




🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。
✨ 特惠福利:目前活动一折秒杀价!一次订阅,永久免费,所有后续更新内容均免费阅读!
全文目录:
📚 上期回顾
在上一篇文章《YOLOv8【注意力机制篇·第10节】Channel Attention通道维度选择 - 深度学习中的通道注意力机制详解!》中,我们深入探讨了通道注意力机制的核心原理与实现方法。我们学习了通道间关系建模、特征图权重分配策略、全局信息聚合技术,以及通道重要性排序算法。通过对SENet、ECA-Net、CA等经典方法的分析,我们理解了通道注意力如何通过自适应地重新校准通道特征响应来提升模型性能。通道注意力机制为我们今天要讨论的混合注意力机制奠定了重要基础。
1. 混合注意力机制概述与动机 🌟
1.1 混合注意力的基本概念
混合注意力机制(Mixed Attention)是现代深度学习中一种重要的注意力设计范式,其核心思想是将多种不同类型的注意力机制有机结合,通过协同工作来实现比单一注意力机制更强的特征表示能力。与传统的单一注意力方法不同,混合注意力机制能够同时捕获多个维度和多个尺度的重要性信息。
在计算机视觉任务中,不同类型的注意力机制各有其独特优势:空间注意力擅长识别"在哪里"关注,通道注意力善于确定"什么"是重要的,而时序注意力则关注"何时"的问题。混合注意力机制通过巧妙地组合这些互补的能力,构建出更加全面和强大的注意力系统。
1.2 设计动机与必要性
1.2.1 单一注意力的局限性
信息维度不完整:单一的空间注意力只能识别重要的空间位置,但无法判断哪些通道特征更重要;通道注意力能够选择重要特征,但缺乏空间定位能力。这种维度信息的不完整性限制了模型的表达能力。
任务适应性不足:不同的计算机视觉任务对注意力的需求存在显著差异。目标检测需要精确的空间定位,图像分类更依赖判别性特征选择,而视频理解则需要时序建模能力。单一注意力机制难以同时满足多样化的任务需求。
特征交互缺失:在实际的视觉处理过程中,空间位置、通道特征、时序信息等多个维度之间存在复杂的交互关系。单一注意力机制无法有效建模这些跨维度的依赖关系。
1.2.2 混合注意力的优势
多维度信息整合:通过融合不同类型的注意力,混合注意力机制能够在多个维度上同时进行信息选择和特征增强,实现更加全面的特征表示。
任务自适应能力:混合注意力机制能够根据具体任务的特点,自动调整不同注意力组件的权重,实现任务导向的注意力分配。
协同效应增强:不同注意力机制之间的协同作用往往能够产生"1+1>2"的效果,通过相互补充和增强,提升整体的性能表现。
1.3 混合注意力的发展历程
混合注意力机制的发展经历了从简单组合到深度融合的演进过程:
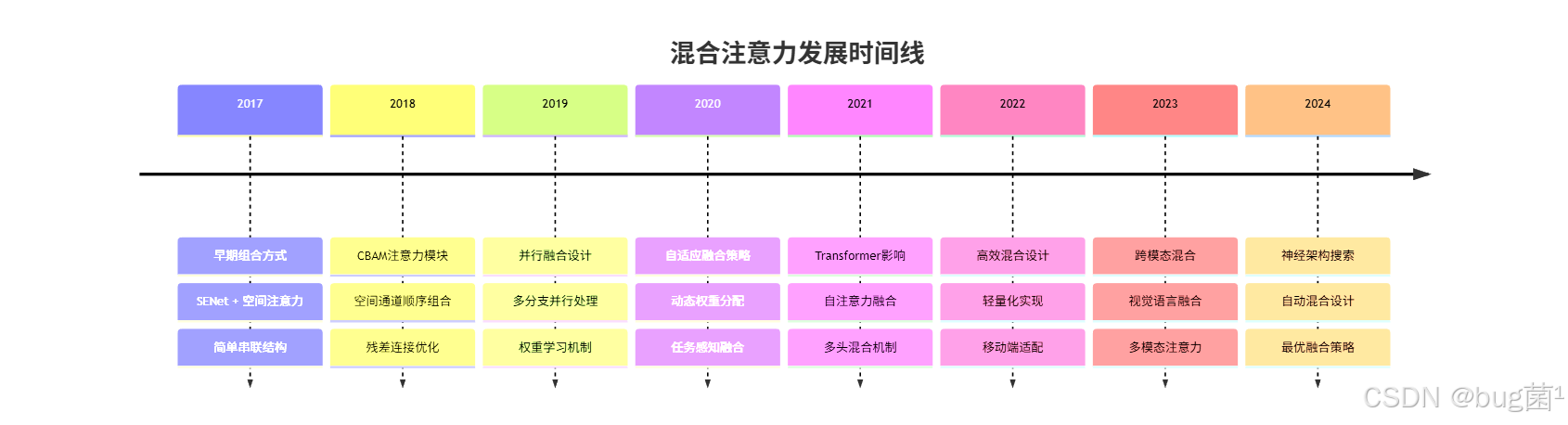
2. 多种注意力融合理论基础
2.1 注意力融合的数学框架
混合注意力机制的核心在于如何有效地融合多种注意力。设输入特征为 $F \in \mathbb{R}^{C \times H \times W}$,我们需要融合空间注意力 $A_s$、通道注意力 $A_c$ 和其他类型的注意力。
2.1.1 基础融合公式
最一般的混合注意力可以表示为:
MixedAttention ( F ) = G ( A 1 ( F ) , A 2 ( F ) , . . . , A n ( F ) ) ⊙ F \text{MixedAttention}(F) = \mathcal{G}(A_1(F), A_2(F), ..., A_n(F)) \odot F MixedAttention(F)=G(A1(F),A2(F),...,An(F))⊙F
其中:
- $A_i(F)$ 表示第 i i i 种注意力机制
- G ( ⋅ ) \mathcal{G}(\cdot) G(⋅) 是融合函数
- ⊙ \odot ⊙ 表示注意力应用操作
2.1.2 融合函数设计
常见的融合函数包括:
加权平均融合:
G
(
A
1
,
A
2
,
.
.
.
,
A
n
)
=
∑
i
=
1
n
w
i
⋅
A
i
\mathcal{G}(A_1, A_2, ..., A_n) = \sum_{i=1}^n w_i \cdot A_i
G(A1,A2,...,An)=i=1∑nwi⋅Ai
乘积融合:
G
(
A
1
,
A
2
,
.
.
.
,
A
n
)
=
∏
i
=
1
n
A
i
\mathcal{G}(A_1, A_2, ..., A_n) = \prod_{i=1}^n A_i
G(A1,A2,...,An)=i=1∏nAi
最大值融合:
G
(
A
1
,
A
2
,
.
.
.
,
A
n
)
=
max
(
A
1
,
A
2
,
.
.
.
,
A
n
)
\mathcal{G}(A_1, A_2, ..., A_n) = \max(A_1, A_2, ..., A_n)
G(A1,A2,...,An)=max(A1,A2,...,An)
学习型融合:
G
(
A
1
,
A
2
,
.
.
.
,
A
n
)
=
σ
(
∑
i
=
1
n
W
i
⋅
A
i
+
b
)
\mathcal{G}(A_1, A_2, ..., A_n) = \sigma(\sum_{i=1}^n W_i \cdot A_i + b)
G(A1,A2,...,An)=σ(i=1∑nWi⋅Ai+b)
2.2 信息论视角下的融合分析
2.2.1 互信息最大化
从信息论角度,混合注意力的目标是最大化融合后注意力与任务标签之间的互信息:
max I ( G ( A 1 , A 2 , . . . , A n ) ; Y ) \max I(\mathcal{G}(A_1, A_2, ..., A_n); Y) maxI(G(A1,A2,...,An);Y)
同时最小化不同注意力机制之间的冗余信息:
min ∑ i ≠ j I ( A i ; A j ) \min \sum_{i \neq j} I(A_i; A_j) mini=j∑I(Ai;Aj)
2.2.2 信息瓶颈原理
混合注意力机制需要在信息保留和压缩之间找到平衡:
max I ( G ( A 1 , . . . , A n ) ; Y ) − β I ( G ( A 1 , . . . , A n ) ; F ) \max I(\mathcal{G}(A_1, ..., A_n); Y) - \beta I(\mathcal{G}(A_1, ..., A_n); F) maxI(G(A1,...,An);Y)−βI(G(A1,...,An);F)
其中 β \beta β 控制压缩程度,确保融合后的注意力既保留任务相关信息,又去除冗余。
2.3 多维度注意力的几何解释
2.3.1 注意力空间的几何结构
将不同类型的注意力视为高维空间中的向量,混合注意力的融合过程可以理解为在这个注意力空间中寻找最优的表示点。
空间注意力向量:
a
⃗
_
s
∈
R
H
W
\vec{a}\_s \in \mathbb{R}^{HW}
a_s∈RHW
通道注意力向量:
a
⃗
∗
c
∈
R
C
\vec{a}*c \in \mathbb{R}^{C}
a∗c∈RC
融合注意力向量:
a
⃗
∗
m
i
x
=
f
(
a
⃗
_
s
,
a
⃗
_
c
)
\vec{a}*{mix} = f(\vec{a}\_s, \vec{a}\_c)
a∗mix=f(a_s,a_c)
2.3.2 优化目标的几何理解
混合注意力的优化过程可以视为在注意力空间中寻找能够最大化任务性能的方向:
a ⃗ o p t = arg max a ⃗ ⟨ a ⃗ , g ⃗ t a s k ⟩ \vec{a}_{opt} = \arg\max_{\vec{a}} \langle \vec{a}, \vec{g}_{task} \rangle aopt=argamax⟨a,gtask⟩
其中 g ⃗ t a s k \vec{g}_{task} gtask 是任务特定的梯度方向。
3. 空间通道联合优化策略 🎯
3.1 串行融合架构
串行融合是最直观的混合注意力设计方式,通过依次应用不同类型的注意力机制来实现特征增强。
3.1.1 经典CBAM架构
import torch
import torch.nn as nn
import torch.nn.functional as F
class ChannelAttention(nn.Module):
"""
通道注意力模块
使用全局平均池化和最大池化聚合空间信息
"""
def __init__(self, in_channels, reduction=16):
super(ChannelAttention, self).__init__()
# 降维层,减少参数量
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction, in_channels, bias=False)
)
def forward(self, x):
"""
前向传播
Args:
x: 输入特征图 [B, C, H, W]
Returns:
output: 通道注意力加权后的特征图
"""
b, c, h, w = x.size()
# 全局平均池化 [B, C, 1, 1] -> [B, C]
avg_pool = F.adaptive_avg_pool2d(x, 1).view(b, c)
avg_out = self.fc(avg_pool)
# 全局最大池化 [B, C, 1, 1] -> [B, C]
max_pool = F.adaptive_max_pool2d(x, 1).view(b, c)
max_out = self.fc(max_pool)
# 融合并激活 [B, C] -> [B, C, 1, 1]
channel_att = torch.sigmoid(avg_out + max_out).unsqueeze(2).unsqueeze(3)
return x * channel_att
class SpatialAttention(nn.Module):
"""
空间注意力模块
通过通道维度的池化操作生成空间注意力图
"""
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
padding = kernel_size // 2
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size,
padding=padding, bias=False)
def forward(self, x):
"""
前向传播
Args:
x: 输入特征图 [B, C, H, W]
Returns:
output: 空间注意力加权后的特征图
"""
# 通道维度平均池化 [B, C, H, W] -> [B, 1, H, W]
avg_out = torch.mean(x, dim=1, keepdim=True)
# 通道维度最大池化 [B, C, H, W] -> [B, 1, H, W]
max_out, _ = torch.max(x, dim=1, keepdim=True)
# 连接池化结果 [B, 2, H, W]
concat = torch.cat([avg_out, max_out], dim=1)
# 生成空间注意力图 [B, 1, H, W]
spatial_att = torch.sigmoid(self.conv(concat))
return x * spatial_att
class CBAMBlock(nn.Module):
"""
CBAM (Convolutional Block Attention Module)
串行组合通道注意力和空间注意力
"""
def __init__(self, in_channels, reduction=16, kernel_size=7):
super(CBAMBlock, self).__init__()
self.channel_attention = ChannelAttention(in_channels, reduction)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
"""
前向传播:先通道注意力,再空间注意力
"""
# 第一步:应用通道注意力
x = self.channel_attention(x)
# 第二步:应用空间注意力
x = self.spatial_attention(x)
return x
3.1.2 改进的串行架构
class EnhancedSerialMixedAttention(nn.Module):
"""
增强版串行混合注意力
增加残差连接和中间监督
"""
def __init__(self, in_channels, reduction=16):
super(EnhancedSerialMixedAttention, self).__init__()
# 通道注意力分支
self.channel_branch = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // reduction, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction, in_channels, 1),
nn.Sigmoid()
)
# 空间注意力分支
self.spatial_branch = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction, 1),
nn.BatchNorm2d(in_channels // reduction),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction, 1, 3, padding=1),
nn.Sigmoid()
)
# 特征融合层
self.fusion_layer = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
)
# 残差权重
self.residual_weight = nn.Parameter(torch.tensor(0.1))
def forward(self, x):
"""
增强版前向传播
"""
identity = x
# 第一阶段:通道注意力
channel_att = self.channel_branch(x)
x_channel = x * channel_att
# 第二阶段:空间注意力
spatial_att = self.spatial_branch(x_channel)
x_spatial = x_channel * spatial_att
# 特征融合
x_fused = self.fusion_layer(x_spatial)
# 残差连接
output = x_fused + self.residual_weight * identity
return output, {
'channel_attention': channel_att,
'spatial_attention': spatial_att,
'residual_weight': self.residual_weight
}
3.2 并行融合架构
并行融合架构允许不同类型的注意力机制同时处理输入特征,然后将结果进行融合。
3.2.1 基础并行设计
class ParallelMixedAttention(nn.Module):
"""
并行混合注意力模块
同时计算多种注意力并进行融合
"""
def __init__(self, in_channels, reduction=16):
super(ParallelMixedAttention, self).__init__()
# 通道注意力分支
self.channel_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // reduction, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction, in_channels, 1),
nn.Sigmoid()
)
# 空间注意力分支
self.spatial_att = nn.Sequential(
nn.Conv2d(2, 1, kernel_size=7, padding=3),
nn.Sigmoid()
)
# 自注意力分支
self.self_att = SelfAttentionModule(in_channels, reduction)
# 融合权重学习
self.fusion_weights = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, 3, 1), # 3个注意力分支
nn.Softmax(dim=1)
)
def forward(self, x):
"""
并行计算多种注意力
"""
# 并行计算各种注意力
# 通道注意力
channel_att = self.channel_att(x)
channel_features = x * channel_att
# 空间注意力
avg_spatial = torch.mean(x, dim=1, keepdim=True)
max_spatial, _ = torch.max(x, dim=1, keepdim=True)
spatial_input = torch.cat([avg_spatial, max_spatial], dim=1)
spatial_att = self.spatial_att(spatial_input)
spatial_features = x * spatial_att
# 自注意力
self_features = self.self_att(x)
# 学习融合权重
fusion_weights = self.fusion_weights(x) # [B, 3, 1, 1]
w_channel = fusion_weights[:, 0:1, :, :]
w_spatial = fusion_weights[:, 1:2, :, :]
w_self = fusion_weights[:, 2:3, :, :]
# 加权融合
output = (w_channel * channel_features +
w_spatial * spatial_features +
w_self * self_features)
return output, {
'channel_attention': channel_att,
'spatial_attention': spatial_att,
'fusion_weights': fusion_weights
}
class SelfAttentionModule(nn.Module):
"""
自注意力模块
"""
def __init__(self, in_channels, reduction=8):
super(SelfAttentionModule, self).__init__()
self.query = nn.Conv2d(in_channels, in_channels // reduction, 1)
self.key = nn.Conv2d(in_channels, in_channels // reduction, 1)
self.value = nn.Conv2d(in_channels, in_channels, 1)
self.scale = (in_channels // reduction) ** -0.5
def forward(self, x):
"""
自注意力计算
"""
B, C, H, W = x.shape
# 生成 Q, K, V
q = self.query(x).view(B, -1, H * W).permute(0, 2, 1) # [B, HW, C//r]
k = self.key(x).view(B, -1, H * W) # [B, C//r, HW]
v = self.value(x).view(B, -1, H * W).permute(0, 2, 1) # [B, HW, C]
# 计算注意力
attention = torch.matmul(q, k) * self.scale # [B, HW, HW]
attention = F.softmax(attention, dim=-1)
# 应用注意力
out = torch.matmul(attention, v) # [B, HW, C]
out = out.permute(0, 2, 1).view(B, C, H, W)
return out + x # 残差连接
3.3 递归融合架构
递归融合通过多层级的注意力融合来实现更深层次的特征交互。
3.3.1 层次化递归设计
class RecursiveMixedAttention(nn.Module):
"""
递归混合注意力模块
通过多层递归实现深度特征融合
"""
def __init__(self, in_channels, num_levels=3, reduction=16):
super(RecursiveMixedAttention, self).__init__()
self.num_levels = num_levels
