






安装rabbitmq
Centos7下安装rabbitmq
rabbitmq是erlang语言编写的,安装rabbitmq之前,需要先安装erlang,这里用erlang的源码进行安装,erlang安装包官网下载:http://erlang.org/download/
wget http://erlang.org/download/otp_src_21.1.tar.gz
tar -zxvf otp_src_21.1.tar.gz
cd otp_src_21.1
# 这里要新建一个erlang文件夹,因为erlang编译安装默认是装在/usr/local下的bin和lib中,这里我们将他统一装到/usr/local/erlang中,方便查找和使用。
mkdir -p /usr/local/erlang
# 在编译之前,必须安装以下依赖包
yum install -y make gcc gcc-c++ m4 openssl openssl-devel ncurses-devel unixODBC unixODBC-devel java java-devel
./configure --prefix=/usr/local/erlang
然后,直接执行make && makeinstall 进行编译安装
make && make install
然后将/usr/local/erlang/bin这个文件夹加入到环境变量中,加载以下即可直接使用。
vim /etc/profile
######### 添加如下内容 ###############
PATH=$PATH:/usr/local/erlang/bin
########################################
source /etc/profile
这里,我们安装的erlang是最新的21版本,所以,rabbitmq也要安装最新的3.7.7,3.7.8。然后在官网上,直接下载该版本的安装包,为了方便安装,最好直接使用编译好的二进制文件包,即开即用,不用进行复杂的yum配置等。具体可以参考官方文档:http://www.rabbitmq.com/install-generic-unix.html
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.7.8/rabbitmq-server-generic-unix-3.7.8.tar.xz
# 解压
tar -xvf rabbitmq-server-generic-unix-3.7.8.tar.xz -C /usr/local/
# 添加环境变量
vim /etc/profile
------ 添加如下内容 ------
PATH=$PATH:/usr/local/rabbitmq_server-3.7.8/sbin
# 重载一下环境变量
source /etc/profile
# 添加web管理插件
rabbitmq-plugins enable rabbitmq_management
默认rabbitmq是没有配置文件的,需要去官方github上,复制一个配置文件模版过来,最新的3.7.0以上的版本可以使用新的key-value形式的配置文件rabbitmq.conf,和原来erlang格式的advanced.config相结合,解决一下key-value形式不好定义的配置。github地址:https://github.com/rabbitmq/rabbitmq-server/tree/master/docs
ok,然后就可以启动rabbitmq服务了,其实没有配置文件也是可以启动服务的。
# 后台启动rabbitmq服务
rabbitmq-server -detached
上面,启用了rabbitmq的管理插件,会有一个web管理界面,默认监听端口15672,将此端口在防火墙上打开,则可以访问web界面:
使用默认的用户 guest / guest (此也为管理员用户)登陆,会发现无法登陆,报错:User can only log in via localhost。那是因为默认是限制了guest用户只能在本机登陆,也就是只能登陆localhost:15672。可以通过修改配置文件rabbitmq.conf,取消这个限制: loopback_users这个项就是控制访问的,如果只是取消guest用户的话,只需要loopback_users.guest = false 即可。
然后,就能登陆到web控制界面:
下面列举一下常用的一些命令行操作:
服务启动停止:
启动: rabbitmq-server -detached
停止: rabbitmqctl stop
插件管理:
插件列表: rabbitmq-plugins list
启动插件: rabbitmq-plugins enable XXX (XXX为插件名)
停用插件: rabbitmq-plugins disable XXX
用户管理:
添加用户: rabbitmqctl add_user username password
删除用户: rabbitmqctl delete_user username
修改密码: rabbitmqctl change_password username newpassword
设置用户角色: rabbitmqctl set_user_tags username tag
列出用户: rabbitmqctl list_users
权限管理:
列出所有用户权限: rabbitmqctl list_permissions
查看制定用户权限: rabbitmqctl list_user_permissions username
清除用户权限: rabbitmqctl clear_permissions [-p vhostpath] username
设置用户权限: rabbitmqctl set_permissions [-p vhostpath] username conf write read
conf: 一个正则匹配哪些资源能被该用户访问
write:一个正则匹配哪些资源能被该用户写入
read:一个正则匹配哪些资源能被该用户读取
python库
pip install pika
RabbitMQ工作原理及应用
队 列
