






一、Why:概述与价值
(一)人工智能的发展历史
人工智能是很早就出现的一个概念,起源于上个世纪50年代,之后由于种种原因人工智能经历了几十年的漫长的消沉的过程,直到最近几年人工智能才火热起来。人工智能的发展其实有三次黄金时期:第一次是人工智能概念提出的时候,学者们以为AI技术能改变世界,但是实际上并没有;第二次是上个世纪80年代左右,此时已经提出了神经网络等模拟人脑思考的算法,但是也并没有得到很快的发展;第三次可以认为是从2010年左右开始的,与前两次不一样的是这次我们有大数据为生产资料,以强大的算力、云计算为基础设施,包括IOT和5g技术的发展,有应用场景驱动,比如说搜索就是一个应用人工智能算法的众多场景之一,所以这次是人工智能发展真正的黄金时期。

(二)为什么需要MaxCompute+AI
Garter在数据分析领域的是大趋势预测如下:

从中可以看出,Garter认为在未来数据与分析的边界逐渐模糊,并且预测在2022年,40%的机器学习工作将在非以机器学习为主要目的的平台上(如数据仓库)完成。因此,可以说MaxCompute+AI是大势所趋。
因为数据仓库承载的是整个企业的数据资产,尤其是MaxCompute,它是一个从TB到EB级,能够弹性扩展大量存储能力的数据平台,所以数据仓库内置机器学习的优势非常明显:
1.无需移动数据(数据量大),降低基础设施成本、人工成本、减少数据安全风险;
2.数据访问速度快(让算法找数据);
3.可扩展性强;
4.纯 SQL ML / Python 更易用。而且数据仓库内置机器学习是各角色均收益的一种集成:对于商务人士来说,新想法可以快速得到快速试验,ROI得到提升;对于数据科学家和数据分析师来说,大部分工作通过SQL/Python实现,易用高效,且模型开发和生产环境可以无缝对接;对于数据库管理员(DBA)来说,数据管理更加简单,安全性更高。
(三)MaxCompute现有的AI能力
MaxCompute的产品特性在之前的讲座中已经具体讲过了,这里不再赘述,其中MaxCompute集成AI的能力主要有:
- 1.提供SQLML,可以直接使用标准SQL训练机器学习模型,并对数据进行预测分析;
- 2.Mars:使用python科学计算、机器学习三方库;
- 3.可以用用户熟悉的Spark-ML开展智能分析;
- 4.与PAI无缝集成,提供强大的机器学习处理能力。
上述的集成AI能力中,SQLML和Mars是MaxCompute的两个原生AI扩展能力,本文我们重点介绍这两个能力。