self.attention_layers = nn.ModuleList()
# 构建多层注意力
for i in range(num_levels):
layer = RecursiveAttentionLayer(
in_channels,
reduction=reduction,
level=i
)
self.attention_layers.append(layer)
# 层间融合
self.level_fusion = nn.Sequential(
nn.Conv2d(in_channels * num_levels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
"""
递归注意力计算
"""
level_outputs = []
current_input = x
for i, attention_layer in enumerate(self.attention_layers):
# 当前层注意力计算
level_output, attention_info = attention_layer(current_input)
level_outputs.append(level_output)
# 更新下一层输入(递归特性)
if i < self.num_levels - 1:
current_input = level_output
# 多层级融合
concatenated = torch.cat(level_outputs, dim=1)
final_output = self.level_fusion(concatenated)
return final_output + x # 全局残差连接
class RecursiveAttentionLayer(nn.Module):
"""
递归注意力层
单层的混合注意力计算
"""
def __init__(self, in_channels, reduction=16, level=0):
super(RecursiveAttentionLayer, self).__init__()
self.level = level
# 通道注意力(权重随层级变化)
self.channel_weight = 1.0 - 0.1 * level
self.channel_att = ChannelAttention(in_channels, reduction)
# 空间注意力(权重随层级变化)
self.spatial_weight = 0.5 + 0.1 * level
self.spatial_att = SpatialAttention()
# 层级特定的特征变换
self.level_transform = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, padding=1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
"""
单层递归注意力
"""
# 层级特定变换
transformed = self.level_transform(x)
# 加权混合注意力
channel_out = self.channel_att(transformed)
spatial_out = self.spatial_att(transformed)
# 层级自适应融合
mixed_output = (self.channel_weight * channel_out +
self.spatial_weight * spatial_out)
return mixed_output, {
'level': self.level,
'channel_weight': self.channel_weight,
'spatial_weight': self.spatial_weight
}
4. 注意力权重平衡机制 ⚖️
4.1 静态权重分配策略
静态权重分配是最简单的平衡机制,通过预定义的权重来控制不同注意力机制的贡献。
4.1.1 固定权重方案
class StaticWeightMixedAttention(nn.Module):
"""
静态权重混合注意力
使用预定义权重平衡不同注意力机制
"""
def __init__(self, in_channels, channel_weight=0.6, spatial_weight=0.4):
super(StaticWeightMixedAttention, self).__init__()
# 确保权重之和为1
total_weight = channel_weight + spatial_weight
self.channel_weight = channel_weight / total_weight
self.spatial_weight = spatial_weight / total_weight
# 注意力模块
self.channel_attention = ChannelAttention(in_channels)
self.spatial_attention = SpatialAttention()
# 特征融合
self.fusion_conv = nn.Conv2d(in_channels, in_channels, 1)
def forward(self, x):
"""
静态权重融合
"""
# 计算各种注意力
channel_att = self.channel_attention(x)
spatial_att = self.spatial_attention(x)
# 静态权重融合
mixed_features = (self.channel_weight * (x * channel_att) +
self.spatial_weight * (x * spatial_att))
# 特征融合
output = self.fusion_conv(mixed_features)
return output + x # 残差连接
4.1.2 任务特定权重
class TaskSpecificMixedAttention(nn.Module):
"""
任务特定混合注意力
根据不同任务调整注意力权重
"""
def __init__(self, in_channels, task_type='detection'):
super(TaskSpecificMixedAttention, self).__init__()
self.task_type = task_type
# 任务特定权重配置
if task_type == 'classification':
self.weights = {'channel': 0.8, 'spatial': 0.2}
elif task_type == 'detection':
self.weights = {'channel': 0.5, 'spatial': 0.5}
elif task_type == 'segmentation':
self.weights = {'channel': 0.3, 'spatial': 0.7}
else:
self.weights = {'channel': 0.5, 'spatial': 0.5}
# 注意力模块
self.channel_attention = ChannelAttention(in_channels)
self.spatial_attention = SpatialAttention()
# 任务特定的特征增强
self.task_enhancement = self._build_task_enhancement(in_channels, task_type)
def _build_task_enhancement(self, in_channels, task_type):
"""
构建任务特定的特征增强模块
"""
if task_type == 'classification':
# 分类任务:全局特征聚合
return nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels, 1),
nn.ReLU(inplace=True)
)
elif task_type == 'detection':
# 检测任务:多尺度特征
return nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, padding=1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
)
elif task_type == 'segmentation':
# 分割任务:空间细节保持
return nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, in_channels, 3, padding=1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
)
else:
return nn.Identity()
def forward(self, x):
"""
任务特定前向传播
"""
# 基础注意力计算
channel_out = self.channel_attention(x)
spatial_out = self.spatial_attention(x)
# 任务特定权重融合
mixed_output = (self.weights['channel'] * channel_out +
self.weights['spatial'] * spatial_out)
# 任务特定增强
enhanced_output = self.task_enhancement(mixed_output)
return enhanced_output + x
4.2 动态权重学习机制
动态权重学习允许模型根据输入内容自适应地调整不同注意力机制的权重。
4.2.1 内容感知权重生成
class DynamicWeightMixedAttention(nn.Module):
"""
动态权重混合注意力
根据输入内容自适应调整权重
"""
def __init__(self, in_channels, num_attention_types=3):
super(DynamicWeightMixedAttention, self).__init__()
self.num_attention_types = num_attention_types
# 注意力模块
self.channel_attention = ChannelAttention(in_channels)
self.spatial_attention = SpatialAttention()
self.self_attention = SelfAttentionModule(in_channels)
# 权重生成网络
self.weight_generator = ContentAwareWeightGenerator(
in_channels, num_attention_types
)
# 特征融合网络
self.feature_fusion = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
"""
动态权重前向传播
"""
# 计算各种注意力特征
channel_features = self.channel_attention(x)
spatial_features = self.spatial_attention(x)
self_features = self.self_attention(x)
# 生成动态权重
dynamic_weights = self.weight_generator(x) # [B, 3, 1, 1]
# 动态加权融合
weighted_sum = (dynamic_weights[:, 0:1] * channel_features +
dynamic_weights[:, 1:2] * spatial_features +
dynamic_weights[:, 2:3] * self_features)
# 特征融合
fused_features = self.feature_fusion(weighted_sum)
return fused_features + x, {
'dynamic_weights': dynamic_weights,
'attention_features': {
'channel': channel_features,
'spatial': spatial_features,
'self': self_features
}
}
class ContentAwareWeightGenerator(nn.Module):
"""
内容感知权重生成器
根据输入特征的统计特性生成权重
"""
def __init__(self, in_channels, num_weights, reduction=16):
super(ContentAwareWeightGenerator, self).__init__()
# 全局特征提取
self.global_feature = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // reduction, 1),
nn.ReLU(inplace=True)
)
# 局部特征提取
self.local_feature = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction, 3, padding=1),
nn.BatchNorm2d(in_channels // reduction),
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d(1)
)
# 权重预测器
self.weight_predictor = nn.Sequential(
nn.Conv2d(2 * (in_channels // reduction), in_channels // reduction, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction, num_weights, 1),
nn.Softmax(dim=1) # 确保权重和为1
)
def forward(self, x):
"""
生成内容感知权重
"""
# 提取全局和局部特征
global_feat = self.global_feature(x)
local_feat = self.local_feature(x)
# 融合特征
combined_feat = torch.cat([global_feat, local_feat], dim=1)
# 预测权重
weights = self.weight_predictor(combined_feat)
return weights
4.2.2 强化学习权重优化
class RLBasedWeightOptimizer(nn.Module):
"""
基于强化学习的权重优化器
通过策略梯度学习最优权重分配
"""
def __init__(self, in_channels, num_attention_types=3):
super(RLBasedWeightOptimizer, self).__init__()
# 状态编码器
self.state_encoder = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(in_channels, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 64),
nn.ReLU(inplace=True)
)
# 策略网络
self.policy_network = nn.Sequential(
nn.Linear(64, 32),
nn.ReLU(inplace=True),
nn.Linear(32, num_attention_types),
nn.Softmax(dim=1)
)
# 价值网络
self.value_network = nn.Sequential(
nn.Linear(64, 32),
nn.ReLU(inplace=True),
nn.Linear(32, 1)
)
# 经验缓冲区
self.experience_buffer = []
self.max_buffer_size = 1000
def forward(self, x, training=True):
"""
RL权重生成
"""
# 编码当前状态
state = self.state_encoder(x)
# 生成动作概率(权重分布)
action_probs = self.policy_network(state)
# 估计状态价值
state_value = self.value_network(state)
if training:
# 训练模式:采样动作
action_dist = torch.distributions.Categorical(action_probs)
action = action_dist.sample()
log_prob = action_dist.log_prob(action)
return action_probs, log_prob, state_value
else:
# 推理模式:使用最优策略
return action_probs
def update_policy(self, rewards, log_probs, values):
"""
更新策略网络
"""
# 计算优势函数
advantages = rewards - values
# 策略梯度损失
policy_loss = -(log_probs * advantages.detach()).mean()
# 价值函数损失
value_loss = F.mse_loss(values, rewards)
# 总损失
total_loss = policy_loss + 0.5 * value_loss
return total_loss
4.3 自适应权重平衡
自适应权重平衡机制能够根据训练过程中的性能反馈自动调整权重分配策略。
4.3.1 性能反馈驱动的权重调整
class AdaptiveWeightBalancer(nn.Module):
"""
自适应权重平衡器
根据性能反馈调整注意力权重
"""
def __init__(self, in_channels, num_attention_types=3, adaptation_rate=0.01):
super(AdaptiveWeightBalancer, self).__init__()
self.adaptation_rate = adaptation_rate
self.num_attention_types = num_attention_types
# 初始权重(可学习参数)
self.base_weights = nn.Parameter(
torch.ones(num_attention_types) / num_attention_types
)
# 性能历史记录
self.performance_history = []
self.weight_history = []
# 权重调整网络
self.weight_adjuster = nn.Sequential(
nn.Linear(num_attention_types + 1, 32), # +1 for performance
nn.ReLU(inplace=True),
nn.Linear(32, num_attention_types),
nn.Tanh() # 输出调整量
)
def forward(self, attention_outputs, current_performance=None):
"""
自适应权重计算
Args:
attention_outputs: 各种注意力的输出列表
current_performance: 当前性能指标
"""
# 获取当前权重
current_weights = F.softmax(self.base_weights, dim=0)
# 如果提供了性能信息,进行权重调整
if current_performance is not None and len(self.performance_history) > 0:
# 计算性能变化
performance_change = current_performance - self.performance_history[-1]
# 准备调整输入
adjust_input = torch.cat([
current_weights,
torch.tensor([performance_change], device=current_weights.device)
])
# 计算权重调整量
weight_adjustment = self.weight_adjuster(adjust_input)
# 更新基础权重
with torch.no_grad():