这种模式就是简单的生产消费者模型。消息队列是一个FIFO的队列
生产者 send.py ,消费者recv.py
import pika
#创建链接
usr = pika.PlainCredentials('hua','hua')
parms = pika.ConnectionParameters('192.168.124.7',5672,virtual_host='test',credentials=usr)
connection = pika.BlockingConnection(parms)
#建立通道
channel = connection.channel()
with connection:
#创建一个队列
channel.queue_declare('hello') #queue
#publish
for i in range(40):
channel.basic_publish(
exchange='',
routing_key='hello', #保证和queue一致
body=f'test {i}' # 消息
)
print('end======')
import pika
url = pika.URLParameters('amqp://hua:hua@192.168.124.7/test')
conn = pika.BlockingConnection(url)
channel = conn.channel()
#单条处理
# with conn:
# data = channel.basic_get('hello',True)
# print(data)
# method,props,body = data
# print(body)
def callback(channel,method,props,body):
print(body)
with conn:
tag = channel.basic_consume(on_message_callback=callback,queue='hello',auto_ack=True) #可以消费数据
# channel.basic_cancel() #在运行取消不了
channel.start_consuming() #forever 阻塞 想干其他的事情 多线程
工作队列
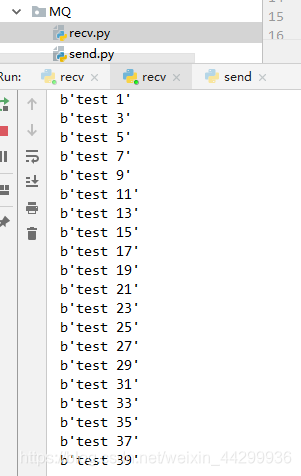
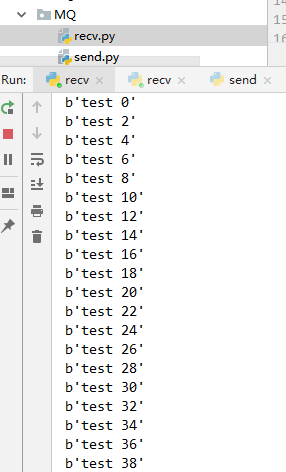
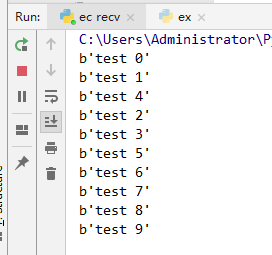
上面结果是同样的代码 多开了一个recv 只有一个队列。 由结果可知这个模式是轮流拿任务,而不是争取
发布 订阅模式
Publish / Subscribe 发布和订阅,发个比方:订阅报纸,订阅者(消费者)订阅报纸(消息),都能拿到同样的报纸
订阅者之间还有一个exchange,可以当成邮局,消费者去邮局订阅报纸,报社发报纸到邮局,邮局决定如何送到消费者手里。
这模式exchange的type是fanout,就是一对多,即广播模式。
注意:同一个queue的消息只能被消费一次,因此,这里使用多个queue。相当于为了保证不同消费者拿到同样的数据,每一个消费者都应该有自己的queue。
生产者使用广播模式。在test虚拟主机下构建logs交换机。交换机bind绑定 queue
import pika
exchange = 'logs'
queue = ''
usr = pika.PlainCredentials('hua','hua')
parms = pika.ConnectionParameters('192.168.124.7',5672,virtual_host='test',credentials=usr)
connection = pika.BlockingConnection(parms)
#建立通道
channel = connection.channel()
channel.exchange_declare(
exchange=exchange, #交换机名称
exchange_type='fanout' #工作模式:广播
)
with connection:
#publish
for i in range(40):
channel.basic_publish(
exchange=exchange,
routing_key='', #广播模式 这个无所谓了
body=f'test {i}' # 消息
)
print('end')
import pika
exchange = 'logs'
url = pika.URLParameters('amqp://hua:hua@192.168.124.7/test')
conn = pika.BlockingConnection(url)
channel = conn.channel()
channel.exchange_declare(
exchange=exchange, #交换机名称
exchange_type='fanout' #工作模式:广播
)
q1 = channel.queue_declare(queue='q1',exclusive=True) #随机名称队列(断开连接queue就被删除)
q2 = channel.queue_declare(queue='q2',exclusive=True) #
name1 = q1.method.queue #得到随机queue的名字
name2 = q2.method.queue
def callback(channel,method,props,body):
print(body)
with conn:
tag1 = channel.basic_consume(on_message_callback=callback,queue=name1 ,auto_ack=True)
tag2 = channel.basic_consume(on_message_callback=callback, queue=name2, auto_ack=True)
channel.start_consuming()
与前面的工作队列不同的是 这里指定了交换机
上面的代码由于没有将交换机与队列绑定 所以后台可以看到没有数据传输,没有绑定,就是弟弟,没有用!
