







概述
本文记录了笔者如何借助PyTorch对飞机和鸟进行简单的分类。撰写本文时,笔者还是PyTorch的初学者,如有错误请各位不吝赐教。
参考文献:Deep Learning with PyTorch
项目环境
为了方便学习和演示项目,笔者使用的是Jupyter Notebook来编写代码。
数据说明
项目使用的是计算机视觉的经典数据集CIFAR-10. CIFAR-10包含了属于10个类别的60,000个32x32的RGB图像,每个图像都已经被标注好类别。
| CLASS | LABEL |
|---|---|
| airplane | 0 |
| automobile | 1 |
| bird | 2 |
| cat | 3 |
| deer | 4 |
| dog | 5 |
| frog | 6 |
| horse | 7 |
| ship | 8 |
| truck | 9 |

为了简化,项目中只会使用其中飞机和鸟的图像。
数据准备
直接使用torchvision和datasets模块下载CIFAR-10数据.
# in[1]
from torchvision import datasets
data_path = '../data/ch7/'
cifar10 = datasets.CIFAR10(data_path, train=True, download=True)
cifar10_val = datasets.CIFAR10(data_path, train=False, download=True)
等待数据下载完毕后,检查cifar10的数据类型及继承关系:
# in[2]
type(cifar10).__mro__
# out[2]
(torchvision.datasets.cifar.CIFAR10,
torchvision.datasets.vision.VisionDataset,
torch.utils.data.dataset.Dataset,
object)
这说明cifar10是Datasets的子类,我们可以像使用Datasets一样使用它。查看数据的长度:
# in[3]
len(cifar10), len(cifar10_val)
# out[3]
(50000, 10000)
本项目使用50,000个数据作为训练集,10,000个数据作为验证集。
检查一下数据集中的某个图像:
# in[4]
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'frog', 'horse', 'ship', 'trcuk']
img, label = cifar10[99]
img, label, class_names[label]
# out[4]
(<PIL.Image.Image image mode=RGB size=32x32 at 0x1BA05444148>, 1, 'automobile')
数据集中的数据是PIL格式(pillow)的图像,把它绘制出来是一辆红色小汽车:
# in[5]
from matplotlib import pyplot as plt
plt.imshow(img)
plt.show()
# out[5]
Pytorch的model接受的是tensor类型的数据,并且最好进行数据的标准化(Normalize)。我们先将数据转化为tensor,然后计算它的mean和std,最后进行数据标准化。
# in[6]
import torchvision.transforms as transforms
import torch
tensor_cifar10 = datasets.CIFAR10(data_path, train=True, download=False, transform
=transforms.ToTensor())
imgs = torch.stack([img_t for img_t, _ in tensor_cifar10], dim=3)
# in[7]
imgs.shape
# out[7]
torch.Size([3, 32, 32, 50000])
# in[8]
imgs.view(3, -1).mean(dim=1), imgs.view(3, -1).std(dim=1)
# out[8]
(tensor([0.4915, 0.4823, 0.4468]), tensor([0.2470, 0.2435, 0.2616]))
# in[9]
transformd_cifar10 = datasets.CIFAR10(data_path, train=True, download=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4915, 0.4823, 0.4468), (0.2470, 0.2435, 0.2616))
]))
这样就得到了标准化的训练数据,同理,使用相同的方法准备验证数据。
# in[10]
tensor_cifar10_val = datasets.CIFAR10(data_path, train=False, download=False, transform
=transforms.ToTensor())
imgs = torch.stack([img_t for img_t, _ in tensor_cifar10_val], dim=3)
imgs.view(3, -1).mean(dim=1), imgs.view(3, -1).std(dim=1)
# out[10]
(tensor([0.4943, 0.4852, 0.4506]), tensor([0.2467, 0.2429, 0.2616]))
# in[11]
transformd_cifar10_val = datasets.CIFAR10(data_path, train=True, download=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4943, 0.4852, 0.4506), (0.2467, 0.2429, 0.2616))
]))
注意,这两个数据中包含的是所有类别的图像数据,而我们只想要airplane和bird两个类别的数据,因此,简单的做一个映射:
# in[12]
label_map = {0:0, 2:1}
class_names = {'airplane', 'bird'}
cifar2 = [(img, label_map[label]) for img, label in transformd_cifar10 if label in [0, 2]]
cifar2_val = [(img, label_map[label]) for img, label in transformd_cifar10_val if label in [0, 2]]
此时的cifar2和cifar_val其实是list类型的数据,每个元素是一个(img, label)元组,其访问的方式和结果与Datasets类型的数据很像,可以作为DataLoader构造函数的输入参数。DataLoader是一个可以打乱数据顺序并且可以把数据组织成minibatch形式的类。最后,我们将数据转化为DataLoader数据,设置batch_size=32,打乱数据顺序:
# in[13]
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=32, shuffle=True)
val_loader = torch.utils.data.DataLoader(cifar2_val, batch_size=32, shuffle=False)
至此,可供model直接使用的数据就已经准备好了。
在进行下一步之前,我们可以查看一下标准化后的图像绘制出来会是什么样的。
# in[14]
img_n, _ = transformd_cifar10[99]
plt.imshow(img_n.permute(1, 2, 0))
plt.show()
# out[14]
Model结构与Loss函数
我们打算建立一个全连接模型(fully connected model)来完成分类任务。
每个图像的大小为3x32x32,也就是说输入特征个数为3072. 分类的类别是2个,所以输出特征个数为2. 先简单的将模型确定为:
model = nn.Sequential(
nn.Linear(3072, 512),
nn.Tanh(),
nn.Linear(512, 2)
)
因为项目要完成的是分类任务,模型的2个输出值应该被认为是图像分别属于这2个类别的概率值,范围0~1,且这2个值相加恰好等于1. Softmax函数满足这些约束。
# in[15]
import torch.nn as nn
x = torch.tensor([[1.0, 2.0, 3.0], [1.0, 2.0, 3.0]])
softmax = nn.Softmax(dim=1)
softmax(x)
# out[15]
tensor([[0.0900, 0.2447, 0.6652],
[0.0900, 0.2447, 0.6652]])
因此,我们将模型修改为:
model = nn.Sequential(
nn.Linear(3072, 512),
nn.Tanh(),
nn.Linear(512, 2),
nn.Softmax(dim=1)
)
如此,模型的输出就是图像属于某个类别的概率值,选择较大的概率值作为分类的结果。例如,输出[0.2, 0.8]就认为图像属于第2个类别,鸟。
接下来确定Loss函数。
我们希望当模型的输出接近真实情况时,loss很低;当远离真实情况时,loss很高。有一个名为nagative log likelihood (NLL)的函数满足这个要求, N L L = − s u m ( l o g ( o u t i [ c i ] ) ) NLL = - sum(log(out_i[c_i])) NLL=−sum(log(outi[ci])), c i c_i ci为图像 i i i正确的类别。
PyTorch中有一个名为nn.NLLLoss的类作用与这个函数类似,但是它的输入并不是概率值 §,而是
l
o
g
(
p
)
log(p)
log(p)。可以使用nn.LogSoftmax代替nn.Softmax,配合nn.NLLLoss使用。模型和Loss函数修改为:
# in[16]
model = nn.Sequential(
nn.Linear(3072, 512),
nn.Tanh(),
nn.Linear(512, 2),
nn.LogSoftmax(dim=1)
)
loss = nn.NLLLoss()
测试数据集中的一张图像,输入到模型中并计算loss:
# in[17]
img, label = cifar2[0]
out = model(img.view(-1).unsqueeze(0))
loss(out, torch.tensor([label]))
# out[17]
tensor(0.8974, grad_fn=<NllLossBackward>)
训练模型
数据、模型、Loss函数都有了,接下来就可以训练模型了。
# in[18]
def validation(model, val_loader):
total = 0
correct = 0
for imgs, labels in val_loader:
batch_size = imgs.shape[0]
outputs = model(imgs.view(batch_size, -1))
_, predicted = torch.max(outputs, dim=1)
total += labels.shape[0]
correct += int((predicted == labels).sum())
return correct / total
def train_loop(n_epochs, model, optimizer, train_loader, val_loader, loss_fn):
for epoch in range(n_epochs):
for imgs, labels in train_loader:
batch_size = imgs.shape[0]
outputs = model(imgs.view(batch_size, -1))
loss = loss_fn(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
accuracy = validation(model, val_loader)
print('Epoch: {}, Loss: {:.6f}, Accuracy: {:.4f}'.format(epoch, loss, accuracy))
上述代码定义了两个函数,validation函数用来计算model的正确率,train_loop函数用来训练model。
# in[19]
import torch.optim as optim
model = nn.Sequential(
nn.Linear(3072, 512),
nn.Tanh(),
nn.Linear(512, 2),
nn.LogSoftmax(dim=1)
)
loss_fn = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=1e-2)
train_loop(
n_epochs=100,
model=model,
optimizer=optimizer,
train_loader=train_loader,
val_loader=val_loader,
loss_fn=loss_fn
)
# out[19]
Epoch: 0, Loss: 0.419110, Accuracy: 0.7995
Epoch: 1, Loss: 0.385583, Accuracy: 0.8081
Epoch: 2, Loss: 0.431234, Accuracy: 0.8135
Epoch: 3, Loss: 0.325677, Accuracy: 0.8333
······
Epoch: 96, Loss: 0.003327, Accuracy: 1.0000
Epoch: 97, Loss: 0.002144, Accuracy: 1.0000
Epoch: 98, Loss: 0.007136, Accuracy: 1.0000
Epoch: 99, Loss: 0.005762, Accuracy: 0.9999
# in[20]
torch.save(model.state_dict(), 'weights/model.pt')
100个epoch后,模型的正确率竟然接近100%!
