







《A Three-Layered Graph-Based Learning Approach for Remote Sensing Image Retrieval》(2016 IEEE)
这篇文章提出了一种基于图(graph)的三层框架来进行遥感图像检索,这个方法的特点在于将整体特征和局部特征相互融合起来,得到更精确的检索结果。
这里贴一下完整的网络结构。
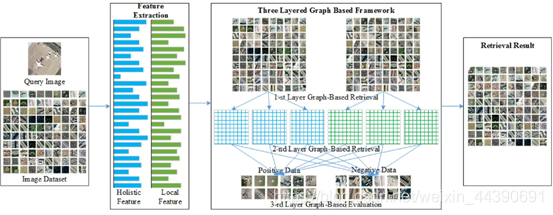
首先是第一层。第一层又细分为两个步骤:第一步,为每一张query图像构造一个无向图G=(V, E, W),其中V代表图像,E是两个图像之间的边缘(edge),W是权重;第二步,通过使用基于图的整体特征和局部特征学习算法,获得两个检索图像列表(两个列表都是按照最佳成对相关性从大到小的顺序排列,但由于获取的途径不同,就会导致列表中的member、顺序等会有一些差异),分别是H_LQ和L_LQ。整体特征用GIST描述符,局部特征用SIFT描述符。
然后是第二层。在从第一层中获取两个列表之后,接下来要做的就是从列表中筛选出三种图像:H_LQ中排名靠前的图像、L_LQ中排名靠前的图像、两个列表中共同拥有的图像。由此获得三种类型的图形锚点:PH,PL和PC。PH和PL是两个列表中排名最高的图像,PC包含两个列表的公共相似图像。然后,以PH、PL和PC作为query,通过整体特征或局部特征学习算法检索数据库图像。这一步骤中用到了一个叫做RS(relative score)的函数:
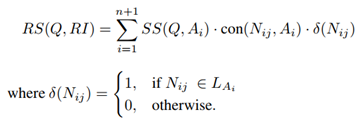
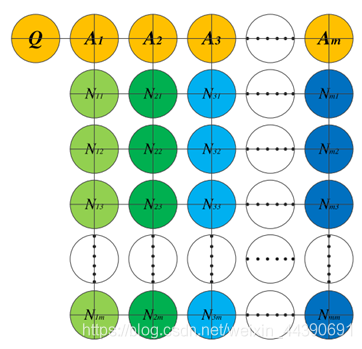
因此,总共可以获得包含检索到的图像的六个列表。这个过程可以用一个示意图表示:(先以图像Q为query,检索到横向列表A;然后以列表A中的每一张图片作为query,检索到纵向列表N1、N2、…、Nm)
最后是第三层。在检索一个query图片的相似对象的时候,往往会用到不止一个特征。那么对于多个特征共存的情况下,不同特征的权重不同,就需要一个融合的过程。
首先,筛选正样本和负样本。把检索到的六个列表中排名靠前的汇总在一起,形成正样本列表(LG),排名在底部的汇总为负样本列表(LD)。然后用这些样本和一个函数来训练simpleMKL(一种算法,用来学习融合权重)的参数:
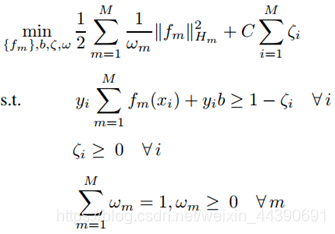
这个优化过程使用SVM求解。
最后我们希望得到的就是所有的wm权重参数。最后,把融合结果放到下面这个核函数中,得到最终的检索排序:
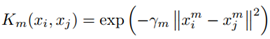
这个核函数是用来衡量两个图片之间相似性的。注意,这个函数针对的是一种特征的情况。那么要推广到多种特征的场景,就要扩展到下面的这个核函数:
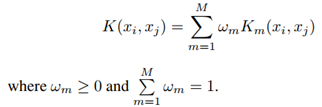
对于这一部分我一开始觉得有一点疑惑:在选取正负样本的时候,为什么要从初步检索出的六个列表中选取排名靠后的样本,而不是直接从六个列表以外的数据中抽取?后来仔细想了想,觉得作者可能是借鉴了curriculum mining的思想,希望通过适当地提高负样本的hard程度来提升检索的精确度。不过这里作者还是没有设计实验环节来进行精确的控制,这也导致了实验结果仍存在一点欠缺。
实验在UC-MERCED数据集上进行,评估标准采用ANMRR和PR曲线。
文章用所提出的三层框架和另外4中最先进的方法进行比较,分别是PHOG(方向梯度直方图金字塔)、Local invariants(局部不变式)、PHOW(单词金字塔直方图)、Global morphological texture descriptors(整体形态纹理描述符)。
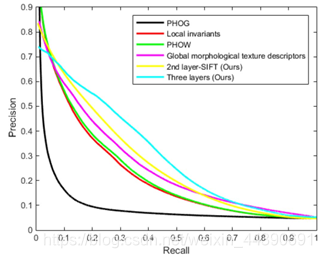
这里给出了几种方法比较的PR曲线,可以看出所提出的three layers方法的表现是最优的,因为曲线下的面积最大。但是在recall值为0.1左右之前,three layers方法的精确度不如其他方法。根据recall值的定义来看,这个原因应该是训练集中的正负样本选取稍微有些问题,导致TP值偏小或者FN值偏大。
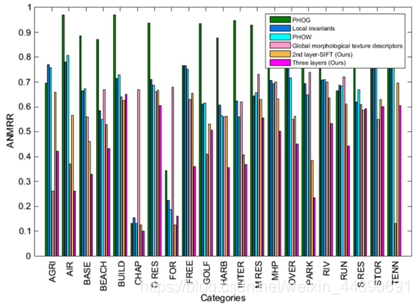
此外,还给出了几种方法在不同类别的图像中的ANMRR值的比较。ANMRR是平均归一化修正检索排序,取值在[0,1]之间。如果ANMRR取值为0,则说明图像库中所有相关图像全部被检索了出来,反之当ANMRR为1时,情况相反。也就是说,ANMRR值越小越好。从上图可以看出,除了“农田”、“森林”、“网球场”这三个场景中,three layer的ANMRR值不是最小以外,在绝大多数情况下three layer的检索结果是最优的。

这里还给出了几种方法检索时间上的比较。可以看出three layer方法ANMRR最优,但检索时间较长,仅比Global morphological texture descriptors时间短。Three layer方法主要在特征提取的环节耗费了较多的时间,因为使用simpleMKL算法在全局特征和局部特征的基础上进行检索并融合权重会花费大部分的检索时间。
总结
文章提出的这个方法在检索精度、ANMRR等指标上都非常具有竞争力。如果要在这个框架的基础上作进一步的改进的话,我认为有两点还可以改善:
- 前面从PR曲线的分析中可以看出,文章并没有设置环节来严格控制正负样本的hard程度,导致在recall值为0.1之前的precision值低于其他方法。
- 对于特征提取的耗时较长这一点,我认为可以考虑将全局特征和局部特征的提取这两个步骤同时进行,用并行计算的方式来实现,从而缩短一半左右的特征提取时间。














 2572
2572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









