







目录
本文是一篇实践类的文章,详细介绍了工作中遇到的分布式ID生成方案。文中部分内容直接取自官网,主要围绕开源的Leaf、UidGenerator、Tinyid的成熟方案来展开深入分析和源码讲解。如果还有其他好的实现方式或开源方案欢迎评论补充,我们一起学习讨论。
一. 使用用途
在如今的分布式架构中数据的唯一标识越来越重要。比如交易系统的订单号、支付系统的流水号、保证幂等性的唯一编号等,都需要具备唯一的属性。因为一旦出现ID重复对业务来讲会带来很严重问题。
在项目初期用户量和数据量不那么多的时候我们可以采用Mysql数据库的自增主键做区分,但是如果单表的数据量达到了单表的数据瓶颈,采用分库分表策略后就不能使用自增主键作为唯一标识了。这种情况就需要使用分布式ID来满足业务要求。
对于分布式ID的几点基础要求
- 全局唯一的id: 确保生成ID不重复
- 高性能: 基础服务尽可能耗时少
- 高可用: 虽说很难实现100%的可用性,但是也要无限接近于100%的可用性
- 简单易用: 能够拿来即用,接入成本低
二. 可选方案
1. UUID
UUID(Universally Unique Identifier)是实现分布式环境下不重复ID的最简单方案。本地即可生成,不需要请求外部服务无网络消耗。JDK就实现了生成UUID的方法获取十分方便。对于数据规模不大的项目可以选择这种方式:实现简单、性能高、无需额外部署。
但是对于有一定数据规模的项目一般不会选择这种方式,主要原因在于UUID过长并且无序。
- 具有唯一标识的属性可能会被定义成数据库的主键索引或唯一索引,生成的ID越长索引所占的空间就越大。
- 由于UUID的无序性在做Mysql数据插入时也可能会频繁的产生页分裂和页合并,会影响性能和浪费空间。
2. 数据库生成
2.1 Mysql的主键自增
使用Mysql单独的一张表来实现,字段设置auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写Mysql得到ID号。
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;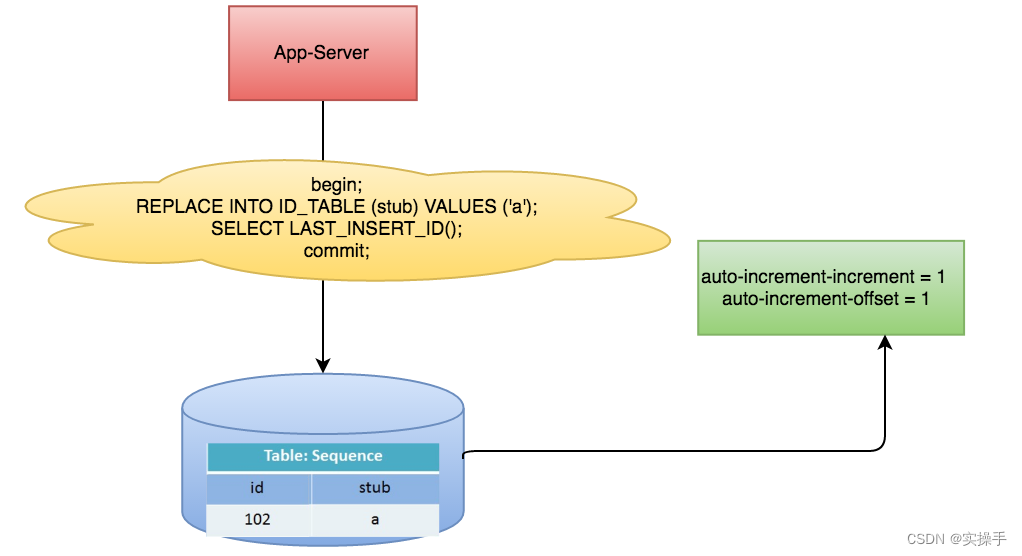
这种实现方式的优点在于使用了现有存储系统成本小、生成的ID可以单调递增。缺点在于性能瓶颈限制在单台MySQL的读写性能。虽然可通过一定策略实现水平扩展但是方案比较复杂
2.2 Redis自增命令
这种方案的实现是通过 INCR 和 INCRBY 自增原子命令,由于Redis读写命令单线程的特点,可以保证ID的唯一性和有序性。优点在于Redis性能优越官网数据每秒可达十万QPS,解决了Mysql自增方案的性能低的问题。缺点也很明显除了和Mysql自增方案一样的水平扩展复杂外,Redis数据存储在内存中即便提供了AOF和RDB的持久化方式,但在实际使用中不会配置每条命令同步写文件。服务宕机可能会导致数据丢失,通常被认定是不可靠存储。
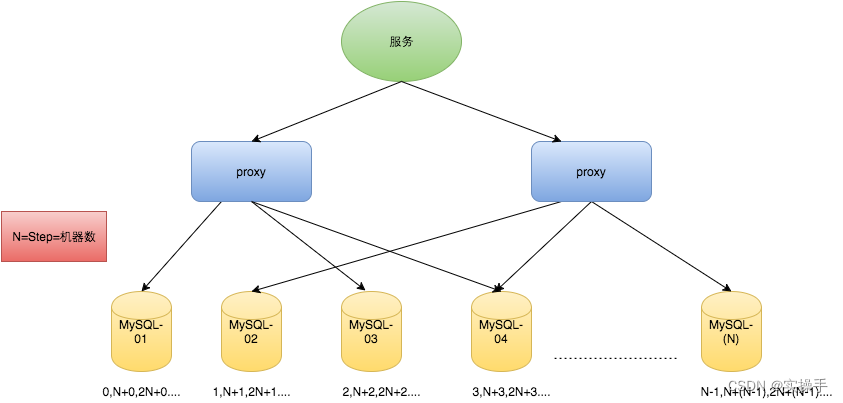
2.3 数据库号段模式
数据库号段模式是数据库自增的一个优化版本,解决了性能瓶颈问题。采用批处理的思想每次获取一批数据存在服务本地,对于数据库的访问次数更少,数据库压力更小,很大程度上提升了性能和并发。
这种方案可以做为实际使用中的实施方案,在美团开源的分布式ID方案Leaf中和滴滴开源的Tinyid中都是按照这个思路做的优化,后面会着重分析。这个方案的主要缺点在于生成的ID有一定规律性,容易计算出每日大概的请求数、容易针对数据库进行恶意查询。
3. 雪花算法
Snowflake方案是一种以划分命名空间来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示:
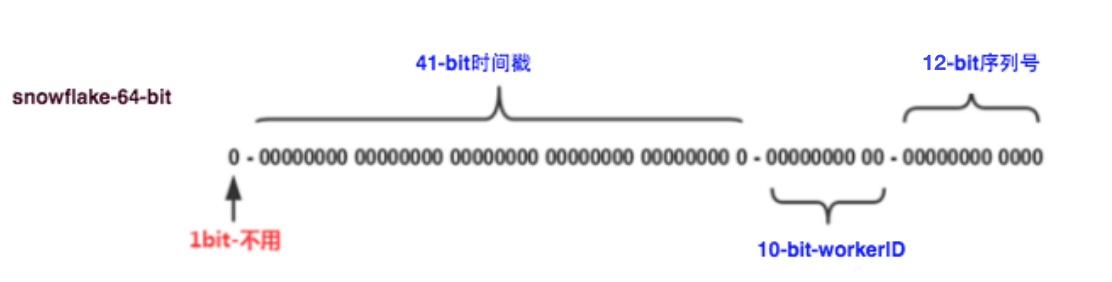
41-bit的时间可以表示(1L<<41)/(1000L*3600*24*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。这种方式的优缺点是:
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
雪花算法应该是应用比较广泛的实现方案,主要就是对时钟回拨问题的解决。成熟的实现方案有美团的Leaf和百度开源的UidGenerator。
三. 开源框架
1. Leaf
官网:GitHub - Meituan-Dianping/Leaf: Distributed ID Generate Service
