










近年来,深度学习在计算机视觉、自然语言处理等领域大放异彩。这些领域所面对的数据都是结构化的,如图像、音频、文本等,它们内部都有明确的排列规则。结构化的数据由于具有这些确定的规则而方便处理,但是在现实生活中,非结构化的关系数据才是主流。我们无时无刻不在面临着关系数据:构成物质的分子是一种由各种原子组成的关系网络;人类社会是一种以人为节点组成的社交网络;整个宇宙更是一种异质、非均匀的大型网络。有实体的地方一定有关系,关系中同样蕴藏着丰富的信息。与一般的深度学习方法不同,图神经网络(GNN)是一种可用来从网络(图)提取信息的方法,在原有特征的基础上,它进一步结合网络(图)的结构来学习更全面的节点表示,从而使下游任务有更好的表现。
图卷积网络是 GNN 的其中一类,本文主要对图卷积做一个简单的概述,包括问题分类、图卷积原理以及 GCN 的变种。之后再通过一个简单的论文分类应用来加深对图卷积的理解。
1 图卷积概述
1.1 问题分类
GNN 所面临的问题大体可分为三个层面:节点级别的,如节点的分类任务;边级别的,如边的预测任务;图级别的,如图的分类任务。其中节点级别与边级别的任务本质都为学习节点的表示,而图级别的任务则是学习图的表示。这些问题也有监督学习、半监督学习与无监督学习之分。
1.2 核心思想
图卷积有许多变种,其原型是GCN[1](图卷积网络),这里以 GCN 为例来展现图卷积的核心思想。卷积神经网络是众多深度网络的核心,因此在探究基于图的学习算法时,研究人员也尝试将“卷积”引入,GCN 应运而生。GCN 可从两个层面进行理解,一种是基于图信号处理的角度,另一种是基于空间信息聚合的角度。图信号处理更本质,空间信息聚合则更直观。