import pika
exchange = 'logs'
url = pika.URLParameters('amqp://hua:hua@192.168.124.7/test')
conn = pika.BlockingConnection(url)
channel = conn.channel()
channel.exchange_declare(
exchange=exchange, #交换机名称
exchange_type='fanout' #工作模式:广播
)
q1 = channel.queue_declare(queue='',exclusive=True) #随机名称队列(断开连接queue就被删除)
q2 = channel.queue_declare(queue='',exclusive=True) #
name1 = q1.method.queue #得到随机queue的名字
name2 = q2.method.queue
#绑定
channel.queue_bind(name1,exchange)
channel.queue_bind(name2,exchange)
def callback(channel,method,props,body):
print(body)
with conn:
tag1 = channel.basic_consume(on_message_callback=callback,queue=name1 ,auto_ack=True)
tag2 = channel.basic_consume(on_message_callback=callback, queue=name2, auto_ack=True)
channel.start_consuming()
queue绑定交换机后再看后台
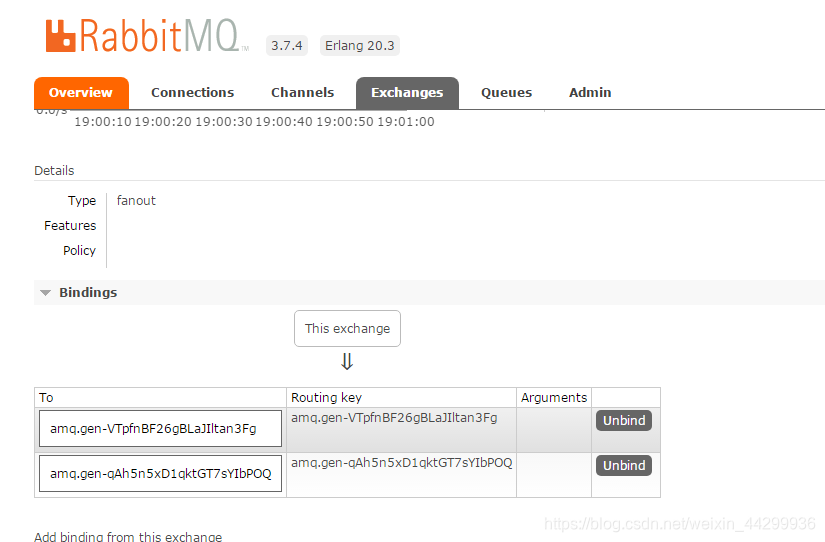
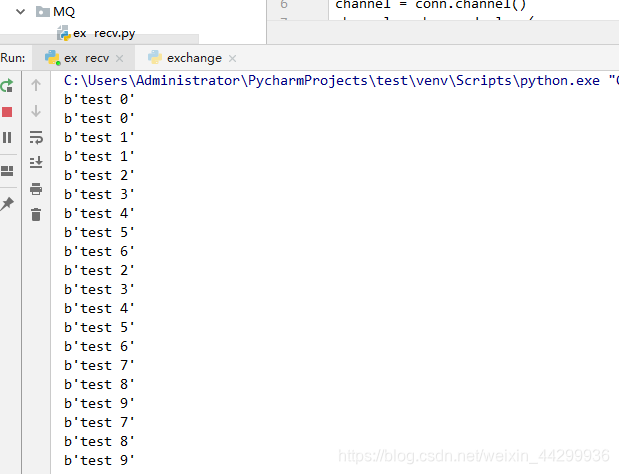
看结果可以对列队速度不一样 以后可以 设计任务难度大多开几个队列
路由模式
路由就是生产者的数据经过exchange的时候,通过匹配规则,决定数据的去向。
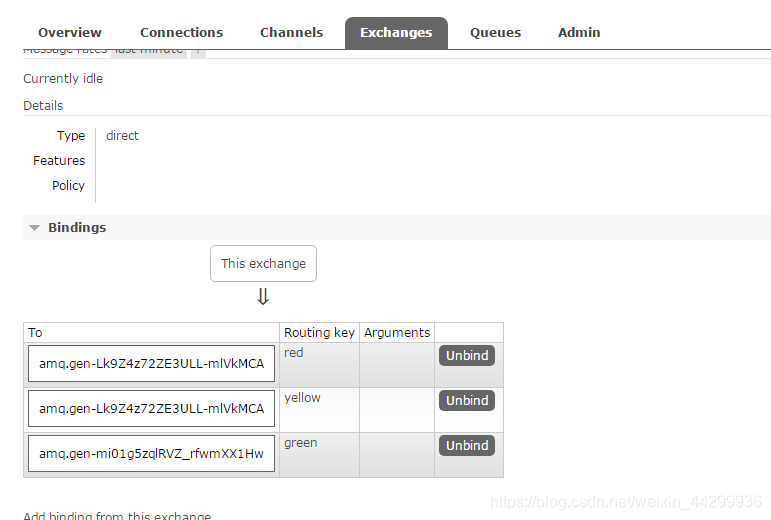
生产者随机产出不同颜色数据 路由选择(必须有routing_key)queue传输 和上面的模式不同的是有多少数据 收到多少数据。虽然路由和queue绑定了,但是只看routing_key!
import pika
exchange = 'color'
colors = ('green','red','yellow')
url = pika.URLParameters('amqp://hua:hua@192.168.124.7/test')
conn = pika.BlockingConnection(url)
channel = conn.channel()
channel.exchange_declare(
exchange, #交换机名称
'direct' #工作模式:广播
)
q1 = channel.queue_declare(queue='',exclusive=True) #随机名称队列(断开连接queue就被删除)
q2 = channel.queue_declare(queue='',exclusive=True) #
name1 = q1.method.queue #得到随机queue的名字
name2 = q2.method.queue
#绑定
channel.queue_bind(name1,exchange,routing_key=colors[0])