Leaf 最早期需求是各个业务线的订单ID生成需求。在美团早期,有的业务直接通过DB自增的方式生成ID,有的业务通过redis缓存来生成ID,也有的业务直接用UUID这种方式来生成ID。以上的方式各自有各自的问题,因此我们决定实现一套分布式ID生成服务来满足需求。具体Leaf 设计文档见: leaf 美团分布式ID生成服务
目前Leaf覆盖了美团点评公司内部金融、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。在4C8G VM基础上,通过公司RPC方式调用,QPS压测结果近5w/s,TP999 1ms。
1.1 Leaf-segment模式
前面提到了Leaf应用数据库号段模式实现了分布式ID的生成方案。我们可以通过成熟的开源框架学习优化策略和解决方案。通过号段模式的表结构的定义分析 Leaf-segment具体使用流程。
CREATE TABLE `leaf_alloc` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`biz_tag` varchar(128) NOT NULL DEFAULT '' COMMENT '标签名',
`max_id` bigint NOT NULL DEFAULT '1' COMMENT '目前Segment的id',
`step` int NOT NULL COMMENT '步长',
`desc` varchar(256) NOT NULL DEFAULT '' COMMENT '描述',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `uk_biz_tag` (`biz_tag`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step,大致架构如下图所示:
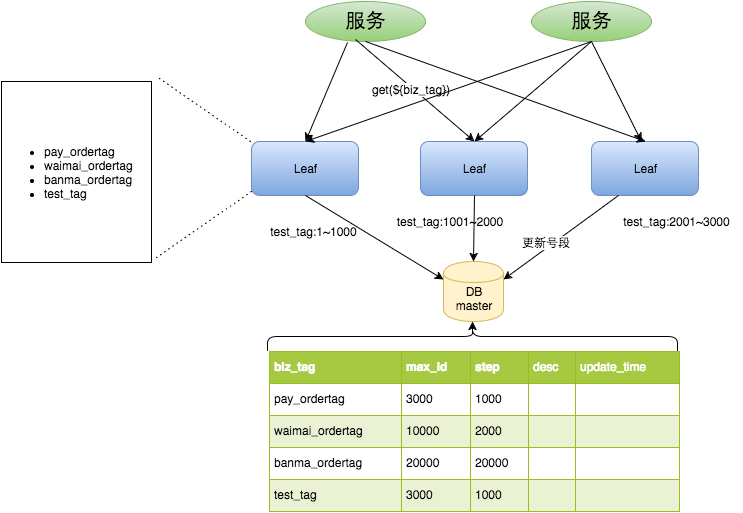
test_tag在第一台Leaf机器上是1~1000的号段,当这个号段用完时,会去加载另一个长度为step=1000的号段,假设另外两台号段都没有更新,这个时候第一台机器新加载的号段就应该是3001~4000。同时数据库对应的biz_tag这条数据的max_id会从3000被更新成4000,更新号段的SQL语句如下:
Begin
UPDATE table SET max_id=max_id+step WHERE biz_tag=xxx
SELECT tag, max_id, step FROM table WHERE biz_tag=xxx
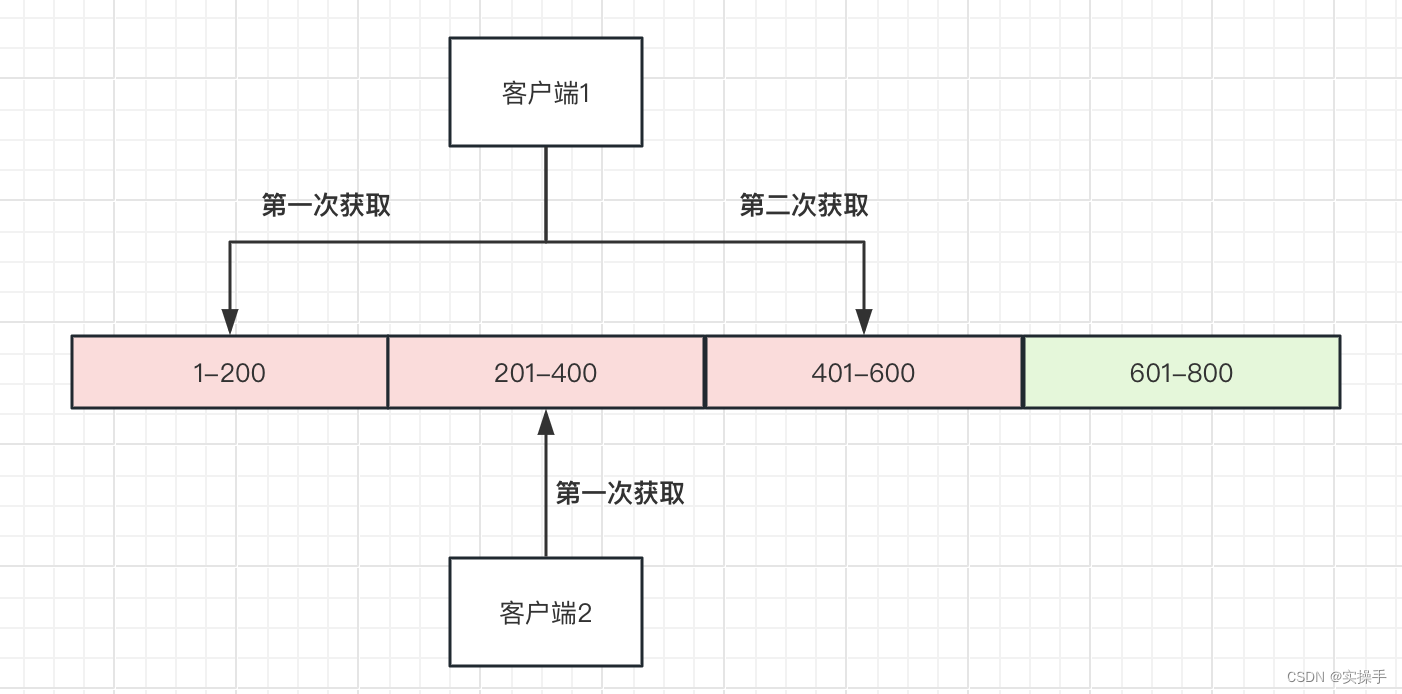
Commit双Buffer的优化
在当前号段消耗完去数据库请求下一次号段时,可能由于请求DB的网络和DB的性能问题导致获取时间过长或阻塞,影响服务的正常处理。为此,我们希望DB取号段的过程能够做到无阻塞,不需要在DB取号段的时候阻塞请求线程。这种场景可以采用预生成的思想来处理。即当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。详细实现如下图所示:

采用双buffer的方式,Leaf服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复。
-
每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响。
-
每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新。
源码分析
Leaf-segment模式的双Buffer实现定义了SegmentBuffer通过对变量segment数组下标的切换来处理数据的加载和获取。
public class SegmentBuffer {
private String key;
private Segment[] segments; //双buffer
private volatile int currentPos; //当前的使用的segment的index
private volatile boolean nextReady; //下一个segment是否处于可切换状态
private volatile boolean initOk; //是否初始化完成
private final AtomicBoolean threadRunning; //线程是否在运行中
private final ReadWriteLock lock;
}获取ID的核心方法在getIdFromSegmentBuffer。ID的获取、Buffer的预加载逻辑都在这个方法里面。为了线程安全方法内使用了volatile关键字、原子变量、锁等方式,为了提升性能使用了读写锁来提高并发。
