






博客记录小样本学习相关论文的笔记
1. IEPT(Instance-level and Episode-level pretext tasks for Few-shot Learning)
为了解决现实应用场景中存在的小样本场景,目前主要有两种解决思路:
- 小样本学习
- 自监督学习
本文则提出将自监督学习用于辅助小样本学习,提出了一个结合小样本学习和自监督学习的统一框架。
FSL-SSL混合学习目标:
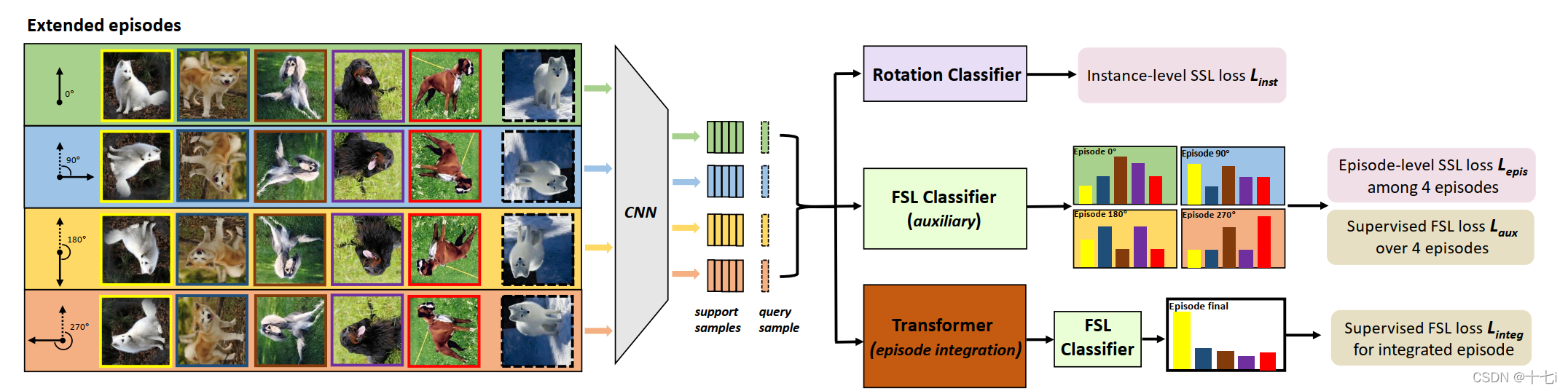
FSL-SSL混合学习目标:
- 将来自不同Extended episodes的分类器预测的一致性最大化,作为一个episode-level的前置任务。这样做的动机是,对于旋转得到不同的Extended episodes,旋转角度不应当影响FSL分类器的判断。
- 不同episodes中,提取单张图像不同旋转角度的特征被集成在一起,从而构建了单个FSL分类器。
图中的左半部分,通过对图像进行不同角度的旋转,将单个episode扩展。右半部分则分为三条支路,计算不同的损失,包含:
- L i n s t L_{inst} Linst:通过几层全连接预测图像的旋转角度,构成一项代理任务。
