首先,图嵌入
G
r
a
p
h
E
m
b
e
d
d
i
n
g
\rm Graph~Embedding
GraphEmbedding 的目的是将给定图
G
\mathcal G
G 中的每个节点映射为一个实值向量表示,该向量通常称之为节点嵌入
N
o
d
e
E
m
b
e
d
d
i
n
g
\rm Node~Embedding
NodeEmbedding,它保留了原图中节点的关键信息。
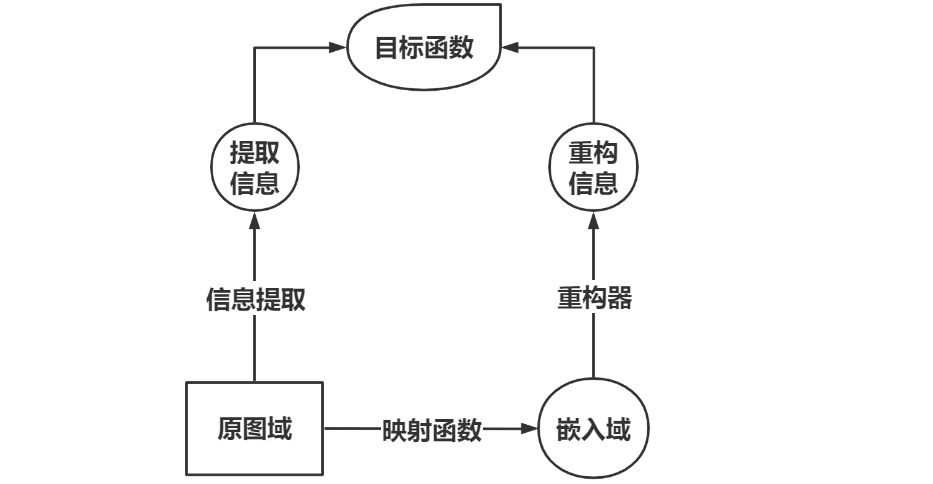
至此我们可以从两个角度来观察图
G
\mathcal G
G 中的节点,角度一是原图域 —— 其中的节点通过图结构(边)彼此连接;角度二是嵌入域 —— 其中每个嵌入向量表示一个节点。而图嵌入算法的目标则是将节点从原图域映射到嵌入域,使得原图域中的信息保留在嵌入域中。
重构器基于嵌入域重构出信息
I
′
\mathcal I'
I′,尝试逼近从原图域中提取出的信息
I
\mathcal I
I;
目标函数优化则是基于提取信息
I
\mathcal I
I 和重构信息
I
′
\mathcal I'
I′ 进行优化,学习映射函数以及重构器中的参数。
DeepWalk.
D
e
e
p
W
a
l
k
\rm DeepWalk
DeepWalk 是保留节点共现关系
N
o
d
e
C
o
−
O
c
c
u
r
e
n
c
e
\rm Node~Co-Occurence
NodeCo−Occurence 的经典图嵌入算法,于
2014
2014
2014 年提出。
映射函数.
常见的映射函数定义方式是使用查找表
L
o
o
k
−
u
p
T
a
b
l
e
\rm Look-up~Table
Look−upTable,在给定节点索引
i
i
i 的条件下,可以直接获取节点
v
i
v_i
vi 的嵌入向量
u
i
\bm u_i
ui,其实现形式如下:
f
(
v
i
)
=
u
i
=
W
T
e
i
(1)
f(v_i)=\bm u_i=\bm W^T\bm e_i\tag{1}
f(vi)=ui=WTei(1)
其中
e
i
∈
{
0
,
1
}
N
\bm e_i\in\{0,1\}^N
ei∈{0,1}N 是节点
v
i
v_i
vi 的独热编码,
N
=
∣
V
∣
N=|\mathcal V|
N=∣V∣ 是给定图的节点数量。
矩阵
W
∈
R
N
×
d
\bm W\in\mathbb R^{N\times d}
W∈RN×d 是要学习的嵌入参数,其中
d
d
d 是嵌入向量的维度。不难发现,矩阵
W
\bm W
W 的第
i
i
i 行是节点
v
i
v_i
vi 的嵌入向量。
共现信息提取器.