public Result getIdFromSegmentBuffer(final SegmentBuffer buffer) {
while (true) {
//加读锁 不影响读并发
buffer.rLock().lock();
try {
final Segment segment = buffer.getCurrent();
/**
* 下一个segment未准备就绪
* 当前的segment已用10%
* 通过CAS方式争抢到可执行
* 满足这三个条件可以加载segment的数据
*/
if (!buffer.isNextReady() && (segment.getIdle() < 0.9 * segment.getStep()) && buffer.getThreadRunning().compareAndSet(false, true)) {
service.execute(new Runnable() {
@Override
public void run() {
//获取下一个segment
Segment next = buffer.getSegments()[buffer.nextPos()];
boolean updateOk = false;
try {
//查询数据库执行数据加载
updateSegmentFromDb(buffer.getKey(), next);
updateOk = true;
logger.info("update segment {} from db {}", buffer.getKey(), next);
} catch (Exception e) {
logger.warn(buffer.getKey() + " updateSegmentFromDb exception", e);
} finally {
if (updateOk) {
//更新正常的情况下加写锁
//此刻数据的读取也会阻塞
//等待处理完SegmentBuffer的状态更新
buffer.wLock().lock();
buffer.setNextReady(true);
buffer.getThreadRunning().set(false);
//处理完解锁
buffer.wLock().unlock();
} else {
//更新失败修改可执行状态 交给后面的来处理更新
buffer.getThreadRunning().set(false);
}
}
}
});
}
/**
* 获取下一个ID在可用的范围内(segment.getMax())直接返回
* 超过可用范围有两种场景
* 一种是正常的把当前的segment使用完了
* 另一种是在下一个segment加载期间 很高的并发把当前的segment使用完了
*/
long value = segment.getValue().getAndIncrement();
if (value < segment.getMax()) {
return new Result(value, Status.SUCCESS);
}
} finally {
buffer.rLock().unlock();
}
//休眠一段时间 为了等待上面第二种情况把下一个segment加载完
waitAndSleep(buffer);
/**
* 获取写锁 在这里排队的有两种情况
* 一种是正常流量
* 一种是更新下一个segment加载期间的并发流量
*/
buffer.wLock().lock();
try {
//第一个获取执行的线程 取不到可用的ID
//对于第一个线程它需要做的
//就是把获取ID的segment切换到刚刚加载完成的新segment
//后续的线程获取的当前segment 就是前面切换后的segment
final Segment segment = buffer.getCurrent();
long value = segment.getValue().getAndIncrement();
if (value < segment.getMax()) {
return new Result(value, Status.SUCCESS);
}
//判断标识 如果下一个segment已就绪就切换segment
//然后重新再走一遍获取ID逻辑
if (buffer.isNextReady()) {
//切换buffer的下标
buffer.switchPos();
buffer.setNextReady(false);
} else {
//两个segment都未就绪就是出现问题了
logger.error("Both two segments in {} are not ready!", buffer);
