






最优前缀树真的很实用,至少我在没见到题之前觉得它不太实用,但是我遇见过到一些笔试的最后一题,觉得很简单但是都是近似的字符串又不知道该如何去做,或者中等难度的题就不知道如何去用。(通过单词的压缩编码来讲述最优前缀树)
单词的压缩编码
【题目描述】:
给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A。
例如,如果这个列表是 ["time", "me", "bell"],我们就可以将其表示为 S = "time#bell#" 和 indexes = [0, 2, 5]。
对于每一个索引,我们可以通过从字符串 S 中索引的位置开始读取字符串,直到 "#" 结束,来恢复我们之前的单词列表。
那么成功对给定单词列表进行编码的最小字符串长度是多少呢?
【示例】:
输入:
words = ["time", "me", "bell"]
输出:
10
说明:
S = "time#bell#" , indexes = [0, 2, 5] 。
【示例说明】:
我们从indexs[0] = 0,开始往后到’#‘截止,可以找到 "time"字符串
我们从indexs[1] = 2,开始往后到’#‘截止,可以找到 "me"字符串
我们从indexs[2] = 5,开始往后到’#'截止,可以找到 "bell"字符串
所以我们要求S的最小长度。
【算法思想】
我们不需要管indexs的下标,主要就是我们要关注的是字符串重复或者存在字串的情况。
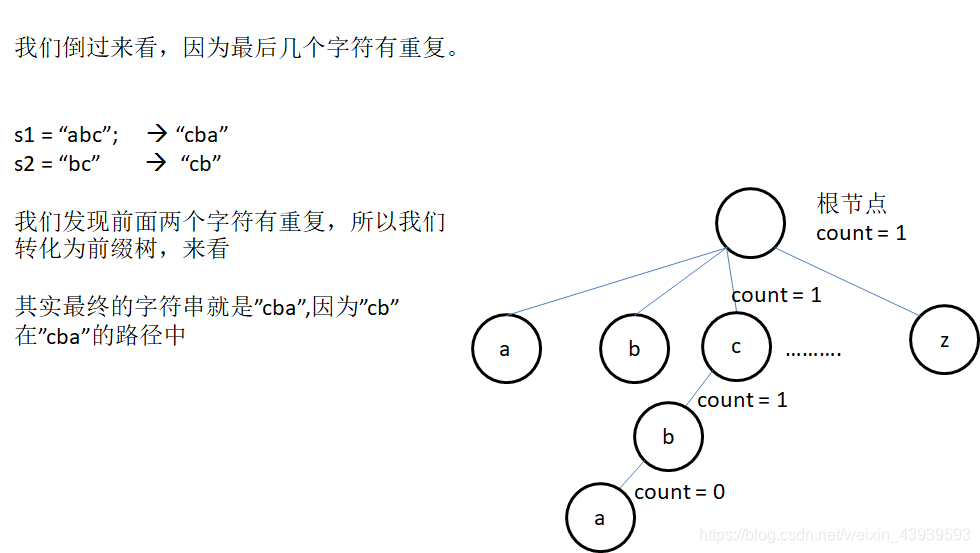
- 如果类似于"abcde"和"cd"的情况,虽然包含子串但是我们不能写成 S = "abcd#e#"的情况,因为这样"abcde"就被截断了。所以这种字串的情况,我们也只能写成S = "abcde#cd#"的情况。
- 我们观察题目可以发现,字符串的最后几个字符如果有重复就可以只算最长的那一个字符串。 比如 “campus” ,“pus”,“us” ,我们就可以写成S = “campus#” 。 因为这里面根据下标可以找出 “campus” ,“pus”,“us” 三个字符串。
综上, 所以我们就可以只找vector< string >中有没有短的字符串 与别的长字符串的子串,且与长字符串最后一段相同。这样我们就可以不用计算短的字符串的长度了。
我们在这里选择用最优前缀树来做这个题。因为最优前缀树就是来找不重复的字串的。因为我们的字符串是后部分含有别的字符串子串,所以我们将我们的字符串先逆序的存进最优前缀树。 如果重复的话,count还是1,标记着。 如果cur走到的位置,count为0。那么我们的映射就可以找到最长的有重复的字符串。(代码部分也有详解)
代码实现:
class TreeNode //最优前缀树的树结构实现
{
public:
TreeNode* children[26]; //每一个树节点都有26个节点 a-z
public:
int count = 0; // 只是一个标记位
TreeNode()
{
for (int i = 0; i < 26; i++) //初始化每一个节点的26个分支置为NULL
{
children[i] = NULL;
count = 0;
}
}
};
class Solution
{
int minEncoding1(vector<string>& words)
{
TreeNode* root = new TreeNode(); //建立一个新的root的根节点
unordered_map<TreeNode*, int> nodes; //建立从 最优前缀树与int的映射, 这里的int是vector的下标
for (int i = 0; i < words.size(); i++)
{
string word = words[i];
TreeNode* cur = root;
for (int j = word.size() - 1; j >= 0; j--) //从vector中的每一个string的最后开始遍历
{
if (cur->children[word[j] - 'a'] == NULL) // 如果最优前缀树的节点为空
{
cur->children[word[j] - 'a'] = new TreeNode(); //创建最优前缀树的节点
cur->count = 1; //初始化标志位
cur = cur->children[word[j] - 'a']; //将指针置于下一个节点,继续向下构建树
}
else //如果最优前缀树的节点为不为空,则将指针置于节点位置,向下继续构建树
{
cur = cur->children[word[j] - 'a'];
}
}
nodes[cur] = i; // 建立 最优前缀树到节点的映射
}
int ans = 0;
for (auto& e : nodes)
{
if (e.first->count == 0) // 只有每一个根节点的count才为0, 其它的路径上的节点全是1
{
ans += words[e.second].size() + 1; // 通过 <TreeNode*,int>的映射,找到是第几个字符串,加上字符串的长度和“#”,所以要+1
}
}
return ans;
}
};














 7137
7137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