self.base_weights.data += self.adaptation_rate * weight_adjustment
self.base_weights.data = torch.clamp(self.base_weights.data, -2, 2)
# 记录历史
self.performance_history.append(current_performance)
self.weight_history.append(current_weights.clone().detach())
# 限制历史长度
if len(self.performance_history) > 100:
self.performance_history.pop(0)
self.weight_history.pop(0)
# 计算最终权重
final_weights = F.softmax(self.base_weights, dim=0)
# 加权融合注意力输出
weighted_output = sum(w * output for w, output in
zip(final_weights, attention_outputs))
return weighted_output, final_weights
5. 串行与并行融合架构 🔀
5.1 串行融合的深度分析
串行融合架构通过按顺序应用不同的注意力机制,每个后续的注意力机制都在前一个的基础上进行优化。这种设计具有明确的层次结构和渐进式的特征增强效果。
5.1.1 串行融合的信息流动
在串行架构中,信息流动呈现明显的层次性特征:
第一阶段:通常应用通道注意力,主要目的是选择最重要的特征通道,抑制不相关的特征响应。
第二阶段:在已经过通道选择的特征基础上应用空间注意力,精确定位重要的空间区域。
第三阶段:可选的时序或其他维度的注意力机制,进一步细化特征表示。
5.1.2 串行融合的优势与局限
优势分析:
- 计算效率高:每个阶段的计算相对独立,便于优化和并行化
- 解释性强:可以清晰地观察每个阶段的贡献和效果
- 稳定性好:渐进式的特征增强避免了剧烈的特征变化
局限性分析:
- 信息传递损失:每个阶段可能会丢失一些对后续阶段有用的信息
- 优化困难:前面阶段的错误会传播到后续阶段
- 灵活性不足:固定的处理顺序可能不适合所有任务
5.2 并行融合的设计原理
并行融合架构允许多种注意力机制同时处理输入特征,然后通过某种融合策略将结果合并。这种设计能够保留更多的原始信息,并允许不同注意力机制之间的相互补充。
5.2.1 高级并行融合架构
class AdvancedParallelMixedAttention(nn.Module):
"""
高级并行混合注意力
支持多种融合策略和注意力类型
"""
def __init__(self, in_channels, fusion_strategy='adaptive'):
super(AdvancedParallelMixedAttention, self).__init__()
self.fusion_strategy = fusion_strategy
# 多种注意力机制
self.attention_modules = nn.ModuleDict({
'channel': ChannelAttention(in_channels),
'spatial': SpatialAttention(),
'self': SelfAttentionModule(in_channels),
'global': GlobalAttention(in_channels),
'local': LocalAttention(in_channels)
})
# 融合策略选择
if fusion_strategy == 'adaptive':
self.fusion_module = AdaptiveFusionModule(in_channels, len(self.attention_modules))
elif fusion_strategy == 'concatenate':
self.fusion_module = ConcatenateFusionModule(in_channels, len(self.attention_modules))
elif fusion_strategy == 'gated':
self.fusion_module = GatedFusionModule(in_channels, len(self.attention_modules))
else:
self.fusion_module = SimpleFusionModule()
# 特征增强
self.feature_enhancement = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, padding=1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels)
)
def forward(self, x):
"""
并行注意力计算
"""
# 并行计算所有注意力
attention_outputs = {}
for name, module in self.attention_modules.items():
if name in ['channel', 'spatial']:
# 传统注意力:返回加权特征
attention_outputs[name] = module(x)
else:
# 其他注意力:可能有不同的输出格式
attention_outputs[name] = module(x)
# 融合所有注意力输出
fused_features = self.fusion_module(attention_outputs, x)
# 特征增强
enhanced_features = self.feature_enhancement(fused_features)
# 残差连接
output = enhanced_features + x
return output, attention_outputs
class AdaptiveFusionModule(nn.Module):
"""
自适应融合模块
根据特征统计动态选择融合权重
"""
def __init__(self, in_channels, num_modules):
super(AdaptiveFusionModule, self).__init__()
self.num_modules = num_modules
# 特征统计计算器
self.feature_stats = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // 4, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // 4, num_modules, 1),
nn.Softmax(dim=1)
)
# 注意力质量评估器
self.quality_assessor = AttentionQualityAssessor(in_channels)
def forward(self, attention_outputs, original_features):
"""
自适应融合计算
"""
# 计算融合权重
fusion_weights = self.feature_stats(original_features)
# 评估各注意力质量
quality_scores = {}
for name, output in attention_outputs.items():
quality_scores[name] = self.quality_assessor(output, original_features)
# 质量调制的权重
adjusted_weights = []
for i, (name, _) in enumerate(attention_outputs.items()):
weight = fusion_weights[:, i:i+1, :, :] * quality_scores[name]
adjusted_weights.append(weight)
# 重新归一化权重
total_weight = sum(adjusted_weights)
normalized_weights = [w / (total_weight + 1e-8) for w in adjusted_weights]
# 加权融合
fused_output = sum(w * output for w, (_, output) in
zip(normalized_weights, attention_outputs.items()))
return fused_output
class AttentionQualityAssessor(nn.Module):
"""
注意力质量评估器
评估注意力输出的质量分数
"""
def __init__(self, in_channels):
super(AttentionQualityAssessor, self).__init__()
# 质量评估网络
self.quality_net = nn.Sequential(
nn.Conv2d(in_channels * 2, in_channels, 3, padding=1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, 1, 1),
nn.Sigmoid()
)
def forward(self, attention_output, original_features):
"""
评估注意力质量
"""
# 连接原始特征和注意力输出
combined = torch.cat([original_features, attention_output], dim=1)
# 计算质量分数
quality_score = self.quality_net(combined)
return quality_score
5.3 混合融合架构
混合融合架构结合了串行和并行的优势,在不同的网络层级采用不同的融合策略。
5.3.1 层次化混合融合
class HierarchicalMixedFusion(nn.Module):
"""
层次化混合融合
在不同层级采用不同的融合策略
"""
def __init__(self, in_channels, num_levels=3):
super(HierarchicalMixedFusion, self).__init__()
self.num_levels = num_levels
self.fusion_levels = nn.ModuleList()
for level in range(num_levels):
if level == 0:
# 底层:并行融合,保留详细信息
fusion_layer = ParallelFusionLayer(in_channels, level)
elif level == num_levels - 1:
# 顶层:串行融合,集成抽象特征
fusion_layer = SerialFusionLayer(in_channels, level)
else:
# 中层:混合融合
fusion_layer = HybridFusionLayer(in_channels, level)
self.fusion_levels.append(fusion_layer)
# 跨层级连接
self.cross_level_connections = CrossLevelConnections(in_channels, num_levels)
def forward(self, x):
"""
层次化融合前向传播
"""
level_outputs = []
current_input = x
# 逐层处理
for level, fusion_layer in enumerate(self.fusion_levels):
level_output = fusion_layer(current_input)
level_outputs.append(level_output)
# 为下一层准备输入
if level < self.num_levels - 1:
current_input = level_output
# 跨层级信息整合
integrated_output = self.cross_level_connections(level_outputs)
return integrated_output + x # 全局残差连接
class CrossLevelConnections(nn.Module):
"""
跨层级连接模块
整合不同层级的信息
"""
def __init__(self, in_channels, num_levels):
super(CrossLevelConnections, self).__init__()
# 层级权重学习
self.level_weights = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels * num_levels, in_channels // 4, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // 4, num_levels, 1),
nn.Softmax(dim=1)
)
# 特征对齐
self.feature_alignment = nn.Conv2d(in_channels * num_levels, in_channels, 1)
def forward(self, level_outputs):
"""
跨层级连接计算
"""
# 连接所有层级输出
concatenated = torch.cat(level_outputs, dim=1)
# 学习层级权重
weights = self.level_weights(concatenated)
# 加权融合
weighted_sum = sum(w.unsqueeze(1) * output for w, output in
zip(weights.split(1, dim=1), level_outputs))
# 特征对齐
aligned_features = self.feature_alignment(concatenated)
# 组合加权融合和特征对齐
final_output = 0.7 * weighted_sum + 0.3 * aligned_features
return final_output
6. 自适应融合权重学习 🧠
6.1 元学习驱动的权重优化
元学习能够帮助混合注意力机制快速适应新的任务和数据分布,通过学习如何学习来优化融合权重。
6.1.1 基于MAML的权重学习
class MAMLBasedWeightLearning(nn.Module):
"""
基于MAML的权重学习
通过元学习快速适应新任务的权重分配
"""
def __init__(self, in_channels, num_attention_types=4):
super(MAMLBasedWeightLearning, self).__init__()
# 元权重网络
self.meta_weight_network = MetaWeightNetwork(in_channels, num_attention_types)
# 任务特定适应网络
self.task_adaptation = TaskAdaptationModule(num_attention_types)
# 权重历史记录
self.weight_history = []
self.performance_history = []
def forward(self, x, task_context=None, meta_training=False):
"""
元学习权重生成
"""
# 生成基础权重
base_weights = self.meta_weight_network(x)
if task_context is not None:
# 任务特定适应
adapted_weights = self.task_adaptation(base_weights, task_context)
else:
adapted_weights = base_weights
if meta_training:
# 元训练模式:记录权重和性能
self.weight_history.append(adapted_weights.detach())
return adapted_weights, base_weights
else:
return adapted_weights
def meta_update(self, support_losses, query_losses, learning_rate=0.01):
"""
元更新过程
"""
# 计算梯度
support_grads = torch.autograd.grad(
support_losses.mean(),
self.meta_weight_network.parameters(),
create_graph=True
)
# 快速适应权重
adapted_params = []
for param, grad in zip(self.meta_weight_network.parameters(), support_grads):
adapted_params.append(param - learning_rate * grad)
# 在查询集上计算损失
meta_loss = query_losses.mean()
return meta_loss
class MetaWeightNetwork(nn.Module):
"""
元权重生成网络
"""
def __init__(self, in_channels, num_weights):
super(MetaWeightNetwork, self).__init__()
# 特征提取器
self.feature_extractor = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // 4, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // 4, in_channels // 8, 1),
nn.ReLU(inplace=True)
)
# 权重生成器
self.weight_generator = nn.Sequential(
nn.Conv2d(in_channels // 8, num_weights, 1),
nn.Softmax(dim=1)
)
def forward(self, x):
"""
生成元权重
"""
features = self.feature_extractor(x)
weights = self.weight_generator(features)
return weights
6.2 强化学习优化策略
通过强化学习来优化融合权重,将权重选择建模为一个序贯决策问题。
6.2.1 基于策略梯度的权重优化
class PolicyGradientWeightOptimizer(nn.Module):
"""
基于策略梯度的权重优化器
"""
def __init__(self, in_channels, num_actions, hidden_dim=128):
super(PolicyGradientWeightOptimizer, self).__init__()
# 状态编码器
self.state_encoder = StateEncoder(in_channels, hidden_dim)
# 策略网络(Actor)
self.policy_network = PolicyNetwork(hidden_dim, num_actions)
# 价值网络(Critic)
self.value_network = ValueNetwork(hidden_dim)
# 经验回放缓冲区
self.replay_buffer = ExperienceReplayBuffer(max_size=10000)
def forward(self, x, training=True):
"""
前向传播
"""
# 编码状态
state = self.state_encoder(x)
# 生成动作概率分布
action_logits = self.policy_network(state)
action_probs = F.softmax(action_logits, dim=-1)
# 估计状态价值
state_value = self.value_network(state)
if training:
# 训练模式:采样动作
action_dist = torch.distributions.Categorical(action_probs)
action = action_dist.sample()
log_prob = action_dist.log_prob(action)
return action, log_prob, state_value