return new Result(EXCEPTION_ID_TWO_SEGMENTS_ARE_NULL, Status.EXCEPTION);
}
} finally {
buffer.wLock().unlock();
}
}
}高可用容灾
分布式ID做为重要的服务,为了保证高可用是一定要进行集群架构的。这部分我们可以直接参考美团给出的方案。
采用一主两从的方式,同时分机房部署,Master和Slave之间采用半同步方式同步数据。同时使用公司Atlas数据库中间件(已开源,改名为DBProxy)做主从切换。当然这种方案在一些情况会退化成异步模式,甚至在非常极端情况下仍然会造成数据不一致的情况,但是出现的概率非常小。如果你的系统要保证100%的数据强一致,可以选择使用“类Paxos算法”实现的强一致MySQL方案,如MySQL 5.7前段时间刚刚GA的MySQL Group Replication。但是运维成本和精力都会相应的增加,根据实际情况选型即可。
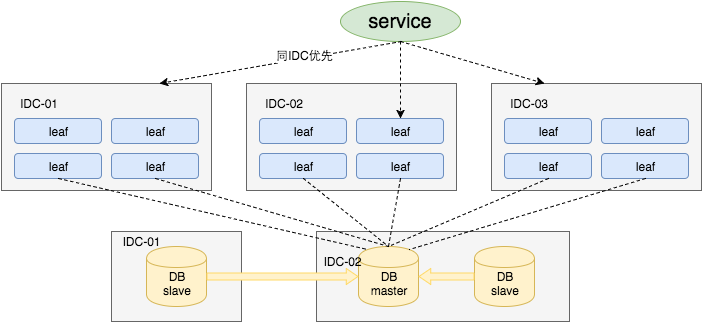
同时Leaf服务分IDC部署,内部的服务化框架是“MTthrift RPC”。服务调用的时候,根据负载均衡算法会优先调用同机房的Leaf服务。在该IDC内Leaf服务不可用的时候才会选择其他机房的Leaf服务。同时服务治理平台OCTO还提供了针对服务的过载保护、一键截流、动态流量分配等对服务的保护措施。
1.2 Leaf-snowflake模式
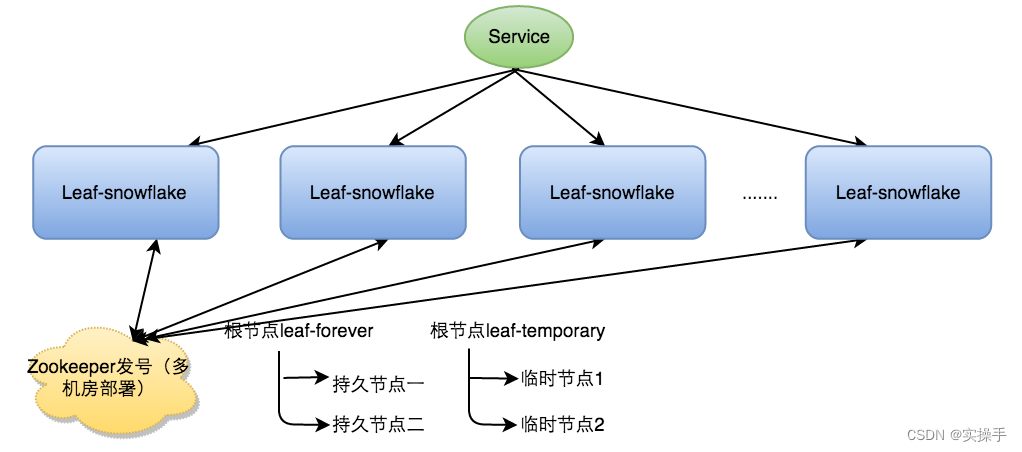
Leaf-snowflake方案完全沿用snowflake方案的bit位设计,即是“1+41+10+12”的方式组装ID号。对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。Leaf服务规模较大,动手配置成本太高。所以使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。Leaf-snowflake是按照下面几个步骤启动的:
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。
时钟问题的解决
如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题。Leaf-snowflake模式通过Zookeeper来解决时钟回拨问题。
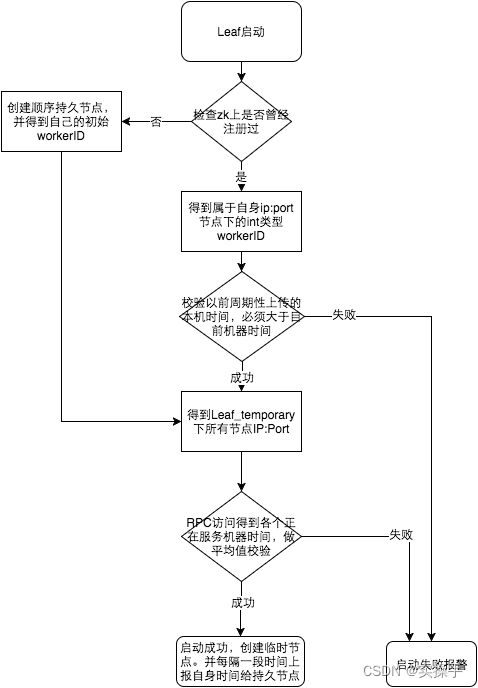
参见上图整个启动流程图,服务启动时首先检查自己是否写过ZooKeeper leaf_forever节点:
- 若写过,则用自身系统时间与leaf_forever/${self}节点记录时间做比较,若小于leaf_forever/${self}时间则认为机器时间发生了大步长回拨,服务启动失败并报警。
- 若未写过,证明是新服务节点,直接创建持久节点leaf_forever/${self}并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。
- 若abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点leaf_temporary/${self} 维持租约。
- 否则认为本机系统时间发生大步长偏移,启动失败并报警。
- 每隔一段时间(3s)上报自身系统时间写入leaf_forever/${self}。
由于强依赖时钟,对时间的要求比较敏感,在机器工作时NTP同步也会造成秒级别的回退,建议可以直接关闭NTP同步。要么在时钟回拨的时候直接不提供服务直接返回ERROR_CODE,等时钟追上即可。或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警,如下:
//发生了回拨,此刻时间小于上次发号时间
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
try {
//时间偏差大小小于5ms,则等待两倍时间
wait(offset << 1);//wait
timestamp = timeGen();
if (timestamp < lastTimestamp) {
//还是小于,抛异常并上报
throwClockBackwardsEx(timestamp);
}
} catch (InterruptedException e) {
throw e;
}
} else {
//throw
throwClockBackwardsEx(timestamp);
}
}
//分配ID 源码分析
