






Python处理Unicode字符时出现中文乱码的情况
Unicode字符时出现中文乱码
遇见\u开头的编码,如\u0032\u0030\u0031\u0039\u002D\u0031\u0031即为Unicode字符
例:\u003C 相当于<, \u003E相当于>
python3中最常用的转换方式是
str1 = '\u4f60\u597d'
# python3中只能先编码再解码,python2的话可以直接解码
print(str1.encode('unicode-escape').decode('unicode-escape'))
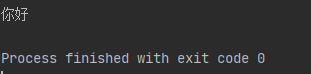
可如果先经过中文格式编码(UTF-8)再获取Unicode解码的话就会出现中文字符变成混乱符号的情况
# -*- coding: utf-8 -*-
str1 = '\u4f60\u597d'
# python3中只能先编码再解码,python2的话可以直接解码
print(str1.encode('unicode-escape').decode('unicode-escape'))
print(str1.encode('utf-8').decode('unicode-escape'))
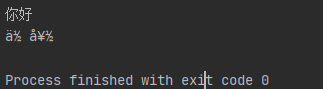
原因:
当对字符串进行编码后,要对其解码变回中文,这是坑就来了,默认先转的中文识别的是gbk格式这才导致我们得到了乱码而不是我们想要的值。
解决方法:
通过raw_unicode_escape,将此str转化为bytes, 再decode为str。从而规避直接转中文导致格式变成gbk的坑
# -*- coding: utf-8 -*-
str1 = '\u4f60\u597d'
# python3中只能先编码再解码,python2的话可以直接解码
print(str1.encode('unicode-escape').decode('unicode-escape'))
print(str1.encode('raw_unicode_escape').decode('unicode-escape'))
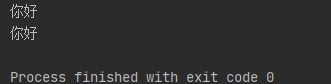
实际应用场景
个人遇见这个问题是在访问一个html页面后,返回给我的是Unicode格式并带中文的标签内容,这时候我就需要将返回过来的内容转换成正常的html标签格式,再从里面获取我需要的标签。
PS:个人遇见的一个内容都是用document.write渲染的页面踩的这个坑
将字符串用utf-8编码再用unicode-escape解码会导致如下情况
str1.encode('utf-8').decode('unicode-escape')
现在打印:// éšè—备案信æ¯å±•ç¤º
正常情况:// 隐藏备案信息展示
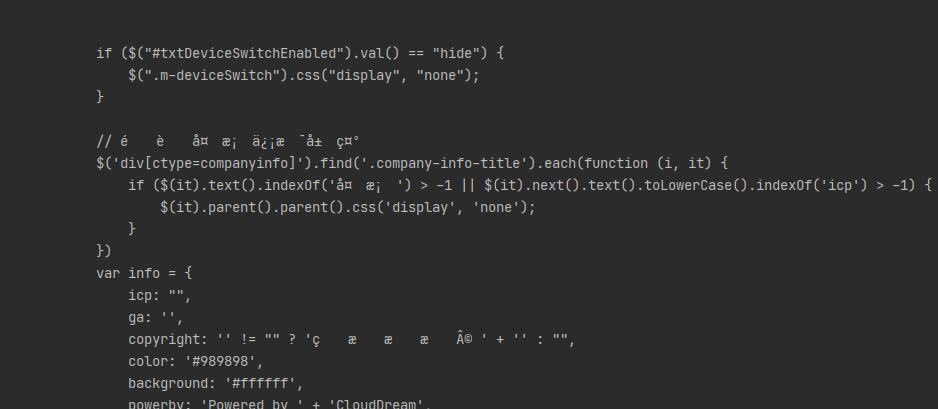
其中的中文字符都出现该问题,就可以用到上述方法解决。
转载:
本文作者: 红 后
本文链接: https://www.cnblogs.com/Red-Sun/p/17219414.html















 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