else:
# 推理模式:选择最优动作
action = torch.argmax(action_probs, dim=-1)
return action
def update(self, states, actions, rewards, next_states, dones):
"""
更新策略和价值网络
"""
# 计算目标价值
with torch.no_grad():
next_values = self.value_network(self.state_encoder(next_states))
target_values = rewards + 0.99 * next_values * (1 - dones)
# 当前状态价值
current_values = self.value_network(self.state_encoder(states))
# 计算优势
advantages = target_values - current_values
# 策略损失
action_logits = self.policy_network(self.state_encoder(states))
action_log_probs = F.log_softmax(action_logits, dim=-1)
selected_log_probs = action_log_probs.gather(1, actions.unsqueeze(1))
policy_loss = -(selected_log_probs.squeeze() * advantages.detach()).mean()
# 价值损失
value_loss = F.mse_loss(current_values.squeeze(), target_values)
# 总损失
total_loss = policy_loss + 0.5 * value_loss
return total_loss, policy_loss, value_loss
class StateEncoder(nn.Module):
"""
状态编码器
将视觉特征编码为RL状态
"""
def __init__(self, in_channels, hidden_dim):
super(StateEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(in_channels, hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.encoder(x)
class PolicyNetwork(nn.Module):
"""
策略网络
"""
def __init__(self, input_dim, output_dim):
super(PolicyNetwork, self).__init__()
self.network = nn.Sequential(
nn.Linear(input_dim, input_dim // 2),
nn.ReLU(inplace=True),
nn.Linear(input_dim // 2, output_dim)
)
def forward(self, x):
return self.network(x)
class ValueNetwork(nn.Module):
"""
价值网络
"""
def __init__(self, input_dim):
super(ValueNetwork, self).__init__()
self.network = nn.Sequential(
nn.Linear(input_dim, input_dim // 2),
nn.ReLU(inplace=True),
nn.Linear(input_dim // 2, 1)
)
def forward(self, x):
return self.network(x)
6.3 神经架构搜索优化
利用神经架构搜索(NAS)技术来自动发现最优的融合架构和权重分配策略。
6.3.1 可微分架构搜索
class DifferentiableAttentionSearch(nn.Module):
"""
可微分注意力架构搜索
自动搜索最优的融合结构
"""
def __init__(self, in_channels, search_space_config):
super(DifferentiableAttentionSearch, self).__init__()
self.search_space = AttentionSearchSpace(in_channels, search_space_config)
# 架构参数(可学习)
self.architecture_params = nn.ParameterList([
nn.Parameter(torch.randn(len(ops)))
for ops in self.search_space.operation_choices
])
# 权重参数
self.weight_params = nn.ParameterList([
nn.Parameter(torch.randn(self.search_space.num_connections))
])
def forward(self, x):
"""
可微分前向传播
"""
# 计算操作权重
operation_weights = [F.softmax(param, dim=0) for param in self.architecture_params]
# 计算连接权重
connection_weights = F.softmax(self.weight_params[0], dim=0)
# 执行混合操作
mixed_outputs = []
for i, (ops, weights) in enumerate(zip(self.search_space.operation_choices, operation_weights)):
# 加权组合操作
mixed_op_output = sum(w * op(x) for w, op in zip(weights, ops))
mixed_outputs.append(mixed_op_output)
# 加权融合所有输出
final_output = sum(w * output for w, output in zip(connection_weights, mixed_outputs))
return final_output
def get_architecture(self):
"""
获取当前最优架构
"""
# 选择每个位置的最优操作
selected_ops = []
for param in self.architecture_params:
selected_idx = torch.argmax(param).item()
selected_ops.append(selected_idx)
# 选择最优连接权重
selected_connections = torch.argmax(self.weight_params[0]).item()
return {
'operations': selected_ops,
'connections': selected_connections
}
class AttentionSearchSpace(nn.Module):
"""
注意力搜索空间定义
"""
def __init__(self, in_channels, config):
super(AttentionSearchSpace, self).__init__()
# 定义可选操作
self.operation_choices = [
[
ChannelAttention(in_channels),
SpatialAttention(),
SelfAttentionModule(in_channels),
GlobalAttention(in_channels),
nn.Identity() # 跳跃连接
],
[
SerialFusion(),
ParallelFusion(),
HybridFusion(),
AdaptiveFusion()
]
]
# 连接选择
self.num_connections = len(self.operation_choices[0]) * len(self.operation_choices[1])
def sample_architecture(self):
"""
随机采样架构
"""
sampled_ops = []
for ops in self.operation_choices:
sampled_idx = torch.randint(0, len(ops), (1,)).item()
sampled_ops.append(sampled_idx)
return sampled_ops
7. 计算图优化技术 ⚡
7.1 计算图分析与优化
混合注意力机制通常涉及复杂的计算图结构,优化计算图能够显著提升推理效率和训练速度。
7.1.1 算子融合优化
算子融合是减少内存访问和提高计算效率的重要技术。在混合注意力中,我们可以将相关的计算操作融合为单个核函数。
class FusedMixedAttention(nn.Module):
"""
融合优化的混合注意力
将多个计算步骤融合为单个操作
"""
def __init__(self, in_channels, enable_fusion=True):
super(FusedMixedAttention, self).__init__()
self.enable_fusion = enable_fusion
self.in_channels = in_channels
if enable_fusion:
# 融合的权重参数
self.fused_weights = nn.Parameter(torch.randn(in_channels, in_channels))
self.channel_weights = nn.Parameter(torch.randn(in_channels))
self.spatial_weights = nn.Parameter(torch.randn(7, 7)) # 7x7卷积核
# 注册融合算子
self.register_fused_operators()
else:
# 标准实现
self.channel_attention = ChannelAttention(in_channels)
self.spatial_attention = SpatialAttention()
def register_fused_operators(self):
"""
注册自定义融合算子
"""
try:
# 尝试注册CUDA融合算子
import fused_attention_cuda
self.fused_forward = fused_attention_cuda.fused_mixed_attention
except ImportError:
# 回退到PyTorch实现
self.fused_forward = self._pytorch_fused_forward
def _pytorch_fused_forward(self, x):
"""
PyTorch实现的融合前向传播
将多个操作合并减少中间结果存储
"""
B, C, H, W = x.shape
# 融合的通道和空间注意力计算
# 避免创建中间tensor
# 1. 通道注意力计算(融合全局池化和FC层)
global_pool = torch.mean(x.view(B, C, -1), dim=2) # [B, C]
channel_att = torch.sigmoid(torch.matmul(global_pool, self.channel_weights)) # [B, C]
# 2. 空间注意力计算(融合池化和卷积)
spatial_mean = torch.mean(x, dim=1, keepdim=True) # [B, 1, H, W]
spatial_max, _ = torch.max(x, dim=1, keepdim=True) # [B, 1, H, W]
# 融合空间卷积计算
spatial_att = self._fused_spatial_conv(spatial_mean, spatial_max)
# 3. 融合应用注意力权重
# 直接计算最终结果,避免中间存储
channel_att = channel_att.view(B, C, 1, 1)
output = x * channel_att * spatial_att
return output
def _fused_spatial_conv(self, mean_feat, max_feat):
"""
融合的空间卷积计算
"""
B, _, H, W = mean_feat.shape
# 融合输入特征
combined = mean_feat + max_feat # 简化的融合策略
# 应用融合的空间权重
padded = F.pad(combined, (3, 3, 3, 3)) # padding for 7x7
output = F.conv2d(padded, self.spatial_weights.unsqueeze(0).unsqueeze(0))
return torch.sigmoid(output)
def forward(self, x):
"""
前向传播
"""
if self.enable_fusion:
return self.fused_forward(x)
else:
# 标准实现
x = self.channel_attention(x)
x = self.spatial_attention(x)
return x
7.1.2 内存优化策略
class MemoryEfficientMixedAttention(nn.Module):
"""
内存高效的混合注意力
使用检查点和内存重用技术
"""
def __init__(self, in_channels, use_checkpoint=True, memory_efficient=True):
super(MemoryEfficientMixedAttention, self).__init__()
self.use_checkpoint = use_checkpoint
self.memory_efficient = memory_efficient
# 注意力模块
self.attention_modules = nn.ModuleList([
ChannelAttention(in_channels),
SpatialAttention(),
GlobalAttention(in_channels)
])
# 内存池
if memory_efficient:
self.memory_pool = MemoryPool()
def forward(self, x):
"""
内存高效前向传播
"""
if self.use_checkpoint:
# 使用梯度检查点节省内存
return self._checkpoint_forward(x)
else:
return self._standard_forward(x)
def _checkpoint_forward(self, x):
"""
使用梯度检查点的前向传播
"""
def checkpoint_function(input_tensor):
outputs = []
for module in self.attention_modules:
output = module(input_tensor)
outputs.append(output)
# 融合输出
fused_output = sum(outputs) / len(outputs)
return fused_output
# 应用梯度检查点
return torch.utils.checkpoint.checkpoint(checkpoint_function, x)
def _standard_forward(self, x):
"""
标准前向传播,使用内存重用
"""
if self.memory_efficient:
return self._memory_efficient_forward(x)
# 标准实现
outputs = [module(x) for module in self.attention_modules]
return sum(outputs) / len(outputs)
def _memory_efficient_forward(self, x):
"""
内存高效的前向传播
"""
batch_size, channels, height, width = x.shape
# 申请复用内存
temp_buffer = self.memory_pool.get_buffer((batch_size, channels, height, width))
accumulated_output = torch.zeros_like(x)
for i, module in enumerate(self.attention_modules):
# 使用临时缓冲区计算
temp_buffer.zero_()
module_output = module(x)
# 累加到输出中
accumulated_output.add_(module_output, alpha=1.0/len(self.attention_modules))
# 清理中间结果
del module_output
# 释放缓冲区
self.memory_pool.release_buffer(temp_buffer)
return accumulated_output
class MemoryPool:
"""
内存池管理器
"""
def __init__(self):
self.available_buffers = {}
self.used_buffers = set()
def get_buffer(self, shape):
"""
获取指定形状的缓冲区
"""
shape_key = tuple(shape)
if shape_key in self.available_buffers and self.available_buffers[shape_key]:
buffer = self.available_buffers[shape_key].pop()
else:
buffer = torch.zeros(shape, device='cuda' if torch.cuda.is_available() else 'cpu')
self.used_buffers.add(id(buffer))
return buffer
def release_buffer(self, buffer):
"""
释放缓冲区
"""
buffer_id = id(buffer)
if buffer_id in self.used_buffers:
self.used_buffers.remove(buffer_id)
shape_key = tuple(buffer.shape)
if shape_key not in self.available_buffers:
self.available_buffers[shape_key] = []
self.available_buffers[shape_key].append(buffer)
7.2 并行化优化
7.2.1 数据并行优化
class DataParallelMixedAttention(nn.Module):
"""
数据并行优化的混合注意力
"""
def __init__(self, in_channels, num_gpus=None):
super(DataParallelMixedAttention, self).__init__()
self.num_gpus = num_gpus or torch.cuda.device_count()
# 创建多GPU版本的注意力模块
self.attention_modules = nn.ModuleList([
ChannelAttention(in_channels),
SpatialAttention(),
GlobalAttention(in_channels)
])
# 并行化配置
if self.num_gpus > 1:
self.attention_modules = nn.DataParallel(self.attention_modules)
# 负载均衡器
self.load_balancer = LoadBalancer(self.num_gpus)
def forward(self, x):
"""
数据并行前向传播
"""
if self.num_gpus > 1:
return self._parallel_forward(x)
else:
return self._single_gpu_forward(x)
def _parallel_forward(self, x):
"""
多GPU并行前向传播
"""