执行随机游走
R
a
n
d
o
m
W
a
l
k
\rm Random~Walk
RandomWalk 是保留图中节点共现信息的流行方法之一。如果某些节点倾向于在某些随机游走中共同出现,则认为这些节点是相似的。
【直观解释】对于给定图
G
\mathcal G
G 指定一个起始节点
v
(
0
)
v^{(0)}
v(0),从它的邻居中随机选中一个节点并前进到该节点,从选中节点处开始重复上述过程,直至访问了
T
T
T 个节点。这些节点按访问顺序排列,得到一个长度为
T
T
T 的节点序列。
【正式定义】给定连通图
G
=
{
V
,
E
}
\mathcal G=\{\mathcal V,\mathcal E\}
G={V,E},考虑从图上节点
v
(
0
)
v^{(0)}
v(0) 开始的随机游走,在第
t
t
t 步访问到的节点是
v
(
t
)
v^{(t)}
v(t),那么第
t
+
1
t+1
t+1 步访问的节点按如下概率从
v
(
t
)
v^{(t)}
v(t) 的邻居节点中选出:
p
(
v
(
t
+
1
)
∣
v
(
t
)
)
=
{
1
/
d
(
v
(
t
)
)
,
v
(
t
+
1
)
∈
N
(
v
(
t
)
)
0
,
e
l
s
e
(2)
p(v^{(t+1)}|v^{(t)})=\left\{ \begin{aligned} &1/d(v^{(t)})~,~v^{(t+1)}\in\mathcal N(v^{(t)})\\ &0~,~else\\ \end{aligned} \right.\tag{2}
p(v(t+1)∣v(t))={1/d(v(t)),v(t+1)∈N(v(t))0,else(2)其中
d
(
v
)
d(v)
d(v) 表示节点
v
v
v 的度,
N
(
v
)
\mathcal N(v)
N(v) 表示节点
v
v
v 的邻居节点集合,换言之,
D
e
e
p
W
a
l
k
\rm DeepWalk
DeepWalk 中随机游走过程的下一个被访问节点是按照均匀分布从当前节点的邻居中随机选择的。
上述随机游走过程可以抽象为一个随机游走序列生成器
R
W
RW
RW,得到的随机游走节点序列表示如下:
W
=
R
W
(
G
,
v
(
0
)
,
T
)
(3)
\mathcal W=RW(\mathcal G,v^{(0)},T)\tag{3}
W=RW(G,v(0),T)(3)其中
W
=
v
(
0
)
,
v
(
1
)
,
⋯
,
v
(
T
−
1
)
\mathcal W=v^{(0)},v^{(1)},\cdots,v^{(T-1)}
W=v(0),v(1),⋯,v(T−1) 表示生成的随机游走序列,
v
(
0
)
v^{(0)}
v(0) 为起始节点,
T
T
T 表示随机游走长度。
我们希望得到的随机游走序列能够捕获到整个图
G
\mathcal G
G 上的节点信息,因此每个节点都会用作随机游走的起始点,并生成
γ
\gamma
γ 个随机游走序列,因此最终共得到
γ
⋅
∣
V
∣
\gamma\cdot|\mathcal V|
γ⋅∣V∣ 个随机游走序列。此过程的伪代码如下所示:
Input:G={V,E},T,gamma
Output:R
Initialize:R=Nonefor i inrange(gamma):for v in V:
W = RW(G,v,T)
R = R U {W}
类比自然语言处理中的情境,可以将这些随机游走序列视作某个自然语言的句子,而节点集
V
\mathcal V
V 是这个自然语言的词汇表。在
N
L
P
\rm NLP
NLP 中,
S
k
i
p
−
G
r
a
m
\rm Skip-Gram
Skip−Gram 算法通过捕获句子中词语的共现关系来保留句子的信息。具体做法是给定中心词
c
e
n
t
e
r
\rm center
center 和距离
w
w
w,那么在中心词
w
w
w 范围以内的此被视为上下文
c
e
n
t
e
x
t
\rm centext
centext,很自然地可以认为中心词与其上下文中的词具有共现关系。这一处理思想同样可以应用到
D
e
e
p
W
a
l
k
\rm DeepWalk
DeepWalk 从随机游走序列中提取节点共现关系的过程。
D
e
e
p
W
a
l
k
\rm DeepWalk
DeepWalk 算法提取节点共现关系的策略和
S
k
i
p
−
G
r
a
m
\rm Skip-Gram
Skip−Gram 算法中提取词语共现关系类似,对于选中的中心节点
v
v
v,将随机游走序列中在其前后一定范围内出现的节点
u
u
u 纳入共现关系中。形式化地说,对于任意随机游走序列
W
∈
R
\mathcal W\in\mathcal R
W∈R,给定距离参数
w
w
w,开始遍历其中的节点。对于每个节点
v
(
i
)
v^{(i)}
v(i),将与其距离在区间
[
1
,
w
]
[1,w]
[1,w] 中的点
v
(
j
)
v^{(j)}
v(j) 纳入共现关系中,记为有序点对
(
v
(
j
)
,
v
(
i
)
)
(v^{(j)},v^{(i)})
(v(j),v(i)),注意点对中第一元素是上下文节点,第二元素是中心节点。如果索引
j
j
j 超出了随机游走序列的范围,忽略即可。该过程的伪代码如下所示:
Input:R,w
Output:I
Initialize:I=[]for W in R:for v[i]in W:for k inrange(1,w):
I.append((v[i+k],v[i]))
I.append((v[i-k],v[i]))
重构器与目标函数.
