







前言
接到了一个实时计算的需求,大致是一个流式计算,需要将DRC提取到的变更数据进行过滤与数据处理后落库。之前也没有接触过大数据,因此对阿里的kepler进行了学习,在此总结。
流式计算
在日常生活中,我们通常会先把数据存储在一张表中,然后再进行加工、分析,这里就涉及到一个时效性的问题。如果我们处理以年、月为单位的级别的数据,那么多数据的实时性要求并不高;但如果我们处理的是以天、小时,甚至分钟为单位的数据,那么对数据的时效性要求就比较高。在第二种场景下,如果我们仍旧采用传统的数据处理方式,统一收集数据,存储到数据库中,之后在进行分析,就可能无法满足时效性的要求。
Kepler 蚂蚁实时计算平台
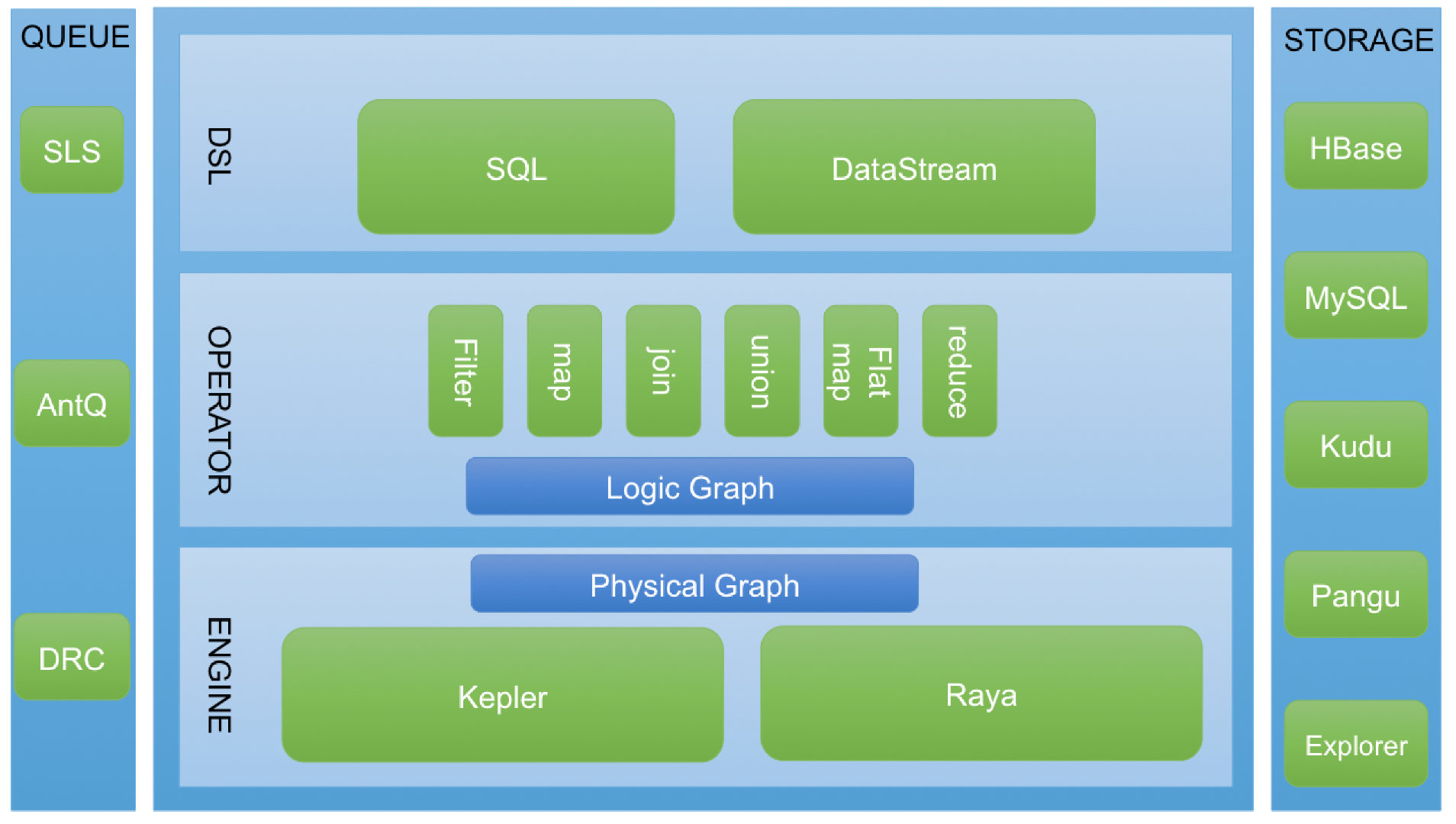
DSL和OPERATOR层
Kepler为用户提供了SQL和高阶算子两种编程范式:
-
Kepler SQL:兼容了大部分的 Streaming SQL 的语义,并支持 Window、Trigger等 Apache Beam的概念。SQL由于易上手易维护的特点,是目前Kepler用户使用方式的主流。
-
高阶算子:Kepler内置了完备的实时计算算子,包括:过滤(Filter)、转换(UDF、UDTF)、聚合(UDAF)、多流 Join、Union、Split 等类型,在 Spark 、Flink 高阶 API 里你能看到相同的概念,通过组装这些算子,用户可以轻松实现一个自定义逻辑的DataStream。通过高阶API,用户可以更细粒度地去描述计算本身,而因为高阶算子封装了 State、Retract 等能力,又为用户省去了繁琐的存储和出错回滚细节。
ENGINE层
Kepler底层执行引擎专注调度和执行数据流,而执行引擎对于算子层是可插拔的,目前Kepler支持了默认的执行引擎和蚂蚁的分布式计算框架 Raya。
IO模块
至于输入数据源和计算结果输出存储,Kepler 支持了蚂蚁所有的 Queue 系统和存储系统,包括但不限于SLS、AntQ、DRC、HBase、MySQL、Kudu、Pangu、Explorer 等等。并且这些存储类型都有对应的内置IO组件,用户不需要写任何 IO 相关的一行代码,就能轻松完成数据读取和存储。
具体实现
总体思路是根据内置的udtf进行改写
1、引入maven依赖
2、创建一个类继承UDF类,
3、写eval方法,规定传入的参数,框架会在运行时会根据参数的类型匹配对应的 eval 方法。
4、对数据进行处理后传入collect()方法。
5、对其中的getReturnType方法进行重写,输出的字段类型在 getReturnType 函数定义
代码示例
在这里,我实现的功能是将某个example字段多行输出,example是个jason数组的字符串,我需要提出字段中的每个jason的Name属性,并作为不同行的记录输出。
[
