





👉 这是一个或许对你有用的社群
🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料:
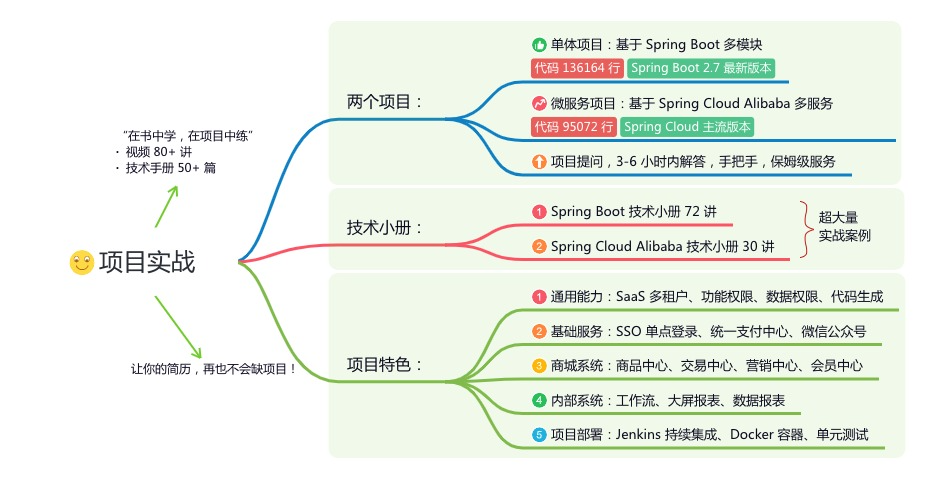
《项目实战(视频)》:从书中学,往事中“练”
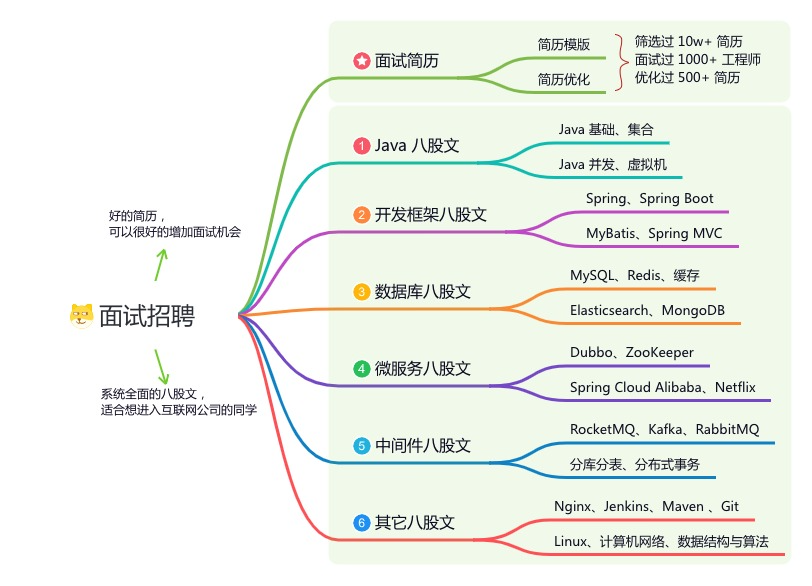
《互联网高频面试题》:面朝简历学习,春暖花开