上部分中我们介绍了如何从原图域中通过随机游走获得节点共现信息
I
\mathcal I
I,现在我们要基于嵌入域的嵌入向量表示重构出共现信息,记重构结果为
I
′
\mathcal I'
I′,并通过优化目标函数使得提取信息
I
\mathcal I
I 和重构信息
I
′
\mathcal I'
I′ 的差距尽可能小。
对于原图域中的任一节点
v
i
v_i
vi 来说,它在共现信息
I
\mathcal I
I 中均可以扮演两个角色 —— 中心节点和上下文节点,因而两个不同的映射被用来表示同一节点扮演不同角色时的表示:
f
c
e
n
(
v
i
)
=
u
i
=
W
c
e
n
T
e
i
(4.1)
f_{cen}(v_i)=\bm u_i=\bm W_{cen}^T\bm e_i\tag{4.1}
fcen(vi)=ui=WcenTei(4.1)
f
c
o
n
(
v
i
)
=
v
i
=
W
c
o
n
T
e
i
(4.2)
f_{con}(v_i)=\bm v_i=\bm W^T_{con}\bm e_i\tag{4.2}
fcon(vi)=vi=WconTei(4.2)
共现关系
I
\mathcal I
I 中的有序点对
(
v
(
j
)
,
v
(
i
)
)
(v^{(j)},v^{(i)})
(v(j),v(i)) 可以解释为在中心节点
v
(
i
)
v^{(i)}
v(i) 的上下文中观察到
v
(
j
)
.
v^{(j)}.
v(j). 嵌入域中节点
v
(
i
)
,
v
(
j
)
v^{(i)},v^{(j)}
v(i),v(j) 均以嵌入向量形式表示,通过
S
o
f
t
m
a
x
\rm Softmax
Softmax 函数处理可以得到以
v
(
i
)
v^{(i)}
v(i) 为中心词的上下文条件分布,即:
p
(
v
(
j
)
∣
v
(
i
)
)
=
exp
(
f
c
o
n
(
v
(
j
)
)
T
⋅
f
c
e
n
(
v
(
i
)
)
)
)
∑
v
∈
V
exp
(
f
c
o
n
(
v
)
T
⋅
f
c
e
n
(
v
(
i
)
)
)
)
(5)
p(v^{(j)}|v^{(i)})=\frac{\exp\Big(f_{con}(v^{(j)})^T\cdot f_{cen}(v^{(i)}))\Big)}{\sum_{v\in\mathcal V}\exp\Big(f_{con}(v)^T\cdot f_{cen}(v^{(i)}))\Big)}\tag{5}
p(v(j)∣v(i))=∑v∈Vexp(fcon(v)T⋅fcen(v(i))))exp(fcon(v(j))T⋅fcen(v(i))))(5)上式的条件概率可以视为基于嵌入域得到的重构信息,对于任意一个给定的有序点对
(
v
(
j
)
,
v
(
i
)
)
(v^{(j)},v^{(i)})
(v(j),v(i)),重构器可以输出形如上式的概率值:
R
e
c
(
(
v
(
j
)
,
v
(
i
)
)
)
=
p
(
v
(
j
)
∣
v
(
i
)
)
(6)
{\rm Rec}\Big((v^{(j)},v^{(i)})\Big)=p(v^{(j)}|v^{(i)})\tag{6}
Rec((v(j),v(i)))=p(v(j)∣v(i))(6)直观上来看,在提取信息
I
\mathcal I
I 中出现次数越多的元组应该被重构器
R
e
c
\rm Rec
Rec 分配更高的概率;相反,出现次数少甚至随机生成的、一次也未出现的元组则得到较低的概率。
D
e
e
p
W
a
l
k
\rm DeepWalk
DeepWalk 中假设这些元组的出现是独立的,那么重构信息
I
′
\mathcal I'
I′ 可以表示如下:
I
′
=
R
e
c
(
I
)
=
∏
(
v
(
j
)
,
v
(
i
)
)
∈
I
p
(
v
(
j
)
∣
v
(
i
)
)
(7)
\mathcal I'={\rm Rec}(\mathcal I)=\prod_{(v^{(j)},v^{(i)})\in\mathcal I}p(v^{(j)}|v^{(i)})\tag{7}
