




 通过爬取拉勾网的数据,分析了各城市数据分析岗位的需求、细分领域的需求、薪资状况、工作经验与薪水的关系、技能要求及学历要求。结果显示一线城市需求大,尤其北上广深,Python/R和SQL技能需求高,本科学历为主,工作经验与薪资正相关。
通过爬取拉勾网的数据,分析了各城市数据分析岗位的需求、细分领域的需求、薪资状况、工作经验与薪水的关系、技能要求及学历要求。结果显示一线城市需求大,尤其北上广深,Python/R和SQL技能需求高,本科学历为主,工作经验与薪资正相关。
通过拉勾网的数据分析数据分析行情
1、明确需求和目的
- 针对当前形势下分析数据分析岗位的行情。
- 选取某一/某些招聘平台上的招聘数据来进行数据分析。
- 对于各大城市、各种规模的数据分析需求进行详细的分析与总结。
2、数据准备
- 数据来源为某位伟大的贡献者提供的爬虫和数据文件,是爬取拉勾网上的招聘数据信息。
- 数据文件集为"lagou.csv",其中共有3140行数据,52具体特征。
3、数据处理
3.1 数据整合
3.1.1 加载相关的库包和数据集
- 其中用到的库包主要包括pandas、numpy、matplotlib、seaborn和pyecharts
- 使用的数据集是lagou.csv
# 导入相应的库包以及设置相应的格式
import pandas as pd
import numpy as np
import seaborn as sns
from pyecharts.charts import Pie
from pyecharts import options as opts
import matplotlib.pyplot as plt
% matplotlib inline
sns.set_style('white',{
'font.sans-serif': ['simhei', 'Arial']})
# 可以选择展示最大的行列数
# pd.set_option("display.max_column", None)
# pd.set_option("display.max_row", None)
# 导入数据集并查看数据中的前3个数据
df = pd.read_csv('./lagou.csv')
df.head(3)
# 如果想查看最后面的几个数据可以使用tail()
# df.tail(3)
# 如果想要随机检查几个数据可以使用sample()
# df.sample(3)
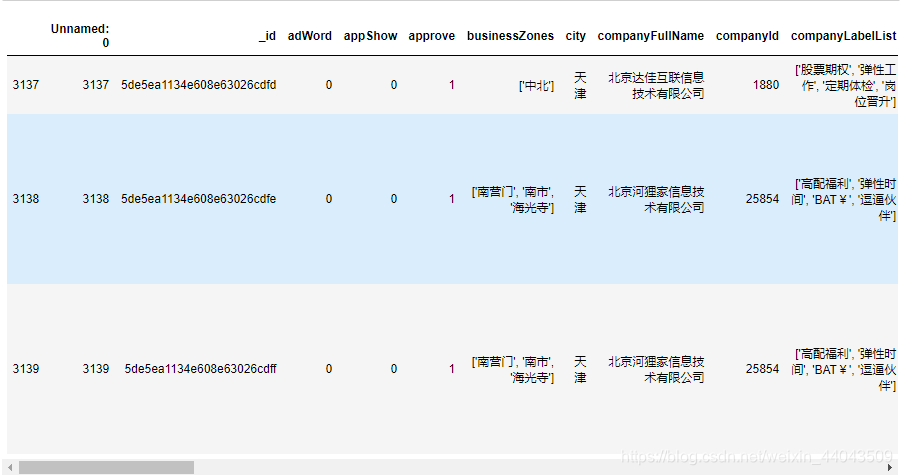
3.1.2 数据概览
- 我们先看一下数据集的大小(行列情况):
df.shape
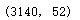
2. 接着看一下这个数据集中的列名(特征):
df.columns

3.2 数据清洗
3.2.1 数据挑选与去重
# 取出我们进行后续分析所需的字段
columns = ["positionName", "companyShortName", "city", "companySize", "education", "financeStage",
"industryField", "salary", "workYear", "hitags", "companyLabelList", "job_detail"]
df = df[columns].drop_duplicates() #去重
# 查看挑选后的数据长度
len(df)
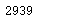
3.2.2 去掉非数据分析岗的数据
- 我们的目标只有一点——数据分析岗位,对于其他的数据我们并不需要。
# 数据分析相应的岗位数量
cond_1 = df["positionName"].str.contains("数据分析") # 职位名中含有数据分析字眼的
cond_2 = ~df["positionName"].str.contains("实习") # 剔除掉带实习字眼的
len(df[cond_1 & cond_2]["positionName"])
# 筛选出我们想要的字段,并剔除positionName
df = df[cond_1 & cond_2]
df.drop(["positionName"], axis=1, inplace=True)
df.reset_index(drop=True, inplace=True)
- 因为拉勾网爬取下来的薪水是一个区间,这里我们用薪水区间的均值作为相应职位的薪水。
# 处理过程
#1、将salary中的字符串均小写化(因为存在8k-16k和8K-16K)
#2、运用正则表达式提取出薪资区间
#3、将提取出来的数字转化为int型
#4、取区间的平均值
df["salary"] = df["salary"].str.lower()\
.str.extract(r'(\d+)[k]-(\d+)k')\
.applymap(lambda x:int(x))\
.mean(axis=1)
从job_detail中提取出技能要求
我们将技能分为以下几类:
- Python/R
- SQL
- Tableau
- Excel
处理方式: 如果job_detail中含有上述四类,则赋值为1,不含有则为0。
df["job_detail"] = df["job_detail"].str.lower().fillna("") #将字符串小写化,并将缺失值赋值为空字符串
df["Python/R"] = df["job_detail"].map(lambda x: 1 if ('python' in x) or ('r' in x) else 0)
df["SQL"] = df["job_detail"].map(lambda x: 1 if ('sql' in x) or ('hive' in x) else 0)
df["Tableau"] = df["job_detail"].map(lambda x: 1 if 'tableau' in x else 0)
df["Excel"] = df["job_detail"].map(lambda x: 1 if 'excel' in x else 0)
# 我们随机产看整理过后的数据情况
df.sample(3)
3. 处理行业信息
def clean_industry(industry):
industry = industry.split(",")
if industry[0]=="移动互联网" and len(industry)>1:
return industry[1]
else:
return industry[0]
df["industryField"< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7446
7446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