《架构 x 系统设计》:摧枯拉朽,掌控面试高频场景题
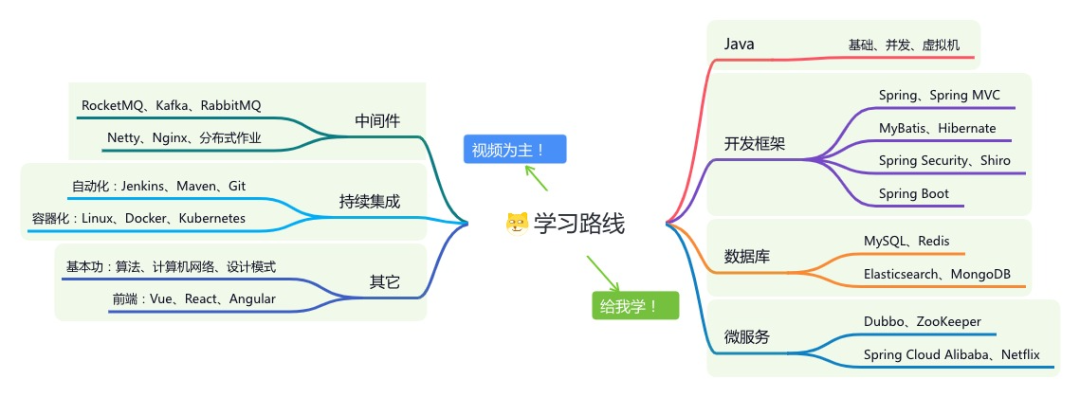
《精进 Java 学习指南》:系统学习,互联网主流技术栈
《必读 Java 源码专栏》:知其然,知其所以然
👉这是一个或许对你有用的开源项目
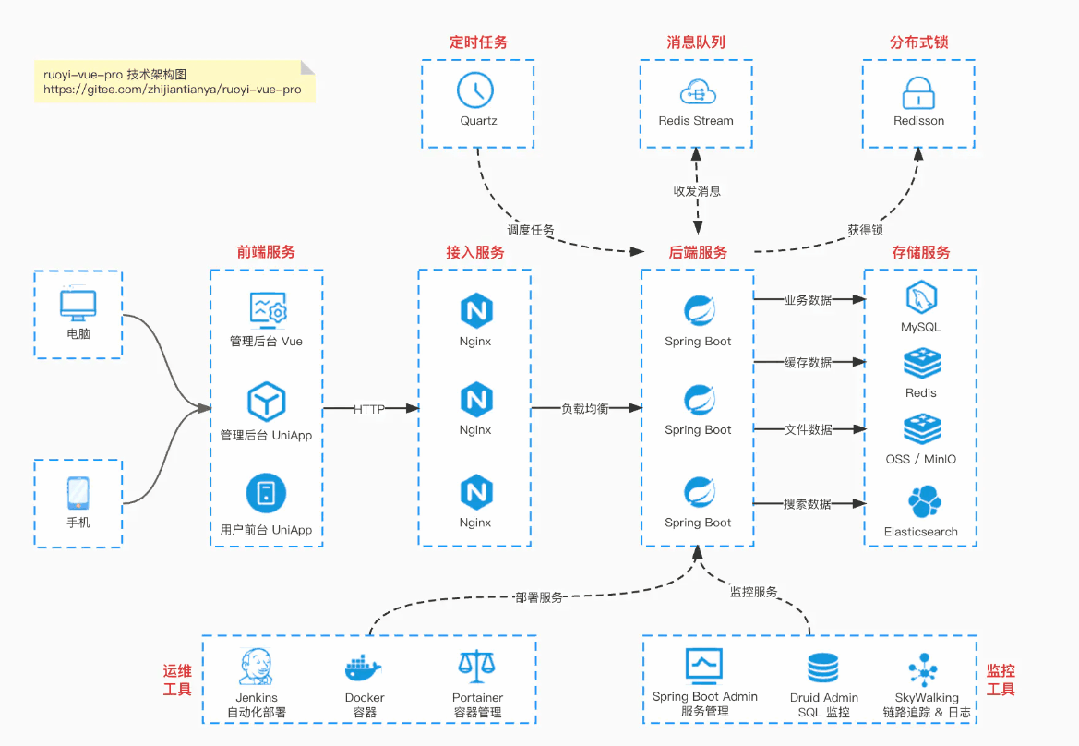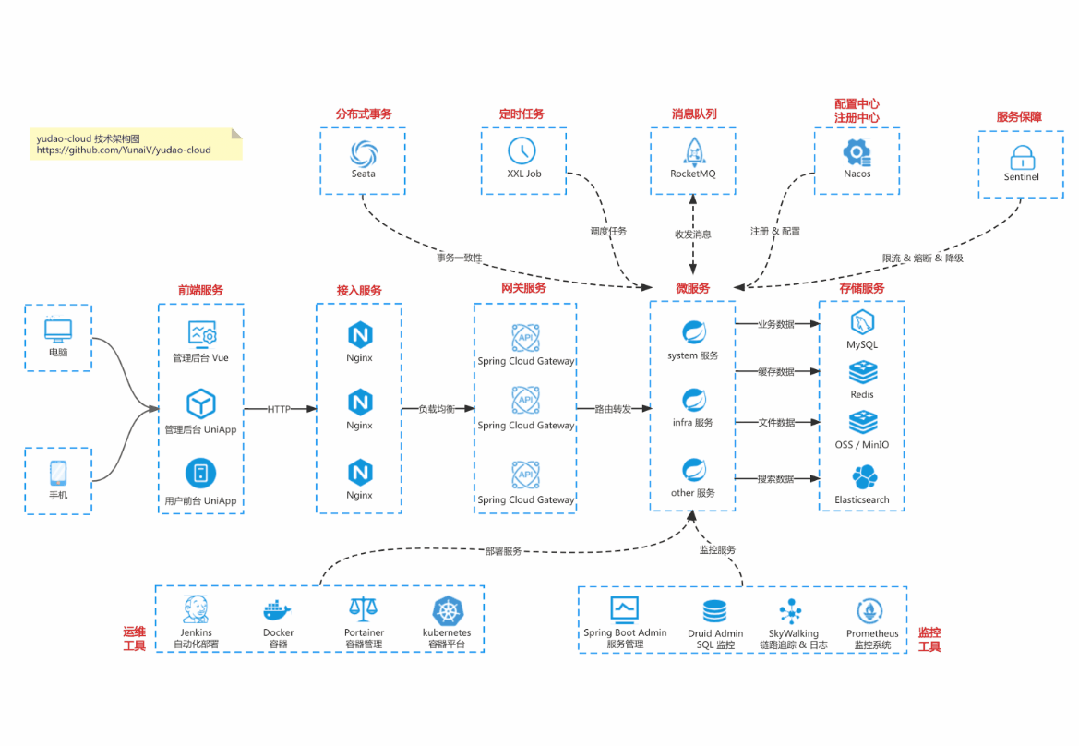