- L e p i s L_{epis} Lepis:计算Extended episodes预测结果之间的KL散度,促使它们的预测结果一致。
- L a u x L_{aux} Laux & L i n t e g L_{integ} Linteg:都是FSL对于episode的预测结果计算得到的交叉熵损失,不同处在于第三条之路采用了自注意力模块(SA)对特征进行了融合。
在推理阶段,模型使用第三条支路进行推理。
2. CSS(Conditional Self-Supervised Learning for Few-Shot Classification)
自监督学习通常需要大量的训练样本,不适用于小样本场景。这篇文章提出使用监督信息指导自监督学习的过程,并且设计了一个特征融合模块,整合了监督模型和自监督模型提取的特征。
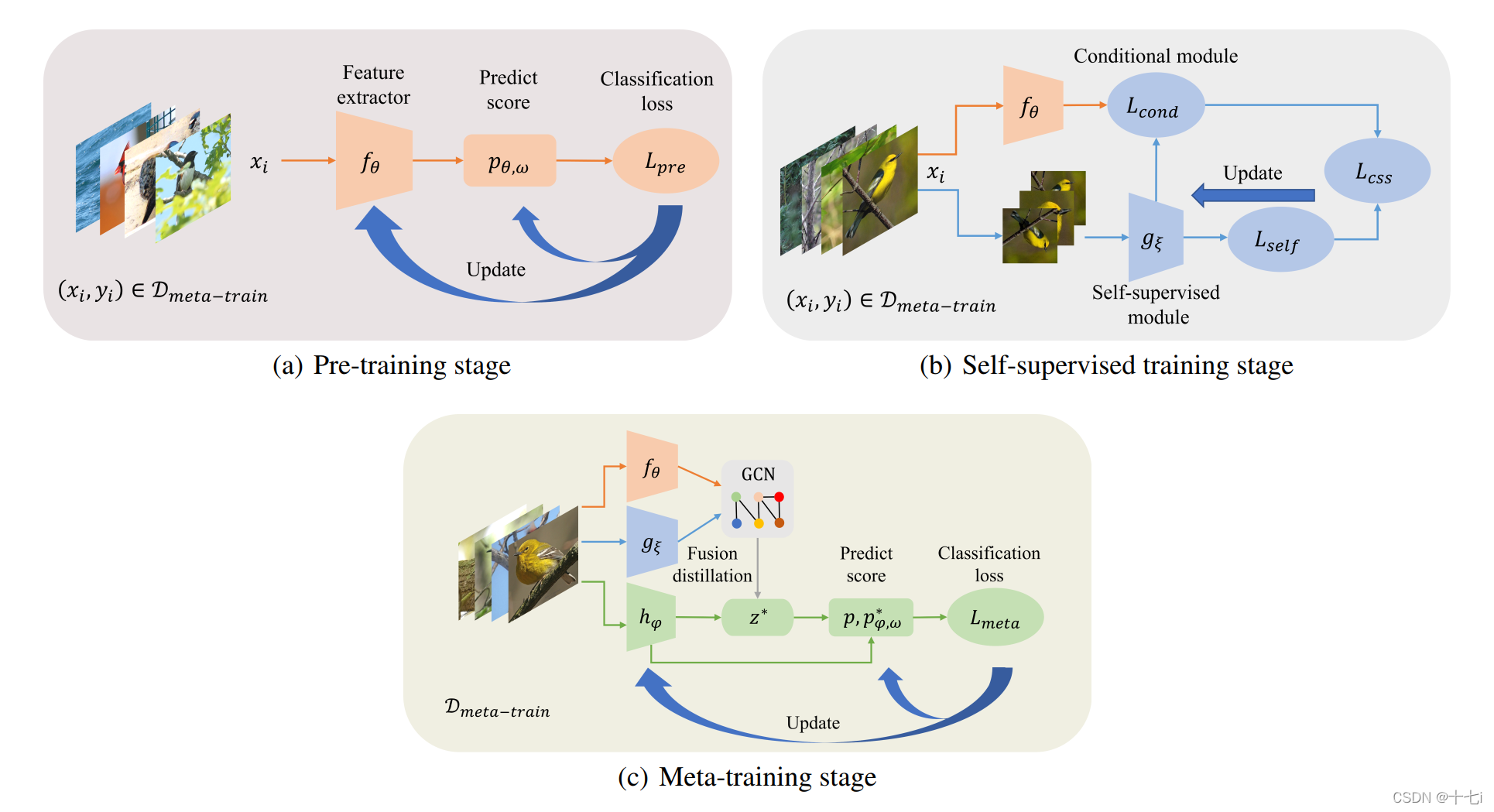
训练过程分为三阶段:
- Pre training:采用原型网络相同的训练方式。
- SSL training:这里采用了一个 L c o n d L_{cond} Lcond,实际是余弦相似性损失,意在使用Pre training训练的模型来指导自监督学习。
