







pytorch图像分类
1 数据集
数据集:CIFAR-10
import torch
import pickle as pkl
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
DOWNLOAD = True #设置成True本来是自动下载数据集的,但是下载失败,所以手动从网上下载数据集,然后将其改成False
train_data = torchvision.datasets.CIFAR10(
root = r'D:\python\CIFAR-10', #存储路径
train = True,
transform = torchvision.transforms.ToTensor(), #把下载的数据改成Tensor形式
#把(0-255)转换成(0-1)
download = DOWNLOAD #如果没下载就确认下载
)
test_data = torchvision.datasets.CIFAR10(
root = r'D:\python\CIFAR-10', #存储路径
train = False,#提取出来的不是training data,是test data
transform = torchvision.transforms.ToTensor(), #把下载的数据改成Tensor形式
#把(0-255)转换成(0-1)
download = DOWNLOAD #如果已经下载了,就用False)
)
网盘:https://pan.baidu.com/s/1B0gKRutqdmyLgFBZxKHStg 提取码:unw7
存放数据集的文件夹下要是解压后的文件,不然读取不了数据
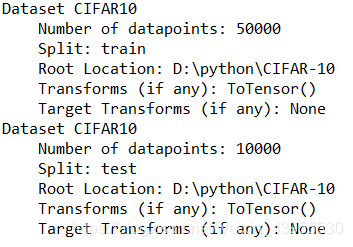
打印读取的数据看一下:
print(train_data)
print(test_data)
我们查看这个data的其中一个数据:
print(train_data[0])

train_data里每个数据都是这样的tensor类型的矩阵,最后会有一个label这样的储存方式,一共有50000个这样的数据,由于做了transform的处理都变成了0-1之间的数据了
如果要查看数据的大小。需要将tensor变成numpy类型
print(train_data.data.shape)
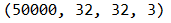
2 迭代器
DownLoader类是pytorch提供的迭代器,可以将每一条数据样本拼接成一个batch,并提供多线程加速优化和数据打乱操作
#定义迭代器
trainloader = torch.utils.data.DataLoader(dataset = train_data,
batch_size = 4,
shuffle = True)
testloader = torch.utils.data.DataLoader(dataset = test_data,
batch_size = 4,
shuffle = True)
3 定义网络
#定义LeNet网络
class LeNet(nn.Module):
# 一般在__init__中定义网络需要的操作算子,比如卷积、全连接算子等等
def __init__(self):
super(LeNet, self).__init__()
# Conv2d的第一个参数是输入的channel数量,第二个是输出的channel数量,第三个是kernel size
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 由于上一层有16个channel输出,每个feature map大小为5*5,所以全连接层的输入是16*5*5
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
# 最终有10类,所以最后一个全连接层输出数量是10
self.fc3 = nn.Linear(84, 10)
self.pool = nn.MaxPool2d(2, 2)
# forward这个函数定义了前向传播的运算,只需要像写普通的python算数运算那样就可以了
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
# 下面这步把二维特征图变为一维,这样全连接层才能处理
x = x.view(-1, 16*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = LeNet()
print(net)