检查效果
为了直观地查看模型的分类效果,我们随机地抽取某张原图像绘制出来,将其输入model进行分类:
# in[21]
label_map = {0:0, 2:1}
class_names = ['airplane', 'bird']
origin_cifar2 = [(img, label_map[label]) for img, label in cifar10 if label in [0, 2]]
origin_cifar2_val = [(img, label_map[label]) for img, label in cifar10_val if label in [0, 2]]
# in[22]
import random
with torch.no_grad():
index = random.randint(0, len(cifar2))
img, label = cifar2[index]
origin_img, label = origin_cifar2[index]
output = model(img.view(1, -1))
_, predicted = torch.max(output, dim=1)
print("{:10}{:10} ".format("Label", "Predicted"))
print("{:10}{:10} ".format(class_names[label], class_names[predicted]))
plt.imshow(origin_img)
plt.show()
# out[22]
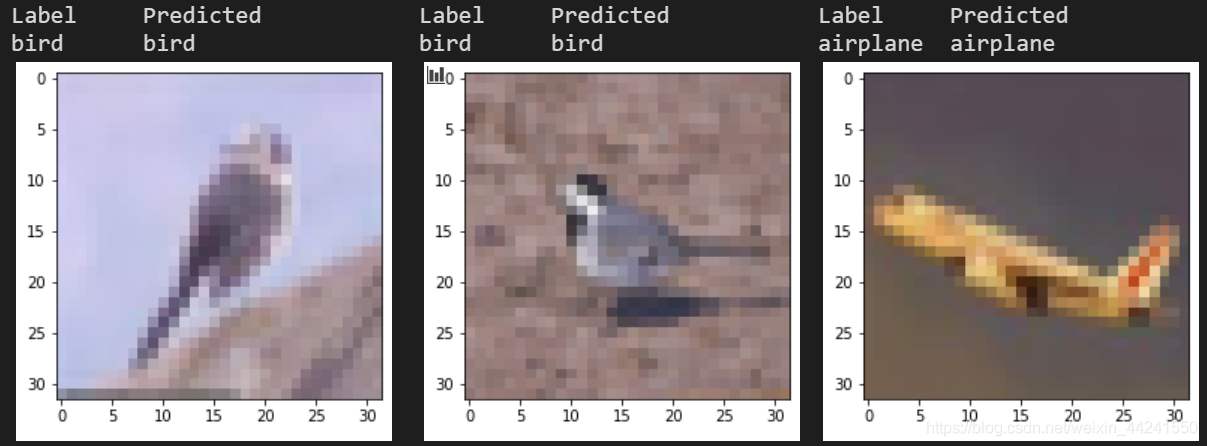
以上是3次执行in[22]的结果,多次执行后也会发现都是正确的。
总结与疑问
模型的效果似乎有些太好!好的有些不正常。在第0次epoch时,模型为什么就有近80%的正确率,此时模型完全没有训练过;在第99次epoch时,模型有了几乎是100%的正确率!
本项目完全是参照Deep Learning with PyTorch一书的chapter 7来做的,书中的正确率只有不到80%,而笔者的正确率近乎是100%,不知道是什么地方出现了问题?欢迎大家留言与我讨论。
欢迎访问我的博客: www.charloe.top
本文作者:Charloe
本文链接:[1] [2]














 1917
1917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