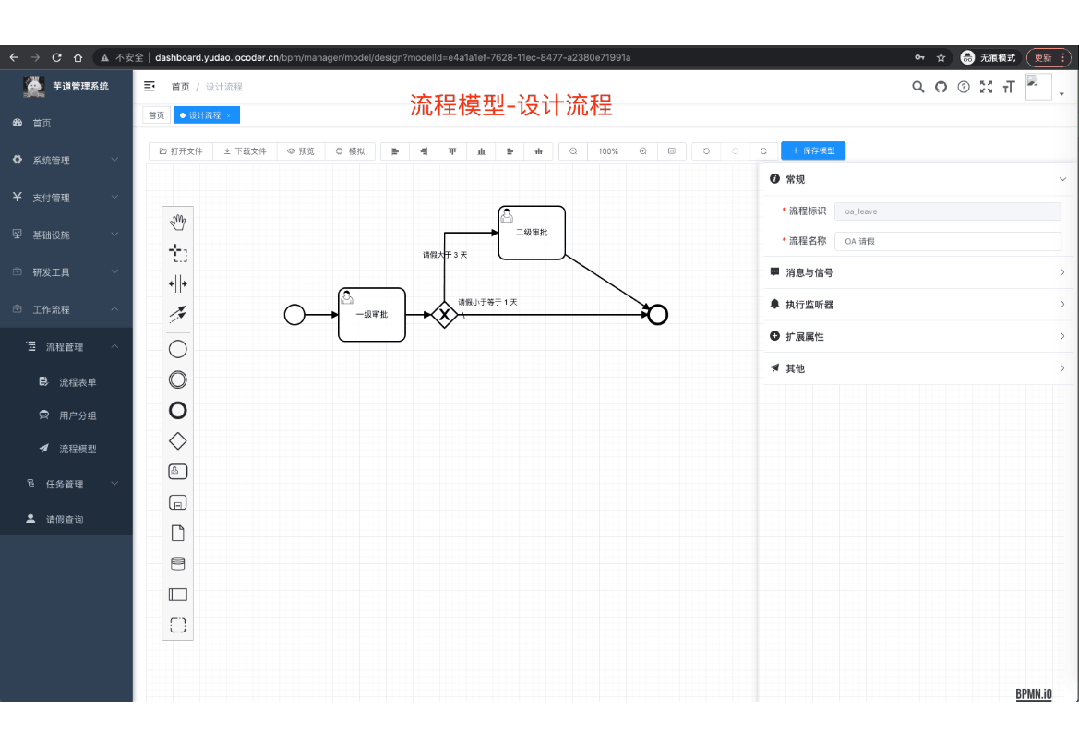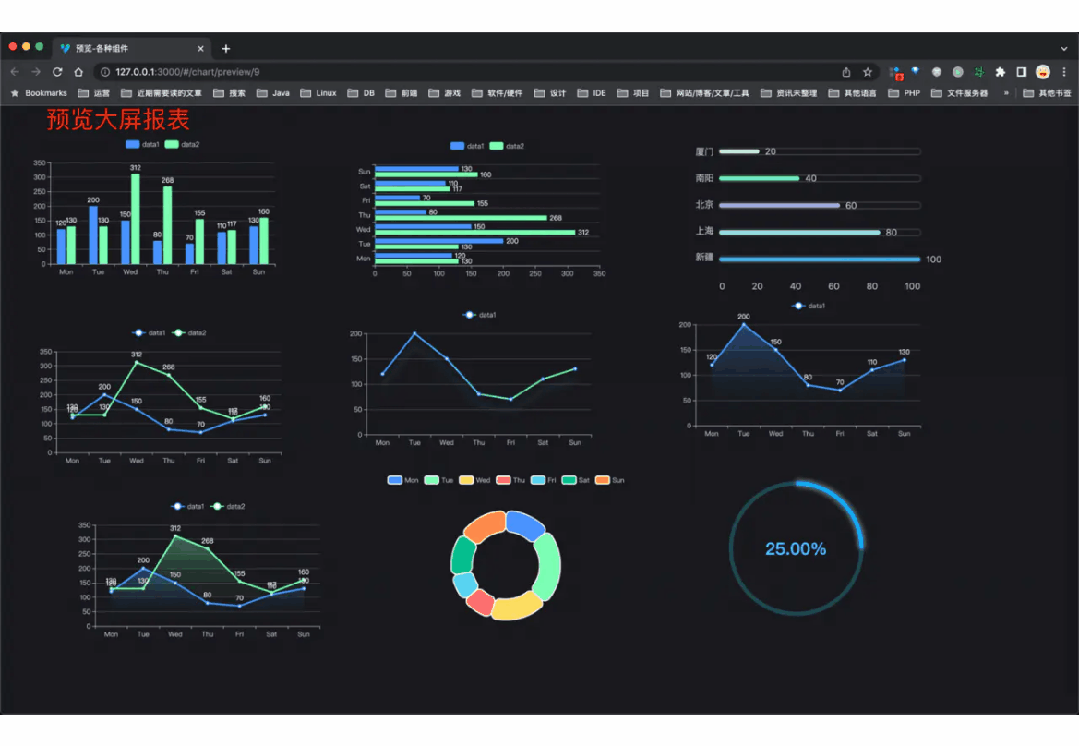
国产 Star 破 10w+ 的开源项目,前端包括管理后台 + 微信小程序,后端支持单体和微服务架构。
功能涵盖 RBAC 权限、SaaS 多租户、数据权限、商城、支付、工作流、大屏报表、微信公众号等等功能:
Boot 仓库:https://gitee.com/zhijiantianya/ruoyi-vue-pro
Cloud 仓库:https://gitee.com/zhijiantianya/yudao-cloud
视频教程:https://doc.iocoder.cn
【国内首批】支持 JDK 21 + SpringBoot 3.2.2、JDK 8 + Spring Boot 2.7.18 双版本
来源:www.linkinstars.com
/post/dbe65928.html
什么是惊群效应?