Leaf-snowflake获取ID的方法并不复杂,主要的修正时间的逻辑是通过定时任务ScheduledUploadData来实现的。
public synchronized Result get(String key) {
//获取当前时间
long timestamp = timeGen();
//小于上一次获取的时间 说明时钟回拨了
if (timestamp < lastTimestamp) {
//计算差值
long offset = lastTimestamp - timestamp;
//小于5毫秒 等待一段时间再次获取
//大于5毫秒直接报错
if (offset <= 5) {
try {
//本机时间有问题时
//只能看定时任务ScheduledUploadData能不能修正时间
wait(offset << 1);
timestamp = timeGen();
//第二次获取还有问题就报错
if (timestamp < lastTimestamp) {
return new Result(-1, Status.EXCEPTION);
}
} catch (InterruptedException e) {
LOGGER.error("wait interrupted");
return new Result(-2, Status.EXCEPTION);
}
} else {
return new Result(-3, Status.EXCEPTION);
}
}
//当前时间等于上一次获取时间
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
//seq为0的时候表示当前毫秒的序列号用完了
//获取一下毫秒的时间
sequence = RANDOM.nextInt(100);
timestamp = tilNextMillis(lastTimestamp);
}
} else {
//如果是新的ms开始
sequence = RANDOM.nextInt(100);
}
//重置lastTimestamp的值
lastTimestamp = timestamp;
//根据雪花算法拼接ID
long id = ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence;
return new Result(id, Status.SUCCESS);
}2. UidGenerator
官网:GitHub - baidu/uid-generator: UniqueID generator
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。 在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
2.1 CachedUidGenerator
RingBuffer环形数组,数组每个元素成为一个slot。RingBuffer容量,默认为Snowflake算法中sequence最大值,且为2^N。可通过boostPower配置进行扩容,以提高RingBuffer 读写吞吐量。
Tail指针、Cursor指针用于环形数组上读写slot:
-
Tail指针
表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过rejectedPutBufferHandler指定PutRejectPolicy -
Cursor指针
表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定TakeRejectPolicy
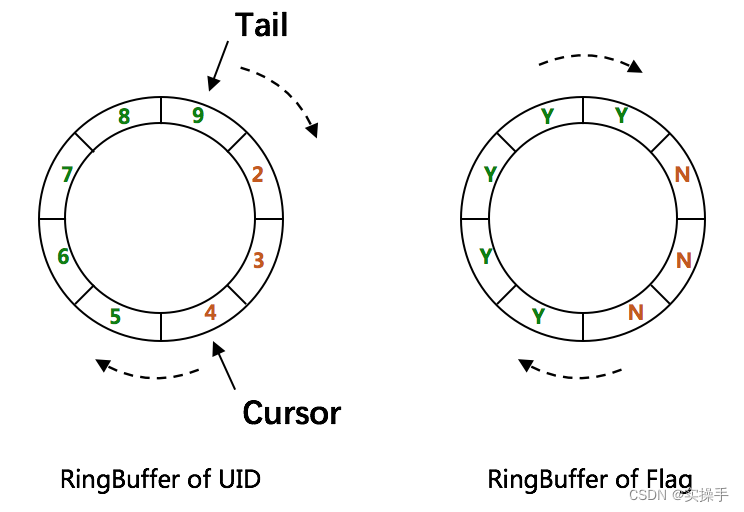
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)
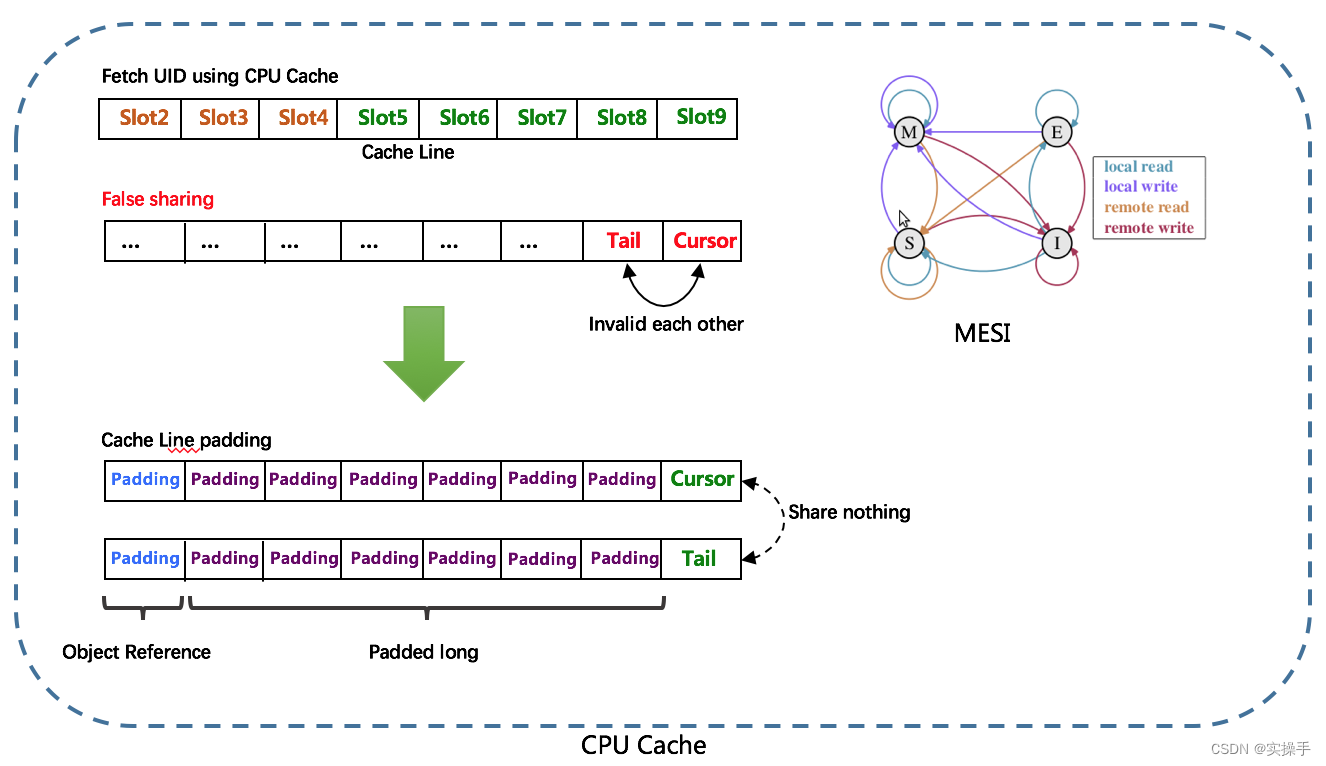
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine 补齐方式。
2.2 RingBuffer填充时机
-
初始化预填充
RingBuffer初始化时,预先填充满整个RingBuffer. -
即时填充
Take消费时,即时检查剩余可用slot量(tail-cursor),如小于设定阈值,则补全空闲slots。阈值可通过paddingFactor来进行配置,请参考Quick Start中CachedUidGenerator配置 -
周期填充
通过Schedule线程,定时补全空闲slots。可通过scheduleInterval配置,以应用定时填充功能,并指定Schedule时间间隔
