









服务器系统为CentOS7
集群环境准备
1、关闭防火墙
关闭防火墙
systemctl stop firewalld.service
查看防火墙状态
systemctl status firewalld.service
禁止firewall开机启动
systemctl disable firewalld.service
2、关闭selinux
vim /etc/selinux/config
SELINUX修改为disabled
3、更改主机名
hostnamectl set-hostname cdh01
参考:https://blog.51cto.com/qiangsh/1561160
4、主机名与IP地址的映射
vim /etc/hosts
192.168.1.183 cdh01
192.168.1.184 cdh02
192.168.1.185 cdh03
5、免密码登录
(1)所有机器执行ssh-keygen -t rsa,一直回车即可生成密钥;
(2)将所有机器的密钥拷贝到一台:ssh-copy-id -i cdh01得到认证文件authorized_keys
(3)复制第一台机器的认证文件到其他机器
scp /root/.ssh/authorized_keys cdh02:$PWD
6、保证所有机器的时间同步
ntpdate 0.asia.pool.ntp.org
7、确保服务器有Java环境

Hadoop部署
1、Hadoop部署包下载:
http://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/
2、部署包上传并解压:
3、修改配置文件:
(1)修改core-site.xml文件
<configuration>
<!-- hadoop默认访问nameNode元数据的路径 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cdh02:8020</value>
</property>
<!-- hadoop的临时文件夹位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/bigdata/hadoop-3.2.0/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
(2)修改hadoop-env.sh文件
export JAVA_HOME=/usr/java/default
(3)修改hdfs-site.xml文件
<configuration>
<!-- NameNode存储元数据信息的路径,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<!-- 集群动态上下线
<property>
<name>dfs.hosts</name>
<value>/home/bigdata/hadoop-3.2.0/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/home/bigdata/hadoop-3.2.0/etc/hadoop/deny_host</value>
</property>
-->
<!-- nameNode的访问路径和端口号 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>cdh02:50090</value>
</property>
<!-- nameNode的外部访问路径和端口号 -->
<property>
<name>dfs.namenode.http-address</name>
<value>cdh02:50070</value>
</property>
<!-- 配置nameNode的存放位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/bigdata/hadoop-3.2.0/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定义dataNode数据存储的节点位置,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/bigdata/hadoop-3.2.0/hadoopDatas/datanodeDatas</value>
</property>
<!-- edits的存储位置 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///home/bigdata/hadoop-3.2.0/hadoopDatas/dfs/nn/edits</value>
</property>
<!-- 元数据信息检查点的存储位置 -->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///home/bigdata/hadoop-3.2.0/hadoopDatas/dfs/snn/name</value>
</property>
<!-- edits的检查点的存储位置 -->
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///home/bigdata/hadoop-3.2.0/hadoopDatas/dfs/nn/snn/edits</value>
</property>
<!-- 副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- hdfs的权限 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- hdfs存储的block大小, 128M -->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
(4)修改mapred-site.xml文件
<configuration>
<!-- 指定MapReduce运行在yarn集群上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 开启MapReduce的小任务模式 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 配置jobhistory的访问路径和端口号, jobhistory是执行完成的任务日志 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>cdh02:10020</value>
</property>
<!-- 配置jobhistory的浏览器访问路径和端口号 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cdh02:19888</value>
</property>
</configuration>
(5)修改workers文件
cdh01
cdh02
cdh03
(6)修改yarn-site.xml文件
<configuration>
<!-- 配置resourcemanager运行在哪台机器上 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>cdh02</value>
</property>
<!-- 配置nodemanager上运行的附属服务为shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启聚合日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 配置聚合日志的保持时长 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://cdh02:19888/jobhistory/logs</value>
</property>
<!--可使用的物理内存-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>61440</value>
</property>
<!--RM上每个container请求的最小内存-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!--RM上每个container请求的最大内存-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>20480</value>
</property>
<!--可使用的VCore-->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>31</value>
</property>
</configuration>
4、 创建数据存储的文件夹
mkdir -p /home/bigdata/hadoop-3.2.0/hadoopDatas/tempDatas
mkdir -p /home/bigdata/hadoop-3.2.0/hadoopDatas/namenodeDatas
mkdir -p /home/bigdata/hadoop-3.2.0/hadoopDatas/datanodeDatas
mkdir -p /home/bigdata/hadoop-3.2.0/hadoopDatas/dfs/nn/edits
mkdir -p /home/bigdata/hadoop-3.2.0/hadoopDatas/dfs/snn/name
mkdir -p /home/bigdata/hadoop-3.2.0/hadoopDatas/dfs/nn/snn/edits
tempDatas 是hadoop临时文件存放位置
namenodeDatas 是namenode元数据存储位置
datanodeDatas 是datanode数据存储位置
dfs/nn/edits 是edites存储位置
dfs/snn/name 是元数据检查点的存储位置
dfs/nn/snn/edits 是edites检查点的存储位置
5、发送安装包到其他机器
scp -r hadoop-3.2.0/ node02:$PWD
scp -r hadoop-3.2.0/ node03:$PWD
6、配置hadoop的环境变量
所有机器都要进行配置hadoop的环境变量
vim /etc/profile
export HADOOP_HOME=/home/bigdata/hadoop-3.2.0
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
7、启动集群
(1)首次启动HDFS时, 必须对其进行格式化操作
hdfs namenode -format 或者 hadoop namenode -format
(2)脚本一键启动:
sbin/start-all.sh
sbin/mr-jobhistory-daemon.sh start historyserver
如启动报错:Attempting to operate on hdfs namenode as root
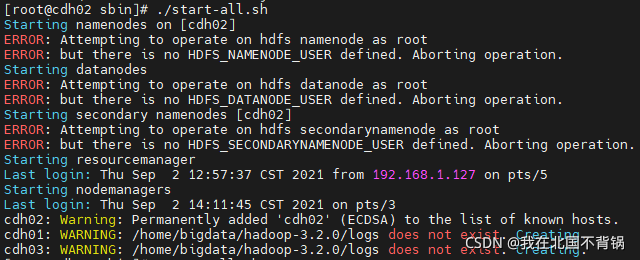
参考:https://blog.csdn.net/weixin_44455388/article/details/120062749
(3)脚本一键停止:
sbin/stop-all.sh
8、浏览器访问
192.168.xxx.xxx:50070 访问hdfs集群
192.168.xxx.xxx:8088 访问yarn集群
192.168.xxx.xxx:19888 访问jobhistory
Spark on yarn设置
如果我们的spark程序是运行在yarn上面的话,那么我们就不需要spark 的standAlone的集群了,我们只需要找任意一台机器配置我们的spark的客户端提交任务到yarn集群上面去即可
1、下载spark部署包:
http://archive.apache.org/dist/spark/spark-3.1.2/
2、上传部署包并解压:
3、修改配置文件:
(1)修改spark-env.sh文件:
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
如没有配置HADOOP_HOME需要写全路径。
(2)yarn的capacity-scheduler.xml文件修改配置保证资源调度按照CPU + 内存模式:
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<!-- <value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value> -->
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>
(3)修改spakr-defaults.conf文件(可选):
spark.eventLog.dir=hdfs:///user/spark/applicationHistory
spark.eventLog.enabled=true
spark.yarn.historyServer.address=http://master:18018
4、测试
./bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master yarn
--deploy-mode cluster
--driver-memory 1g
--num-executors 3
--executor-memory 1g
--executor-cores 1
examples/jars/spark-examples_2.12-3.1.2.jar














 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









