







一、Go语言函数声明
普通函数声明(定义)
函数声明包括函数名、形式参数列表、返回值列表(可省略)以及函数体。
func 函数名(形式参数列表)(返回值列表){
函数体
}
形式参数列表描述了函数的参数名以及参数类型,这些参数作为局部变量,其值由参数调用者提供,返回值列表描述了函数返回值的变量名以及类型,如果函数返回一个无名变量或者没有返回值,返回值列表的括号是可以省略的。
如果一个函数声明不包括返回值列表,那么函数体执行完毕后,不会返回任何值,在下面的 hypot 函数中:
func hypot(x, y float64) float64 {
return math.Sqrt(x*x + y*y)
}
fmt.Println(hypot(3,4)) // "5"
x 和 y 是形参名,3 和 4 是调用时的传入的实数,函数返回了一个 float64 类型的值,返回值也可以像形式参数一样被命名,在这种情况下,每个返回值被声明成一个局部变量,并根据该返回值的类型,将其初始化为 0。
如果一个函数在声明时,包含返回值列表,那么该函数必须以 return 语句结尾,除非函数明显无法运行到结尾处,例如函数在结尾时调用了 panic 异常或函数中存在无限循环。
正如 hypot 函数一样,如果一组形参或返回值有相同的类型,我们不必为每个形参都写出参数类型,下面 2 个声明是等价的:
func f(i, j, k int, s, t string) { /* ... */ }
func f(i int, j int, k int, s string, t string) { /* ... */ }
下面,我们给出 4 种方法声明拥有 2 个 int 型参数和 1 个 int 型返回值的函数,空白标识符 _ 可以强调某个参数未被使用。
func add(x int, y int) int {return x + y}
func sub(x, y int) (z int) { z = x - y; return}
func first(x int, _ int) int { return x }
func zero(int, int) int { return 0 }
fmt.Printf("%T\n", add) // "func(int, int) int"
fmt.Printf("%T\n", sub) // "func(int, int) int"
fmt.Printf("%T\n", first) // "func(int, int) int"
fmt.Printf("%T\n", zero) // "func(int, int) int"
函数的类型被称为函数的标识符,如果两个函数形式参数列表和返回值列表中的变量类型一一对应,那么这两个函数被认为有相同的类型和标识符,形参和返回值的变量名不影响函数标识符也不影响它们是否可以以省略参数类型的形式表示。
每一次函数在调用时都必须按照声明顺序为所有参数提供实参(参数值),在函数调用时,Go语言没有默认参数值,也没有任何方法可以通过参数名指定形参,因此形参和返回值的变量名对于函数调用者而言没有意义。
在函数中,实参通过值传递的方式进行传递,因此函数的形参是实参的拷贝,对形参进行修改不会影响实参,但是,如果实参包括引用类型,如指针、slice(切片)、map、function、channel 等类型,实参可能会由于函数的间接引用被修改。
函数的返回值
Go语言支持多返回值,多返回值能方便地获得函数执行后的多个返回参数,Go语言经常使用多返回值中的最后一个返回参数返回函数执行中可能发生的错误,示例代码如下:
conn, err := connectToNetwork()
在这段代码中,connectToNetwork 返回两个参数,conn 表示连接对象,err 返回错误信息。
其它编程语言中函数的返回值
C/C++ 语言中只支持一个返回值,在需要返回多个数值时,则需要使用结构体返回结果,或者在参数中使用指针变量,然后在函数内部修改外部传入的变量值,实现返回计算结果,C++ 语言中为了安全性,建议在参数返回数据时使用“引用”替代指针。
C# 语言也没有多返回值特性,C# 语言后期加入的 ref 和 out 关键字能够通过函数的调用参数获得函数体中修改的数据。
lua 语言没有指针,但支持多返回值,在大块数据使用时方便很多。
Go语言既支持安全指针,也支持多返回值,因此在使用函数进行逻辑编写时更为方便。
1) 同一种类型返回值
如果返回值是同一种类型,则用括号将多个返回值类型括起来,用逗号分隔每个返回值的类型。
使用 return 语句返回时,值列表的顺序需要与函数声明的返回值类型一致,示例代码如下:
func typedTwoValues() (int, int) {
return 1, 2
}
func main() {
a, b := typedTwoValues()
fmt.Println(a, b)
}
代码输出结果:
1 2
纯类型的返回值对于代码可读性不是很友好,特别是在同类型的返回值出现时,无法区分每个返回参数的意义。
2) 带有变量名的返回值
Go语言支持对返回值进行命名,这样返回值就和参数一样拥有参数变量名和类型。
命名的返回值变量的默认值为类型的默认值,即数值为 0,字符串为空字符串,布尔为 false、指针为 nil 等。
下面代码中的函数拥有两个整型返回值,函数声明时将返回值命名为 a 和 b,因此可以在函数体中直接对函数返回值进行赋值,在命名的返回值方式的函数体中,在函数结束前需要显式地使用 return 语句进行返回,代码如下:
func namedRetValues() (a, b int) {
a = 1
b = 2
return
}
代码说明如下:
第 1 行,对两个整型返回值进行命名,分别为 a 和 b。
第 3 行和第 4 行,命名返回值的变量与这个函数的布局变量的效果一致,可以对返回值进行赋值和值获取。
第 6 行,当函数使用命名返回值时,可以在 return 中不填写返回值列表,如果填写也是可行的,下面代码的执行效果和上面代码的效果一样。
func namedRetValues() (a, b int) {
a = 1
return a, 2
}
提示
同一种类型返回值和命名返回值两种形式只能二选一,混用时将会发生编译错误,例如下面的代码:
func namedRetValues() (a, b int, int)
编译报错提示:
mixed named and unnamed function parameters
意思是:在函数参数中混合使用了命名和非命名参数。
调用函数
函数在定义后,可以通过调用的方式,让当前代码跳转到被调用的函数中进行执行,调用前的函数局部变量都会被保存起来不会丢失,被调用的函数运行结束后,恢复到调用函数的下一行继续执行代码,之前的局部变量也能继续访问。
函数内的局部变量只能在函数体中使用,函数调用结束后,这些局部变量都会被释放并且失效。
Go语言的函数调用格式如下:
返回值变量列表 = 函数名(参数列表)
下面是对各个部分的说明:
函数名:需要调用的函数名。
参数列表:参数变量以逗号分隔,尾部无须以分号结尾。
返回值变量列表:多个返回值使用逗号分隔。
例如,加法函数调用样式如下:
result := add(1,1)
二、Go语言函数变量——把函数作为值保存到变量中
在Go语言中,函数也是一种类型,可以和其他类型一样保存在变量中,下面的代码定义了一个函数变量 f,并将一个函数名为 fire() 的函数赋给函数变量 f,这样调用函数变量 f 时,实际调用的就是 fire() 函数,代码如下:
package main
import (
"fmt"
)
func fire() {
fmt.Println("fire")
}
func main() {
var f func()
f = fire
f()
}
代码输出结果:
fire
代码说明:
第 7 行,定义了一个 fire() 函数。
第 13 行,将变量 f 声明为 func() 类型,此时 f 就被俗称为“回调函数”,此时 f 的值为 nil。
第 15 行,将 fire() 函数作为值,赋给函数变量 f,此时 f 的值为 fire() 函数。
第 17 行,使用函数变量 f 进行函数调用,实际调用的是 fire() 函数。
三、Go语言匿名函数
定义一个匿名函数
匿名函数的定义格式如下:
func(参数列表)(返回参数列表){
函数体
}
匿名函数的定义就是没有名字的普通函数定义。
1) 在定义时调用匿名函数
匿名函数可以在声明后调用,例如:
func(data int) {
fmt.Println("hello", data)
}(100)
注意第3行}后的(100),表示对匿名函数进行调用,传递参数为 100。
2) 将匿名函数赋值给变量
匿名函数可以被赋值,例如:
// 将匿名函数体保存到f()中
f := func(data int) {
fmt.Println("hello", data)
}
// 使用f()调用
f(100)
匿名函数的用途非常广泛,它本身就是一种值,可以方便地保存在各种容器中实现回调函数和操作封装。
匿名函数用作回调函数
下面的代码实现对切片的遍历操作,遍历中访问每个元素的操作使用匿名函数来实现,用户传入不同的匿名函数体可以实现对元素不同的遍历操作,代码如下:
package main
import (
"fmt"
)
// 遍历切片的每个元素, 通过给定函数进行元素访问
func visit(list []int, f func(int)) {
for _, v := range list {
f(v)
}
}
func main() {
// 使用匿名函数打印切片内容
visit([]int{1, 2, 3, 4}, func(v int) {
fmt.Println(v)
})
}
代码说明如下:
第 8 行,使用 visit() 函数将整个遍历过程进行封装,当要获取遍历期间的切片值时,只需要给 visit() 传入一个回调参数即可。
第 18 行,准备一个整型切片 []int{1,2,3,4} 传入 visit() 函数作为遍历的数据。
第 19~20 行,定义了一个匿名函数,作用是将遍历的每个值打印出来。
匿名函数作为回调函数的设计在Go语言的系统包中也比较常见,strings 包中就有类似的设计,代码如下:
func TrimFunc(s string, f func(rune) bool) string {
return TrimRightFunc(TrimLeftFunc(s, f), f)
}
使用匿名函数实现操作封装
下面这段代码将匿名函数作为 map 的键值,通过命令行参数动态调用匿名函数,代码如下:
package main
import (
"flag"
"fmt"
)
var skillParam = flag.String("skill", "", "skill to perform")
func main() {
flag.Parse()
var skill = map[string]func(){
"fire": func() {
fmt.Println("chicken fire")
},
"run": func() {
fmt.Println("soldier run")
},
"fly": func() {
fmt.Println("angel fly")
},
}
if f, ok := skill[*skillParam]; ok {
f()
} else {
fmt.Println("skill not found")
}
}
代码说明如下:
第 8 行,定义命令行参数 skill,从命令行输入 --skill 可以将 = 后的字符串传入 skillParam 指针变量。
第 12 行,解析命令行参数,解析完成后,skillParam 指针变量将指向命令行传入的值。
第 14 行,定义一个从字符串映射到 func() 的 map,然后填充这个 map。
第 15~23 行,初始化 map 的键值对,值为匿名函数。
第 26 行,skillParam 是一个 *string 类型的指针变量,使用 *skillParam 获取到命令行传过来的值,并在 map 中查找对应命令行参数指定的字符串的函数。
第 29 行,如果在 map 定义中存在这个参数就调用,否则打印“技能没有找到”。
运行代码,结果如下:
PS D:\code> go run main.go --skill=fly
angel fly
PS D:\code> go run main.go --skill=run soldier run
四、Go语言函数类型实现接口
package main
import (
"fmt"
)
// 调用器接口
type Invoker interface {
// 需要实现一个Call方法
Call(interface{})
}
// 结构体类型
type Struct struct {
}
// 实现Invoker的Call
func (s *Struct) Call(p interface{}) {
fmt.Println("from struct", p)
}
// 函数定义为类型
type FuncCaller func(interface{})
// 实现Invoker的Call
func (f FuncCaller) Call(p interface{}) {
// 调用f函数本体
f(p)
}
func main() {
// 声明接口变量
var invoker Invoker
// 实例化结构体
s := new(Struct)
// 将实例化的结构体赋值到接口
invoker = s
// 使用接口调用实例化结构体的方法Struct.Call
invoker.Call("hello")
// 将匿名函数转为FuncCaller类型,再赋值给接口
invoker = FuncCaller(func(v interface{}) {
fmt.Println("from function", v)
})
// 使用接口调用FuncCaller.Call,内部会调用函数本体
invoker.Call("hello")
}
有如下一个接口:
// 调用器接口
type Invoker interface {
// 需要实现一个Call()方法
Call(interface{})
}
这个接口需要实现 Call() 方法,调用时会传入一个 interface{} 类型的变量,这种类型的变量表示任意类型的值。
接下来,使用结构体进行接口实现。
结构体实现接口
结构体实现 Invoker 接口的代码如下:
// 结构体类型
type Struct struct {
}
// 实现Invoker的Call
func (s *Struct) Call(p interface{}) {
fmt.Println("from struct", p)
}
代码说明如下:
第 2 行,定义结构体,该例子中的结构体无须任何成员,主要展示实现 Invoker 的方法。
第 6 行,Call() 为结构体的方法,该方法的功能是打印 from struct 和传入的 interface{} 类型的值。
将定义的 Struct 类型实例化,并传入接口中进行调用,代码如下:
// 声明接口变量
var invoker Invoker
// 实例化结构体
s := new(Struct)
// 将实例化的结构体赋值到接口
invoker = s
// 使用接口调用实例化结构体的方法Struct.Call
invoker.Call(“hello”)
代码说明如下:
第 2 行,声明 Invoker 类型的变量。
第 5 行,使用 new 将结构体实例化,此行也可以写为 s:=&Struct。
第 8 行,s 类型为 *Struct,已经实现了 Invoker 接口类型,因此赋值给 invoker 时是成功的。
第 11 行,通过接口的 Call() 方法,传入 hello,此时将调用 Struct 结构体的 Call() 方法。
接下来,对比下函数实现结构体的差异。
代码输出如下:
from struct hello
函数体实现接口
函数的声明不能直接实现接口,需要将函数定义为类型后,使用类型实现结构体,当类型方法被调用时,还需要调用函数本体。
// 函数定义为类型
type FuncCaller func(interface{})
// 实现Invoker的Call
func (f FuncCaller) Call(p interface{}) {
// 调用f()函数本体
f(p)
}
代码说明如下:
第 2 行,将 func(interface{}) 定义为 FuncCaller 类型。
第 5 行,FuncCaller 的 Call() 方法将实现 Invoker 的 Call() 方法。
第 8 行,FuncCaller 的 Call() 方法被调用与 func(interface{}) 无关,还需要手动调用函数本体。
上面代码只是定义了函数类型,需要函数本身进行逻辑处理,FuncCaller 无须被实例化,只需要将函数转换为 FuncCaller 类型即可,函数来源可以是命名函数、匿名函数或闭包,参见下面代码:
// 声明接口变量
var invoker Invoker
// 将匿名函数转为FuncCaller类型, 再赋值给接口
invoker = FuncCaller(func(v interface{}) {
fmt.Println("from function", v)
})
// 使用接口调用FuncCaller.Call, 内部会调用函数本体
invoker.Call("hello")
代码说明如下:
第 2 行,声明接口变量。
第 5 行,将 func(v interface{}){} 匿名函数转换为 FuncCaller 类型(函数签名才能转换),此时 FuncCaller 类型实现了 Invoker 的 Call() 方法,赋值给 invoker 接口是成功的。
第 10 行,使用接口方法调用。
代码输出如下:
from function hello
HTTP包中的例子
HTTP 包中包含有 Handler 接口定义,代码如下:
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
Handler 用于定义每个 HTTP 的请求和响应的处理过程。
同时,也可以使用处理函数实现接口,定义如下:
type HandlerFunc func(ResponseWriter, *Request)
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}
要使用闭包实现默认的 HTTP 请求处理,可以使用 http.HandleFunc() 函数,函数定义如下:
func HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
DefaultServeMux.HandleFunc(pattern, handler)
}
而 DefaultServeMux 是 ServeMux 结构,拥有 HandleFunc() 方法,定义如下:
func (mux *ServeMux) HandleFunc(pattern string, handler func
(ResponseWriter, *Request)) {
mux.Handle(pattern, HandlerFunc(handler))
}
上面代码将外部传入的函数 handler() 转为 HandlerFunc 类型,HandlerFunc 类型实现了 Handler 的 ServeHTTP 方法,底层可以同时使用各种类型来实现 Handler 接口进行处理。
五、Go语言闭包(Closure)引用了外部变量的匿名函数
函数 + 引用环境 = 闭包
同一个函数与不同引用环境组合,可以形成不同的实例,如下图所示。
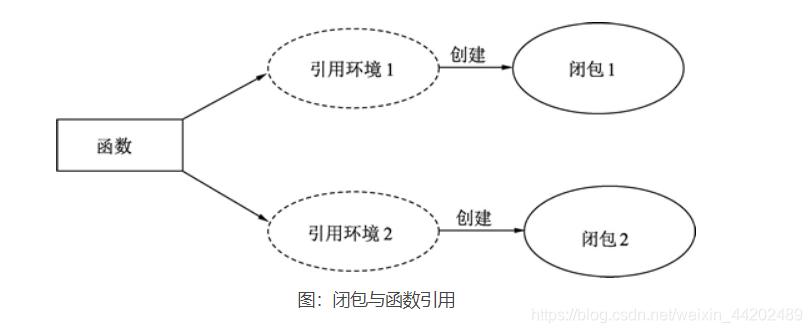
一个函数类型就像结构体一样,可以被实例化,函数本身不存储任何信息,只有与引用环境结合后形成的闭包才具有“记忆性”,函数是编译期静态的概念,而闭包是运行期动态的概念。
其它编程语言中的闭包
闭包(Closure)在某些编程语言中也被称为 Lambda 表达式。
闭包对环境中变量的引用过程也可以被称为“捕获”,在 C++11 标准中,捕获有两种类型,分别是引用和复制,可以改变引用的原值叫做“引用捕获”,捕获的过程值被复制到闭包中使用叫做“复制捕获”。
在 Lua 语言中,将被捕获的变量起了一个名字叫做 Upvalue,因为捕获过程总是对闭包上方定义过的自由变量进行引用。
闭包在各种语言中的实现也是不尽相同的,在 Lua 语言中,无论闭包还是函数都属于 Prototype 概念,被捕获的变量以 Upvalue 的形式引用到闭包中。
C++ 与 C# 中为闭包创建了一个类,而被捕获的变量在编译时放到类中的成员中,闭包在访问被捕获的变量时,实际上访问的是闭包隐藏类的成员。
在闭包内部修改引用的变量
闭包对它作用域上部的变量可以进行修改,修改引用的变量会对变量进行实际修改,通过下面的例子来理解:
// 准备一个字符串
str := "hello world"
// 创建一个匿名函数
foo := func() {
// 匿名函数中访问str
str = "hello dude"
}
// 调用匿名函数
foo()
代码说明如下:
第 2 行,准备一个字符串用于修改。
第 5 行,创建一个匿名函数。
第 8 行,在匿名函数中并没有定义 str,str 的定义在匿名函数之前,此时,str 就被引用到了匿名函数中形成了闭包。
第 12 行,执行闭包,此时 str 发生修改,变为 hello dude。
代码输出:
hello dude
示例:闭包的记忆效应
被捕获到闭包中的变量让闭包本身拥有了记忆效应,闭包中的逻辑可以修改闭包捕获的变量,变量会跟随闭包生命期一直存在,闭包本身就如同变量一样拥有了记忆效应。
累加器的实现:
package main
import (
"fmt"
)
// 提供一个值, 每次调用函数会指定对值进行累加
func Accumulate(value int) func() int {
// 返回一个闭包
return func() int {
// 累加
value++
// 返回一个累加值
return value
}
}
func main() {
// 创建一个累加器, 初始值为1
accumulator := Accumulate(1)
// 累加1并打印
fmt.Println(accumulator())
fmt.Println(accumulator())
// 打印累加器的函数地址
fmt.Printf("%p\n", &accumulator)
// 创建一个累加器, 初始值为1
accumulator2 := Accumulate(10)
// 累加1并打印
fmt.Println(accumulator2())
// 打印累加器的函数地址
fmt.Printf("%p\n", &accumulator2)
}
代码说明如下:
第 8 行,累加器生成函数,这个函数输出一个初始值,调用时返回一个为初始值创建的闭包函数。
第 11 行,返回一个闭包函数,每次返回会创建一个新的函数实例。
第 14 行,对引用的 Accumulate 参数变量进行累加,注意 value 不是第 11 行匿名函数定义的,但是被这个匿名函数引用,所以形成闭包。
第 17 行,将修改后的值通过闭包的返回值返回。
第 24 行,创建一个累加器,初始值为 1,返回的 accumulator 是类型为 func()int 的函数变量。
第 27 行,调用 accumulator() 时,代码从 11 行开始执行匿名函数逻辑,直到第 17 行返回。
第 32 行,打印累加器的函数地址。
对比输出的日志发现 accumulator 与 accumulator2 输出的函数地址不同,因此它们是两个不同的闭包实例。
每调用一次 accumulator 都会自动对引用的变量进行累加。
示例:闭包实现生成器
闭包的记忆效应被用于实现类似于设计模式中工厂模式的生成器,下面的例子展示了创建一个玩家生成器的过程。
玩家生成器的实现:
package main
import (
"fmt"
)
// 创建一个玩家生成器, 输入名称, 输出生成器
func playerGen(name string) func() (string, int) {
// 血量一直为150
hp := 150
// 返回创建的闭包
return func() (string, int) {
// 将变量引用到闭包中
return name, hp
}
}
func main() {
// 创建一个玩家生成器
generator := playerGen("high noon")
// 返回玩家的名字和血量
name, hp := generator()
// 打印值
fmt.Println(name, hp)
}
代码输出如下:
high noon 150
代码说明如下:
第 8 行,playerGen() 需要提供一个名字来创建一个玩家的生成函数。
第 11 行,声明并设定 hp 变量为 150。
第 14~18 行,将 hp 和 name 变量引用到匿名函数中形成闭包。
第 24 行中,通过 playerGen 传入参数调用后获得玩家生成器。
第 27 行,调用这个玩家生成器函数,可以获得玩家的名称和血量。
闭包还具有一定的封装性,第 11 行的变量是 playerGen 的局部变量,playerGen 的外部无法直接访问及修改这个变量,这种特性也与面向对象中强调的封装性类似。
六、Go语言可变参数(变参函数)
可变参数类型
可变参数是指函数传入的参数个数是可变的,为了做到这点,首先需要将函数定义为可以接受可变参数的类型:
func myfunc(args ...int) {
for _, arg := range args {
fmt.Println(arg)
}
}
上面这段代码的意思是,函数 myfunc() 接受不定数量的参数,这些参数的类型全部是 int,所以它可以用如下方式调用:
myfunc(2, 3, 4)
myfunc(1, 3, 7, 13)
形如…type格式的类型只能作为函数的参数类型存在,并且必须是最后一个参数,它是一个语法糖(syntactic sugar),即这种语法对语言的功能并没有影响,但是更方便程序员使用,通常来说,使用语法糖能够增加程序的可读性,从而减少程序出错的可能。
从内部实现机理上来说,类型…type本质上是一个数组切片,也就是[]type,这也是为什么上面的参数 args 可以用 for 循环来获得每个传入的参数。
假如没有…type这样的语法糖,开发者将不得不这么写:
func myfunc2(args []int) {
for _, arg := range args {
fmt.Println(arg)
}
}
从函数的实现角度来看,这没有任何影响,该怎么写就怎么写,但从调用方来说,情形则完全不同:
myfunc2([]int{1, 3, 7, 13})
大家会发现,我们不得不加上[]int{}来构造一个数组切片实例,但是有了…type这个语法糖,我们就不用自己来处理了。
任意类型的可变参数
之前的例子中将可变参数类型约束为 int,如果你希望传任意类型,可以指定类型为 interface{},下面是Go语言标准库中 fmt.Printf() 的函数原型:
func Printf(format string, args ...interface{}) {
// ...