2.3 源码分析
从上面官网的说明可以了解到UidGenerator解决时钟回退问题十分的巧妙。它是以一个基准时间为基础,计算当前时间(项目启动时获取之后每次进行累加)和基准时间的差值来当作雪花算法的时间戳部分。这样就避免了时钟回退问题因为根本就不需要在使用过程中获取时间戳了。
/** We can borrow UIDs from the future, here store the last second we have consumed */
private final PaddedAtomicLong lastSecond;
/** Customer epoch, unit as second. For example 2016-05-20 (ms: 1463673600000)*/
protected String epochStr = "2016-05-20";
protected long epochSeconds = TimeUnit.MILLISECONDS.toSeconds(1463673600000L);为了提高性能UidGenerator也提供了预生成的方式向RingBuffer加载ID。获取时直接从RingBuffer的缓存中获取。
/**
* Take an UID of the ring at the next cursor, this is a lock free operation by using atomic cursor<p>
*
* Before getting the UID, we also check whether reach the padding threshold,
* the padding buffer operation will be triggered in another thread<br>
* If there is no more available UID to be taken, the specified {@link RejectedTakeBufferHandler} will be applied<br>
*
* @return UID
* @throws IllegalStateException if the cursor moved back
*/
public long take() {
//当前获取的id的位置
long currentCursor = cursor.get();
//获取下一个id的位置 不能超过tail位置
long nextCursor = cursor.updateAndGet(old -> old == tail.get() ? old : old + 1);
//nextCursor一定在currentCursor前面
Assert.isTrue(nextCursor >= currentCursor, "Curosr can't move back");
//当前填充位置
long currentTail = tail.get();
//当前填充-当前获取 < 阈值 触发异步填充
if (currentTail - nextCursor < paddingThreshold) {
LOGGER.info("Reach the padding threshold:{}. tail:{}, cursor:{}, rest:{}", paddingThreshold, currentTail,
nextCursor, currentTail - nextCursor);
bufferPaddingExecutor.asyncPadding();
}
//代表当前获取的就是当前填充位置 没有多余ID了
if (nextCursor == currentCursor) {
rejectedTakeHandler.rejectTakeBuffer(this);
}
//获取ID的位置 - (sequence%bufferSize)计算插槽索引
int nextCursorIndex = calSlotIndex(nextCursor);
//flags[nextCursorIndex]的状态一定是可获取的
Assert.isTrue(flags[nextCursorIndex].get() == CAN_TAKE_FLAG, "Curosr not in can take status");
//获取ID
long uid = slots[nextCursorIndex];
//设置flags的nextCursorIndex 可添加
flags[nextCursorIndex].set(CAN_PUT_FLAG);
return uid;