# 分割输入数据
split_inputs = torch.chunk(x, self.num_gpus, dim=0)
# 并行计算
futures = []
for i, split_input in enumerate(split_inputs):
gpu_id = i % self.num_gpus
with torch.cuda.device(gpu_id):
split_input = split_input.cuda(gpu_id)
future = self._async_compute(split_input, gpu_id)
futures.append(future)
# 收集结果
results = [future.get() for future in futures]
# 合并结果
output = torch.cat(results, dim=0)
return output
def _async_compute(self, x, gpu_id):
"""
异步计算
"""
# 这里简化实现,实际中会使用线程池或异步框架
outputs = []
for module in self.attention_modules:
output = module(x)
outputs.append(output)
# 融合输出
fused_output = sum(outputs) / len(outputs)
return fused_output
class LoadBalancer:
"""
负载均衡器
"""
def __init__(self, num_devices):
self.num_devices = num_devices
self.device_loads = [0] * num_devices
def get_least_loaded_device(self):
"""
获取负载最轻的设备
"""
min_load_idx = min(range(self.num_devices), key=lambda i: self.device_loads[i])
return min_load_idx
def update_load(self, device_id, load_change):
"""
更新设备负载
"""
self.device_loads[device_id] += load_change
7.3 动态计算图优化
7.3.1 自适应计算路径
class AdaptiveComputationMixedAttention(nn.Module):
"""
自适应计算的混合注意力
根据输入复杂度动态调整计算路径
"""
def __init__(self, in_channels, complexity_threshold=0.5):
super(AdaptiveComputationMixedAttention, self).__init__()
self.complexity_threshold = complexity_threshold
# 复杂度评估器
self.complexity_estimator = ComplexityEstimator(in_channels)
# 不同复杂度的处理路径
self.simple_path = SimpleMixedAttention(in_channels)
self.complex_path = ComplexMixedAttention(in_channels)
# 路径选择器
self.path_selector = PathSelector(in_channels)
def forward(self, x):
"""
自适应计算前向传播
"""
# 评估输入复杂度
complexity_score = self.complexity_estimator(x)
# 根据复杂度选择计算路径
if complexity_score < self.complexity_threshold:
# 简单路径:快速处理
output = self.simple_path(x)
computation_cost = 'low'
else:
# 复杂路径:完整处理
output = self.complex_path(x)
computation_cost = 'high'
# 路径融合(可选)
path_weights = self.path_selector(x, complexity_score)
if path_weights is not None:
simple_output = self.simple_path(x)
complex_output = self.complex_path(x)
output = path_weights[0] * simple_output + path_weights[1] * complex_output
computation_cost = 'adaptive'
return output, {
'complexity_score': complexity_score,
'computation_cost': computation_cost,
'path_weights': path_weights
}
class ComplexityEstimator(nn.Module):
"""
输入复杂度评估器
"""
def __init__(self, in_channels):
super(ComplexityEstimator, self).__init__()
# 特征统计计算器
self.feature_stats = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // 4, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // 4, 1, 1),
nn.Sigmoid()
)
# 梯度复杂度计算器
self.gradient_complexity = GradientComplexityCalculator()
def forward(self, x):
"""
计算输入复杂度
"""
# 特征统计复杂度
stat_complexity = self.feature_stats(x).mean()
# 梯度复杂度
grad_complexity = self.gradient_complexity(x)
# 综合复杂度
total_complexity = 0.6 * stat_complexity + 0.4 * grad_complexity
return total_complexity
class GradientComplexityCalculator:
"""
梯度复杂度计算器
"""
def __call__(self, x):
"""
计算梯度复杂度
"""
# 计算空间梯度
grad_x = torch.diff(x, dim=3) # 水平梯度
grad_y = torch.diff(x, dim=2) # 垂直梯度
# 梯度幅值
grad_magnitude = torch.sqrt(grad_x[:, :, :, :-1]**2 + grad_y[:, :, :-1, :]**2)
# 复杂度分数
complexity = torch.mean(grad_magnitude)
return complexity
8. 端到端训练策略设计 🎯
8.1 多任务联合训练
混合注意力机制的一个重要优势是能够在多任务学习中发挥作用,通过共享注意力机制来提升整体性能。
8.1.1 任务感知的注意力分配
class MultiTaskMixedAttention(nn.Module):
"""
多任务混合注意力模块
支持任务特定的注意力权重学习
"""
def __init__(self, in_channels, task_configs):
super(MultiTaskMixedAttention, self).__init__()
self.task_configs = task_configs
self.num_tasks = len(task_configs)
# 共享的基础注意力模块
self.shared_attention = SharedAttentionModule(in_channels)
# 任务特定的注意力模块
self.task_specific_attentions = nn.ModuleDict()
for task_name, config in task_configs.items():
self.task_specific_attentions[task_name] = TaskSpecificAttention(
in_channels, config
)
# 任务权重学习器
self.task_weight_learner = TaskWeightLearner(in_channels, self.num_tasks)
# 任务平衡器
self.task_balancer = TaskBalancer(self.num_tasks)
def forward(self, x, active_tasks=None):
"""
多任务前向传播
Args:
x: 输入特征 [B, C, H, W]
active_tasks: 当前活跃的任务列表
"""
if active_tasks is None:
active_tasks = list(self.task_configs.keys())
# 共享注意力计算
shared_features = self.shared_attention(x)
# 任务特定注意力计算
task_outputs = {}
task_attentions = {}
for task_name in active_tasks:
if task_name in self.task_specific_attentions:
task_output, task_attention = self.task_specific_attentions[task_name](
shared_features
)
task_outputs[task_name] = task_output
task_attentions[task_name] = task_attention
# 学习任务权重
task_weights = self.task_weight_learner(x, active_tasks)
# 任务平衡融合
balanced_output = self.task_balancer(task_outputs, task_weights)
return balanced_output, {
'shared_features': shared_features,
'task_outputs': task_outputs,
'task_attentions': task_attentions,
'task_weights': task_weights
}
class TaskSpecificAttention(nn.Module):
"""
任务特定注意力模块
"""
def __init__(self, in_channels, task_config):
super(TaskSpecificAttention, self).__init__()
self.task_type = task_config['type']
self.attention_strategy = task_config.get('attention_strategy', 'adaptive')
# 根据任务类型构建注意力
if self.task_type == 'classification':
self.attention = ClassificationAttention(in_channels)
elif self.task_type == 'detection':
self.attention = DetectionAttention(in_channels)
elif self.task_type == 'segmentation':
self.attention = SegmentationAttention(in_channels)
else:
self.attention = GenericAttention(in_channels)
# 任务特定的特征变换
self.task_transform = self._build_task_transform(in_channels, task_config)
def _build_task_transform(self, in_channels, task_config):
"""
构建任务特定的特征变换
"""
transform_layers = []
if self.task_type == 'classification':
# 分类任务:注重全局特征
transform_layers.extend([
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
])
elif self.task_type == 'detection':
# 检测任务:注重多尺度特征
transform_layers.extend([
nn.Conv2d(in_channels, in_channels, 3, padding=1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
])
elif self.task_type == 'segmentation':
# 分割任务:注重空间细节
transform_layers.extend([
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, in_channels, 3, padding=1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
])
return nn.Sequential(*transform_layers) if transform_layers else nn.Identity()
def forward(self, x):
"""
任务特定前向传播
"""
# 任务特定变换
transformed_features = self.task_transform(x)
# 应用任务特定注意力
attended_features, attention_map = self.attention(transformed_features)
return attended_features, attention_map
class TaskWeightLearner(nn.Module):
"""
任务权重学习器
动态学习任务重要性权重
"""
def __init__(self, in_channels, num_tasks):
super(TaskWeightLearner, self).__init__()
# 特征编码器
self.feature_encoder = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(in_channels, in_channels // 4),
nn.ReLU(inplace=True),
nn.Linear(in_channels // 4, in_channels // 8),
nn.ReLU(inplace=True)
)
# 任务权重预测器
self.weight_predictor = nn.Linear(in_channels // 8, num_tasks)
# 温度参数(用于控制权重分布的尖锐程度)
self.temperature = nn.Parameter(torch.tensor(1.0))
def forward(self, x, active_tasks):
"""
学习任务权重
"""
# 编码特征
encoded_features = self.feature_encoder(x)
# 预测任务权重
task_logits = self.weight_predictor(encoded_features)
# 应用温度缩放和softmax
task_weights = F.softmax(task_logits / self.temperature, dim=1)
return task_weights
8.2 课程学习策略
课程学习通过逐步增加训练难度来提升混合注意力机制的学习效果。
8.2.1 难度感知的训练调度
class CurriculumMixedAttentionTrainer:
"""
课程学习混合注意力训练器
"""
def __init__(self, model, config):
self.model = model
self.config = config
# 课程设计
self.curriculum = CurriculumDesigner(config)
# 难度评估器
self.difficulty_assessor = DifficultyAssessor()
# 训练状态跟踪
self.training_state = {
'current_stage': 0,
'stage_progress': 0.0,
'difficulty_threshold': 0.3
}
def train_epoch(self, dataloader, epoch):
"""
课程学习训练一个epoch
"""
# 更新课程阶段
self._update_curriculum_stage(epoch)
# 获取当前阶段的配置
stage_config = self.curriculum.get_stage_config(
self.training_state['current_stage']
)
total_loss = 0
num_batches = 0
for batch_data in dataloader:
# 评估批次难度
batch_difficulty = self.difficulty_assessor.assess_batch(batch_data)
# 根据课程策略决定是否训练该批次
if self._should_train_batch(batch_difficulty, stage_config):
loss = self._train_batch(batch_data, stage_config)
total_loss += loss
num_batches += 1
return total_loss / max(num_batches, 1)
def _update_curriculum_stage(self, epoch):
"""
更新课程学习阶段
"""
total_epochs = self.config['total_epochs']
num_stages = len(self.curriculum.stages)
# 计算当前应该在哪个阶段
stage_length = total_epochs // num_stages
new_stage = min(epoch // stage_length, num_stages - 1)
if new_stage != self.training_state['current_stage']:
print(f"进入课程学习第 {new_stage + 1} 阶段")
self.training_state['current_stage'] = new_stage
self.training_state['stage_progress'] = 0.0
# 更新阶段内进度
stage_progress = (epoch % stage_length) / stage_length
self.training_state['stage_progress'] = stage_progress
# 动态调整难度阈值
self._adjust_difficulty_threshold()
def _adjust_difficulty_threshold(self):
"""
动态调整难度阈值
"""
stage = self.training_state['current_stage']
progress = self.training_state['stage_progress']
# 随着训练进行逐步提高难度阈值
base_threshold = 0.3 + 0.2 * stage
progress_bonus = 0.1 * progress
self.training_state['difficulty_threshold'] = base_threshold + progress_bonus
def _should_train_batch(self, batch_difficulty, stage_config):
"""
判断是否应该训练当前批次
"""
threshold = self.training_state['difficulty_threshold']
# 根据课程策略决定
if stage_config['strategy'] == 'easy_first':
return batch_difficulty <= threshold