}
用 interface{} 传递任意类型数据是Go语言的惯例用法,使用 interface{} 仍然是类型安全的,这和 C/C++ 不太一样,下面通过示例来了解一下如何分配传入 interface{} 类型的数据。
package main
import "fmt"
func MyPrintf(args ...interface{}) {
for _, arg := range args {
switch arg.(type) {
case int:
fmt.Println(arg, "is an int value.")
case string:
fmt.Println(arg, "is a string value.")
case int64:
fmt.Println(arg, "is an int64 value.")
default:
fmt.Println(arg, "is an unknown type.")
}
}
}
func main() {
var v1 int = 1
var v2 int64 = 234
var v3 string = "hello"
var v4 float32 = 1.234
MyPrintf(v1, v2, v3, v4)
}
该程序的输出结果为:
1 is an int value.
234 is an int64 value.
hello is a string value.
1.234 is an unknown type.
遍历可变参数列表——获取每一个参数的值
可变参数列表的数量不固定,传入的参数是一个切片,如果需要获得每一个参数的具体值时,可以对可变参数变量进行遍历,参见下面代码:
package main
import (
"bytes"
"fmt"
)
// 定义一个函数, 参数数量为0~n, 类型约束为字符串
func joinStrings(slist ...string) string {
// 定义一个字节缓冲, 快速地连接字符串
var b bytes.Buffer
// 遍历可变参数列表slist, 类型为[]string
for _, s := range slist {
// 将遍历出的字符串连续写入字节数组
b.WriteString(s)
}
// 将连接好的字节数组转换为字符串并输出
return b.String()
}
func main() {
// 输入3个字符串, 将它们连成一个字符串
fmt.Println(joinStrings("pig ", "and", " rat"))
fmt.Println(joinStrings("hammer", " mom", " and", " hawk"))
}
代码输出如下:
pig and rat
hammer mom and hawk
代码说明如下:
第 8 行,定义了一个可变参数的函数,slist 的类型为 []string,每一个参数的类型都是 string,也就是说,该函数只接受字符串类型作为参数。
第 11 行,bytes.Buffer 在这个例子中的作用类似于 StringBuilder,可以高效地进行字符串连接操作。
第 13 行,遍历 slist 可变参数,s 为每个参数的值,类型为 string。
第 15 行,将每一个传入参数放到 bytes.Buffer 中。
第 19 行,将 bytes.Buffer 中的数据转换为字符串作为函数返回值返回。
第 24 行,输入 3 个字符串,使用 joinStrings() 函数将参数连接为字符串输出。
第 25 行,输入 4 个字符串,连接后输出。
如果要获取可变参数的数量,可以使用 len() 函数对可变参数变量对应的切片进行求长度操作,以获得可变参数数量。
获得可变参数类型——获得每一个参数的类型
当可变参数为 interface{} 类型时,可以传入任何类型的值,此时,如果需要获得变量的类型,可以通过 switch 获得变量的类型,下面的代码演示将一系列不同类型的值传入 printTypeValue() 函数,该函数将分别为不同的参数打印它们的值和类型的详细描述。
打印类型及值:
package main
import (
"bytes"
"fmt"
)
func printTypeValue(slist ...interface{}) string {
// 字节缓冲作为快速字符串连接
var b bytes.Buffer
// 遍历参数
for _, s := range slist {
// 将interface{}类型格式化为字符串
str := fmt.Sprintf("%v", s)
// 类型的字符串描述
var typeString string
// 对s进行类型断言
switch s.(type) {
case bool: // 当s为布尔类型时
typeString = "bool"
case string: // 当s为字符串类型时
typeString = "string"
case int: // 当s为整型类型时
typeString = "int"
}
// 写字符串前缀
b.WriteString("value: ")
// 写入值
b.WriteString(str)
// 写类型前缀
b.WriteString(" type: ")
// 写类型字符串
b.WriteString(typeString)
// 写入换行符
b.WriteString("\n")
}
return b.String()
}
func main() {
// 将不同类型的变量通过printTypeValue()打印出来
fmt.Println(printTypeValue(100, "str", true))
}
代码输出如下:
value: 100 type: int
value: str type: string
value: true type: bool
代码说明如下:
第 8 行,printTypeValue() 输入不同类型的值并输出类型和值描述。
第 11 行,bytes.Buffer 字节缓冲作为快速字符串连接。
第 14 行,遍历 slist 的每一个元素,类型为 interface{}。
第 17 行,使用 fmt.Sprintf 配合%v动词,可以将 interface{} 格式的任意值转为字符串。
第 20 行,声明一个字符串,作为变量的类型名。
第 23 行,switch s.(type) 可以对 interface{} 类型进行类型断言,也就是判断变量的实际类型。
第 24~29 行为 s 变量可能的类型,将每种类型的对应类型字符串赋值到 typeString 中。
第 33~42 行为写输出格式的过程。
在多个可变参数函数中传递参数
可变参数变量是一个包含所有参数的切片,如果要将这个含有可变参数的变量传递给下一个可变参数函数,可以在传递时给可变参数变量后面添加…,这样就可以将切片中的元素进行传递,而不是传递可变参数变量本身。
下面的例子模拟 print() 函数及实际调用的 rawPrint() 函数,两个函数都拥有可变参数,需要将参数从 print 传递到 rawPrint 中。
可变参数传递:
package main
import "fmt"
// 实际打印的函数
func rawPrint(rawList ...interface{}) {
// 遍历可变参数切片
for _, a := range rawList {
// 打印参数
fmt.Println(a)
}
}
// 打印函数封装
func print(slist ...interface{}) {
// 将slist可变参数切片完整传递给下一个函数
rawPrint(slist...)
