







进程
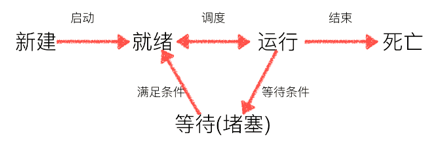
三种状态
- 就绪态:运行的条件都已经慢去,正在等在cpu执行
- 执行态:cpu正在执行其功能
- 等待态:等待某些 条件满足,例如一个程序sleep了,此时就处于等待态
生命周期:
-
用户编写代码(代码本身是以进程运行的)
-
启动程序,进入进程“就绪”状态
-
操作系统调度资源,做“程序切换”,使得进程进入“运行”状态
-
结束/中断
特性
-
每个程序,本身首先是一个进程
-
运行中每个进程都拥有自己的地址空间、内存、数据栈及其它资源。
-
操作系统本身自动管理着所有的进程(不需要用户代码干涉),并为这些进程合理分配可以执行时间。
-
进程可以通过派生新的进程来执行其它任务,不过每个进程还是都拥有自己的内存和数据栈等。
-
进程间可以通讯(发消息和数据),采用 进程间通信(IPC) 方式。
说明
-
多个进程可以在不同的 CPU 上运行,互不干扰
-
同一个CPU上,可以运行多个进程,由操作系统来自动分配时间片
-
由于进程间资源不能共享,需要进程间通信,来发送数据,接受消息等
-
多进程,也称为“并行”。
- 多进程
- 函数方法:创建proess对象,指定target要执行的函数任务
- 类方法:继承process,重写run方法,由这个类实例化之后执行start会自动调用run方法
- 业务复杂是使用
- 进程间通信
-
进程队列queue
- multiprocess.Queue
-
管道pipe
-
说明
-
管道就是管道,就像生活中的管道,两头都能进能出
-
默认管道是全双工的,如果创建管道的时候映射成False,左边只能用于接收,右边只能用于发送,类似于单行道
-
import multiprocessing
def foo(sk):
sk.send('hello world')
print(sk.recv())
if __name__ == '__main__':
conn1,conn2=multiprocessing.Pipe() #开辟两个口,都是能进能出,括号中如果False即单向通信
p=multiprocessing.Process(target=foo,args=(conn1,)) #子进程使用sock口,调用foo函数
p.start()
print(conn2.recv()) #主进程使用conn口接收
conn2.send('hi son') #主进程使用conn口发送
常用方法
conn1.recv():接收conn2.send(obj)发送的对象。如果没有消息可接收,recv方法会一直阻塞。如果连接的另外一端已经关闭,那么recv方法会抛出EOFError。
conn1.send(obj):通过连接发送对象。obj是与序列化兼容的任意对象
注意:send()和recv()方法使用pickle模块对对象进行序列化
- 共享数据manage
Queue和pipe只是实现了数据交互,并没实现数据共享,即一个进程去更改另一个进程的数据。
注:进程间通信应该尽量避免使用共享数据的方式 - 进程池
- 开多进程是为了并发,通常有几个cpu核心就开几个进程,但是进程开多了会影响效率,主要体现在切换的开销,所以引入进程池限制进程的数量。
- 进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
僵尸进程与孤儿进程
- 僵尸进程是父进程早于子进程先退出,这种对操作系统有害
- 如何避免:先执行一次fork在创建的子进程中再次fork,然后将第一次fork的进程退出,第二个子进程成为孤儿进程,从而其的父进程变为init进程,通过init进程管理,防止僵尸进程。
- 通过信号机制异步回收,最理想处理方式
- 孤儿进程是父进程存在而不处理子进程,这种最终会交给pid处理
线程
线程,是在进程中执行的代码。
一个进程下可以运行多个线程,这些线程之间共享主进程内申请的操作系统资源。
在一个进程中启动多个线程的时候,每个线程按照顺序执行。现在的操作系统中,也支持线程抢占,也就是说其它等待运行的线程,可以通过优先级,信号等方式,将运行的线程挂起,自己先运行。
使用
用户编写包含线程的程序(每个程序本身都是一个进程)
操作系统“程序切换”进入当前进程
当前进程包含了线程,则启动线程
多个线程,则按照顺序执行,除非抢占
特性
线程,必须在一个存在的进程中启动运行
线程使用进程获得的系统资源,不会像进程那样需要申请CPU等资源
线程无法给予公平执行时间,它可以被其他线程抢占,而进程按照操作系统的设定分配执行时间
每个进程中,都可以启动很多个线程
说明
多线程,也被称为”并发“执行。
线程池
系统启动一个新线程的成本是比较高的,因为它涉及与操作系统的交互。在这种情形下,使用线程池可以很好地提升性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池。
线程池在系统启动时即创建大量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数。
此外,使用线程池可以有效地控制系统中并发线程的数量。当系统中包含有大量的并发线程时,会导致系统性能急剧下降,甚至导致 Python 解释器崩溃,而线程池的最大线程数参数可以控制系统中并发线程的数量不超过此数。
多线程通信
-
共享变量
创建全局变量,多个线程公用一个全局变量,方便简单。但是坏处就是共享变量容易出现数据竞争,不是线程安全的,解决方法就是使用互斥锁。 -
变量共享引申出线程同步问题
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。 使用Thread对象的Lock和Rlock可以实现简单的线程同步,这两个对象都有acquire方法和release方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到acquire和release方法之间。 -
队列
线程间使用队列进行通信,因为队列所有方法都是线程安全的,所以不会出现线程竞争资源的情况
Queue.Queue 是进程内非阻塞队列
进程和线程的区别
一个进程中的各个线程与主进程共享相同的资源,与进程间互相独立相比,线程之间信息共享和通信更加容易(都在进程中,并且共享内存等)。
线程一般以并发执行,正是由于这种并发和数据共享机制,使多任务间的协作成为可能。
进程一般以并行执行,这种并行能使得程序能同时在多个CPU上运行;
区别于多个线程只能在进程申请到的的“时间片”内运行(一个CPU内的进程,启动了多个线程,线程调度共享这个进程的可执行时间片),进程可以真正实现程序的“同时”运行(多个CPU同时运行)。
进程和线程的常用应用场景
一般来说,在Python中编写并发程序的经验:
计算密集型任务使用多进程
IO密集型(如:网络通讯)任务使用多线程,较少使用多进程.
这是由于 IO操作需要独占资源
协程
协程: 协程,又称微线程,纤程,英文名Coroutine。协程的作用,是在执行函数A时,可以随时中断,去执行函数B,然后中断继续执行函数A(可以自由切换)。但这一过程并不是函数调用(没有调用语句),这一整个过程看似像多线程,然而协程只有一个线程执行.
协程由于由程序主动控制切换,没有线程切换的开销,所以执行效率极高。对于IO密集型任务非常适用,如果是cpu密集型,推荐多进程+协程的方式。
协程,又称微线程。
说明
协程的主要特色是:
协程间是协同调度的,这使得并发量数万以上的时候,协程的性能是远远高于线程。
注意这里也是“并发”,不是“并行”。
实现方式:greenlet gevent python之yield
协程优点:
1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
2. 单线程内就可以实现并发的效果,最大限度地利用cpu
协程缺点:
1.协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
2.协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