1.2.1 图信号处理

也即 GCN 的形式,其中

1.2.2 空间信息聚合
如果不管 GCN 的数学推导,仅观察最终 GCN 的计算方式,可发现它就是先将图节点特征 通过一个全连接网络,再基于图结构进行一阶邻域信息的聚合,如图 2.1 所示。当有多层卷积时,GCN 相当于将节点的多阶邻域信息聚合,即每个节点都可以看到更远的特征与结构。以这种角度看 GCN 则已经完全没有了卷积的概念,只剩下空间中的信息聚合。
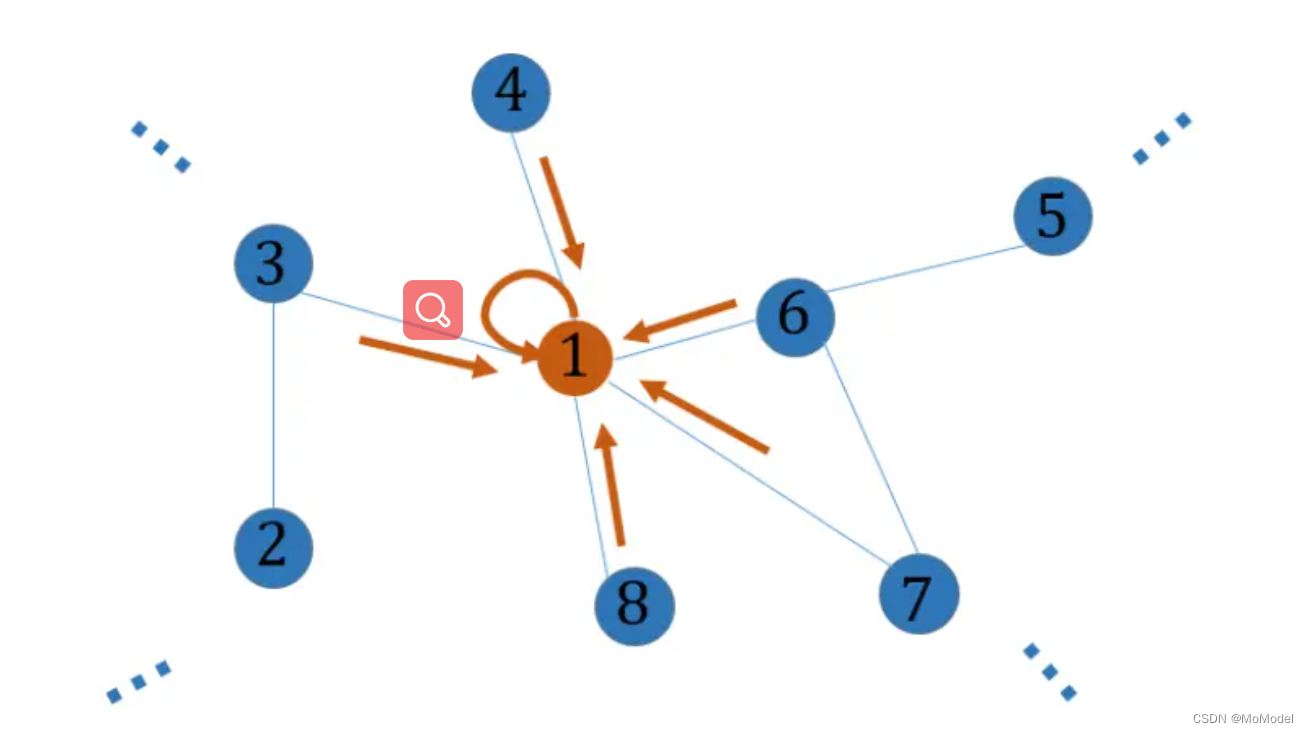
图 1.1 节点信息的空间聚合示意
尽管谱卷积有优美的数学推导,但目前空间卷积比谱卷积更受研究人员的青睐,这主要是因为谱卷积有很多限制。运用谱卷积时需要输入整图进行学习,一旦图的尺度非常大,该方法就需要耗费极大的空间、时间复杂度,因此谱卷积对于图尺度的鲁棒性不佳。也正是因为谱卷积需要明确整图,所以它属于直推式(Transductive)方法,即它需要在训练过程中就看见包括测试数据在内的所有信息,而现实应用一般都要求算法是归纳式(Inductive)的,即能归纳出训练集的规律,将其用在未知的数据集上。与之相比,空间卷积的定义更加灵活,可以根据不同的需求设计出不同的结构,因此它可以更好的规避这些不足。
然而,不断简化后的 GCN 已经没有了“卷积” 的影子, 因此它也可直接作为归纳式方法使用。
1.3 GCN 的变种