}
func main() {
print(1, 2, 3)
}
代码输出如下:
1
2
3
对代码的说明:
第 9~13 行,遍历 rawPrint() 的参数列表 rawList 并打印。
第 20 行,将变量在 print 的可变参数列表中添加…后传递给 rawPrint()。
第 25 行,传入 1、2、3 这 3 个整型值并进行打印。
如果尝试将第 20 行修改为:
rawPrint("fmt", slist)
再次执行代码,将输出:
[1 2 3]
此时,slist(类型为 []interface{})将被作为一个整体传入 rawPrint(),rawPrint() 函数中遍历的变量也就是 slist 的切片值。
可变参数使用…进行传递与切片间使用 append 连接是同一个特性。
七、Go语言defer(延迟执行语句)
关键字 defer 的用法类似于面向对象编程语言 Java 和 C# 的 finally 语句块,它一般用于释放某些已分配的资源,典型的例子就是对一个互斥解锁,或者关闭一个文件。
多个延迟执行语句的处理顺序
当有多个 defer 行为被注册时,它们会以逆序执行(类似栈,即后进先出),下面的代码是将一系列的数值打印语句按顺序延迟处理,如下所示:
package main
import (
"fmt"
)
func main() {
fmt.Println("defer begin")
// 将defer放入延迟调用栈
defer fmt.Println(1)
defer fmt.Println(2)
// 最后一个放入, 位于栈顶, 最先调用
defer fmt.Println(3)
fmt.Println("defer end")
}
代码输出如下:
defer begin
defer end
3
2
1
结果分析如下:
代码的延迟顺序与最终的执行顺序是反向的。
延迟调用是在 defer 所在函数结束时进行,函数结束可以是正常返回时,也可以是发生宕机时。
使用延迟执行语句在函数退出时释放资源
处理业务或逻辑中涉及成对的操作是一件比较烦琐的事情,比如打开和关闭文件、接收请求和回复请求、加锁和解锁等。在这些操作中,最容易忽略的就是在每个函数退出处正确地释放和关闭资源。
defer 语句正好是在函数退出时执行的语句,所以使用 defer 能非常方便地处理资源释放问题。
1) 使用延迟并发解锁
在下面的例子中会在函数中并发使用 map,为防止竞态问题,使用 sync.Mutex 进行加锁,参见下面代码:
var (
// 一个演示用的映射
valueByKey = make(map[string]int)
// 保证使用映射时的并发安全的互斥锁
valueByKeyGuard sync.Mutex
)
// 根据键读取值
func readValue(key string) int {
// 对共享资源加锁
valueByKeyGuard.Lock()
// 取值
v := valueByKey[key]
// 对共享资源解锁
valueByKeyGuard.Unlock()
// 返回值
return v
}
代码说明如下:
第 3 行,实例化一个 map,键是 string 类型,值为 int。
第 5 行,map 默认不是并发安全的,准备一个 sync.Mutex 互斥量保护 map 的访问。
第 9 行,readValue() 函数给定一个键,从 map 中获得值后返回,该函数会在并发环境中使用,需要保证并发安全。
第 11 行,使用互斥量加锁。
第 13 行,从 map 中获取值。
第 15 行,使用互斥量解锁。
第 17 行,返回获取到的 map 值。
使用 defer 语句对上面的语句进行简化,参考下面的代码。
func readValue(key string) int {
valueByKeyGuard.Lock()
// defer后面的语句不会马上调用, 而是延迟到函数结束时调用
defer valueByKeyGuard.Unlock()
return valueByKey[key]
}
上面的代码中第 6~8 行是对前面代码的修改和添加的代码,代码说明如下:
第 6 行在互斥量加锁后,使用 defer 语句添加解锁,该语句不会马上执行,而是等 readValue() 函数返回时才会被执行。
第 8 行,从 map 查询值并返回的过程中,与不使用互斥量的写法一样,对比上面的代码,这种写法更简单。
2) 使用延迟释放文件句柄
文件的操作需要经过打开文件、获取和操作文件资源、关闭资源几个过程,如果在操作完毕后不关闭文件资源,进程将一直无法释放文件资源,在下面的例子中将实现根据文件名获取文件大小的函数,函数中需要打开文件、获取文件大小和关闭文件等操作,由于每一步系统操作都需要进行错误处理,而每一步处理都会造成一次可能的退出,因此就需要在退出时释放资源,而我们需要密切关注在函数退出处正确地释放文件资源,参考下面的代码:
// 根据文件名查询其大小
func fileSize(filename string) int64 {
// 根据文件名打开文件, 返回文件句柄和错误
f, err := os.Open(filename)
// 如果打开时发生错误, 返回文件大小为0
if err != nil {
return 0
}
// 取文件状态信息
info, err := f.Stat()
// 如果获取信息时发生错误, 关闭文件并返回文件大小为0
if err != nil {
f.Close()
return 0
}
// 取文件大小
size := info.Size()
// 关闭文件
f.Close()
// 返回文件大小
return size
}
代码说明如下:
第 2 行,定义获取文件大小的函数,返回值是 64 位的文件大小值。
第 5 行,使用 os 包提供的函数 Open(),根据给定的文件名打开一个文件,并返回操作文件用的句柄和操作错误。
第 8 行,如果打开的过程中发生错误,如文件没找到、文件被占用等,将返回文件大小为 0。
第 13 行,此时文件句柄 f 可以正常使用,使用 f 的方法 Stat() 来获取文件的信息,获取信息时,可能也会发生错误。
第 16~19 行对错误进行处理,此时文件是正常打开的,为了释放资源,必须要调用 f 的 Close() 方法来关闭文件,否则会发生资源泄露。
第 22 行,获取文件大小。
第 25 行,关闭文件、释放资源。
第 28 行,返回获取到的文件大小。
在上面的例子中,第 25 行是对文件的关闭操作,下面使用 defer 对代码进行简化,代码如下:
func fileSize(filename string) int64 {
f, err := os.Open(filename)
if err != nil {
return 0
}
// 延迟调用Close, 此时Close不会被调用
defer f.Close()
info, err := f.Stat()
if err != nil {
// defer机制触发, 调用Close关闭文件
return 0
}
size := info.Size()
// defer机制触发, 调用Close关闭文件
return size
}
代码中加粗部分为对比前面代码而修改的部分,代码说明如下:
第 10 行,在文件正常打开后,使用 defer,将 f.Close() 延迟调用,注意,不能将这一句代码放在第 4 行空行处,一旦文件打开错误,f 将为空,在延迟语句触发时,将触发宕机错误。
第 16 行和第 22 行,defer 后的语句(f.Close())将会在函数返回前被调用,自动释放资源。
八、Go语言递归函数
构成递归需要具备以下条件:
- 一个问题可以被拆分成多个子问题;
- 拆分前的原问题与拆分后的子问题除了数据规模不同,但处理问题的思路是一样的;
- 不能无限制的调用本身,子问题需要有退出递归状态的条件。
注意:编写递归函数时,一定要有终止条件,否则就会无限调用下去,直到内存溢出。
下面通过几个示例来演示一下递归函数的使用。
斐波那契数列
下面我们就以递归函数的经典示例 —— 斐波那契数列为例,演示如何通过Go语言编写的递归函数来打印斐波那契数列。
数列的形式如下所示:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597,
2584, 4181, 6765, 10946, …
使用Go语言递归函数实现斐波那契数列的具体代码如下所示:
package main
import "fmt"
func main() {
result := 0
for i := 1; i <= 10; i++ {
result = fibonacci(i)
fmt.Printf("fibonacci(%d) is: %d\n", i, result)
}
}
func fibonacci(n int) (res int) {
if n <= 2 {
res = 1
} else {
res = fibonacci(n-1) + fibonacci(n-2)
}
return
}
输出结果为:
fibonacci(1) is: 1
fibonacci(2) is: 1
