






转载自:生信天地
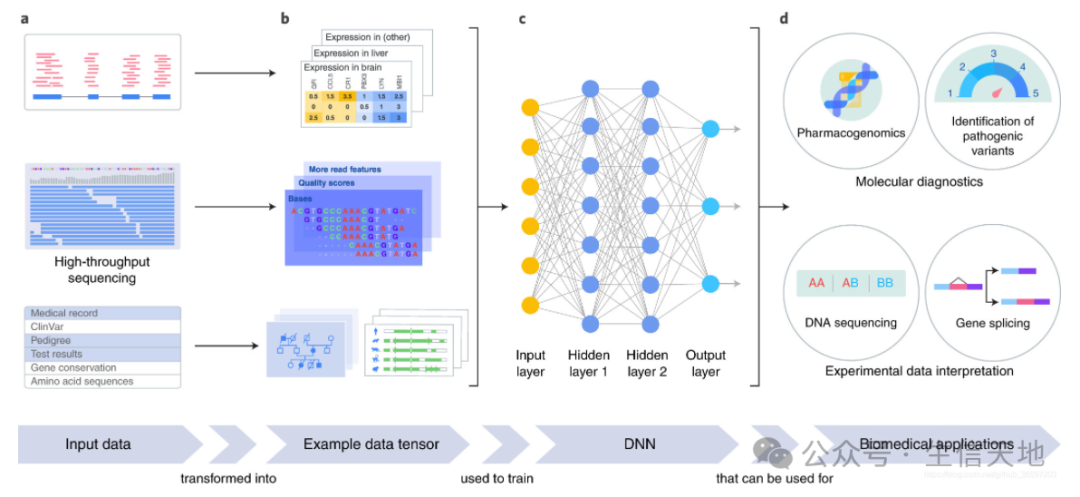
一、深度学习概念定义
深度学习(Deep Learning)是机器学习的一个子领域,它基于人工神经网络,尤其是深度神经网络。深度学习的核心思想是通过学习数据的表示层次和抽象层次,让机器能够具有类似于人类的分析学习能力。深度学习的“深度”一词指的是神经网络中隐藏层的数量,通常一个深度学习模型的隐藏层会比较多,从而使其能够从输入数据中学习到更复杂、更抽象的特征。
二、深度学习的特点
1. 强大的特征学习能力:深度学习模型能够自动从原始数据中学习到有用的特征,而无需人工进行特征提取。
2. 层次化的表示:深度学习模型通过多层非线性变换,对数据进行逐层抽象,从而形成层次化的表示。
3. 大数据适应性:深度学习模型在大规模数据集上表现优异,能够处理复杂的模式识别和分类任务。
4. 端到端学习:深度学习模型可以实现从原始输入到最终输出的直接映射,简化了机器学习任务的流程。
三、深度学习分类
根据神经网络的架构和训练方式,深度学习大致可以分为以下几类:
1. 卷积神经网络(CNN):主要用于图像处理领域,通过卷积层、池化层和全连接层的组合,学习图像中的局部特征和全局特征。
2. 循环神经网络(RNN):主要用于序列数据处理,如语音识别、文本生成等,能够捕捉序列数据中的时序依赖关系。
3. 生成对抗网络(GAN):由生成器和判别器两部分组成,通过对抗训练生成逼真的数据样本。
4. 自编码器(AE)和变分自编码器(VAE):通过无监督学习学习数据的低维表示,可用于数据压缩、特征提取和生成等任务。
5. 强化学习(RL):通过与环境的交互进行学习,使智能体能够在给定的任务中做出最优决策。
四、深度学习与其他算法的异同
深度学习与其他机器学习方法的主要区别在于其对数据表示的学习方式。其他机器学习方法,如支持向量机(SVM)、决策树等,通常需要人工设计和选择特征,而深度学习则能够自动从原始数据中学习到有用的特征。此外,深度学习在大规模数据集上的表现通常优于其他机器学习方法,但也需要更多的计算资源和训练时间。
五、深度学习在生物信息学中的应用
深度学习在生物信息学领域的应用日益广泛,取得了许多重要的研究成果。以下是一些典型的应用实例:
1. 基因组学:深度学习可以用于基因组序列分析,如基因预测、基因组结构和功能注释等。例如,卷积神经网络可以用于识别基因组中的保守序列模式,进而预测基因的位置和功能。
2. 转录组学:深度学习可以用于分析RNA测序数据,识别差异表达基因和调控网络。循环神经网络可以捕捉基因表达的时间序列变化,揭示基因调控的动态过程。
3. 蛋白质组学:深度学习可以用于蛋白质结构预测、功能注释和相互作用预测等任务。例如,AlphaFold等深度学习模型在蛋白质结构预测方面取得了突破性进展。
4. 代谢组学:深度学习可以用于代谢物鉴定、代谢途径分析和疾病标志物发现等任务。通过学习代谢产物的光谱特征或质谱特征,深度学习模型可以准确地鉴定和定量代谢物。
5. 疾病诊断和治疗:深度学习可以用于疾病诊断、药物设计和个性化治疗等方面。例如,深度学习模型可以通过分析病理图像或基因表达数据辅助医生进行疾病诊断;通过学习药物与靶标的相互作用机制,设计新的靶向药物;根据患者的基因组和其他临床信息制定个性化的治疗方案。
六、代码示例
以下是一个简单的Python代码示例,演示如何使用深度学习模型进行基因表达数据分类:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.optimizers import Adam
# 加载基因表达数据集
data = pd.read_csv('gene_expression.csv')
X = data.iloc[:, 1:] # 特征矩阵(去除第一列的样本标签)
y = data.iloc[:, 0] # 标签向量
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建深度学习模型
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(X_train.shape[1],)))
model.add(Dropout(0.5))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(optimizer=Adam(lr=0.001), loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=100, batch_size=32, validation_split=0.1)
# 评估模型性能
loss, accuracy = model.evaluate(X_test, y_test)
print('Test loss:', loss)
print('Test accuracy:', accuracy)在这个示例中,我们首先加载了一个基因表达数据集(假设文件名为`gene_expression.csv`),然后使用`train_test_split`函数将数据集划分为训练集和测试集。接着,我们构建了一个包含两个隐藏层和一个输出层的深度学习模型,并使用`Adam`优化器和二元交叉熵损失函数进行模型编译。最后,我们使用`fit`函数训练模型,并使用`evaluate`函数评估模型在测试集上的性能。这个示例仅用于演示目的,实际应用中可能需要调整模型结构、超参数和数据预处理步骤以获得更好的性能。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