channel.queue_bind(name2,exchange,routing_key=colors[1])
channel.queue_bind(name2,exchange,routing_key=colors[2])
def callback(channel,method,props,body):
print(body)
with conn:
tag1 = channel.basic_consume(on_message_callback=callback,queue=name1 ,auto_ack=True)
tag2 = channel.basic_consume(on_message_callback=callback, queue=name2, auto_ack=True)
channel.start_consuming()
import pika
import random
exchange = 'color'
colors = ['green','red','yellow']
usr = pika.PlainCredentials('hua','hua')
parms = pika.ConnectionParameters('192.168.124.7',5672,virtual_host='test',credentials=usr)
connection = pika.BlockingConnection(parms)
#建立通道
channel = connection.channel()
channel.exchange_declare(
exchange, #交换机名称
'direct' #工作模式:广播
)
with connection:
#publish
for i in range(10):
rk = '{}'.format(colors[random.randint(0,2)])
channel.basic_publish(
exchange=exchange,
routing_key=rk, #广播模式 这个无所谓了
body=f'test {i}' # 消息
)
print('end')
PS:另外这个模式可以多播,多个queue路由一样 数据会被多个对列接受
Topic
topic就是更高级的路由,支持模式匹配
topic的routing_key必须使用.点号分割的单词组成。最多255个字节
支持使用通配符:
- *表示严格的一个单词
- #表示0个或者多个单词
如果queue绑定的routing_key只是一个#,这个queue接受所有的消息
没有通配符,效果类似于direct (路由模式)
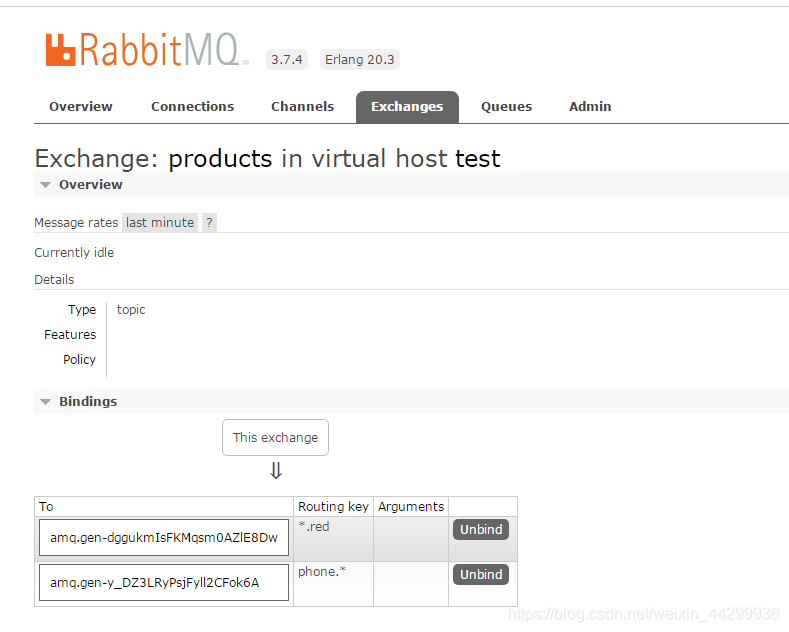
import pika
import random
exchange = 'products'
products= ('phone','tv','bike')
topics = ('phone.*','*.red')
colors = ['green','red','yellow']
usr = pika.PlainCredentials('hua','hua')
parms = pika.ConnectionParameters('192.168.124.7',5672,virtual_host='test',credentials=usr)
connection = pika.BlockingConnection(parms)
#建立通道
channel = connection.channel()
channel.exchange_declare(
exchange, #交换机名称
'topic'
)
with connection:
#publish
for i in range(10):
rk = '{}.{}'.format(products[random.randint(0,2)],colors[random.randint(0,2)])
channel.basic_publish(
exchange=exchange,
routing_key=rk, #广播模式 这个无所谓了
body=f'test {rk,i}' # 消息
)
print('end')
import pika
exchange = 'products'
products= ('phone','tv','bike')
topics = ('phone.*','*.red')
colors = ('green','red','yellow')
url = pika.URLParameters('amqp://hua:hua@192.168.124.7/test')
conn = pika.BlockingConnection(url)
channel = conn.channel()
channel.exchange_declare(
exchange, #交换机名称
'topic' #工作模式:话题
)
q1 = channel.queue_declare(queue='',exclusive=True) #随机名称队列(断开连接queue就被删除)
q2 = channel.queue_declare(queue='',exclusive=True) #
name1 = q1.method.queue #得到随机queue的名字
name2 = q2.method.queue
#绑定
channel.queue_bind(name1,exchange,routing_key=topics[0])
channel.queue_bind(name2,exchange,routing_key=topics[1])
# channel.queue_bind(name2,exchange,routing_key=colors[2])
def callback(channel,method,props,body):
print(body)
with conn:
tag1 = channel.basic_consume(on_message_callback=callback,queue=name1 ,auto_ack=True)
tag2 = channel.basic_consume(on_message_callback=callback, queue=name2, auto_ack=True)
channel.start_consuming()
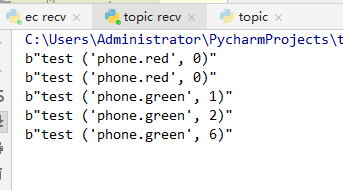
由结果可知 ,topic模式是不可预测多少数据的
RPC远程过程调用
服务和服务之间的通信
有更好的RPC通信框架,不建议使用
消息队列的作用
- 系统间解耦:原来都是耦合在一起,多线程之类的,虽然要跨进程,但是代码分开,各个功能单独形成应用程序,功能越少,程序越好实现和稳定
- 解决生产者,消费者速度匹配:异步调用
由于项目分层,分模块开发,模块间或系统尽量不要耦合,需要开放公共接口提供给别的模块或系统调用,而调用可能触发并发问题,为了缓冲和解耦,往往采用中间件技术。(RabbitMQ只是中间件中的一个应用程序,也是常见的消息中间件的服务)
最后只有消息队列支持AMPQ 都可以用RabbitMQ,学其他的消息队列,学不同即可!














 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