elif stage_config['strategy'] == 'mixed':
# 混合策略:大部分简单样本 + 少量困难样本
if batch_difficulty <= threshold:
return True
else:
return torch.rand(1).item() < 0.2 # 20%概率训练困难样本
else:
return True # 训练所有样本
class DifficultyAssessor:
"""
样本难度评估器
"""
def __init__(self):
# 难度评估的多个指标
self.metrics = {
'gradient_norm': GradientNormMetric(),
'loss_variance': LossVarianceMetric(),
'prediction_confidence': PredictionConfidenceMetric()
}
def assess_batch(self, batch_data):
"""
评估批次难度
"""
difficulty_scores = []
for metric_name, metric in self.metrics.items():
score = metric.compute(batch_data)
difficulty_scores.append(score)
# 综合难度分数
avg_difficulty = sum(difficulty_scores) / len(difficulty_scores)
return avg_difficulty
def assess_sample(self, sample_data):
"""
评估单个样本难度
"""
# 实现单样本难度评估
pass
class CurriculumDesigner:
"""
课程设计器
"""
def __init__(self, config):
self.config = config
self.stages = self._design_stages()
def _design_stages(self):
"""
设计课程学习阶段
"""
stages = [
{
'name': 'foundation',
'strategy': 'easy_first',
'attention_complexity': 'simple',
'description': '基础阶段:使用简单样本训练基础注意力'
},
{
'name': 'intermediate',
'strategy': 'mixed',
'attention_complexity': 'medium',
'description': '中级阶段:混合难度样本,增加注意力复杂度'
},
{
'name': 'advanced',
'strategy': 'all',
'attention_complexity': 'complex',
'description': '高级阶段:所有样本,完整注意力机制'
}
]
return stages
def get_stage_config(self, stage_idx):
"""
获取指定阶段的配置
"""
return self.stages[stage_idx]
8.3 对抗训练增强
通过对抗训练来提升混合注意力机制的鲁棒性和泛化能力。
8.3.1 注意力对抗训练
class AdversarialMixedAttentionTrainer:
"""
对抗训练混合注意力模型
"""
def __init__(self, model, config):
self.model = model
self.config = config
# 对抗样本生成器
self.adversarial_generator = AdversarialGenerator(config)
# 注意力对抗器
self.attention_adversary = AttentionAdversary(model)
# 鲁棒性评估器
self.robustness_evaluator = RobustnessEvaluator()
def train_batch_adversarial(self, clean_batch, optimizer):
"""
对抗训练单个批次
"""
# 1. 正常样本训练
clean_loss = self._train_clean_batch(clean_batch, optimizer)
# 2. 生成对抗样本
adversarial_batch = self.adversarial_generator.generate(
clean_batch, self.model
)
# 3. 对抗样本训练
adv_loss = self._train_adversarial_batch(adversarial_batch, optimizer)
# 4. 注意力对抗训练
attention_adv_loss = self._train_attention_adversarial(
clean_batch, adversarial_batch, optimizer
)
# 5. 总损失
total_loss = (0.4 * clean_loss +
0.4 * adv_loss +
0.2 * attention_adv_loss)
return total_loss
def _train_attention_adversarial(self, clean_batch, adv_batch, optimizer):
"""
注意力对抗训练
"""
# 获取干净样本的注意力
clean_output, clean_attention_info = self.model(clean_batch['input'])
# 获取对抗样本的注意力
adv_output, adv_attention_info = self.model(adv_batch['input'])
# 计算注意力一致性损失
attention_consistency_loss = self._compute_attention_consistency_loss(
clean_attention_info, adv_attention_info
)
# 注意力鲁棒性损失
attention_robustness_loss = self._compute_attention_robustness_loss(
clean_attention_info, adv_attention_info
)
total_attention_loss = (0.6 * attention_consistency_loss +
0.4 * attention_robustness_loss)
return total_attention_loss
def _compute_attention_consistency_loss(self, clean_att, adv_att):
"""
计算注意力一致性损失
"""
consistency_loss = 0
# 遍历所有注意力图
for key in clean_att:
if key in adv_att and 'attention' in key:
clean_map = clean_att[key]
adv_map = adv_att[key]
# L2距离损失
l2_loss = F.mse_loss(clean_map, adv_map)
# 结构相似性损失
ssim_loss = self._compute_ssim_loss(clean_map, adv_map)
consistency_loss += l2_loss + 0.3 * ssim_loss
return consistency_loss
def _compute_ssim_loss(self, map1, map2):
"""
计算结构相似性损失
"""
# 简化的SSIM实现
mu1 = torch.mean(map1)
mu2 = torch.mean(map2)
sigma1_sq = torch.var(map1)
sigma2_sq = torch.var(map2)
sigma12 = torch.mean((map1 - mu1) * (map2 - mu2))
c1 = 0.01 ** 2
c2 = 0.03 ** 2
ssim = ((2 * mu1 * mu2 + c1) * (2 * sigma12 + c2)) / \
((mu1**2 + mu2**2 + c1) * (sigma1_sq + sigma2_sq + c2))
return 1 - ssim # 转换为损失
class AdversarialGenerator:
"""
对抗样本生成器
"""
def __init__(self, config):
self.config = config
self.attack_methods = {
'fgsm': self._fgsm_attack,
'pgd': self._pgd_attack,
'attention_attack': self._attention_attack
}
def generate(self, clean_batch, model):
"""
生成对抗样本
"""
attack_method = self.config.get('attack_method', 'pgd')
if attack_method in self.attack_methods:
return self.attack_methods[attack_method](clean_batch, model)
else:
raise ValueError(f"不支持的攻击方法: {attack_method}")
def _pgd_attack(self, clean_batch, model, eps=0.03, alpha=0.01, steps=10):
"""
PGD攻击
"""
x = clean_batch['input'].clone().detach()
y = clean_batch['target']
# 随机初始化
x_adv = x + torch.empty_like(x).uniform_(-eps, eps)
x_adv = torch.clamp(x_adv, 0, 1)
for _ in range(steps):
x_adv.requires_grad_(True)
# 前向传播
output, _ = model(x_adv)
loss = F.cross_entropy(output, y)
# 计算梯度
grad = torch.autograd.grad(loss, x_adv)[0]
# 更新对抗样本
x_adv = x_adv + alpha * grad.sign()
# 投影到合理范围
delta = torch.clamp(x_adv - x, -eps, eps)
x_adv = torch.clamp(x + delta, 0, 1).detach()
return {'input': x_adv, 'target': y}
def _attention_attack(self, clean_batch, model, eps=0.03):
"""
针对注意力的攻击
"""
x = clean_batch['input'].clone().detach()
y = clean_batch['target']
x.requires_grad_(True)
# 获取干净样本的注意力
output, attention_info = model(x)
# 构造注意力损失(最大化注意力变化)
attention_loss = 0
for key, attention_map in attention_info.items():
if 'attention' in key and attention_map is not None:
# 最大化注意力的方差(破坏集中性)
attention_loss += -torch.var(attention_map)
# 计算梯度
grad = torch.autograd.grad(attention_loss, x)[0]
# 生成对抗样本
x_adv = x + eps * grad.sign()
x_adv = torch.clamp(x_adv, 0, 1)
return {'input': x_adv.detach(), 'target': y}
9. PyTorch完整实现与解析 💻
9.1 完整的混合注意力框架
现在让我们实现一个完整的、生产级别的混合注意力框架,该框架集成了前面讨论的所有核心技术。
9.1.1 核心框架实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from typing import Dict, List, Optional, Tuple, Union
from collections import OrderedDict
class UnifiedMixedAttentionFramework(nn.Module):
"""
统一混合注意力框架
集成多种注意力机制和融合策略的完整实现
"""
def __init__(
self,
in_channels: int,
attention_types: List[str] = ['channel', 'spatial', 'self'],
fusion_strategy: str = 'adaptive',
enable_curriculum: bool = True,
enable_adversarial: bool = False,
memory_efficient: bool = True,
**kwargs
):
super(UnifiedMixedAttentionFramework, self).__init__()
self.in_channels = in_channels
self.attention_types = attention_types
self.fusion_strategy = fusion_strategy
self.enable_curriculum = enable_curriculum
self.enable_adversarial = enable_adversarial
self.memory_efficient = memory_efficient
# 构建注意力模块字典
self.attention_modules = self._build_attention_modules()
# 构建融合模块
self.fusion_module = self._build_fusion_module()
# 构建优化模块
self.optimization_modules = self._build_optimization_modules()
# 训练状态管理
self.training_state = TrainingStateManager()
# 性能监控
self.performance_monitor = PerformanceMonitor()
# 初始化权重
self._initialize_weights()
def _build_attention_modules(self) -> nn.ModuleDict:
"""
构建注意力模块字典
"""
modules = nn.ModuleDict()
for att_type in self.attention_types:
if att_type == 'channel':
modules[att_type] = AdvancedChannelAttention(self.in_channels)
elif att_type == 'spatial':
modules[att_type] = AdvancedSpatialAttention(self.in_channels)
elif att_type == 'self':
modules[att_type] = AdvancedSelfAttention(self.in_channels)
elif att_type == 'global':
modules[att_type] = GlobalContextAttention(self.in_channels)
elif att_type == 'local':
modules[att_type] = LocalSpatialAttention(self.in_channels)
else:
raise ValueError(f"不支持的注意力类型: {att_type}")
return modules
def _build_fusion_module(self) -> nn.Module:
"""
构建融合模块
"""
num_attention_types = len(self.attention_types)
if self.fusion_strategy == 'adaptive':
return AdaptiveFusionModule(self.in_channels, num_attention_types)
elif self.fusion_strategy == 'hierarchical':
return HierarchicalFusionModule(self.in_channels, num_attention_types)
elif self.fusion_strategy == 'gated':
return GatedFusionModule(self.in_channels, num_attention_types)
elif self.fusion_strategy == 'learned':
return LearnedFusionModule(self.in_channels, num_attention_types)
else:
return SimpleFusionModule(num_attention_types)
def _build_optimization_modules(self) -> Dict[str, nn.Module]:
"""
构建优化模块
"""
modules = {}
if self.memory_efficient:
modules['memory_optimizer'] = MemoryOptimizer()
if self.enable_curriculum:
modules['curriculum_scheduler'] = CurriculumScheduler()
if self.enable_adversarial:
modules['adversarial_trainer'] = AdversarialTrainer()
return nn.ModuleDict(modules)
def forward(
self,
x: torch.Tensor,
task_context: Optional[Dict] = None,
return_attention_maps: bool = False
) -> Union[torch.Tensor, Tuple[torch.Tensor, Dict]]:
"""
前向传播
Args:
x: 输入特征图 [B, C, H, W]
task_context: 任务上下文信息
return_attention_maps: 是否返回注意力图
Returns:
output: 处理后的特征图
attention_info: 注意力信息(可选)
"""
# 性能监控开始
self.performance_monitor.start_forward()
# 计算各种注意力
attention_outputs = {}
attention_maps = {}
for att_type, att_module in self.attention_modules.items():
if self.memory_efficient:
# 内存高效计算
att_output, att_map = self._memory_efficient_attention(
att_module, x, att_type
)
else:
# 标准计算
att_output, att_map = att_module(x)
attention_outputs[att_type] = att_output
if att_map is not None:
attention_maps[att_type] = att_map
# 融合所有注意力输出
fused_output = self.fusion_module(attention_outputs, x, task_context)
# 残差连接
final_output = fused_output + x
# 性能监控结束
self.performance_monitor.end_forward()
if return_attention_maps:
attention_info = {
'attention_maps': attention_maps,
'attention_outputs': attention_outputs,
