









先给出Seq2Seq Attention的计算过程的截图,来源于知乎Yuanche.Sh的题为真正的完全图解Seq2Seq Attention模型的文章,也希望你阅读了我的上一篇文章:Seq2Seq Attention(这三篇就够了,精心发掘整理)
这样对Seq2Seq Attention会有一个比较基础全面的认识。为了进一步加深对于Seq2Seq Attention的认识,我们还需要搞懂,Seq2Seq Attention数据输入输出维度的变化。

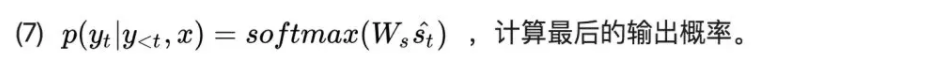
上述流程图是常见的一种Seq2Seq Attention,虽然Attention有多种,但是我们搞懂一种维度的变化后,那么其它的类似。这里我采用具体的数据来说明,这样更直观一些。我们从第一步开始看,假设输入数据xt的形状是[N,100],其中N表示batch_size,表示批次大小,也即一个批次含有的句子数目,这里我们没有给出具体是多少,但是不影响接下来的理解,100为input_dim也就是输入数据的维度。ht-1为时刻t-1的状态,形状为[N,128],其中,128为RNN中的神经元数目,也就是Encoder神经网络输出的维度大小。ht的形状当然和ht-1是一样的。这里你可能会问,xt的形状和ht-1不一样,如何一起运算呢?其实这个(1)式省略了系数矩阵,完整的应该是这样子的:
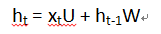
这里U的形状为[100,128],W的形状为[128,128],也就是说,通过一个系数矩阵U,把原来形状为[N,100]的输入数据xt转换成了[N,128],所以说,输入数据其实无论什么维度,都可以很方便的找到对应的转换矩阵将之转换为我们神经网络所需要的形状。
再看第二步,由于Decoder网络的第一个隐状态s0就是Encoder网络最后一个时刻的隐状态,在Seq2Seq中就是我们常见的c,所以Decoder网络隐状态的形状和Encoder的隐状态的形状是完全一样的。即st-1和st的形状均为[N,128],而y是我们的目标单词(Target word)所生成的word embedding,也就是一个词向量,和xt很类似,为了统一,我们也可以将y的维度设为[N,100]。这里和(1)式一样,也隐藏了系数矩阵。
对于计算Attention的(3),(4),(5)步,我们首先从(5)步说起,这一步作用是计算Attention score,这一步的方式有多种,但是搞懂一种,其它方式的类似。我们这里采取了
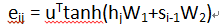
hj和si-1的形状均是[N,128],所以W1和W2形状也一样。其中,j和i分别表示Encoder和Decoder的时间序列的时刻。这里有两种做法,一种是W1和W2的形状都是[128,128],这样得到的eij的形状为[N,128],另一种W1和W2的形状都是[128,1],这样的话,eij的形状便为[1,1],其实就是一个单个的值了。理论上这两种方法都是可以的,但是前者保留了更细致的维度信息,所以效果可能稍好些,所以也最常用,但是相应的计算量会增加。我们这里采用第一种,这样便得到了eij的形状为[N,128].
再看第(4)步,由于分子分母的形状均是[N,128],,所以αij的大小也为[N,128],通过点乘和累加的方式得到的ct形状同样是[N,128]。
(6),(7)步就比较好理解了,每个参数的形状均是 [N,128],这里的y<t表示y0,y1…yt-1.
需要注意的是,(7)步只是得到了目标单词(target word)的概率分布,而得到具体的单词还需要更近一步,就是将此概率分布设为Ot,也即:
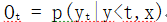
则具体的单词通过下式求得:
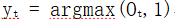
这个公式表示只取概率最大值对应的那一个单词的索引。Yt的形状变为[1,1],也就是一个单独的单词索引。通过这个索引我们在字典中可以查到相应的单词:
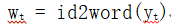














 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