}RingBuffer的核心加载方法在paddingBuffer。这部分源码不复杂主要逻辑先通过原子变量争抢执行,然后通过nextIdsForOneSecond获取生成的一批ID添加到RingBuffer。直到Tail追赶上Cursor结束添加。
/**
* Padding buffer fill the slots until to catch the cursor
*/
public void paddingBuffer() {
LOGGER.info("Ready to padding buffer lastSecond:{}. {}", lastSecond.get(), ringBuffer);
// 原子变量获取执行
if (!running.compareAndSet(false, true)) {
LOGGER.info("Padding buffer is still running. {}", ringBuffer);
return;
}
// fill the rest slots until to catch the cursor
boolean isFullRingBuffer = false;
while (!isFullRingBuffer) {
/**
* 获取生成的下一批ID
*/
List<Long> uidList = uidProvider.provide(lastSecond.incrementAndGet());
for (Long uid : uidList) {
isFullRingBuffer = !ringBuffer.put(uid);
//ringBuffer.put添加不成功代表tail已经赶上了Cursor结束添加
if (isFullRingBuffer) {
break;
}
}
}
//修改原子变量
running.compareAndSet(true, false);
LOGGER.info("End to padding buffer lastSecond:{}. {}", lastSecond.get(), ringBuffer);
}
/**
* Get the UIDs in the same specified second under the max sequence
*
* @param currentSecond
* @return UID list, size of {@link BitsAllocator#getMaxSequence()} + 1
*/
protected List<Long> nextIdsForOneSecond(long currentSecond) {
// Initialize result list size of (max sequence + 1)
int listSize = (int) bitsAllocator.getMaxSequence() + 1;
List<Long> uidList = new ArrayList<>(listSize);
// Allocate the first sequence of the second, the others can be calculated with the offset
long firstSeqUid = bitsAllocator.allocate(currentSecond - epochSeconds, workerId, 0L);
for (int offset = 0; offset < listSize; offset++) {
uidList.add(firstSeqUid + offset);
}
return uidList;
}2.4 伪共享问题的优化
伪共享的优化体现在PaddedAtomicLong中,通过数据填充的方式解决。代码中的注释做了很详细的说明。可以提升CPU缓存的使用效率,提升性能。
/**
* Represents a padded {@link AtomicLong} to prevent the FalseSharing problem<p>
*
* The CPU cache line commonly be 64 bytes, here is a sample of cache line after padding:<br>
* 64 bytes = 8 bytes (object reference) + 6 * 8 bytes (padded long) + 8 bytes (a long value)
*
* @author yutianbao
*/
public class PaddedAtomicLong extends AtomicLong {