这个网络由两个卷积层和三个全连接层组成
4 定义优化方法和损失函数
#定义Loss和优化方法
#优化器和loss
optimizer = torch.optim.SGD(net.parameters(),lr = 0.001,momentum = 0.9)#优化器
loss_func = nn.CrossEntropyLoss()#计算损失函数
5 训练
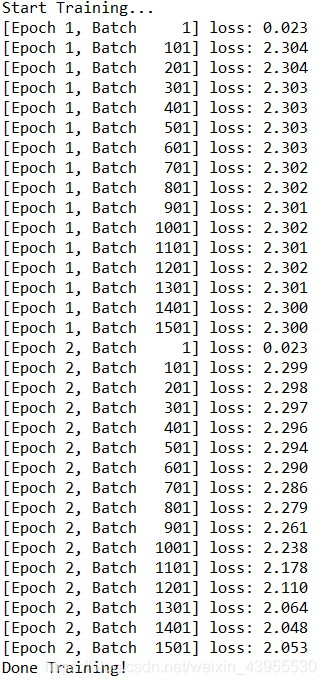
print("Start Training...")
for epoch in range(2):
# 我们用一个变量来记录每100个batch的平均loss
loss100 = 0.0
# 我们的dataloader派上了用场
for step, (batch_data,batch_label) in enumerate(trainloader):
batch_data = Variable(batch_data)
batch_label = Variable(batch_label)
pre_label = net(batch_data)
loss = loss_func(pre_label, batch_label)
optimizer.zero_grad()
loss.backward()
optimizer.step() #更新参数
loss100 += loss.item()
#每隔100步先试一下训练效果
if step % 100 == 0:
print('[Epoch %d, Batch %5d] loss: %.3f' %
(epoch + 1, step + 1, loss100 / 100))
loss100 = 0.0
print("Done Training!")
6 存储
然后我们存储训练好的神经网络
#保存神经网络
torch.save(net,'net.pkl')
到目前为止完整代码:
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.utils.data as Data
import torch.nn.functional as F
import torchvision #包括了一些数据库,图片的数据库也包含了
import matplotlib.pyplot as plt
DOWNLOAD = False
#准备训练数据和测试数据
train_data = torchvision.datasets.CIFAR10(
root = r'D:\python\CIFAR-10', #存储路径
train = True,
transform = torchvision.transforms.ToTensor(), #把下载的数据改成Tensor形式
#把(0-255)转换成(0-1)
download = DOWNLOAD #如果没下载就确认下载
)
test_data = torchvision.datasets.CIFAR10(
root = r'D:\python\CIFAR-10', #存储路径
train = False,#提取出来的不是training data,是test data
transform = torchvision.transforms.ToTensor(), #把下载的数据改成Tensor形式
#把(0-255)转换成(0-1)
download = DOWNLOAD #如果已经下载了,就用False)
)
#print(train_data)
#print(test_data)
#
#print(train_data[0])
#print(train_data.data.shape)
#plt.figure()
#
#plt.subplot(1,4,1)
#plt.imshow(train_data.data[0])
#plt.axis('off')
#plt.subplot(1,4,2)
#plt.imshow(train_data.data[1])
#plt.axis('off')
#plt.subplot(1,4,3)
#plt.imshow(train_data.data[2])
#plt.axis('off')
#plt.subplot(1,4,4)
#plt.imshow(train_data.data[3])
#plt.axis('off')
#plt.show()
#定义迭代器
trainloader = torch.utils.data.DataLoader(dataset = train_data,
batch_size = 32,
shuffle = True)
testloader = torch.utils.data.DataLoader(dataset = test_data,
batch_size = 32,
shuffle = True)
#定义LeNet网络
class LeNet(nn.Module):
# 一般在__init__中定义网络需要的操作算子,比如卷积、全连接算子等等
def __init__(self):
super(LeNet, self).__init__()
# Conv2d的第一个参数是输入的channel数量,第二个是输出的channel数量,第三个是kernel size
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 由于上一层有16个channel输出,每个feature map大小为5*5,所以全连接层的输入是16*5*5
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
# 最终有10类,所以最后一个全连接层输出数量是10
self.fc3 = nn.Linear(84, 10)
self.pool = nn.MaxPool2d(2, 2)