第一次听到的这个名词的时候觉得很是有趣,不知道是个什么意思,总觉得又是奇怪的中文翻译导致的。
复杂的说(来源于网络)TLDR;
惊群效应(
thundering herd)是指多进程(多线程)在同时阻塞等待同一个事件的时候(休眠状态),如果等待的这个事件发生,那么他就会唤醒等待的所有进程(或者线程),但是最终却只能有一个进程(线程)获得这个时间的“控制权”,对该事件进行处理,而其他进程(线程)获取“控制权”失败,只能重新进入休眠状态,这种现象和性能浪费就叫做惊群效应。
简单的讲(我的大白话)
有一道雷打下来,把很多人都吵醒了,但只有其中一个人去收衣服了。也就是:有一个请求过来了,把很多进程都唤醒了,但只有其中一个能最终处理。
原因&问题
说起来其实也简单,多数时候为了提高应用的请求处理能力,会使用多进程(多线程)去监听请求,当请求来时,因为都有能力处理,所以就都被唤醒了。
而问题就是,最终还是只能有一个进程能来处理。当请求多了,不停地唤醒、休眠、唤醒、休眠,做了很多的无用功,上下文切换又累,对吧。那怎么解决这个问题呢?下面就是今天要看的重点,我们看看 nginx 是如何解决这个问题的。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
Nginx 架构
第一点我们需要了解 nginx 大致的架构是怎么样的。nginx 将进程分为 master 和 worker 两类,非常常见的一种 M-S 策略,也就是 master 负责统筹管理 worker,当然它也负责如:启动、读取配置文件,监听处理各种信号等工作。
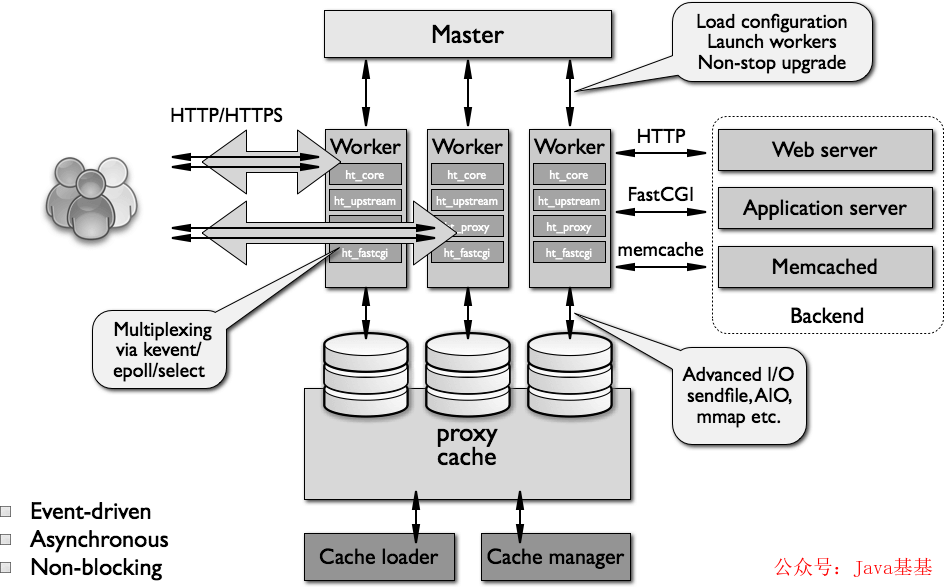
但是,第一个要注意的问题就出现了,master 的工作有且只有这些,对于请求来说它是不管的,就如同图中所示,请求是直接被 worker 处理的。如此一来,请求应该被哪个 worker 处理呢?worker 内部又是如何处理请求的呢?
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
nginx 使用 epoll
接下来我们就要知道 nginx 是如何使用 epoll 来处理请求的。下面可能会涉及到一些源码的内容,但不用担心,你不需要全部理解,只需要知道它们的作用就可以了。顺便我会简单描述一下我是如何去找到这些源码的位置的。
master 的工作
其实 master 并不是毫无作为,至少端口是它来占的。
ngx_open_listening_sockets(ngx_cycle_t *cycle)
{
.....
for (i = 0; i < cycle->listening.nelts; i++) {
.....
if (bind(s, ls[i].sockaddr, ls[i].socklen) == -1) {
if (listen(s, ls[i].backlog) == -1) {
}那么,根据我们 nginx.conf 的配置文件,看需要监听哪个端口,于是就去 bind 的了,这里没问题。
【发现源码】这里我是直接在代码里面搜 bind 方法去找的,因为我知道,不管你怎么样,你总是要绑定端口的
然后是创建 worker 的,虽不起眼,但很关键。
ngx_spawn_process(ngx_cycle_t *cycle, ngx_spawn_proc_pt proc, void *data,
char *name, ngx_int_t respawn)
{
....