从空间角度进行推导,可根据不同的信息聚合方式定义不同的 GCN,比较经典的有 GAT 与 GrahSAGE 等。GCN 在聚合邻域信息时对邻域节点一视同仁,如图 2.2(a) 所示,GAT 则进一步学习每个邻域节点的信息对当前节点的重要程度,图中不同颜色代表了聚合时需要乘上不同的权重。GraphSAGE 是加强版 Inductive 形式的 GCN,它将节点的信息聚合分成采样与聚合两个步骤。如图 2.2(b) 所示,黄色节点为被选中的信息聚合节点,并且在聚合过程中使用 pooling、LSTM 等方法。
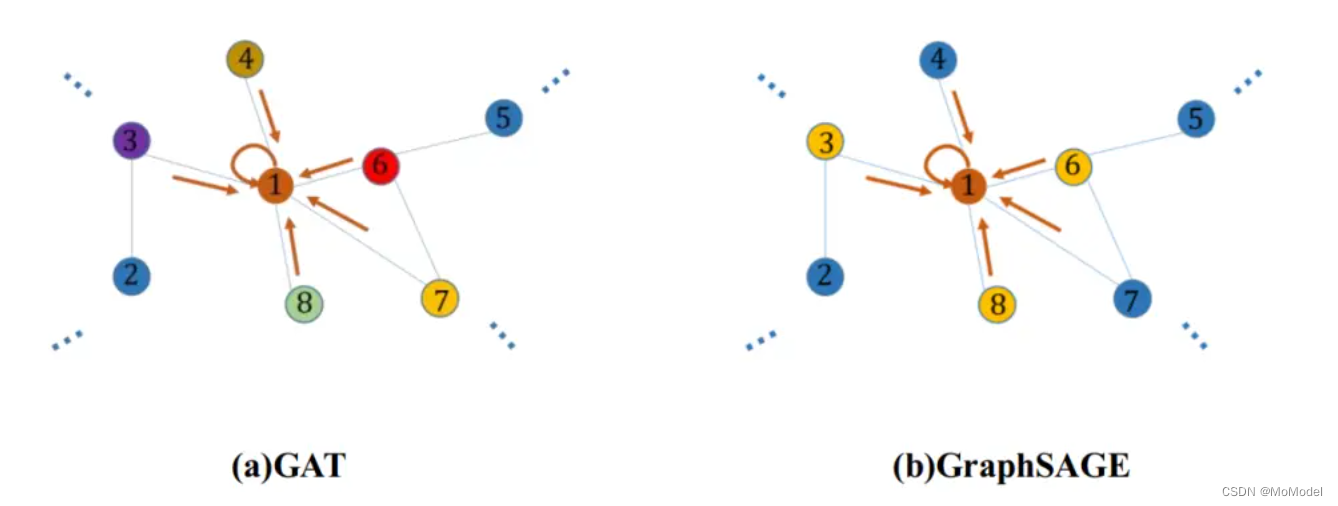
图 1.2 GAT 与 GraphSAGE 信息聚合示意
GCN 的变种还有很多,根据不同的应用场合可设计特定的聚合方式,如在交通流量预测任务中有时空图卷积 STGCN,在金融反欺诈任务有 GenePath、GEM 等变种。
2 基于 GCN 的论文分类
2.1 数据集
本实验所用的数据集为 Cora、Citeseer、PubMed [2]。表 2.1 展示了各数据集的详细信息。

数据集包含每篇论文的稀疏词袋特征向量和论文之间的引用链接列表,并将引文链接视为无向的边,以此可构建一个二进制的、对称的邻接矩阵。每篇论文都有一个类标签。在训练时,将数据集按节点随机分为有标签节点与无标签节点,比例为2:8.
2.2 模型
论文分类任务相对简单,用基础的 GCN 就能完成,设计如图2.1所示的模型。
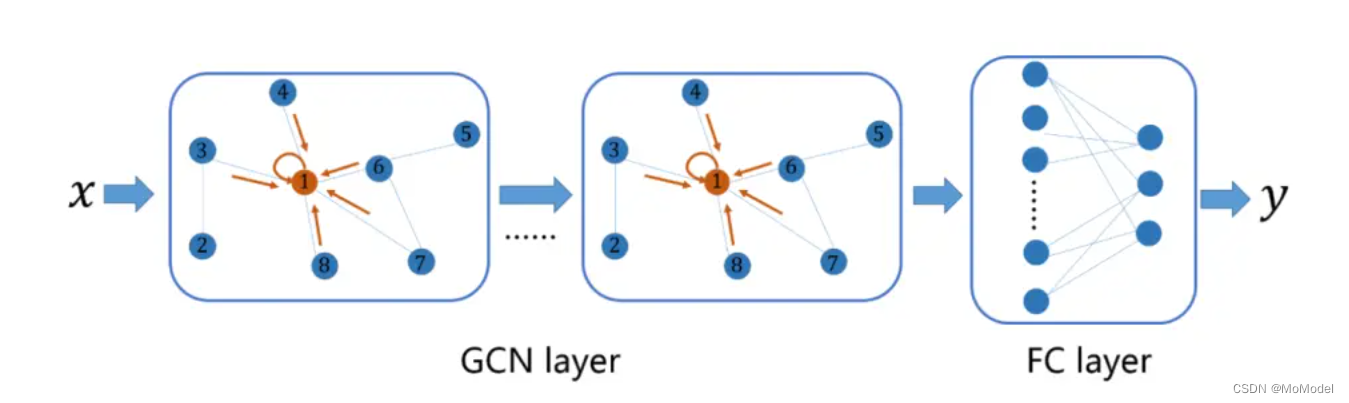
图 2.1 基于 GCN 的论文分类模型
每个节点都代表一篇论文,边则代表论文之间存在的引用关系。节点的初始特征为论文的词袋。上述模型表示先通过若干层 GCN 学习节点的表示,使之含有引用信息,最后基于学习到的表示通过全连接层做的分类。