I′=Rec(I)=(v(j),v(i))∈I∏p(v(j)∣v(i))(7)考虑到
I
\mathcal I
I 中存在重复的元组,记
S
e
t
(
I
)
{\rm Set(\mathcal I)}
Set(I) 是去重后的元组集合,则有:
I
′
=
∏
(
v
(
j
)
,
v
(
i
)
)
∈
S
e
t
(
I
)
p
(
v
(
j
)
∣
v
(
i
)
)
#
(
v
(
j
)
,
v
(
i
)
)
(8)
\mathcal I'=\prod_{(v^{(j)},v^{(i)})\in{\rm Set}(\mathcal I)}p(v^{(j)}|v^{(i)})^{\#(v^{(j)},v^{(i)})}\tag{8}
I′=(v(j),v(i))∈Set(I)∏p(v(j)∣v(i))#(v(j),v(i))(8)其中
#
(
v
(
j
)
,
v
(
i
)
)
\#(v^{(j)},v^{(i)})
#(v(j),v(i)) 表示对元组
(
v
(
j
)
,
v
(
i
)
)
(v^{(j)},v^{(i)})
(v(j),v(i)) 在
I
\mathcal I
I 中进行计数。为了达到良好重构出提取信息
I
\mathcal I
I 的目的,我们力求最大化上式的概率乘积,即等价于最小化如下的目标函数:
max
∏
(
v
(
j
)
,
v
(
i
)
)
∈
S
e
t
(
I
)
p
(
v
(
j
)
∣
v
(
i
)
)
#
(
v
(
j
)
,
v
(
i
)
)
⇔
min
−
∑
(
v
(
j
)
,
v
(
i
)
)
∈
S
e
t
(
I
)
#
(
v
(
j
)
,
v
(
i
)
)
⋅
log
p
(
v
(
j
)
∣
v
(
i
)
)
(9)
\max \prod_{(v^{(j)},v^{(i)})\in{\rm Set}(\mathcal I)}p(v^{(j)}|v^{(i)})^{\#(v^{(j)},v^{(i)})}\Leftrightarrow\min -\sum_{(v^{(j)},v^{(i)})\in{\rm Set}(\mathcal I)}\#(v^{(j)},v^{(i)})\cdot\log p(v^{(j)}|v^{(i)})\tag{9}
max(v(j),v(i))∈Set(I)∏p(v(j)∣v(i))#(v(j),v(i))⇔min−(v(j),v(i))∈Set(I)∑#(v(j),v(i))⋅logp(v(j)∣v(i))(9)不难发现等价符号右边的最小化部分是左边最大化部分的负对数。
加速计算.
由于重构器
R
e
c
\rm Rec
Rec 中涉及
S
o
f
t
m
a
x
\rm Softmax
Softmax 函数值的计算,即下式所表示的条件概率:
p
(
v
(
j
)
∣
v
(
i
)
)
=
exp
(
f
c
o
n
(
v
(
j
)
)
T
⋅
f
c
e
n
(
v
(
i
)
)
)
∑
v
∈
V
exp
(
f
c
o
n
(
v
)
T
⋅
f
c
e
n
(
v
(
i
)
)
)
(5)
p(v^{(j)}|v^{(i)})=\frac{\exp\Big(f_{con}(v^{(j)})^T\cdot f_{cen}(v^{(i)})\Big)}{\sum_{v\in\mathcal V}\exp\Big(f_{con}(v)^T\cdot f_{cen}(v^{(i)})\Big)}\tag{5}
p(v(j)∣v(i))=∑v∈Vexp(fcon(v)T⋅fcen(v(i)))exp(fcon(v(j))T⋅fcen(v(i)))(5)当分母求和项很多时,计算代价较大,因此可以引入针对
S
o
f
t
m
a
x
\rm Softmax
Softmax 的各类加速方法。例如分层
S
o
f
t
m
a
x
\rm Softmax
Softmax、负采样
N
e
g
a
t
i
v
e
−
S
a
m
p
l
i
n
g
\rm Negative-Sampling
Negative−Sampling 等策略,这些策略在图深度学习以外的深度学习领域,例如自然语言处理等也有应用,可以参见《Word Presentation》.
分层Softmax.