pid = fork();【发现源码】这里我直接搜 fork,整个项目里面需要 fork 的情况只有两个地方,很快就找到了 worker
由于是 fork 创建的,也就是复制了一份 task_struct 结构。所以 master 的几乎全部它都有。
worker 的工作
nginx 有一个分模块的思想,它将不同功能分成了不同的模块,而 epoll 自然就是在 ngx_epoll_module.c 中了
ngx_epoll_init(ngx_cycle_t *cycle, ngx_msec_t timer)
{
ngx_epoll_conf_t *epcf;
epcf = ngx_event_get_conf(cycle->conf_ctx, ngx_epoll_module);
if (ep == -1) {
ep = epoll_create(cycle->connection_n / 2);其他不重要,就连 epoll_ctl 和 epoll_wait 也不重要了,这里你需要知道的就是,从调用链路来看,是 worker 创建的 epoll 对象,也就是每个 worker 都有自己的 epoll 对象,而监听的sokcet 是一样的!
【发现源码】这里更加直接,搜索
epoll_create肯定就能找到
问题的关键
此时问题的关键基本就能了解了,每个 worker 都有处理能力,请求来了此时应该唤醒谁呢?讲道理那不是所有 epoll 都会有事件,所有 worker 都 accept 请求?显然这样是不行的。那么 nginx 是如何解决的呢?
如何解决
解决方式一共有三种,下面我们一个个来看:
accept_mutex(应用层的解决方案)EPOLLEXCLUSIVE(内核层的解决方案)SO_REUSEPORT(内核层的解决方案)
accept_mutex
看到 mutex 可能你就知道了,锁嘛!这也是对于高并发处理的 ”基操“ 遇事不决加锁,没错,加锁肯定能解决问题。
https://github.com/nginx/nginx/blob/b489ba83e9be446923facfe1a2fe392be3095d1f/src/event/ngx_event_accept.c#L328
具体代码就不展示了,其中细节很多,但本质很容易理解,就是当请求来了,谁拿到了这个锁,谁就去处理。没拿到的就不管了。锁的问题很直接,除了慢没啥不好的,但至少很公平。
EPOLLEXCLUSIVE
EPOLLEXCLUSIVE 是 2016 年 4.5+ 内核新添加的一个 epoll 的标识。它降低了多个进程/线程通过 epoll_ctl 添加共享 fd 引发的惊群概率,使得一个事件发生时,只唤醒一个正在 epoll_wait 阻塞等待唤醒的进程(而不是全部唤醒)。