该任务属于半监督学习,因此在学习过程中,只根据有标签的节点所产生的损失进行梯度下降。
2.3 算法实现细节
图 2.2 展示了所设置的模型具体参数及其前向传播过程(以Cora数据集为例)。
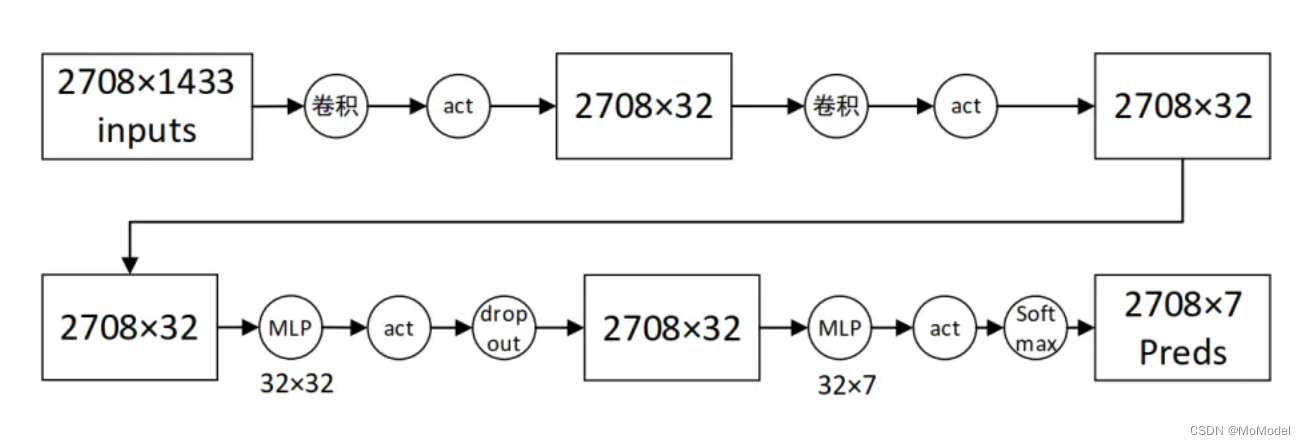
图 2.2 某组参数下模型的前向传播过程
算法实现可基于 PyTorch Geometry 工具包,数据集管理、GCN 层的实现可直接调用了 api 函数。优化器采用 adam,学习率设为 0.002,衰减率为 5e-4. Epoch设为 200,bachsize 为整体数据集的大小。使用交叉熵为模型的损失函数。
2.4 结果分析
2.4.1 两层 GCN 网络
按上述参数进行实验,模型训练过程的精度曲线与损失曲线如图2.3所示
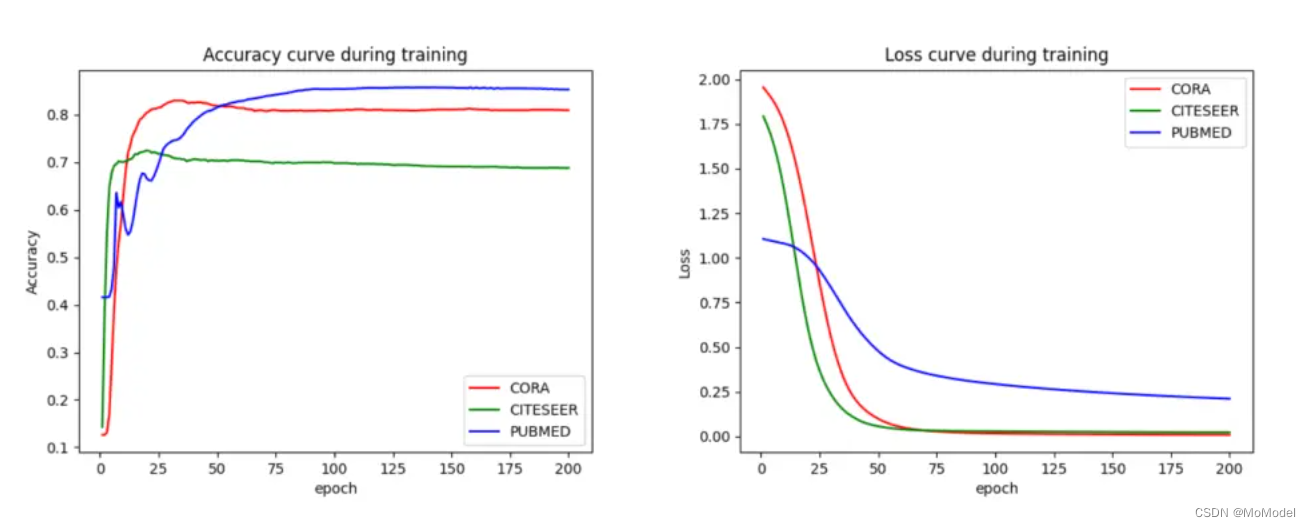
图 2.3 精度曲线与损失曲线
模型训练非常快,且最终效果都不错,在 Cora、citeseer 以及 PubMed 数据集上分别可以达到 82.4%、70.0%、85.3% 的精度。每个数据集各训练 5 次取平均后可得到平均分类精度为 78.36% 。由此可得 GCN 对图数据的信息提取能力非常强。
2.4.2 16 层 GCN 网络
进一步探索不同数量的 GCN 层对于模型性能的影响,图 2.4 为 当GCN层堆叠到16层时模型训练过程的精度曲线与损失曲线。
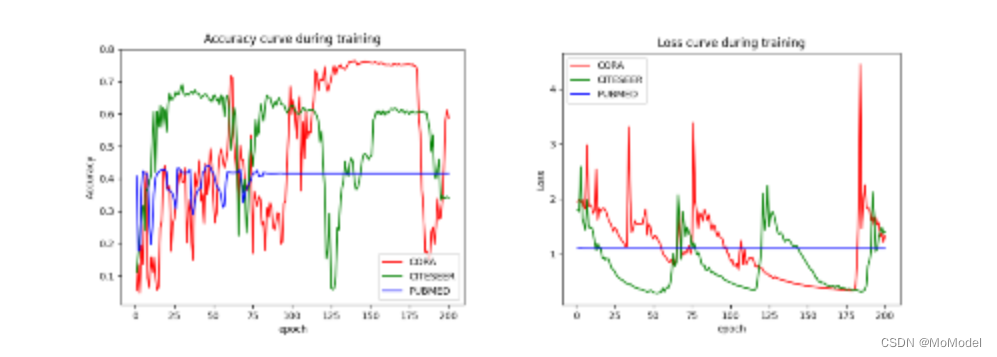
图 2.4 16 层 GCN 时的训练过程
训练结果显示不仅精度没有上升,层数直接影响了整个训练过程。这是因为 GCN 的本质是节点邻域间的信息聚合, 层表示 级邻域,由于该图比较小,图的直径也比较小,节点在跳跃16次之后基本可以到达任意节点,这也就意味着当经过 16 层的信息聚合后,每个节点的信息包含了整个图的信息,这间接缩小了每个节点之间的相似性,对节点分类任务而言增加了难度。
这个例子从反面表现出 GCN 的工作原理,且表明了 GCN 的层数应依据网络的大小而定,有时本意是希望通过GCN 学习到节点局部子图的信息,但当层数过多时,它实际早已学到了整个图的全局信息。
参考文献
1.Kipf T N , Welling M . Semi-Supervised Classification with Graph Convolutional Networks[J]. 2016.
2.Yang, Zhilin , W. W. Cohen , and R. Salakhutdinov . "Revisiting Semi-Supervised Learning with Graph Embeddings. " International Conference on International Conference on Machine Learning JMLR.org, 2016.
欢迎关注我们的微信公众号:MomodelAI
同时,欢迎使用 「Mo AI编程」 微信小程序
以及登录官网,了解更多信息:Mo 平台
Mo,发现意外,创造可能















 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