在该问题情境中应用分层
S
o
f
t
m
a
x
\rm Softmax
Softmax 技术时,会将图
G
\mathcal G
G 的
∣
V
∣
|\mathcal V|
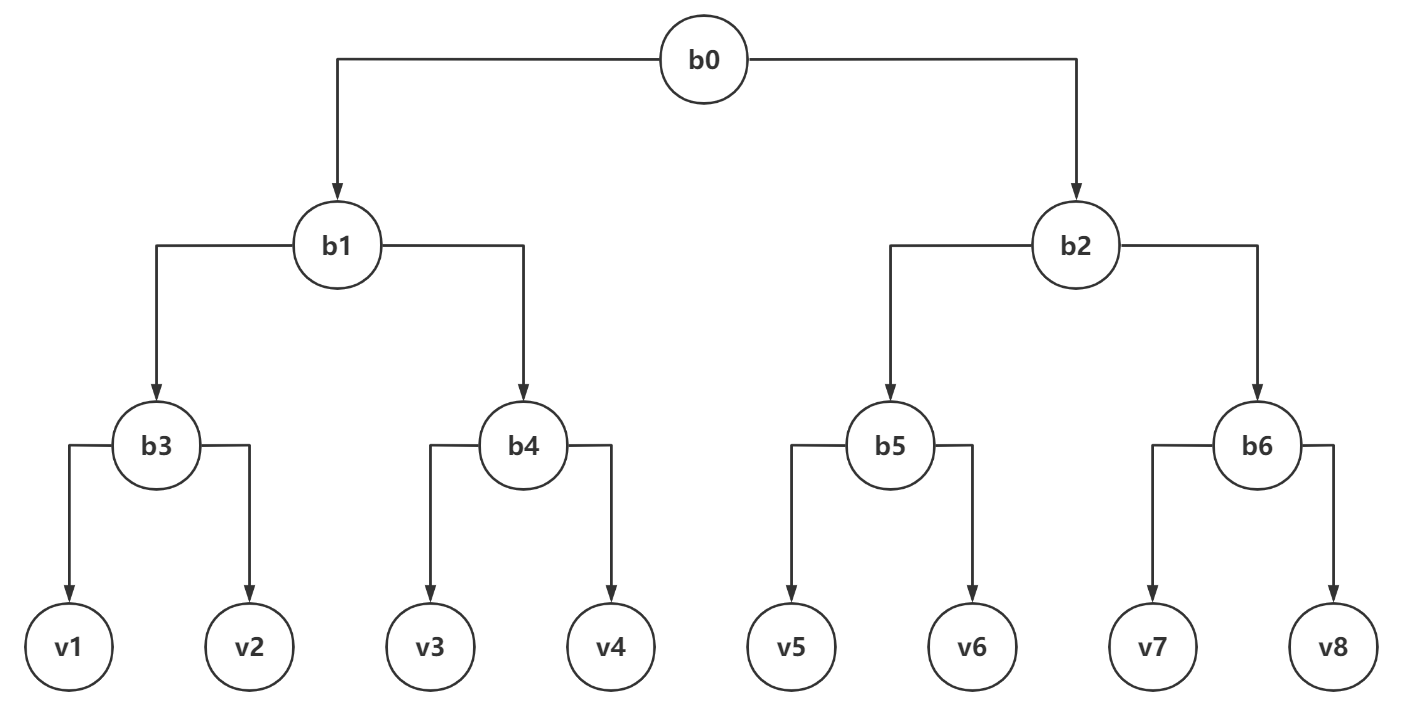
∣V∣ 个节点分配给一棵二叉树的叶子节点。出于叙述方便,我们以
∣
V
∣
=
8
|\mathcal V|=8
∣V∣=8 为例,构造出的二叉树如下所示,其中的叶子节点对应图
G
\mathcal G
G 的节点。
下述事实存在:任一叶子节点 ——
v
1
,
v
2
,
⋯
,
v
8
v_{1},v_{2},\cdots,v_{8}
v1,v2,⋯,v8 均可由上图中二叉树以根
b
0
b_{0}
b0 的唯一路径确定,例如
v
3
v_{3}
v3 对应的唯一路径是
(
b
0
,
b
1
,
b
4
,
v
3
)
.
(b_0,b_1,b_4,v_3).
(b0,b1,b4,v3).