fibonacci(3) is: 2
fibonacci(4) is: 3
fibonacci(5) is: 5
fibonacci(6) is: 8
fibonacci(7) is: 13
fibonacci(8) is: 21
fibonacci(9) is: 34
fibonacci(10) is: 55
数字阶乘
一个正整数的阶乘(factorial)是所有小于及等于该数的正整数的积,并且 0 的阶乘为 1,自然数 n 的阶乘写作n!,“基斯顿·卡曼”在 1808 年发明了n!这个运算符号。
例如,n!=1×2×3×…×n,阶乘亦可以递归方式定义:0!=1,n!=(n-1)!×n。
使用递归函数计算给定数的阶乘,示例代码如下所示:
package main
import "fmt"
func Factorial(n uint64) (result uint64) {
if n > 0 {
result = n * Factorial(n-1)
return result
}
return 1
}
func main() {
var i int = 10
fmt.Printf("%d 的阶乘是 %d\n", i, Factorial(uint64(i)))
}
输出结果为:
10 的阶乘是 3628800
多个函数组成递归
Go语言中也可以使用相互调用的递归函数,多个函数之间相互调用形成闭环,因为Go语言编译器的特殊性,这些函数的声明顺序可以是任意的,下面这个简单的例子展示了函数 odd 和 even 之间的相互调用:
package main
import (
"fmt"
)
func main() {
fmt.Printf("%d is even: is %t\n", 16, even(16)) // 16 is even: is true
fmt.Printf("%d is odd: is %t\n", 17, odd(17))
// 17 is odd: is true
fmt.Printf("%d is odd: is %t\n", 18, odd(18))
// 18 is odd: is false
}
func even(nr int) bool {
if nr == 0 {
return true
}
return odd(RevSign(nr) - 1)
}
func odd(nr int) bool {
if nr == 0 {
return false
}
return even(RevSign(nr) - 1)
}
func RevSign(nr int) int {
if nr < 0 {
return -nr
}
return nr
}
运行效果如下所示:
16 is even: is true
17 is odd: is true
18 is odd: is false
九、Go语言处理运行时错误
Go语言的错误处理思想及设计包含以下特征:
一个可能造成错误的函数,需要返回值中返回一个错误接口(error),如果调用是成功的,错误接口将返回 nil,否则返回错误。
在函数调用后需要检查错误,如果发生错误,则进行必要的错误处理。
Go语言没有类似 Java 或 .NET 中的异常处理机制,虽然可以使用 defer、panic、recover 模拟,但官方并不主张这样做,Go语言的设计者认为其他语言的异常机制已被过度使用,上层逻辑需要为函数发生的异常付出太多的资源,同时,如果函数使用者觉得错误处理很麻烦而忽略错误,那么程序将在不可预知的时刻崩溃。
Go语言希望开发者将错误处理视为正常开发必须实现的环节,正确地处理每一个可能发生错误的函数,同时,Go语言使用返回值返回错误的机制,也能大幅降低编译器、运行时处理错误的复杂度,让开发者真正地掌握错误的处理。
net 包中的例子
net.Dial() 是Go语言系统包 net 即中的一个函数,一般用于创建一个 Socket 连接。
net.Dial 拥有两个返回值,即 Conn 和 error,这个函数是阻塞的,因此在 Socket 操作后,会返回 Conn 连接对象和 error,如果发生错误,error 会告知错误的类型,Conn 会返回空。
根据Go语言的错误处理机制,Conn 是其重要的返回值,因此,为这个函数增加一个错误返回,类似为 error,参见下面的代码:
func Dial(network, address string) (Conn, error) {
var d Dialer
return d.Dial(network, address)
}
在 io 包中的 Writer 接口也拥有错误返回,代码如下:
type Writer interface {
Write(p []byte) (n int, err error)
}
io 包中还有 Closer 接口,只有一个错误返回,代码如下:
type Closer interface {
Close() error
}
错误接口的定义格式
error 是 Go 系统声明的接口类型,代码如下:
type error interface {
Error() string
}
所有符合 Error()string 格式的方法,都能实现错误接口,Error() 方法返回错误的具体描述,使用者可以通过这个字符串知道发生了什么错误。
自定义一个错误
返回错误前,需要定义会产生哪些可能的错误,在Go语言中,使用 errors 包进行错误的定义,格式如下:
var err = errors.New("this is an error")
错误字符串由于相对固定,一般在包作用域声明,应尽量减少在使用时直接使用 errors.New 返回。
1) errors 包
Go语言的 errors 中对 New 的定义非常简单,代码如下:
// 创建错误对象
func New(text string) error {
return &errorString{text}
}
// 错误字符串
type errorString struct {
s string
}
// 返回发生何种错误
func (e *errorString) Error() string {
return e.s
}
代码说明如下:
第 2 行,将 errorString 结构体实例化,并赋值错误描述的成员。
第 7 行,声明 errorString 结构体,拥有一个成员,描述错误内容。
第 12 行,实现 error 接口的 Error() 方法,该方法返回成员中的错误描述。
2) 在代码中使用错误定义
下面的代码会定义一个除法函数,当除数为 0 时,返回一个预定义的除数为 0 的错误。
package main
import (
"errors"
"fmt"
)
// 定义除数为0的错误
var errDivisionByZero = errors.New("division by zero")
func div(dividend, divisor int) (int, error) {
// 判断除数为0的情况并返回
if divisor == 0 {
return 0, errDivisionByZero
}
// 正常计算,返回空错误
return dividend / divisor, nil
}
func main() {
fmt.Println(div(1, 0))
}
代码输出如下:
0 division by zero
代码说明:
第 9 行,预定义除数为 0 的错误。
第 11 行,声明除法函数,输入被除数和除数,返回商和错误。
第 14 行,在除法计算中,如果除数为 0,计算结果为无穷大,为了避免这种情况,对除数进行判断,并返回商为 0 和除数为 0 的错误对象。
第 19 行,进行正常的除法计算,没有发生错误时,错误对象返回 nil。
示例:在解析中使用自定义错误
使用 errors.New 定义的错误字符串的错误类型是无法提供丰富的错误信息的,那么,如果需要携带错误信息返回,就需要借助自定义结构体实现错误接口。
下面代码将实现一个解析错误(ParseError),这种错误包含两个内容,分别是文件名和行号,解析错误的结构还实现了 error 接口的 Error() 方法,返回错误描述时,就需要将文件名和行号返回。
package main
import (
"fmt"
)
// 声明一个解析错误
type ParseError struct {
Filename string // 文件名
Line int // 行号
}
// 实现error接口,返回错误描述
func (e *ParseError) Error() string {
return fmt.Sprintf("%s:%d", e.Filename, e.Line)
}
// 创建一些解析错误
func newParseError(filename string, line int) error {
return &ParseError{filename, line}
}
func main() {
var e error
// 创建一个错误实例,包含文件名和行号
e = newParseError("main.go", 1)
// 通过error接口查看错误描述