关键是:每次内核只唤醒一个睡眠的进程处理资源
但,这个方案不是完美的解决了,它仅是降低了概率哦。为什么这样说呢?相比于原来全部唤醒,那肯定是好了不少,降低了冲突。但由于本质来说 socket 是共享的,当前进程处理完成的时间不确定,在后面被唤醒的进程可能会发现当前的 socket 已经被之前唤醒的进程处理掉了。
SO_REUSEPORT
nginx 在 1.9.1 版本加入了这个功能
https://www.nginx.com/blog/socket-sharding-nginx-release-1-9-1/
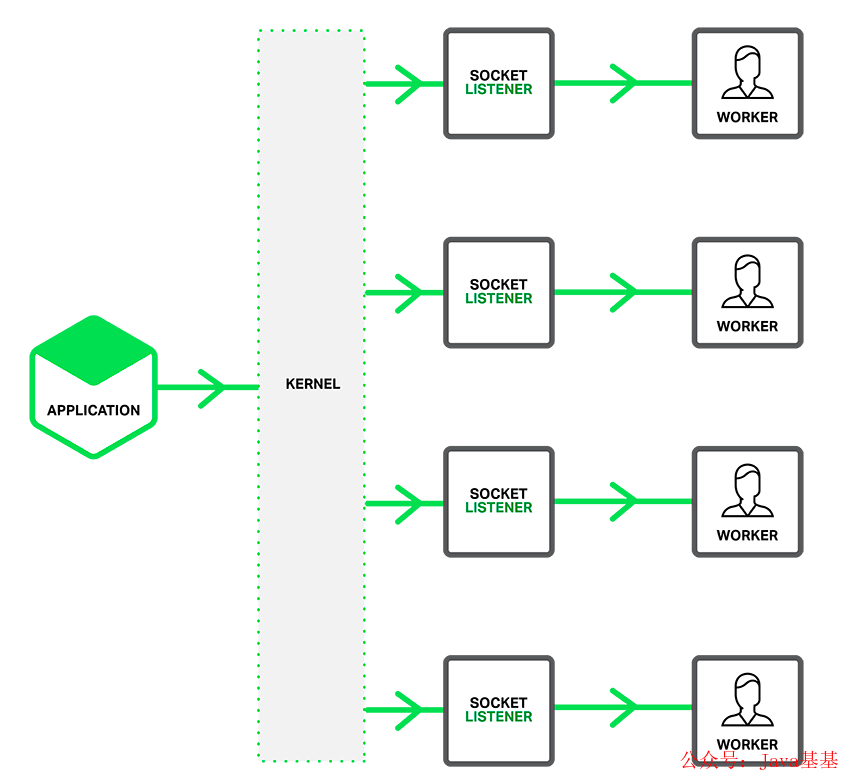
其本质是利用了 Linux 的 reuseport 的特性,使用 reuseport 内核允许多个进程 listening socket 到同一个端口上,而从内核层面做了负载均衡,每次唤醒其中一个进程。
反应到 nginx 上就是,每个 worker 进程都创建独立的 listening socket,监听相同的端口,accept 时只有一个进程会获得连接。效果就和下图所示一样。
而使用方式则是:
http {
server {
listen 80 reuseport;
server_name localhost;
# ...
}
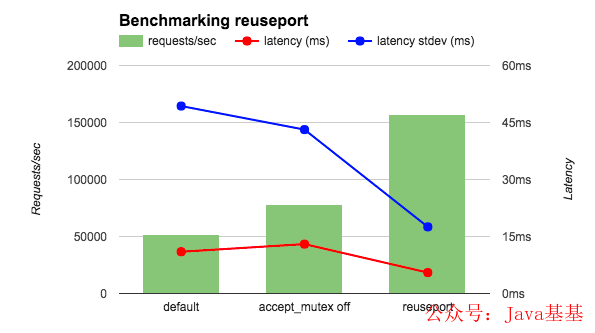
}从官方的测试情况来看确实是厉害
当然,正所谓:完事无绝对,技术无银弹。这个方案的问题在于内核是不知道你忙还是不忙的。只会无脑的丢给你。与之前的抢锁对比,抢锁的进程一定是不忙的,现在手上的工作都已经忙不过来了,没机会去抢锁了;而这个方案可能导致,如果当前进程忙不过来了,还是会只要根据 reuseport 的负载规则轮到你了就会发送给你,所以会导致有的请求被前面慢的请求卡住了。
总结
本文,从了解什么 ”惊群效应“ 到 nginx 架构和 epoll 处理的原理,最终分析三种不同的处理 “惊群效应” 的方案。分析到这里,我想你应该明白其实 nginx 这个多队列服务模型是所存在的一些问题,只不过绝大多数场景已经完完全全够用了。
欢迎加入我的知识星球,全面提升技术能力。
👉 加入方式,“长按”或“扫描”下方二维码噢:

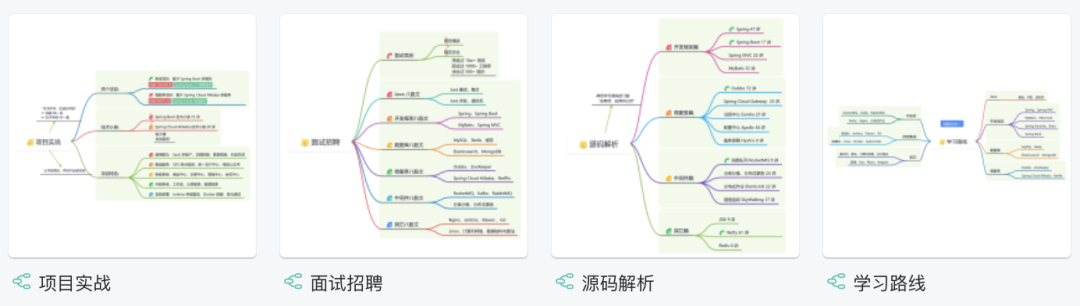
星球的内容包括:项目实战、面试招聘、源码解析、学习路线。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)














 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









