







q: 为什么要用动量法
a: 梯度下降存在以下问题:
一个输入和输出分别为二维向量x=[x1,x2]T和
标量的目标函数f(x)=0.1x12 + 2x22
基于这个目标函数的梯度下降,并演示使用学习率为0.40.4时自变量的迭代轨迹。
import sys
sys.path.append("d2lzh_pytorch.py")
import d2lzh_pytorch as d2l
import torch
eta = 0.4 # 学习率
def f_2d(x1, x2):
return 0.1 * x1 ** 2 + 2 * x2 ** 2
def gd_2d(x1, x2, s1, s2):
return (x1 - eta * 0.2 * x1, x2 - eta * 4 * x2, 0, 0)
d2l.show_trace_2d(f_2d, d2l.train_2d(gd_2d))
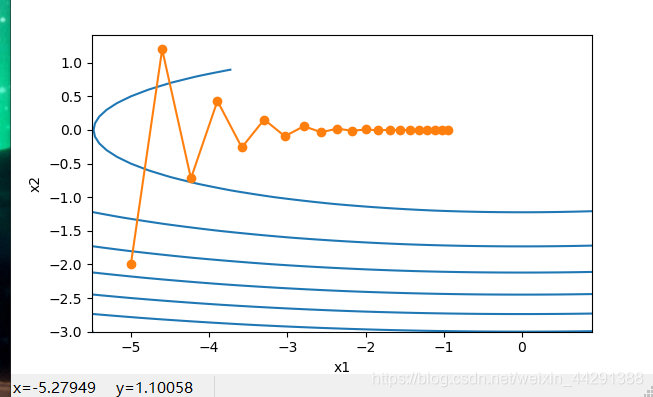
存在的问题:
同一位置上,目标函数在竖直方向(x2轴方向)比在水平方向(x1 轴方向)的斜率的绝对值更大。
因此,给定学习率,梯度下降迭代自变量时会使自变量在竖直方向比在水平方向移动幅度更大。
那么,我们需要一个较小的学习率从而避免自变量在竖直方向上越过目标函数最优解。
然而,这会造成自变量在水平方向上朝最优解移动变慢。
学习率调得稍大一点
eta = 0.6
d2l.show_trace_2d(f_2d, d2l.train_2d(gd_2d))
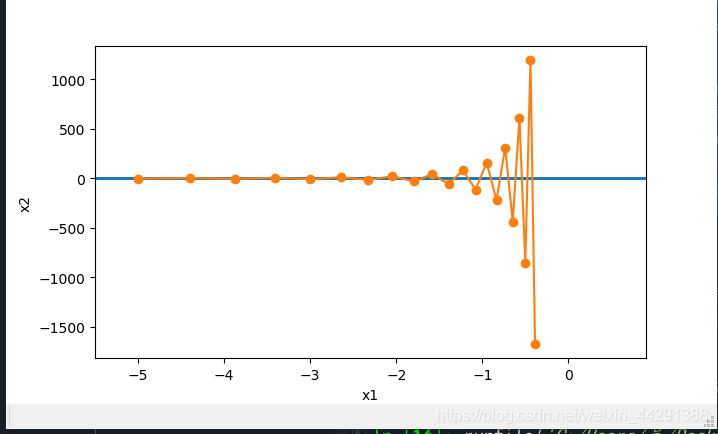
存在问题
此时自变量在竖直方向不断越过最优解并逐渐发散
为解决这个问题,引入动量法
因为上面一个学习率会同时改变x轴 和 y轴,所以动量法引入两个参数

def momentum_2d(x1, x2, v1, v2):
v1 = gamma * v1 + eta * 0.2 * x1
v2 = gamma * v2 + eta * 4 * x2
return x1 - v1, x2 - v2, v1, v2
eta, gamma = 0.4, 0.5
d2l.show_trace_2d(f_2d, d2l.train_2d(momentum_2d))
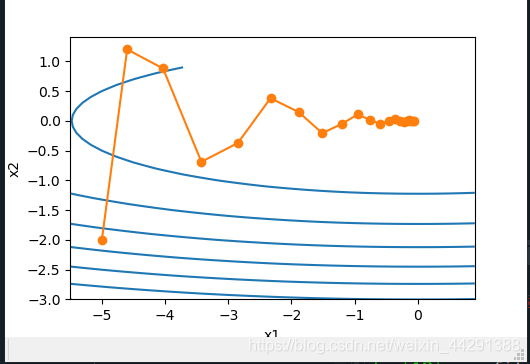
使用较小的学习率η=0.4η=0.4和动量超参数γ=0.5γ=0.5时,动量法在竖直方向上的移动更加平滑,且在水平方向上更快逼近最优解。
下面使用较大的学习率η=0.6η=0.6,此时自变量也不再发散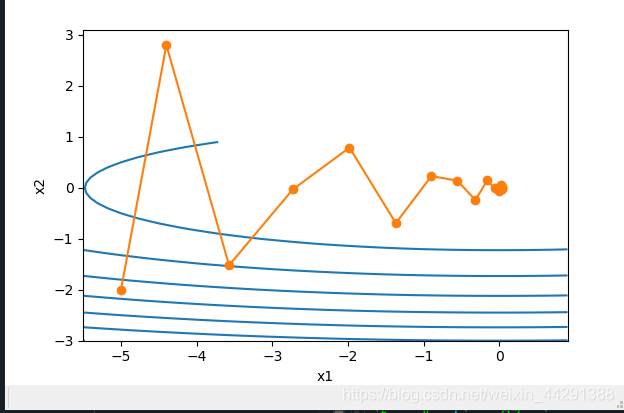
进一步理解动量
指数加权移动平均


看完上面或许感觉比较麻烦,但是在PyTorch中,只需要通过参数momentum来指定动量超参数即可使用动量法。
features, labels = d2l.get_data_ch7()
d2l.train_pytorch_ch7(torch.optim.SGD, {'lr': 0.004, 'momentum': 0.9},
features, labels)
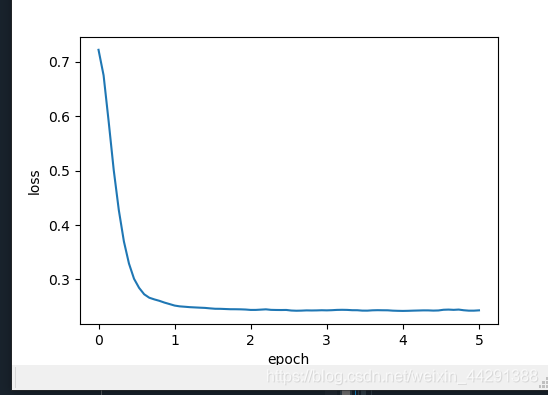
*动量法使用了指数加权移动平均的思想。它将过去时间步的梯度做了加权平均,且权重按时间步指数衰减。
*动量法使得相邻时间步的自变量更新在方向上更加一致。
d2lzh_pytorch














 990
990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