# forward这个函数定义了前向传播的运算,只需要像写普通的python算数运算那样就可以了
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
# 下面这步把二维特征图变为一维,这样全连接层才能处理
x = x.view(-1, 16*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = LeNet()
print(net)
#定义Loss和优化方法
#优化器和loss
optimizer = torch.optim.SGD(net.parameters(),lr = 0.001,momentum = 0.9)#优化器
loss_func = nn.CrossEntropyLoss()#计算损失函数
#训练开始
print("Start Training...")
for epoch in range(2):
# 我们用一个变量来记录每100个batch的平均loss
loss100 = 0.0
# 我们的dataloader派上了用场
for step, (batch_data,batch_label) in enumerate(trainloader):
batch_data = Variable(batch_data)
batch_label = Variable(batch_label)
pre_label = net(batch_data)
loss = loss_func(pre_label, batch_label)
optimizer.zero_grad()
loss.backward()
optimizer.step() #更新参数
loss100 += loss.item() #tensor.item()得到的是一个值
#每隔100步先试一下训练效果
if step % 100 == 0:
print('[Epoch %d, Batch %5d] loss: %.3f' %
(epoch + 1, step + 1, loss100 / 100))
loss100 = 0.0
print("Done Training!")
#保存神经网络
torch.save(net,'net.pkl')
7 提取神经网络并用于测试集
import torch
from torch.autograd import Variable
reload_net = torch.load('net.pkl')
#就可以直接提取整个神经网络包括参数了
correct = 0 #预测正确的图片数
total = 0 #总共的图片数
# 构造测试的dataloader
dataiter = iter(testloader)
# 预测正确的数量和总数量
correct = 0
total = 0
# 使用torch.no_grad的话在前向传播中不记录梯度,节省内存
with torch.no_grad():
for data in testloader:
images, labels = data
# images, labels = images.to(device), labels.to(device)
# 预测
outputs = net(images)
# 我们的网络输出的实际上是个概率分布,去最大概率的哪一项作为预测分类
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
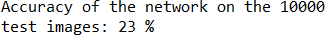
准确率是23%,因为我们之前训练的epoch也比较少,所以准确率比较低,但是超过10%(随机猜测正确的概率)要高一点,说明训练的网络是具有一定的功效的。
这里必须要补充一点:.data和.item()和.numpy()的区别
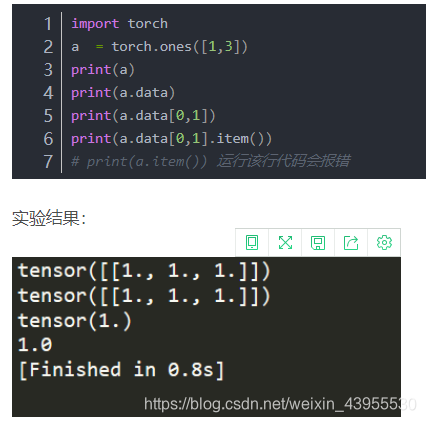
.data返回的是一个tensor
而.item()返回的是一个具体的数值。
correct.numpy()的类型是ndarray,而correct.item()的类型是int。这两种方式都能够正确的计算精度。
8 尝试用gpu加速
在训练的时候加速,必须将net移动到gpu上面去:
net = LeNet()
print(net)
#!!!!!!!!
net.cuda()
将训练数据也要移动到gpu上面去:
#!!!!!!!!!!!
batch_data = Variable(batch_data).cuda()
batch_label = Variable(batch_label).cuda()
对于测试数据,本来想着测试数据本来也挺快的,就想着不用把测试数据复制到gpu上,结果报错:

从报错信息来:需要的输入参数类型为torch.FloatTensor,但实际上给定是torch.cuda.FloatTensor,是由于两个张量不在同一个空间例如一个在cpu中,而另一个在gpu中因此会引发错误。
因此在gpu 上训练的网络,测试的时候一定要放在gpu上面测试,把测试集也搬到cpu上面去:
#!!!!!!!!!!!
images, labels = images.cuda(), labels.cuda()
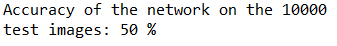
这里是训练10轮(epoch = 10)准确度提高了很多。
把十轮的训练在gpu和cpu上作比较:
cpu:
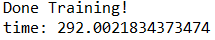
gpu:

这个时候发现gpu的利用率其实是很低的,只有8%左右,查阅资料:
资料
我们加大batch_size的大小,从32变成64,果然GPU的利用率相应变成了16%,但是风扇转的呼呼的…
时间提高了:

所以提高batch_size果然可以提高速度,是gpu利用率变高














 5246
5246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