由于
(
5
)
(5)
(5) 式计算代价较大,因此尝试对条件概率
p
(
v
(
j
)
∣
v
(
i
)
)
p(v^{(j)}|v^{(i)})
p(v(j)∣v(i)) 进行改写,分层
S
o
f
t
m
a
x
\rm Softmax
Softmax 中的做法基于以下等式:
p
(
Y
∣
X
)
=
∑
i
p
(
Y
,
C
=
i
∣
X
)
=
∑
i
p
(
Y
∣
C
=
i
,
X
)
⋅
p
(
C
=
i
∣
X
)
(10.1)
\begin{aligned}p(Y|X) &=\sum_ip(Y,C=i|X)\\ &=\sum_ip(Y|C=i,X)\cdot p(C=i|X) \end{aligned}\tag{10.1}
p(Y∣X)=i∑p(Y,C=i∣X)=i∑p(Y∣C=i,X)⋅p(C=i∣X)(10.1)定义函数
c
:
Y
→
C
c:Y\rightarrow C
c:Y→C,则
(
10.1
)
(10.1)
(10.1) 可以简化如下:
p
(
Y
∣
X
)
=
∑
i
p
(
Y
∣
C
=
i
,
X
)
⋅
p
(
C
=
i
∣
X
)
=
p
(
Y
∣
C
=
c
(
Y
)
,
X
)
⋅
p
(
C
=
c
(
Y
)
∣
X
)
(10.2)
\begin{aligned}p(Y|X) &=\sum_ip(Y|C=i,X)\cdot p(C=i|X)\\ &=p\Big(Y|C=c(Y),X\Big)\cdot p\Big(C=c(Y)|X\Big) \end{aligned}\tag{10.2}
p(Y∣X)=i∑p(Y∣C=i,X)⋅p(C=i∣X)=p(Y∣C=c(Y),X)⋅p(C=c(Y)∣X)(10.2)
(
10.2
)
(10.2)
(10.2) 式体现了分层
S
o
f
t
m
a
x
\rm Softmax
Softmax 的核心思想,抛弃直接由
X
X
X 直接计算条件概率
p
(
Y
∣
X
)
p(Y|X)
p(Y∣X) 的做法,而引入中间变量
C
C
C,
C
C
C 的每一个取值对应着
Y
Y
Y 的一类,所以将条件概率
p
(
Y
∣
X
)
p(Y|X)
p(Y∣X) 转化为
p
(
Y
∣
C
=
c
(
Y
)
,
X
)
⋅
p
(
C
=
c
(
Y
)
∣
X
)
p\Big(Y|C=c(Y),X\Big)\cdot p\Big(C=c(Y)|X\Big)
p(Y∣C=c(Y),X)⋅p(C=c(Y)∣X) 来计算。
这样做能够显著地降低计算量,原文
《
H
i
e
r
a
r
c
h
i
c
a
l
P
r
o
b
a
b
i
l
i
s
t
i
c
N
e
u
r
a
l
N
e
t
w
o
r
k
L
a
n
g
u
a
g
e
M
o
d
e
l
》
\rm《Hierarchical ~Probabilistic ~Neural~ Network~ Language~ Model》
《HierarchicalProbabilisticNeuralNetworkLanguageModel》中的解释如下: 同理上述
(
10.2
)
(10.2)
(10.2) 式可以推广到更多的中间变量
C
1
,
C
2
,
⋯
,
C
k
.
C_1,C_2,\cdots,C_k.
C1,C2,⋯,Ck.
具体到
D
e
e
p
W
a
l
k
\rm DeepWalk
DeepWalk 中重构器
R
e
c
\rm Rec
Rec 计算条件概率
p
(
v
(
j
)
∣
v
(
i
)
)
p(v^{(j)}|v^{(i)})
p(v(j)∣v(i)) 的问题,我们以下图为实例,计算概率
p
(
v
3
∣
v
8
)
.
p(v_3|v_8).
p(v3∣v8).
