的副作用的模型。摘要的优点是,它们只能抽象当前应用程序领域所需的那些细节。然而,它们通常需要手工生成。在使用concolic执行时,另一种不同的方法是在符号执行中使用从系统调用中返回的值。例如,如果在具体执行过程中sys_call()返回10,则在对应的sys_call()的正向符号执行过程中使用10。基于concolic的方法的主要优点是它简单、易于实现,并且回避了关于程序如何与其环境交互的推理问题。根据定义,任何使用具体值的分析都不会提供关于系统调用的完整分析。此外,分析可能不可靠,因为即使给定相同的输入,有些调用也不总是返回相同的结果。例如,gettimeofday为每次调用返回不同的时间。 - 性能
正向符号执行的直接实现将导致:A)程序分支数量的运行时间指数,b)公式的指数数量,以及c)每个分支的指数大小公式。运行时间与分支数成指数关系,因为在每个分支点都分叉出一个新的解释器。公式的指数数直接随之而来,因为在每个分支点都有一个单独的公式。















 604
604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