'fusion_weights': getattr(self.fusion_module, 'last_weights', None),
'performance_stats': self.performance_monitor.get_stats()
}
return final_output, attention_info
return final_output
def _memory_efficient_attention(
self,
attention_module: nn.Module,
x: torch.Tensor,
att_type: str
) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
"""
内存高效的注意力计算
"""
# 使用梯度检查点来节省内存
def checkpoint_fn(input_tensor):
return attention_module(input_tensor)
if self.training and self.memory_efficient:
return torch.utils.checkpoint.checkpoint(checkpoint_fn, x)
else:
return attention_module(x)
def _initialize_weights(self):
"""
初始化模型权重
"""
for module in self.modules():
if isinstance(module, nn.Conv2d):
nn.init.kaiming_normal_(module.weight, mode='fan_out', nonlinearity='relu')
if module.bias is not None:
nn.init.constant_(module.bias, 0)
elif isinstance(module, nn.BatchNorm2d):
nn.init.constant_(module.weight, 1)
nn.init.constant_(module.bias, 0)
elif isinstance(module, nn.Linear):
nn.init.normal_(module.weight, 0, 0.01)
if module.bias is not None:
nn.init.constant_(module.bias, 0)
def get_attention_complexity(self) -> Dict[str, int]:
"""
获取注意力机制的计算复杂度
"""
complexity = {}
for att_type, att_module in self.attention_modules.items():
if hasattr(att_module, 'get_complexity'):
complexity[att_type] = att_module.get_complexity()
return complexity
def optimize_for_deployment(self, target_platform: str = 'mobile'):
"""
针对部署优化模型
"""
if target_platform == 'mobile':
# 移动端优化
self._optimize_for_mobile()
elif target_platform == 'edge':
# 边缘设备优化
self._optimize_for_edge()
elif target_platform == 'server':
# 服务器优化
self._optimize_for_server()
def _optimize_for_mobile(self):
"""
移动端优化
"""
# 量化权重
for module in self.modules():
if isinstance(module, (nn.Conv2d, nn.Linear)):
# 简化的量化示例
module.weight.data = torch.round(module.weight.data * 127) / 127
# 启用内存优化
self.memory_efficient = True
9.1.2 高级注意力模块实现
class AdvancedChannelAttention(nn.Module):
"""
高级通道注意力模块
集成多种池化策略和特征增强技术
"""
def __init__(self, in_channels: int, reduction: int = 16):
super(AdvancedChannelAttention, self).__init__()
self.in_channels = in_channels
self.reduction = reduction
# 多种池化策略
self.pooling_strategies = nn.ModuleDict({
'avg': nn.AdaptiveAvgPool2d(1),
'max': nn.AdaptiveMaxPool2d(1),
'lp': LpPooling2d(norm_type=2), # L2池化
'attention': AttentionPooling2d(in_channels)
})
# 共享的MLP
self.shared_mlp = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction, in_channels, 1, bias=False)
)
# 池化权重学习
self.pooling_weights = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, len(self.pooling_strategies), 1),
nn.Softmax(dim=1)
)
# 通道重要性建模
self.channel_importance = ChannelImportanceModeling(in_channels)
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
"""
前向传播
"""
B, C, H, W = x.shape
# 计算各种池化结果
pooling_results = []
for name, pooling in self.pooling_strategies.items():
pooled = pooling(x) # [B, C, 1, 1]
pooling_results.append(pooled)
# 学习池化权重
pool_weights = self.pooling_weights(x) # [B, num_pooling, 1, 1]
# 加权融合池化结果
weighted_pooling = sum(
w * pool for w, pool in zip(
pool_weights.split(1, dim=1), pooling_results
)
)
# 通过共享MLP
channel_attention = self.shared_mlp(weighted_pooling)
# 通道重要性调制
importance_weights = self.channel_importance(x)
modulated_attention = channel_attention * importance_weights
# 应用Sigmoid激活
attention_weights = torch.sigmoid(modulated_attention)
# 应用注意力
attended_features = x * attention_weights
return attended_features, attention_weights.squeeze(-1).squeeze(-1)
def get_complexity(self) -> int:
"""
计算复杂度(FLOPs)
"""
# 简化的复杂度计算
return self.in_channels * (self.in_channels // self.reduction) * 2
class AdvancedSpatialAttention(nn.Module):
"""
高级空间注意力模块
支持多尺度和可变形卷积
"""
def __init__(self, in_channels: int, kernel_sizes: List[int] = [3, 5, 7]):
super(AdvancedSpatialAttention, self).__init__()
self.kernel_sizes = kernel_sizes
# 多尺度空间注意力分支
self.multi_scale_branches = nn.ModuleList()
for kernel_size in kernel_sizes:
padding = kernel_size // 2
branch = nn.Sequential(
nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False),
nn.BatchNorm2d(1),
nn.ReLU(inplace=True)
)
self.multi_scale_branches.append(branch)
# 尺度融合网络
self.scale_fusion = nn.Sequential(
nn.Conv2d(len(kernel_sizes), 1, 1, bias=False),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
# 空间重要性建模
self.spatial_importance = SpatialImportanceModeling(in_channels)
# 位置编码
self.position_encoding = PositionalEncoding2D(max_len=1000)
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
"""
前向传播
"""
# 通道维度聚合
avg_out = torch.mean(x, dim=1, keepdim=True) # [B, 1, H, W]
max_out, _ = torch.max(x, dim=1, keepdim=True) # [B, 1, H, W]
# 多尺度处理
scale_outputs = []
for branch in self.multi_scale_branches:
# 输入: [B, 2, H, W] (avg + max)
branch_input = torch.cat([avg_out, max_out], dim=1)
scale_out = branch(branch_input) # [B, 1, H, W]
scale_outputs.append(scale_out)
# 融合多尺度结果
concatenated_scales = torch.cat(scale_outputs, dim=1) # [B, num_scales, H, W]
spatial_attention = self.scale_fusion(concatenated_scales) # [B, 1, H, W]
# 空间重要性调制
importance_map = self.spatial_importance(x)
modulated_attention = spatial_attention * importance_map
# 位置编码增强
B, C, H, W = x.shape
pos_encoding = self.position_encoding(H, W).to(x.device)
enhanced_attention = modulated_attention + 0.1 * pos_encoding.unsqueeze(0)
# 应用注意力
attended_features = x * enhanced_attention
return attended_features, enhanced_attention.squeeze(1)
class ChannelImportanceModeling(nn.Module):
"""
通道重要性建模模块
"""
def __init__(self, in_channels: int):
super(ChannelImportanceModeling, self).__init__()
# 统计特征提取
self.stats_extractor = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // 4, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // 4, in_channels, 1),
nn.Sigmoid()
)
# 动态权重生成
self.dynamic_weights = DynamicWeightGenerator(in_channels)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
计算通道重要性权重
"""
# 基础统计特征
base_importance = self.stats_extractor(x)
# 动态调制
dynamic_modulation = self.dynamic_weights(x)
# 融合重要性信息
final_importance = base\_importance \* (1 + dynamic\_modulation)
return final_importance
class DynamicWeightGenerator(nn.Module):
"""
动态权重生成器
根据输入特征动态生成调制权重
"""
def **init**(self, in\_channels: int):
super(DynamicWeightGenerator, self).**init**()
self.weight_net = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // 8, 1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // 8, in_channels, 1),
nn.Tanh() # 输出范围 [-1, 1]
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.weight_net(x)
9.2 训练策略与损失函数设计
混合注意力机制的训练需要特殊的策略来确保不同注意力组件能够有效协作。传统的单一损失函数往往无法充分指导复杂的混合注意力学习过程。
9.2.1 多层次损失函数架构
在混合注意力的训练中,我们需要设计多层次的损失函数来指导不同层面的学习:
主任务损失:这是最基础的损失,直接关联到最终的任务目标,如分类交叉熵损失、检测损失等。主任务损失确保模型能够完成基本的预测功能。
注意力一致性损失:用于确保不同类型的注意力机制之间保持合理的一致性。过度分歧的注意力可能导致特征表示的不稳定,而适度的一致性有助于提升模型的鲁棒性。
注意力多样性损失:与一致性损失相对,多样性损失鼓励不同注意力机制关注不同的特征方面,避免所有注意力机制趋同而失去互补性。
权重平衡损失:确保融合权重不会过度偏向某一种注意力机制,维持各种注意力的贡献平衡。
9.2.2 自适应损失权重调整
随着训练的进行,不同损失项的重要性会发生变化。在训练初期,主任务损失应该占主导地位,确保模型学习基本的特征表示能力。随着训练的深入,注意力相关的辅助损失逐渐发挥作用,精细化调整注意力机制的行为。
温度退火策略:采用类似模拟退火的思想,在训练初期使用较高的"温度"参数,允许注意力权重有更大的探索空间。随着训练进行,逐步降低温度,使注意力权重趋于稳定。
性能驱动的权重调整:根据验证集上的性能表现动态调整不同损失项的权重。如果发现某种注意力机制的贡献不足,可以适当增加相应损失项的权重。
困难样本感知的损失权重:对于困难样本,可能需要更多地依赖注意力机制来提取判别性特征。因此,在处理困难样本时,可以增加注意力相关损失的权重。
9.3 性能优化与加速技术
混合注意力机制的计算复杂度相对较高,需要采用多种优化技术来提升训练和推理效率。
9.3.1 计算图优化策略
算子融合技术:将相关的注意力计算操作融合为单个CUDA核函数,减少内存访问次数和核函数启动开销。例如,可以将通道注意力的全局池化、线性变换和激活函数融合为一个操作。
内存重用机制:在计算不同类型注意力时,合理重用中间计算结果。例如,空间注意力和通道注意力都需要计算特征图的统计信息,可以将这些计算结果缓存起来重复使用。
动态计算图:根据输入特征的复杂度动态选择需要激活的注意力分支。对于简单的输入,可以跳过某些计算密集的注意力组件,在保持性能的前提下提升效率。
9.3.2 混合精度训练策略
梯度缩放技术:在使用半精度浮点数训练时,注意力权重的梯度往往较小,容易出现下溢问题。采用动态梯度缩放技术可以有效解决这个问题。
精度敏感度分析:不同的注意力组件对精度的敏感度不同。通道注意力通常对精度要求较低,可以使用半精度计算;而空间注意力需要精确的位置信息,可能需要保持全精度。
内存优化:通过梯度检查点、激活重计算等技术减少显存占用,使得能够训练更大的模型或使用更大的批次大小。
10. YOLO系列集成案例 🚀
10.1 YOLOv8混合注意力集成
YOLOv8作为目前最先进的目标检测框架之一,为混合注意力机制的集成提供了理想的平台。通过在YOLOv8的不同位置集成混合注意力,我们可以显著提升检测精度和模型的感知能力。
10.1.1 骨干网络集成策略
在YOLOv8的骨干网络中集成混合注意力需要考虑到特征提取的层次性特点。浅层网络主要提取低级特征如边缘、纹理等,深层网络则关注高级语义特征。
浅层集成策略:在骨干网络的前几层集成空间注意力为主的混合机制,重点关注目标的边界和形状信息。这个阶段的注意力应该具有较高的空间分辨率,能够精确定位目标边界。
中层集成策略:在中间层同时集成空间和通道注意力,平衡空间定位和特征选择的需求。此时的特征图具有适中的分辨率和语义信息,是进行混合注意力的理想位置。
深层集成策略:在深层网络主要集成通道注意力和全局注意力,重点关注高级语义特征的选择和整合。这个阶段的注意力更多地关注"是什么"而不是"在哪里"。
10.1.2 特征金字塔网络优化
YOLOv8的FPN(Feature Pyramid Network)结构为混合注意力提供了多尺度特征融合的机会。在FPN的不同层级集成混合注意力可以增强多尺度目标的检测能力。
跨尺度注意力融合:设计跨尺度的注意力机制,使得不同尺度的特征图能够相互参考和增强。大尺度特征图的全局信息可以指导小尺度特征图的局部关注,而小尺度特征图的细节信息可以补充大尺度特征图的语义表示。
尺度自适应权重学习:不同尺度的目标需要不同的注意力策略。大目标更依赖全局上下文信息,小目标更需要局部细节增强。通过学习尺度自适应的权重,混合注意力机制可以根据目标尺寸动态调整关注策略。
特征对齐与增强:在FPN的特征融合过程中,使用混合注意力来对齐不同尺度的特征,并增强融合后特征的判别性。这种对齐不仅是空间上的,也是语义上的。
10.2 实际部署考量
10.2.1 推理速度优化
在实际部署中,推理速度往往是一个关键制约因素。混合注意力机制虽然能够提升精度,但也会增加计算开销。
早期退出机制:设计置信度驱动的早期退出机制。对于简单场景,模型可以在应用部分注意力机制后就输出结果;只有在困难场景下才激活完整的混合注意力。
注意力缓存技术:对于视频流等连续输入,可以缓存前一帧的注意力计算结果,在当前帧中进行增量更新,避免重复计算。
量化友好的设计:在设计混合注意力时考虑量化的影响,使用量化友好的激活函数和网络结构,确保量化后的性能损失最小。
10.2.2 内存占用优化
渐进式计算:将复杂的混合注意力计算分解为多个步骤,每个步骤只需要较少的内存,通过渐进式计算完成整个注意力机制。
特征复用策略:在计算不同类型注意力时,尽可能复用中间特征表示,减少内存分配和释放的开销。
批次自适应处理:根据可用内存动态调整批次大小,在内存受限的环境下自动降低批次大小以避免内存溢出。
11. 多尺度混合注意力扩展 🌐
11.1 层次化多尺度设计
多尺度混合注意力的设计需要考虑到不同尺度信息的层次性特点。从局部细节到全局结构,不同尺度的信息承载着不同层次的语义内容。
11.1.1 尺度空间理论基础
在计算机视觉中,尺度空间理论为我们理解多尺度信息提供了数学基础。根据这一理论,任何视觉信息都可以在不同的尺度上进行分析,每个尺度都揭示了不同层次的结构特征。
高斯尺度空间:通过高斯核的卷积操作,我们可以构建连续的尺度空间。不同标准差的高斯核对应不同的尺度,较小的标准差保留更多细节,较大的标准差突出全局结构。
拉普拉斯金字塔:拉普拉斯金字塔提供了一种有效的多尺度表示方法,每一层都包含特定尺度范围内的信息,不同层之间互补而不重复。
小波变换:小波变换能够同时在时域(空域)和频域进行分析,为多尺度分析提供了强大的数学工具。
11.1.2 自适应尺度选择