fmt.Println(e.Error())
// 根据错误接口具体的类型,获取详细错误信息
switch detail := e.(type) {
case *ParseError: // 这是一个解析错误
fmt.Printf("Filename: %s Line: %d\n", detail.Filename, detail.Line)
default: // 其他类型的错误
fmt.Println("other error")
}
}
代码输出如下:
main.go:1
Filename: main.go Line: 1
代码说明如下:
第 8 行,声明了一个解析错误的结构体,解析错误包含有 2 个成员,分别是文件名和行号。
第 14 行,实现了错误接口,将成员的文件名和行号格式化为字符串返回。
第 19 行,根据给定的文件名和行号创建一个错误实例。
第 25 行,声明一个错误接口类型。
第 27 行,创建一个实例,这个错误接口内部是 *ParserError 类型,携带有文件名 main.go 和行号 1。
第 30 行,调用 Error() 方法,通过第 15 行返回错误的详细信息。
第 33 行,通过错误断言,取出发生错误的详细类型。
第 34 行,通过分析这个错误的类型,得知错误类型为 *ParserError,此时可以获取到详细的错误信息。
第 36 行,如果不是我们能够处理的错误类型,会打印出其他错误做出其他的处理。
错误对象都要实现 error 接口的 Error() 方法,这样,所有的错误都可以获得字符串的描述,如果想进一步知道错误的详细信息,可以通过类型断言,将错误对象转为具体的错误类型进行错误详细信息的获取。
十、Go语言宕机(panic)——程序终止运行
宕机不是一件很好的事情,可能造成体验停止、服务中断,就像没有人希望在取钱时遇到 ATM 机蓝屏一样,但是,如果在损失发生时,程序没有因为宕机而停止,那么用户将会付出更大的代价,这种代价可以是金钱、时间甚至生命,因此,宕机有时也是一种合理的止损方法。
一般而言,当宕机发生时,程序会中断运行,并立即执行在该 goroutine(可以先理解成线程)中被延迟的函数(defer 机制),随后,程序崩溃并输出日志信息,日志信息包括 panic value 和函数调用的堆栈跟踪信息,panic value 通常是某种错误信息。
对于每个 goroutine,日志信息中都会有与之相对的,发生 panic 时的函数调用堆栈跟踪信息,通常,我们不需要再次运行程序去定位问题,日志信息已经提供了足够的诊断依据,因此,在我们填写问题报告时,一般会将宕机和日志信息一并记录。
虽然Go语言的 panic 机制类似于其他语言的异常,但 panic 的适用场景有一些不同,由于 panic 会引起程序的崩溃,因此 panic 一般用于严重错误,如程序内部的逻辑不一致。任何崩溃都表明了我们的代码中可能存在漏洞,所以对于大部分漏洞,我们应该使用Go语言提供的错误机制,而不是 panic。
手动触发宕机
Go语言可以在程序中手动触发宕机,让程序崩溃,这样开发者可以及时地发现错误,同时减少可能的损失。
Go语言程序在宕机时,会将堆栈和 goroutine 信息输出到控制台,所以宕机也可以方便地知晓发生错误的位置,那么我们要如何触发宕机呢,示例代码如下所示:
package main
func main() {
panic("crash")
}
代码运行崩溃并输出如下:
panic: crash
goroutine 1 [running]:
main.main()
D:/code/main.go:4 +0x40
exit status 2
以上代码中只用了一个内建的函数 panic() 就可以造成崩溃,panic() 的声明如下:
func panic(v interface{}) //panic() 的参数可以是任意类型的。
在运行依赖的必备资源缺失时主动触发宕机
regexp 是Go语言的正则表达式包,正则表达式需要编译后才能使用,而且编译必须是成功的,表示正则表达式可用。
编译正则表达式函数有两种,具体如下:
*1) func Compile(expr string) (Regexp, error)
编译正则表达式,发生错误时返回编译错误同时返回 Regexp 为 nil,该函数适用于在编译错误时获得编译错误进行处理,同时继续后续执行的环境。
*2) func MustCompile(str string) Regexp
当编译正则表达式发生错误时,使用 panic 触发宕机,该函数适用于直接使用正则表达式而无须处理正则表达式错误的情况。
MustCompile 的代码如下:
func MustCompile(str string) *Regexp {
regexp, error := Compile(str)
if error != nil {
panic(`regexp: Compile(` + quote(str) + `): ` + error.Error())
}
return regexp
}
代码说明如下:
第 1 行,编译正则表达式函数入口,输入包含正则表达式的字符串,返回正则表达式对象。
第 2 行,Compile() 是编译正则表达式的入口函数,该函数返回编译好的正则表达式对象和错误。
第 3 和第 4 行判断如果有错,则使用 panic() 触发宕机。
第 6 行,没有错误时返回正则表达式对象。
手动宕机进行报错的方式不是一种偷懒的方式,反而能迅速报错,终止程序继续运行,防止更大的错误产生,不过,如果任何错误都使用宕机处理,也不是一种良好的设计习惯,因此应根据需要来决定是否使用宕机进行报错。
在宕机时触发延迟执行语句
当 panic() 触发的宕机发生时,panic() 后面的代码将不会被运行,但是在 panic() 函数前面已经运行过的 defer 语句依然会在宕机发生时发生作用,参考下面代码:
package main
import "fmt"
func main() {
defer fmt.Println("宕机后要做的事情1")
defer fmt.Println("宕机后要做的事情2")
panic("宕机")
}
代码输出如下:
宕机后要做的事情2
宕机后要做的事情1
panic: 宕机
goroutine 1 [running]:
main.main()
D:/code/main.go:8 +0xf8
exit status 2
对代码的说明:
第 6 行和第 7 行使用 defer 语句延迟了 2 个语句。
第 8 行发生宕机。
宕机前,defer 语句会被优先执行,由于第 7 行的 defer 后执行,因此会在宕机前,这个 defer 会优先处理,随后才是第 6 行的 defer 对应的语句,这个特性可以用来在宕机发生前进行宕机信息处理。
十一、Go语言宕机恢复(recover)——防止程序崩溃
Recover 是一个Go语言的内建函数,可以让进入宕机流程中的 goroutine 恢复过来,recover 仅在延迟函数 defer 中有效,在正常的执行过程中,调用 recover 会返回 nil 并且没有其他任何效果,如果当前的 goroutine 陷入恐慌,调用 recover 可以捕获到 panic 的输入值,并且恢复正常的执行。
通常来说,不应该对进入 panic 宕机的程序做任何处理,但有时,需要我们可以从宕机中恢复,至少我们可以在程序崩溃前,做一些操作,举个例子,当 web 服务器遇到不可预料的严重问题时,在崩溃前应该将所有的连接关闭,如果不做任何处理,会使得客户端一直处于等待状态,如果 web 服务器还在开发阶段,服务器甚至可以将异常信息反馈到客户端,帮助调试。
提示
在其他语言里,宕机往往以异常的形式存在,底层抛出异常,上层逻辑通过 try/catch 机制捕获异常,没有被捕获的严重异常会导致宕机,捕获的异常可以被忽略,让代码继续运行。
Go语言没有异常系统,其使用 panic 触发宕机类似于其他语言的抛出异常,recover 的宕机恢复机制就对应其他语言中的 try/catch 机制。
让程序在崩溃时继续执行
下面的代码实现了 ProtectRun() 函数,该函数传入一个匿名函数或闭包后的执行函数,当传入函数以任何形式发生 panic 崩溃后,可以将崩溃发生的错误打印出来,同时允许后面的代码继续运行,不会造成整个进程的崩溃。
保护运行函数:
package main
import (
"fmt"
"runtime"
)
// 崩溃时需要传递的上下文信息
type panicContext struct {
function string // 所在函数
}
// 保护方式允许一个函数
func ProtectRun(entry func()) {
// 延迟处理的函数
defer func() {
// 发生宕机时,获取panic传递的上下文并打印
err := recover()
switch err.(type) {
case runtime.Error: // 运行时错误
fmt.Println("runtime error:", err)
default: // 非运行时错误
fmt.Println("error:", err)
}
}()
entry()
}