{"Name":"Apollo","School":{"Name":"Thu","City":"BeiJing"}},
{"Name":"Apollo2","School":{"Name":"Thu2","City":"BeiJing2"}}
]
示例如下
1,1,1,hello|java
******根据‘|’分割作为不同行输出*********
1,1,1,hello
1,1,1,java
实现代码
public class newsplit extends UDTF {
//arg0为传入String,arg1为需要提取的字段如instanceName
public void eval(String arg0, String arg1) {
evalInternal(arg0, arg1);
}
//具体实现方法
//传入目标字符串a,以及我要提取的属性名字b,及json的key
private void evalInternal(String a, String b) {
if (a != null) {
//将字符串a转为JSONArray,此时每个数组元素都是Object类型,无法直接得到jason的key
JSONArray jsArr = JSONObject.parseArray(a);
int len = jsArr.size();
String[] strs = new String[len];
//遍历数组每个Object对象
for(int i = 0; i < len; i++){
//将Object先变成String类型,然后利用parseObject变成JSONObject,因为JSONObject只能String作为参数
JSONObject obj = JSONObject.parseObject(jsArr.get(i).toString());
//JSONObject可以直接get(key)方法得到预提取字符,储存进字符串数组strs
strs[i] = obj.get(b).toString();
}
//具体输出,遍历str字符串并传入collect()
for (String str : strs) {
collect(new Object[]{str});
}
}
}
@Override
public List<Class<?>> getReturnType(List<Class<?>> paramTypes,
List<String> udtfReturnFields) {
List<Class<?>> clazzs = Lists.newArrayList();
clazzs.add(String.class);
return clazzs;
}
}














 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