前面说过
v
3
v_3
v3 由路径
(
b
0
,
b
1
,
b
4
,
v
3
)
(b_0,b_1,b_4,v_3)
(b0,b1,b4,v3) 唯一确定,我们规定自根节点开始向左子树编码为
1
1
1,右子树编码为
0
0
0,易知
v
3
v_3
v3 节点由编码
101
101
101 确定,因此可以将上述编码的每一位视为一个中间变量
B
n
B_n
Bn,则有:
p
(
v
3
∣
v
8
)
=
p
(
B
1
=
1
,
B
2
=
0
,
B
3
=
1
∣
v
8
)
=
p
(
B
3
=
1
∣
B
2
=
0
,
B
1
=
1
,
v
8
)
⋅
p
(
B
2
=
0
,
B
1
=
1
∣
v
8
)
=
p
(
B
3
=
1
∣
B
2
=
0
,
B
1
=
1
,
v
8
)
⋅
p
(
B
2
=
0
∣
B
1
=
1
,
v
8
)
⋅
p
(
B
1
=
1
∣
v
8
)
=
p
(
B
3
=
1
∣
v
8
)
⋅
p
(
B
2
=
0
∣
v
8
)
⋅
p
(
B
1
=
1
∣
v
8
)
(11.1)
\begin{aligned}p(v_3|v_8) &=p(B_1=1,B_2=0,B_3=1|v_8)\\ &=p(B_3=1|B_2=0,B_1=1,v_8)\cdot p(B_2=0,B_1=1|v_8)\\ &=p(B_3=1|B_2=0,B_1=1,v_8)\cdot p(B_2=0|B_1=1,v_8)\cdot p(B_1=1|v_8)\\ &=p(B_3=1|v_8)\cdot p(B_2=0|v_8)\cdot p(B_1=1|v_8) \end{aligned}\tag{11.1}
p(v3∣v8)=p(B1=1,B2=0,B3=1∣v8)=p(B3=1∣B2=0,B1=1,v8)⋅p(B2=0,B1=1∣v8)=p(B3=1∣B2=0,B1=1,v8)⋅p(B2=0∣B1=1,v8)⋅p(B1=1∣v8)=p(B3=1∣v8)⋅p(B2=0∣v8)⋅p(B1=1∣v8)(11.1)将
(
11.1
)
(11.1)
(11.1) 式进行推广,设节点
v
(
j
)
v^{(j)}
v(j) 的编码为
B
1
B
2
⋯
B
m
B_1B_2\cdots B_m
B1B2⋯Bm,则有:
p
(
v
(
j
)
∣
v
(
i
)
)
=
∏
k
=
1
m
p
(
B
k
∣
B
1
,
B
2
,
⋯
,
B
i
−
1
,
v
(
i
)
)
=
∏
k
=
1
m
p
(
B
k
∣
v
(
i
)
)
(11.2)
\begin{aligned}p(v^{(j)}|v^{(i)}) &=\prod_{k=1}^mp(B_k|B_1,B_2,\cdots,B_{i-1},v^{(i)})\\ &=\prod_{k=1}^mp(B_k|v^{(i)}) \end{aligned}\tag{11.2}
p(v(j)∣v(i))=k=1∏mp(Bk∣B1,B2,⋯,Bi−1,v(i))=k=1∏mp(Bk∣v(i))(11.2)
(
11.2
)
(11.2)
(11.2) 式说明可以将
(
5
)
(5)
(5) 式代表的
∣
V
∣
|\mathcal V|
∣V∣ 分类器替换为
⌈
log
∣
V
∣
⌉
\lceil\log|\mathcal V|\rceil
⌈log∣V∣⌉ 个二分类器,相应的可以将计算复杂度从
O
(
∣
V
∣
)
\mathcal O\big(|\mathcal V|\big)
O(∣V∣) 降低到
O
(
log
∣
V
∣
)
.
\mathcal O\big(\log|\mathcal V|\big).
O(log∣V∣).
在重构器
R
e
c
\rm Rec
Rec 中应用分层
S
o
f
t
m
a
x
\rm Softmax
Softmax 时,我们将
(
11.2
)
(11.2)
(11.2) 式中的单个概率定义如下,以
p
(
B
1
∣
v
8
)
p(B_1|v_8)
p(B1∣v8) 为例:
p
(
B
1
=
1
∣
v
8
)
=
p
(
l
e
f
t
∣
b
0
,
v
8
)
=
S
i
g
m
o
i
d
(
f
b
(
b
0
)
T
⋅
f
v
(
v
8
)
)
(12)
p(B_1=1|v_8)=p({\rm left}|b_0,v_8)={\rm Sigmoid}\Big(f_b(b_0)^T\cdot f_v(v_8)\Big)\tag{12}
p(B1=1∣v8)=p(left∣b0,v8)=Sigmoid(fb(b0)T⋅fv(v8))(12)
注意
(
12
)
(12)
(12) 式与
(
5
)
(5)
(5) 式中存在的不同,即不再学习中心节点、上下文节点映射
f
c
e
n
,
f
c
o
n
f_{cen},f_{con}
fcen,fcon,取而代之的是内部节点映射与叶子节点映射
f
b
,
f
v
.
f_b,f_v.
fb,fv.
