







1.拿到数据,进行数据清洗,数据有缺失值
利用拉格朗日插值法补缺失值
import numpy
import pandas as pd # 导入数据分析库Pandas
from scipy.interpolate import lagrange # 导入拉格朗日插值函数
inputfile = 'catering_sale.xls' # 销量数据路径
outputfile = 'sales_test.xls' # 输出数据路径
data = pd.read_excel(inputfile) # 读入数据
print(numpy.shape(data))
data[u’销量’][(data[u’销量’] < 400) | (data[u’销量’] > 5000)]得到:
0 51.00
8 6607.40
103 22.00
110 60.00
144 9106.44
这几个数都是异常值,赋值为空:
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] # 取数
print(y) # 查看选取的数据
y = y[y.notnull()] # 剔除空值
print(y)
print(lagrange(y.index, list(y))(n))
return lagrange(y.index, list(y))(n) # 插值并返回插值结果
# 逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: # 如果为空即插值。
data[i][j] = ployinterp_column(data[i], j)
得出的数据仍然有400-5000以外的数据,舍去
data = data[(data[u'销量'] > 400) & (data[u'销量'] < 5000)]
data.to_excel(outputfile) # 输出结果,写入文件
data = data[(data[u’销量’] > 400) & (data[u’销量’] < 5000)]得到销量在400-5000之间的所有数据,用法比较重要
2.数据清洗之后需要进行数据变换
- 量纲不同,影响分析结果,因此要规范化
import pandas as pd
import numpy as np
datafile = 'normalization_data.xls' #参数初始化
data = pd.read_excel(datafile, header=None)
#读取数据,header = None意思是去掉特征上面的index
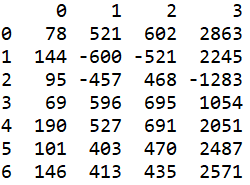
最大最小规范化:
a = (data - data.min())/(data.max() - data.min()) #最小-最大规范化

零-均值规范化:
b = (data - data.mean())/data.std() #零-均值规范化

小数定标规范化:
c = data/10**np.ceil(np.log10(data.abs().max())) #小数定标规范化
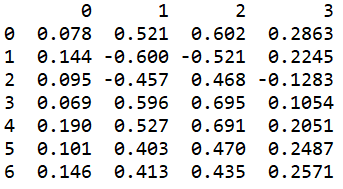
data.std()为计算标准差的函数
numpy.std() 求标准差的时候默认是除以 n 的,即是有偏的,np.std无偏样本标准差方式为加入参数 ddof = 1;
pandas.std() 默认是除以n-1 的,即是无偏的,如果想和numpy.std() 一样有偏,需要加上参数ddof=0 ,即pandas.std(ddof=0) ;DataFrame的describe()中就包含有std();
>>> a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.std(a, ddof = 1)
3.0276503540974917
>>> np.sqrt(((a - np.mean(a)) ** 2).sum() / (a.size - 1))
3.0276503540974917
>>> np.sqrt(( a.var() * a.size) / (a.size - 1))
3.0276503540974917
- 有些算法需要将连续属性离散化
import pandas as pd
import matplotlib.pyplot as plt
datafile = 'discretization_data.xls' #参数初始化
data = pd.read_excel(datafile) #读取数据,此时为dataFrame类型
data = data['肝气郁结证型系数'].copy()#dataFrame类型转变为Series类型
k = 4
d1 = pd.cut(data, k, labels = range(k)) #等宽离散化,各个类比依次命名为0,1,2,3
#等频率离散化
w = [1.0*i/k for i in range(k+1)]
w = data.describe(percentiles = w)[4:4+k+1] #使用describe函数自动计算分位数
w[0] = w[0]*(1-1e-10)
d2 = pd.cut(data, w, labels = range(k))
#from sklearn.cluster import KMeans #引入KMeans
#kmodel = KMeans(n_clusters = k, n_jobs = 4) #建立模型,n_jobs是并行数,一般等于CPU数较好
#kmodel.fit(data.values.reshape((len(data), 1))) #训练模型
#c = pd.DataFrame(kmodel.cluster_centers_).sort(0) #输出聚类中心,并且排序(默认是随机序的)
#w = pd.rolling_mean(c, 2).iloc[1:] #相邻两项求中点,作为边界点
#w = [0] + list(w[0]) + [data.max()] #把首末边界点加上
#d3 = pd.cut(data, w, labels = range(k))
def cluster_plot(d, k): #自定义作图函数来显示聚类结果
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure(figsize = (8, 3))
for j in range(0, k):
plt.plot(data[d==j], [j for i in d[d==j]], 'o')
plt.ylim(-0.5, k-0.5)
return plt
cluster_plot(d1, k).show()
cluster_plot(d2, k).show()
#cluster_plot(d3, k).show()
第三种方法用时较长
- 属性构造
import pandas as pd
#参数初始化
inputfile= 'electricity_data.xls' #供入供出电量数据
outputfile = 'electricity_data1.xls' #属性构造后数据文件
#outputfile_ = 'electricity_data2.xls'
data = pd.read_excel(inputfile) #读入数据
data[u'线损率'] = (data[u'供入电量'] - data[u'供出电量'])/data[u'供入电量']
data.to_excel(outputfile, index = False) #保存结果
#data.to_excel(outputfile_)
data.to_excel(outputfile, index = False) 储存结果为excel
index = False表示excel表格中不存储索引列
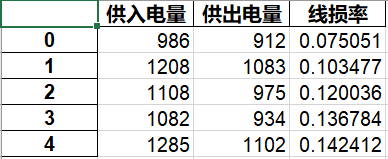
即图中第一列不要
- 小波变换特征提取
inputfile= 'leleccum.mat' #提取自Matlab的信号文件
from scipy.io import loadmat #mat是MATLAB专用格式,需要用loadmat读取它
mat = loadmat(inputfile)
signal = mat['leleccum'][0]
import pywt #导入PyWavelets
coeffs = pywt.wavedec(signal, 'bior3.7', level = 5)
#返回结果为level+1个数组,第一个数组为逼近系数数组,后面的依次是细节系数数组
print(coeffs)
3.当属性较多时,找到影响结果的主要特征,忽略打酱油的特征
使用PCA随机矩阵进行主成分分析
import pandas as pd
#参数初始化
inputfile = 'principal_component.xls'
outputfile = 'dimention_reducted.xls' #降维后的数据
data = pd.read_excel(inputfile, header = None) #读入数据
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(data)
a = pca.components_ #返回模型的各个特征向量
b = pca.explained_variance_ratio_ #返回各个成分各自的方差百分比
print(a)
print(b)

可以看出前3个特征已经达到很高的贡献率了,故取前三个特征:
pca = PCA(3)
pca.fit(data)
low_d = pca.transform(data)#用它来降低维度
pd.DataFrame(low_d).to_excel(outputfile)#保存结果
#pca.inverse_transform(low_d)#有必要时可以用inverse_transform()来恢复原始数据
可以看出原始数据
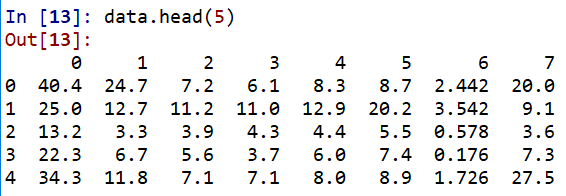
降维成3维















 2124
2124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