private static final long serialVersionUID = -3415778863941386253L;
/** Padded 6 long (48 bytes) */
public volatile long p1, p2, p3, p4, p5, p6 = 7L;
/**
* Constructors from {@link AtomicLong}
*/
public PaddedAtomicLong() {
super();
}
public PaddedAtomicLong(long initialValue) {
super(initialValue);
}
/**
* To prevent GC optimizations for cleaning unused padded references
*/
public long sumPaddingToPreventOptimization() {
return p1 + p2 + p3 + p4 + p5 + p6;
}
}3. Tinyid
官网:https://github.com/didi/tinyid
Tinyid是用Java开发的一款分布式id生成系统,基于数据库号段算法实现。Tinyid扩展了leaf-segment算法,支持了多db(master),同时提供了java-client(sdk)使id生成本地化,获得了更好的性能与可用性。Tinyid在滴滴客服部门使用,均通过tinyid-client方式接入,每天生成亿级别的id。
3.1 增加多db支持
db只有一个master时,如果db不可用(down掉或者主从延迟比较大),则获取号段不可用。实际上我们可以支持多个db,比如2个db,A和B,我们获取号段可以随机从其中一台上获取。那么如果A,B都获取到了同一号段,我们怎么保证生成的id不重呢?tinyid是这么做的,让A只生成偶数id,B只生产奇数id,对应的db设计增加了两个字段,如下所示
| id | biz_type | max_id | step | delta | remainder | version |
|---|---|---|---|---|---|---|
| 1 | 1000 | 2000 | 1000 | 2 | 0 | 0 |
delta代表id每次的增量,remainder代表余数,例如可以将A,B都delta都设置2,remainder分别设置为0,1则,A的号段只生成偶数号段,B是奇数号段。 通过delta和remainder两个字段我们可以根据使用方的需求灵活设计db个数,同时也可以为使用方提供只生产类似奇数的id序列。
3.2 增加tinyid-client
使用http获取一个id,存在网络开销,是否可以本地生成id?为此我们提供了tinyid-client,我们可以向tinyid-server发送请求来获取可用号段,之后在本地构建双号段、id生成,如此id生成则变成纯本地操作,性能大大提升,因为本地有双号段缓存,则可以容忍tinyid-server一段时间的down掉,可用性也有了比较大的提升。
Tinyid的源码和Leaf-segment模式的源码差不多。理解了前面的逻辑分析Tinyid并不复杂。这里就不另作分析了。
四. 总结
本文主要介绍了分布式ID的用途、实现原理和各种方案的优化方式。目前的主流方案有两种:
一种是号段模式(美团的Leaf-segment模式和滴滴的Tinyid)均采用这种方案。这种方案的关键在于依赖数据库生成,需要保证数据库的高可用。另外号段模式的缺点在于生成的ID具有规律性,容易计算出每日大概的请求数、容易针对数据库进行恶意查询。
一种是雪花算法模式(美团的Leaf-snowflake模式和百度的UidGenerator)均采用这种方案。这种方案的关键在于如何解决时间回退问题。Leaf的解决办法是通过Zookeeper来定时检查并修正时间,而UidGenerator则是通过自增时间和基准时间的差值当作时间戳的方式来解决这个问题。
另外在这几个方案中我们也可以看到常见的性能优化思路:批处理和预生成。这是比较通用的思路在其他中间件中也比较常见。
最后感谢大家观看!如有帮助 感谢支持!
后续争取每周更新一篇
参考 :
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
https://github.com/didi/tinyid/wiki/tinyid%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D


















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