在
D
e
e
p
W
a
l
k
\rm DeepWalk
DeepWalk 中应用负采样的过程如下:对于提取信息
I
\mathcal I
I 中的每个元组
(
v
(
j
)
,
v
(
i
)
)
(v^{(j)},v^{(i)})
(v(j),v(i)),从那些没有出现在中心节点
v
(
i
)
v^{(i)}
v(i) 上下文的节点集合中采样
k
k
k 个节点
v
′
(
1
)
,
v
′
(
2
)
,
⋯
,
v
′
(
k
)
v'^{(1)},v'^{(2)},\cdots,v'^{(k)}
v′(1),v′(2),⋯,v′(k),构造负样本元组
(
v
′
(
n
)
,
v
(
i
)
)
,
n
=
1
,
2
,
⋯
,
k
(v'^{(n)},v^{(i)}),n=1,2,\cdots,k
(v′(n),v(i)),n=1,2,⋯,k,负样本元组的分布记为
P
n
(
v
)
.
P_n(v).
Pn(v).
利用
1
1
1 个正样本元组和
k
k
k 个负样本元组,定义如下的负采样目标函数:
log
[
S
i
g
m
o
i
d
(
f
c
o
n
(
v
(
j
)
)
T
⋅
f
c
e
n
(
v
(
i
)
)
)
]
+
∑
n
=
1
k
E
P
n
(
v
)
[
log
[
S
i
g
m
o
i
d
(
−
f
c
o
n
(
v
′
(
n
)
)
T
⋅
f
c
e
n
(
v
(
i
)
)
)
]
]
(13)
\log\big[{\rm Sigmoid}\Big(f_{con}(v^{(j)})^T\cdot f_{cen}(v^{(i)})\Big)\big]+\sum_{n=1}^kE_{_{P_n(v)}}\Big[\log\big[{\rm Sigmoid}\Big(-f_{con}(v'^{(n)})^T\cdot f_{cen}(v^{(i)})\Big)\big]\Big]\tag{13}
log[Sigmoid(fcon(v(j))T⋅fcen(v(i)))]+n=1∑kEPn(v)[log[Sigmoid(−fcon(v′(n))T⋅fcen(v(i)))]](13)
最大化
(
13
)
(13)
(13) 式能够使得来自
I
\mathcal I
I 的真实元组中节点共现概率最大化,而负元组中节点共现概率最小化,从而倾向于保持原图域中的节点共现关系。
用
(
13
)
(13)
(13) 式替换
(
9
)
(9)
(9) 式中的
log
p
(
v
(
j
)
∣
v
(
i
)
)
\log p(v^{(j)}|v^{(i)})
logp(v(j)∣v(i)) 得到如下的优化目标:
min
−
∑
(
v
(
j
)
,
v
(
i
)
)
∈
S
e
t
(
I
)
#
(
v
(
j
)
,
v
(
i
)
)
⋅
(
log
[
S
i
g
m
o
i
d
(
f
c
o
n
(
v
(
j
)
)
T
⋅
f
c
e
n
(
v
(
i
)
)
)
]
+
∑
n
=
1
k
E
P
n
(
v
)
[
log
[
S
i
g
m
o
i
d
(
−
f
c
o
n
(
v
′
(
n
)
)
T
⋅
f
c
e
n
(
v
(
i
)
)
)
]
]
)
(14)
\min -\sum_{(v^{(j)},v^{(i)})\in{\rm Set}(\mathcal I)}\#(v^{(j)},v^{(i)})\cdot\Big(\log\big[{\rm Sigmoid}\Big(f_{con}(v^{(j)})^T\cdot f_{cen}(v^{(i)})\Big)\big]\\+\sum_{n=1}^kE_{_{P_n(v)}}\Big[\log\big[{\rm Sigmoid}\Big(-f_{con}(v'^{(n)})^T\cdot f_{cen}(v^{(i)})\Big)\big]\Big]\Big)\tag{14}
min−(v(j),v(i))∈Set(I)∑#(v(j),v(i))⋅(log[Sigmoid(fcon(v(j))T⋅fcen(v(i)))]+n=1∑kEPn(v)[log[Sigmoid(−fcon(v′(n))T⋅fcen(v(i)))]])(14)








 同理上述
(
10.2
)
(10.2)
(10.2) 式可以推广到更多的中间变量
C
1
,
C
2
,
⋯
,
C
k
.
C_1,C_2,\cdots,C_k.
C1,C2,⋯,Ck.
同理上述
(
10.2
)
(10.2)
(10.2) 式可以推广到更多的中间变量
C
1
,
C
2
,
⋯
,
C
k
.
C_1,C_2,\cdots,C_k.
C1,C2,⋯,Ck.













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