为什么选择SQL和Python这两种语言呢?主要是因为SQL和Python是当前数据处理和机器学习领域中最火的两种语言。下面两张图是SQL查询语言的发展及现状以及Python的发展。
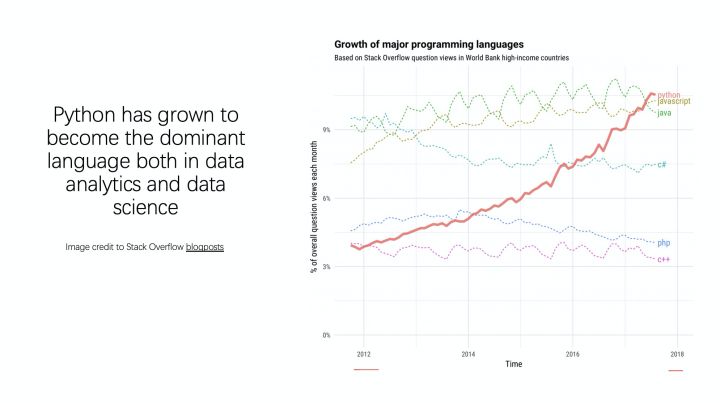
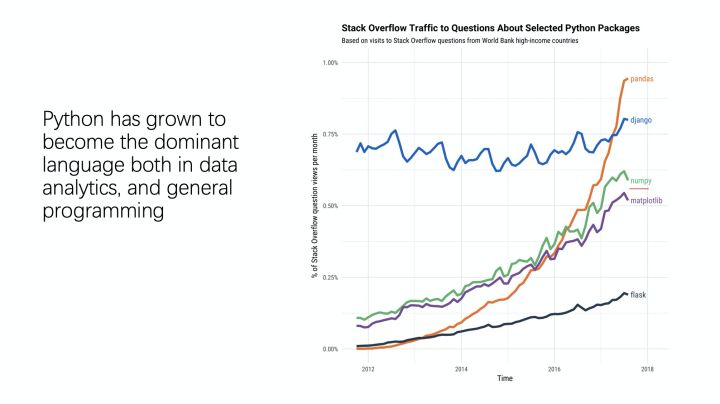
对于数据处理语言来讲,关系型数据库,也就是以SQL为基础的关系型数据库,包括类似的数据库目前仍然占据了数据处理引擎的前几名,有着稳健的生态;而Python已经逐渐成为数据分析领域和数据科学领域的主流语言,其有着强大的机器学习生态。因此选择这两种语言作为MaxCompute的AI集成,既是大势所趋,又能减轻使用者的学习成本和迁移成本。
二、What:能力与应用
我们将该项目的名字叫Mars,其最早是意味着Matrix和array,当然现在已经不再局限于这两者,数据维度可以达到非常高的程度;第二是意味着我们向着比登月更高的目标出发,不断的挑战自己。
那么我们为什么要做Mars呢?其主要原因有:
- 1.为大规模科学计算设计的:传统的大数据引擎编程接口对科学计算不太友好,框架设计也不是为科学计算模型考虑的;
- 2.传统科学计算大多基于单机,而大规模科学计算需要用到超算,并非普通人所能寄予的能力;
- 3.传统SQL模型科学计算的处理能力不足,做一些简单的科学计算,比如矩阵转置等等,效率也是非常低;
- 4.目前R和Python基本上基于单机,其分布式扩展能力比较弱。
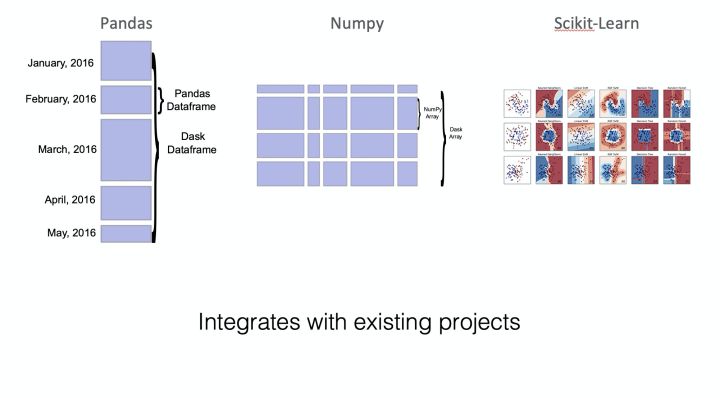
目前,Mars是唯一的商业化的大规模科学计算引擎,关于Mars的更多信息大家可以到阿里云官网查找。Mars的基本思路如下图所示,主要是将Python中的主流科学计算和机器学习的库做相应的分布式化处理。
三、How:最佳实践
下面是一个简单的SQLML的Demo介绍。
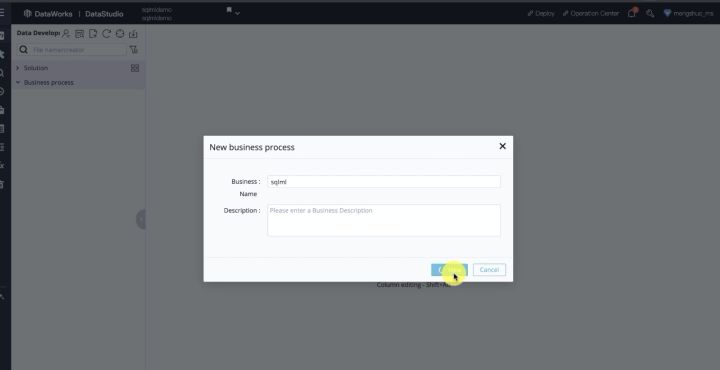
首先,我们在DataWorks中新建一个工作流,会发现工作流中有很多组件,我们先建一个临时查询,如下图所示:
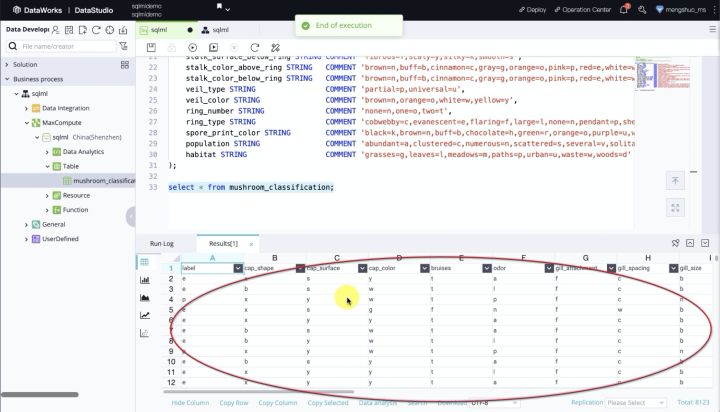
然后新建一张表,其中保存的是关于蘑菇的一些属性,根据这些属性数据,我们可以对其进行分类。
表建立好之后,我们可以将数据导入,因为该数据集比较小,所以我们从本地上传csv文件,将列与表中的字段对应即可:
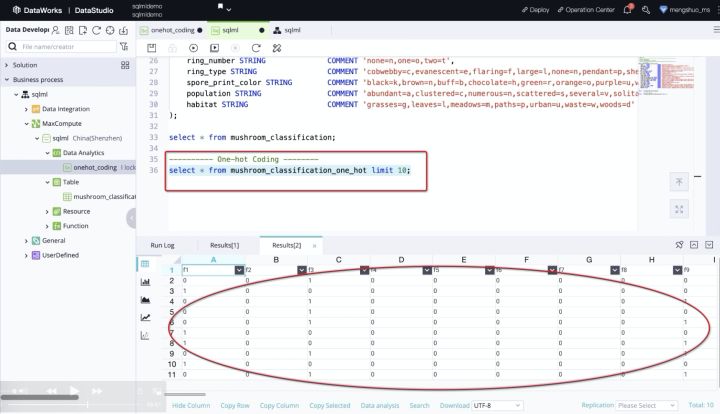
之后,我们需要对特征进行onehot编码,其结果如下图所示:
然后,我们将数据分成训练集和测试集,并且分别将训练集和测试集导入一张单独的表中,之后就可以创建模型了,这里我们用的是逻辑回归,一个常用的二分类算法:

运行模型,很便捷地就可以得到训练结果:
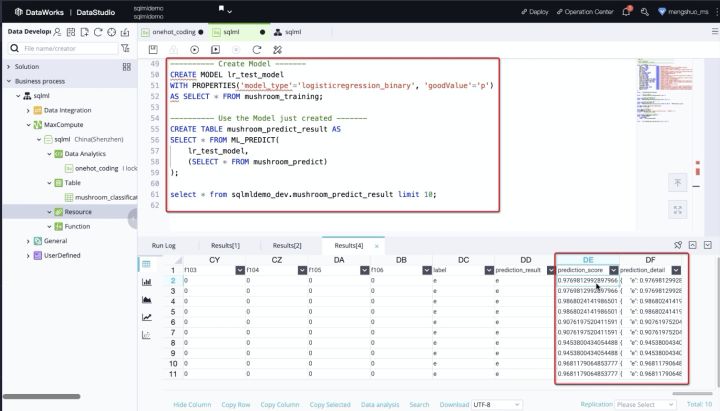
通过上面的Demo,我们很容易的就完成了一次机器学习的训练过程,其过程类似与使用SQL中的UDF,简便、高效。上面Demo介绍的是SQLML,如果想使用Mars也非常简单,我们只需要拖拽PyODPS3组件即可,如下图所示。
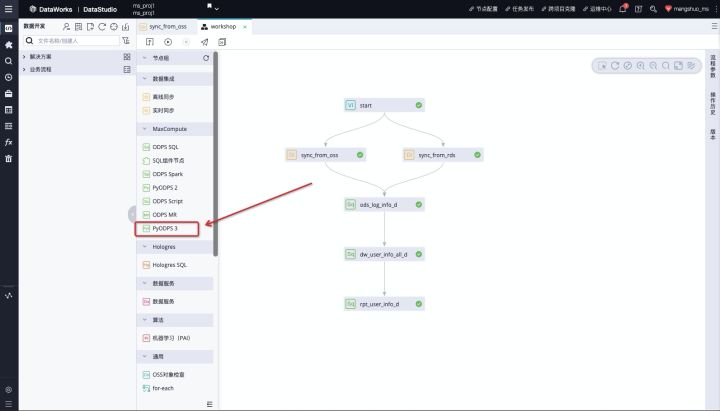
目前,Mars已经可以试用,SQLML马上就会和大家见面,欢迎大家进行试用。
本文为阿里云原创内容,未经允许不得转载。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