- Meta training:这里在计算原型时,采用了两种方式提取的特征。一种是 f f f和 g g g的特征经过GCN融合,一种通过 h h h提取,最后计算了两次余弦相似度损失累加求和。
3. Meta-Baseline: Exploring Simple Meta-Learning for Few-Shot Learning
这篇文章探究了为什么在小样本分类,标准的预训练模型优于元训练模型。
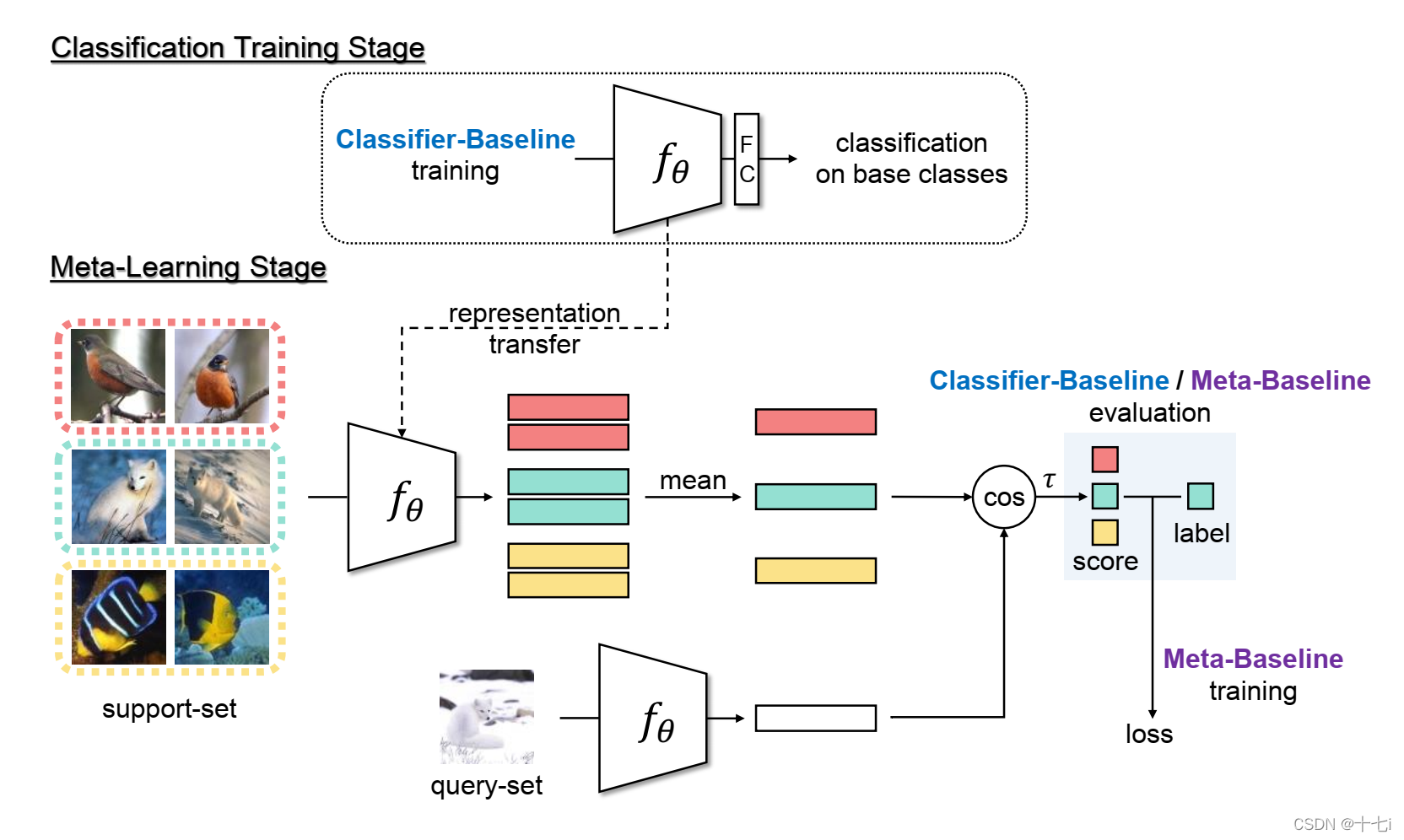
Classifier-Baseline就是常规的预训练方式,Meta-Baseline则是在预训练的基础上增加了元训练进行微调。
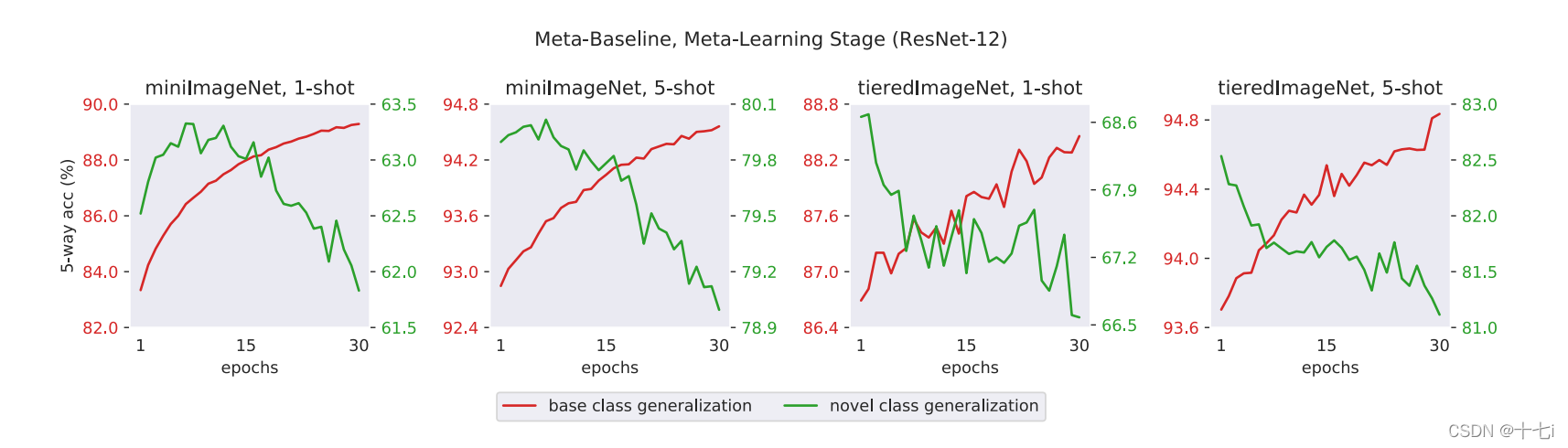
论文所得出的结论是:meta-training能够提升模型对基类的泛化性能,但同时会削弱其对新类的泛化能力。原因是meta-training导致了模型对类别空间的过拟合,而非样本空间。对比常规训练和meta-training训练,常规训练具有更好的类可迁移性。














 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