func main() {
fmt.Println("运行前")
// 允许一段手动触发的错误
ProtectRun(func() {
fmt.Println("手动宕机前")
// 使用panic传递上下文
panic(&panicContext{
"手动触发panic",
})
fmt.Println("手动宕机后")
})
// 故意造成空指针访问错误
ProtectRun(func() {
fmt.Println("赋值宕机前")
var a *int
*a = 1
fmt.Println("赋值宕机后")
})
fmt.Println("运行后")
}
代码输出结果:
运行前
手动宕机前
error: &{手动触发panic}
赋值宕机前
runtime error: runtime error: invalid memory address or nil pointer dereference
运行后
对代码的说明:
第 9 行声明描述错误的结构体,保存执行错误的函数。
第 17 行使用 defer 将闭包延迟执行,当 panic 触发崩溃时,ProtectRun() 函数将结束运行,此时 defer 后的闭包将会发生调用。
第 20 行,recover() 获取到 panic 传入的参数。
第 22 行,使用 switch 对 err 变量进行类型断言。
第 23 行,如果错误是有 Runtime 层抛出的运行时错误,如空指针访问、除数为 0 等情况,打印运行时错误。
第 25 行,其他错误,打印传递过来的错误数据。
第 44 行,使用 panic 手动触发一个错误,并将一个结构体附带信息传递过去,此时,recover 就会获取到这个结构体信息,并打印出来。
第 57 行,模拟代码中空指针赋值造成的错误,此时会由 Runtime 层抛出错误,被 ProtectRun() 函数的 recover() 函数捕获到。
panic 和 recover 的关系
panic 和 recover 的组合有如下特性:
有 panic 没 recover,程序宕机。
有 panic 也有 recover,程序不会宕机,执行完对应的 defer 后,从宕机点退出当前函数后继续执行。
提示
虽然 panic/recover 能模拟其他语言的异常机制,但并不建议在编写普通函数时也经常性使用这种特性。
在 panic 触发的 defer 函数内,可以继续调用 panic,进一步将错误外抛,直到程序整体崩溃。
如果想在捕获错误时设置当前函数的返回值,可以对返回值使用命名返回值方式直接进行设置。
十二、Go语言计算函数执行时间
在Go语言中我们可以使用 time 包中的 Since() 函数来获取函数的运行时间,Go语言官方文档中对 Since() 函数的介绍是这样的。
func Since(t Time) Duration
Since() 函数返回从 t 到现在经过的时间,等价于time.Now().Sub(t)。
【示例】使用 Since() 函数获取函数的运行时间。
package main
import (
"fmt"
"time"
)
func test() {
start := time.Now() // 获取当前时间
sum := 0
for i := 0; i < 100000000; i++ {
sum++
}
elapsed := time.Since(start)
fmt.Println("该函数执行完成耗时:", elapsed)
}
func main() {
test()
}
运行结果如下所示:
该函数执行完成耗时: 39.8933ms
上面我们提到了 time.Now().Sub() 的功能类似于 Since() 函数,想要使用 time.Now().Sub() 获取函数的运行时间只需要把我们上面代码的第 14 行简单修改一下就行。
【示例 2】使用 time.Now().Sub() 获取函数的运行时间。
package main
import (
"fmt"
"time"
)
func test() {
start := time.Now() // 获取当前时间
sum := 0
for i := 0; i < 100000000; i++ {
sum++
}
elapsed := time.Now().Sub(start)
fmt.Println("该函数执行完成耗时:", elapsed)
}
func main() {
test()
}
运行结果如下所示:
该函数执行完成耗时: 36.8769ms
由于计算机 CPU 及一些其他因素的影响,在获取函数运行时间时每次的结果都有些许不同,属于正常现象。
十三、Go语言Test功能测试函数详解
Go语言自带了 testing 测试包,可以进行自动化的单元测试,输出结果验证,并且可以测试性能。
为什么需要测试
完善的测试体系,能够提高开发的效率,当项目足够复杂的时候,想要保证尽可能的减少 bug,有两种有效的方式分别是代码审核和测试,Go语言中提供了 testing 包来实现单元测试功能。
测试规则
要开始一个单元测试,需要准备一个 go 源码文件,在命名文件时文件名必须以_test.go结尾,单元测试源码文件可以由多个测试用例(可以理解为函数)组成,每个测试用例的名称需要以 Test 为前缀,例如:
func TestXxx( t *testing.T ){
//......
}
编写测试用例有以下几点需要注意:
- 测试用例文件不会参与正常源码的编译,不会被包含到可执行文件中;
- 测试用例的文件名必须以_test.go结尾;
- 需要使用 import 导入 testing 包;
- 测试函数的名称要以Test或Benchmark开头,后面可以跟任意字母组成的字符串,但第一个字母必须大写,例如
TestAbc(),一个测试用例文件中可以包含多个测试函数; - 单元测试则以(t *testing.T)作为参数,性能测试以(t *testing.B)做为参数;
- 测试用例文件使用 go test 命令来执行,源码中不需要 main()
函数作为入口,所有以_test.go结尾的源码文件内以Test开头的函数都会自动执行。
Go语言的 testing 包提供了三种测试方式,分别是单元(功能)测试、性能(压力)测试和覆盖率测试。
单元(功能)测试
在同一文件夹下创建两个Go语言文件,分别命名为 demo.go 和 demt_test.go,如下图所示:
具体代码如下所示:
demo.go:
package demo
// 根据长宽获取面积
func GetArea(weight int, height int) int {
return weight * height
}
demo_test.go:
package demo
import "testing"
func TestGetArea(t *testing.T) {
area := GetArea(40, 50)
if area != 2000 {
t.Error("测试失败")
}
}
执行测试命令,运行结果如下所示:
PS D:\code> go test -v
=== RUN TestGetArea
--- PASS: TestGetArea (0.00s)
PASS
ok _/D_/code 0.435s
性能(压力)测试
将 demo_test.go 的代码改造成如下所示的样子:
package demo
import "testing"
func BenchmarkGetArea(t *testing.B) {
for i := 0; i < t.N; i++ {
GetArea(40, 50)
}
}
执行测试命令,运行结果如下所示:
PS D:\code> go test -bench="."
goos: windows
goarch: amd64
BenchmarkGetArea-4 2000000000 0.35 ns/op
PASS
ok _/D_/code 1.166s
上面信息显示了程序执行 2000000000 次,共耗时 0.35 纳秒。
覆盖率测试
覆盖率测试能知道测试程序总共覆盖了多少业务代码(也就是 demo_test.go 中测试了多少 demo.go 中的代码),可以的话最好是覆盖100%。
将 demo_test.go 代码改造成如下所示的样子:
package demo
import "testing"
func TestGetArea(t *testing.T) {
area := GetArea(40, 50)
if area != 2000 {
t.Error("测试失败")
}
}
func BenchmarkGetArea(t *testing.B) {
for i := 0; i < t.N; i++ {
GetArea(40, 50)
}
}
执行测试命令,运行结果如下所示:
PS D:\code> go test -cover
PASS
coverage: 100.0% of statements
ok _/D_/code 0.437s














 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