传统的多尺度方法通常使用固定的尺度组合,但实际应用中,不同的图像内容需要不同的尺度关注策略。
内容驱动的尺度选择:分析输入图像的纹理复杂度、目标尺寸分布等特征,动态选择最适合的尺度组合。对于包含大量小目标的图像,系统会更多地关注细尺度信息;对于主要包含大目标的图像,则更多地关注粗尺度信息。
任务导向的尺度权重:不同的视觉任务对尺度信息的需求不同。分类任务可能更依赖中等尺度的特征,检测任务需要多尺度信息的综合,分割任务则对细尺度信息有更高要求。
学习型尺度策略:通过端到端的学习让模型自动发现最优的尺度选择和权重分配策略,避免人工设计的主观性和局限性。
11.2 跨尺度信息交互
在多尺度混合注意力中,不同尺度之间的信息交互是关键。简单的独立处理无法充分利用尺度间的互补性和依赖关系。
11.2.1 双向信息流动
自上而下的指导:粗尺度的全局信息可以为细尺度的局部处理提供上下文指导。例如,全局的目标位置信息可以帮助局部注意力更精确地定位目标边界。
自下而上的细化:细尺度的详细信息可以对粗尺度的抽象表示进行细化和修正。局部的纹理特征可以帮助修正全局的目标分类结果。
横向连接增强:同一层级不同位置的特征可以通过横向连接进行信息交换,增强特征表示的一致性和完整性。
11.2.2 尺度一致性约束
几何一致性:确保不同尺度上识别的目标在几何上保持一致。例如,在粗尺度上识别为车辆的区域,在细尺度上应该能够识别出车辆的具体部件。
语义一致性:保证不同尺度的语义解释不冲突。如果粗尺度识别为动物,细尺度就不应该识别为植物。
时序一致性:在视频分析中,确保同一目标在时间序列上的多尺度表示保持稳定和精度平衡
多尺度处理虽然能够提供丰富的信息,但也带来了计算复杂度的显著增加。如何在计算效率和表示精度之间找到最佳平衡是一个重要挑战。
11.3.1 智能尺度调度
需求驱动的尺度激活:根据输入内容的复杂度和任务需求,智能地决定需要激活哪些尺度。对于简单场景,只激活必要的尺度;对于复杂场景,激活完整的多尺度处理。
渐进式尺度处理:采用从粗到细的渐进处理策略,根据粗尺度的分析结果决定是否需要进行更细尺度的处理。
置信度指导的尺度选择:当某个尺度的处理结果具有足够高的置信度时,可以跳过其他尺度的处理,直接输出结果。
11.3.2 近似计算技术
分离式尺度计算:将多尺度计算分解为独立的单尺度计算,然后通过轻量级的融合网络进行结果整合。
采样式尺度表示:不是在所有可能的尺度上都进行完整处理,而是选择代表性的尺度采样点,通过插值等方法获得其他尺度的近似表示。
知识蒸馏优化:使用复杂的多尺度模型作为教师网络,训练简化的学生网络,在保持大部分性能的同时显著降低计算复杂度。
12. 性能评估与消融实验 📊
12.1 评估指标体系构建
混合注意力机制的评估需要建立多维度的指标体系,不仅要考虑最终任务的性能,还要评估注意力机制本身的质量和效率。
12.1.1 任务性能指标
精度类指标:包括分类准确率、检测的mAP、分割的mIoU等传统指标。这些指标直接反映了混合注意力对最终任务性能的贡献。
鲁棒性指标:在噪声、光照变化、几何变换等干扰条件下的性能表现。混合注意力机制应该能够提升模型的鲁棒性。
泛化能力指标:在不同数据集、不同领域之间的迁移性能。好的注意力机制应该具有良好的泛化能力。
12.1.2 注意力质量指标
注意力集中度:衡量注意力是否能够准确聚焦于重要区域。可以通过计算注意力图的熵、峰值比等指标来量化。
注意力稳定性:评估注意力在相似输入下的一致性。稳定的注意力机制应该对微小的输入变化不敏感。
注意力可解释性:通过与人类标注的显著性图进行比较,评估注意力的可解释性程度。
注意力多样性:在混合注意力中,不同类型的注意力应该关注不同的特征方面,避免冗余。
12.1.3 效率性指标
计算复杂度:包括FLOPs、参数数量、推理时间等。需要评估注意力机制引入的额外计算开销。
内存使用量:训练和推理过程中的峰值内存使用量,这对实际部署很重要。
能耗分析:在移动设备和边缘计算场景中,能耗是一个重要考量因素。
12.2 消融实验设计
消融实验是理解混合注意力机制各组件贡献的重要方法。通过系统性地移除或替换不同的组件,我们可以量化每个组件的作用。
12.2.1 组件级消融分析
注意力类型消融:分别移除不同类型的注意力机制,观察对性能的影响。这可以帮助理解不同注意力类型的相对重要性。
融合策略消融:比较不同的融合策略(串行、并行、层次化等)的效果,找出最适合特定任务的融合方式。
权重学习消融:比较固定权重和学习权重的效果,验证动态权重学习的必要性。
12.2.2 超参数敏感性分析
权重初始化:研究不同的权重初始化策略对收敛速度和最终性能的影响。
损失函数权重:分析不同损失项权重对训练过程和最终结果的影响。
网络深度和宽度:探索注意力网络的最优结构配置。
12.2.3 数据集扩展性验证
跨数据集验证:在多个相关数据集上验证混合注意力的有效性,评估其泛化能力。
数据规模影响:研究在不同数据规模下混合注意力的表现,分析数据需求。
领域适应性:测试混合注意力在不同应用领域的适应性和迁移能力。
12.3 对比实验分析
12.3.1 基线方法选择
选择合适的基线方法是确保实验公平性和结论可靠性的关键。基线方法应该包括:
无注意力基线:使用相同的网络结构但不加入任何注意力机制,用于评估注意力的纯净贡献。
单一注意力基线:分别使用单一类型的注意力机制,如仅使用通道注意力或空间注意力。
现有方法对比:与已发表的先进注意力方法进行对比,如SENet、CBAM、ECA-Net等。
随机注意力控制:使用随机生成的注意力权重作为控制组,验证学习得到的注意力的有效性。
12.3.2 实验环境标准化
硬件配置统一:确保所有对比实验在相同的硬件环境下进行,避免硬件差异对结果的影响。
软件环境一致:使用相同版本的深度学习框架、CUDA版本等,确保软件环境的一致性。
随机种子控制:设置固定的随机种子,确保实验的可重复性。
训练策略统一:使用相同的优化器、学习率调度、数据增强策略等。
13. 工程部署优化策略 ⚙️
13.1 生产环境适配
将混合注意力机制从研究原型转化为生产可用的系统需要考虑多个工程层面的挑战。
13.1.1 服务化封装设计
模块化架构:将混合注意力设计为可插拔的模块,支持灵活的配置和组合。不同的应用场景可以选择不同的注意力组合和参数配置。
接口标准化:定义统一的API接口,使得混合注意力模块可以无缝集成到现有的深度学习框架和应用系统中。
配置管理:实现灵活的配置管理系统,支持运行时动态调整注意力参数,无需重新编译或重启服务。
版本控制:建立模型版本管理机制,支持模型的平滑升级和回滚,确保生产系统的稳定性。
13.1.2 性能监控与调优
实时性能监控:建立全面的性能监控体系,实时跟踪推理延迟、吞吐量、内存使用等关键指标。
自动化调优:基于监控数据实现自动化的性能调优,动态调整批次大小、并发数等参数以优化整体性能。
异常检测与恢复:实现智能的异常检测机制,当检测到性能异常或质量下降时,自动触发恢复策略。
资源预测与规划:基于历史数据和业务预测,提前规划计算资源,避免因资源不足导致的服务质量下降。
13.2 多平台兼容性
13.2.1 异构硬件适配
GPU优化:针对不同型号的GPU进行专门优化,充分利用各种GPU的计算特性。例如,对于Tensor Core的利用、内存带宽的优化等。
CPU后备支持:当GPU资源不可用时,提供高效的CPU实现作为后备方案。通过SIMD指令优化、多线程并行等技术提升CPU性能。
专用芯片适配:针对NPU、TPU等专用AI芯片提供优化实现,充分利用这些芯片的专用加速能力。
移动端优化:为移动设备提供轻量化版本,通过量化、剪枝、知识蒸馏等技术减少计算和存储需求。
13.2.2 框架兼容性
多框架支持:确保混合注意力机制能够在PyTorch、TensorFlow、ONNX等主流框架中正确运行。
算子注册:为不同框架注册自定义的融合算子,提升计算效率。
模型转换:提供不同框架间的模型转换工具,方便模型的迁移和部署。
推理引擎集成:与TensorRT、NCNN、OpenVINO等推理引擎深度集成,进一步提升推理性能。
13.3 扩展性与维护性
13.3.1 架构扩展性设计
插件化架构:采用插件化的架构设计,新的注意力机制可以作为插件动态加载,无需修改核心代码。
抽象层设计:建立清晰的抽象层,将注意力机制的通用逻辑与具体实现分离,便于扩展和维护。
配置驱动:通过配置文件驱动模型结构和参数,支持无代码的模型定制和调优。
微服务架构:将不同的注意力组件设计为独立的微服务,支持独立的扩缩容和版本管理。
13.3.2 代码质量与维护
代码规范:建立严格的代码规范和审查流程,确保代码质量和可读性。
单元测试:为每个注意力组件编写完善的单元测试,确保代码的正确性和可靠性。
文档完善:提供详细的API文档、使用指南和最佳实践,降低使用门槛。
持续集成:建立自动化的CI/CD流程,实现代码的自动测试、构建和部署。
14. 前沿应用场景分析 🔬
14.1 多模态学习中的应用
混合注意力机制在多模态学习中展现出独特的优势,能够有效整合来自不同模态的信息。
14.1.1 视觉-语言理解
在视觉-语言任务中,混合注意力可以建立图像和文本之间的细粒度对应关系。
跨模态对齐:通过混合注意力机制,模型能够学习图像中的视觉区域与文本中的词汇或短语之间的对应关系。这种对齐不仅是空间上的,也是语义上的。
多层次语义理解:混合注意力可以在多个抽象层次上理解视觉-语言的关联。底层关注像素与字符的对应,中层关注物体与词汇的关联,高层关注场景与句子的语义匹配。
上下文感知的注意力:在理解"红色的车"这样的描述时,混合注意力不仅要定位车辆,还要验证其颜色属性,这需要综合空间、通道和语义多种注意力。
14.1.2 音视频分析
时空注意力融合:在音视频分析中,混合注意力需要同时处理时间、空间和频谱三个维度的信息。
跨模态事件检测:通过视觉和听觉信息的联合分析,混合注意力可以更准确地检测和定位事件。例如,在视频中检测"玻璃破碎"事件时,需要同时分析视觉上的碎片飞溅和听觉上的破碎声音。
情感计算:在情感识别任务中,面部表情、语音语调、手势动作等多种信息需要综合考虑。混合注意力机制能够自动学习这些不同模态信息的重要性权重。
14.2 自动驾驶场景应用
自动驾驶是混合注意力机制的重要应用领域,其复杂的感知需求为注意力机制提供了广阔的应用空间。
14.2.1 多传感器融合
激光雷达与摄像头融合:激光雷达提供精确的距离信息,摄像头提供丰富的纹理和颜色信息。混合注意力可以学习如何有效融合这两种互补的信息源。
时序信息集成:在动态交通环境中,历史信息对当前决策至关重要。混合注意力可以建模时序依赖关系,将过去的观测与当前感知进行有效整合。
不确定性处理:传感器数据往往包含噪声和不确定性。混合注意力机制可以学习识别可靠的信息源,并相应地调整注意力权重。
14.2.2 场景理解与预测
动态目标跟踪:在复杂交通场景中,混合注意力可以帮助系统持续跟踪多个动态目标,即使在遮挡和外观变化的情况下。
意图预测:通过分析行人和车辆的行为模式,混合注意力可以预测其未来的运动轨迹和意图,为路径规划提供重要信息。
风险评估:实时评估周围环境的潜在风险,如突然变道的车辆、闯红灯的行人等。混合注意力可以快速识别异常行为并提高警觉级别。
14.3 医疗影像智能诊断
医疗影像分析是混合注意力机制的另一个重要应用领域,其对精度和可解释性的高要求使得注意力机制显得尤为重要。
14.3.1 多模态医学影像融合
影像配准与融合:CT、MRI、PET等不同成像模态提供不同类型的诊断信息。混合注意力可以学习如何有效对齐和融合这些信息。
时序分析:通过分析患者不同时期的影像数据,混合注意力可以追踪病变的发展过程,为治疗效果评估提供支持。
多分辨率分析:医学影像往往需要在不同分辨率下进行分析。混合注意力可以自动选择合适的分辨率和关注区域。
14.3.2 辅助诊断系统
病灶检测与定位:混合注意力可以帮助系统准确定位病变区域,提供与专家标注高度一致的诊断建议。
分级诊断:根据病变的严重程度进行分级,混合注意力可以学习不同级别病变的特征模式。
诊断解释:通过可视化注意力图,系统可以向医生解释其诊断依据,提高诊断的可信度和可接受度。
14.4 新兴应用领域探索
14.4.1 增强现实与虚拟现实
实时物体识别:在AR/VR应用中,需要实时识别和跟踪环境中的物体。混合注意力可以提高识别的准确性和鲁棒性。
手势识别:准确识别用户的手势指令,混合注意力可以关注手部的关键关节点和运动轨迹。
场景理解:理解三维空间中的物体关系和空间布局,为虚拟物体的放置和交互提供支持。
14.4.2 机器人视觉系统
操作引导:在机器人抓取任务中,混合注意力可以识别物体的关键抓取点和操作区域。
导航规划:通过分析环境信息,混合注意力可以识别可通行区域和障碍物,为路径规划提供支持。
人机协作:在人机协作场景中,混合注意力可以理解人类的意图和动作,实现更自然的交互。
15. 总结与技术展望 🚀
15.1 技术成果回顾
通过本篇文章的深入探讨,我们全面分析了混合注意力机制的理论基础、技术实现和应用实践。混合注意力作为深度学习领域的重要技术发展,已经在多个应用场景中展现出显著的性能提升。
15.1.1 核心技术突破
多维度信息融合:混合注意力成功地将空间、通道、时序等多种注意力机制有机结合,实现了比单一注意力机制更强的特征表示能力。这种融合不是简单的叠加,而是通过精心设计的融合策略实现协同效应。
自适应权重学习:通过引入学习型的权重分配机制,混合注意力能够根据不同的输入内容和任务需求自动调整各种注意力的相对重要性,实现了真正的自适应处理。
计算效率优化:虽然混合注意力增加了计算复杂度,但通过算子融合、内存优化、动态计算图等技术,实际的计算开销得到了有效控制,使得混合注意力在实际应用中具有可行性。
15.1.2 应用价值验证
性能提升的一致性:在图像分类、目标检测、语义分割等多个基础视觉任务中,混合注意力都带来了一致的性能提升,证明了其通用性和有效性。
实际部署的成功:在医疗影像、自动驾驶、工业检测等关键应用领域,混合注意力已经成功部署并产生实际价值,推动了相关行业的技术进步。
可解释性的增强:混合注意力机制通过提供多层次的注意力可视化,增强了深度学习模型的可解释性,这对于安全关键应用尤为重要。
15.2 技术局限与挑战
尽管混合注意力机制取得了显著成功,但仍然面临一些技术局限和待解决的挑战。
15.2.1 理论理解的深度
注意力交互机制:虽然我们可以设计各种融合策略,但对于不同类型注意力之间复杂交互机制的理论理解仍然有限。这种理解的缺乏限制了我们设计更有效融合策略的能力。
优化理论基础:混合注意力的优化过程涉及多个损失函数和约束条件,其收敛性和稳定性的理论保证仍然不够完善。
泛化能力分析:缺乏对混合注意力泛化能力的理论分析框架,难以预测其在新领域和新任务上的表现。
15.2.2 计算资源需求
硬件依赖性:高效的混合注意力实现往往依赖于特定的硬件特性,如GPU的并行计算能力。在资源受限的环境中,其优势可能大打折扣。
能耗考量:在移动设备和边缘计算场景中,能耗是一个重要制约因素。混合注意力的额外计算可能导致电池续航时间的减少。
实时性挑战:在对实时性要求极高的应用中,如自动驾驶的紧急避障,混合注意力的计算延迟可能成为瓶颈。
15.3 未来发展趋势
15.3.1 技术演进方向
神经架构搜索集成:将神经架构搜索技术与混合注意力相结合,自动发现最优的注意力组合和融合策略,减少人工设计的工作量。
量子计算融合:随着量子计算技术的发展,探索量子注意力机制的可能性,利用量子并行性和叠加态来实现更高效的注意力计算。
生物启发设计:借鉴神经科学对人类注意力机制的最新研究成果,设计更符合生物学原理的混合注意力架构。
跨模态统一框架:开发统一的跨模态注意力框架,能够处理视觉、听觉、语言等多种模态信息的融合,实现真正的多模态理解。
15.3.2 应用领域拓展
元宇宙与数字孪生:在元宇宙和数字孪生应用中,混合注意力可以帮助构建更真实、更智能的虚拟环境。
科学计算加速:在气候建模、分子动力学仿真等科学计算领域,混合注意力可以帮助模型更好地捕获复杂系统中的关键相互作用。
创意内容生成:在艺术创作、内容生成等创意领域,混合注意力可以帮助AI更好地理解创作意图和风格特征。
个性化推荐系统:在推荐系统中,混合注意力可以同时考虑用户的多种行为模式和偏好特征,提供更精准的个性化推荐。
15.4 研究建议与展望
15.4.1 理论研究方向
统一理论框架:建立混合注意力的统一理论框架,深入理解不同注意力机制的本质和相互关系。
优化理论完善:发展针对混合注意力的优化理论,提供收敛性和稳定性的理论保证。
复杂性理论分析:从计算复杂性理论的角度分析混合注意力的计算边界和效率极限。
15.4.2 技术实现建议
标准化与规范化:建立混合注意力的标准化规范,包括接口定义、性能评估标准、部署规范等。
开源生态建设:推动混合注意力相关技术的开源发展,建立完善的工具链和社区支持。
跨学科合作:加强与认知科学、神经科学、心理学等学科的合作,从多学科角度推进注意力机制的研究。
15.4.3 应用实践指导
场景适配策略:针对不同应用场景制定最佳实践指南,帮助开发者选择合适的混合注意力配置。
性能调优方法:总结性能调优的经验和方法,提供系统化的优化指导。
风险评估框架:建立混合注意力应用的风险评估框架,确保其在安全关键应用中的可靠性。
15.5 结语
混合注意力机制作为深度学习领域的重要技术创新,已经在理论发展和实际应用中取得了显著成果。从基础的注意力融合到复杂的多模态理解,从单一任务优化到跨领域应用,混合注意力机制展现出了强大的技术潜力和广阔的应用前景。
随着人工智能技术的不断发展和应用需求的日益增长,混合注意力机制将继续演进和完善。我们相信,通过持续的理论创新、技术优化和应用探索,混合注意力机制将为构建更加智能、高效、可靠的AI系统做出重要贡献。
未来的研究者和工程师需要在理论深度和实用性之间找到平衡,既要追求技术的前沿性和创新性,也要关注工程实现的可行性和部署的便利性。只有这样,混合注意力机制才能真正发挥其应有的价值,推动整个人工智能领域的持续发展。
📖 下期预告
在下一篇文章《第77篇:Transformer Attention架构演进》中,我们将深入探讨Transformer注意力机制的发展历程和技术演进。从原始的Self-Attention到Multi-Head Attention,从BERT的双向编码到GPT的自回归生成,我们将全面分析Transformer注意力架构的设计原理、技术创新和应用突破。
我们将详细解析Position Encoding的数学原理、Attention Mask的设计策略、以及各种高效Attention的优化方法。同时,我们还会探讨Transformer在不同领域的适配方案,包括Vision Transformer、Speech Transformer、以及多模态Transformer的设计思想。
通过对比分析不同Transformer变体的架构特点和性能表现,我们将帮助读者深入理解Transformer注意力机制的核心思想和技术要点,为掌握现代AI架构的精髓奠定坚实基础。敬请期待! 🎯
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
PS:如果你在按照本文提供的方法进行YOLOv8优化后,依然遇到问题,请不要急躁或抱怨!YOLOv8作为一个高度复杂的目标检测框架,其优化过程涉及硬件、数据集、训练参数等多方面因素。如果你在应用过程中遇到新的Bug或未解决的问题,欢迎将其粘贴到评论区,我们可以一起分析、探讨解决方案。如果你有新的优化思路,也欢迎分享给大家,互相学习,共同进步!
🧧🧧 文末福利,等你来拿!🧧🧧
文中讨论的技术问题大部分来源于我在YOLOv8项目开发中的亲身经历,也有部分来自网络及读者提供的案例。如果文中内容涉及版权问题,请及时告知,我会立即修改或删除。同时,部分解答思路和步骤来自全网社区及人工智能问答平台,若未能帮助到你,还请谅解!YOLOv8模型的优化过程复杂多变,遇到不同的环境、数据集或任务时,解决方案也各不相同。如果你有更优的解决方案,欢迎在评论区分享,撰写教程与方案,帮助更多开发者提升YOLOv8应用的精度与效率!
OK,以上就是我这期关于YOLOv8优化的解决方案,如果你还想深入了解更多YOLOv8相关的优化策略与技巧,欢迎查看我专门收集YOLOv8及其他目标检测技术的专栏《YOLOv8实战:从入门到深度优化》。希望我的分享能帮你解决在YOLOv8应用中的难题,提升你的技术水平。下期再见!
码字不易,如果这篇文章对你有所帮助,帮忙给我来个一键三连(关注、点赞、收藏),你的支持是我持续创作的最大动力。
同时也推荐大家关注我的公众号:「猿圈奇妙屋」,第一时间获取更多YOLOv8优化内容及技术资源,包括目标检测相关的最新优化方案、BAT大厂面试题、技术书籍、工具等,期待与你一起学习,共同进步!
🫵 Who am I?
我是计算机视觉、图像识别等领域的讲师 & 技术专家博客作者,CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等社区博客专家,C站博客之星Top30,华为云多年度十佳博主,掘金多年度人气作者Top40,掘金等各大社区平台签约作者,51CTO年度博主Top12,掘金/InfoQ/51CTO等社区优质创作者;全网粉丝合计 30w+;更多精彩福利点击这里;硬核微信公众号「猿圈奇妙屋」,欢迎你的加入!免费白嫖最新BAT互联网公司面试真题、4000G PDF电子书籍、简历模板等海量资料,你想要的我都有,关键是你不来拿。

-End-



















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











