







接着上一篇《Spark Streaming快速入门系列(7)》,这算是Spark的终结篇了,从Spark的入门到现在的Structured Streaming,相信很多人学完之后,应该对Spark摸索的差不多了,Spark是一个很重要的技术点,希望我的文章能给大家带来帮助。

第一章 Structured Streaming曲折发展史
1.1. Spark Streaming
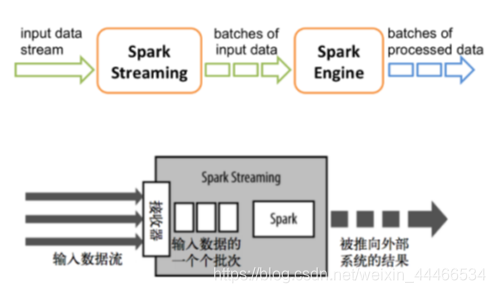
Spark Streaming针对实时数据流,提供了一套可扩展、高吞吐、可容错的流式计算模型。Spark Streaming接收实时数据源的数据,切分成很多小的batches,然后被Spark Engine执行,产出同样由很多小的batchs组成的结果流。本质上,这是一种micro-batch(微批处理)的方式处理
不足在于处理延时较高(无法优化到秒以下的数量级), 无法支持基于event_time的时间窗口做聚合逻辑。
1.2. Structured Streaming
1.2.1. 介绍
●官网
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
●简介
spark在2.0版本中发布了新的流计算的API,Structured Streaming/结构化流。
Structured Streaming是一个基于Spark SQL引擎的可扩展、容错的流处理引擎。统一了流、批的编程模型,可以使用静态数据批处理一样的方式来编写流式计算操作。并且支持基于event_time的时间窗口的处理逻辑。
随着数据不断地到达,Spark 引擎会以一种增量的方式来执行这些操作,并且持续更新结算结果。可以使用Scala、Java、Python或R中的DataSet/DataFrame API来表示流聚合、事件时间窗口、流到批连接等。此外,Structured Streaming会通过checkpoint和预写日志等机制来实现Exactly-Once语义。
简单来说,对于开发人员来说,根本不用去考虑是流式计算,还是批处理,只要使用同样的方式来编写计算操作即可,Structured Streaming提供了快速、可扩展、容错、端到端的一次性流处理,而用户无需考虑更多细节
默认情况下,结构化流式查询使用微批处理引擎进行处理,该引擎将数据流作为一系列小批处理作业进行处理,从而实现端到端的延迟,最短可达100毫秒,并且完全可以保证一次容错。自Spark 2.3以来,引入了一种新的低延迟处理模式,称为连续处理,它可以在至少一次保证的情况下实现低至1毫秒的端到端延迟。也就是类似于 Flink 那样的实时流,而不是小批量处理。实际开发可以根据应用程序要求选择处理模式,但是连续处理在使用的时候仍然有很多限制,目前大部分情况还是应该采用小批量模式。
1.2.2. API
1.Spark Streaming 时代 -DStream-RDD
Spark Streaming 采用的数据抽象是DStream,而本质上就是时间上连续的RDD,
对数据流的操作就是针对RDD的操作

2.Structured Streaming 时代 - DataSet/DataFrame -RDD
Structured Streaming是Spark2.0新增的可扩展和高容错性的实时计算框架,它构建于Spark SQL引擎,把流式计算也统一到DataFrame/Dataset里去了。
Structured Streaming 相比于 Spark Streaming 的进步就类似于 Dataset 相比于 RDD 的进步

1.2.3. 主要优势
1.简洁的模型。Structured Streaming 的模型很简洁,易于理解。用户可以直接把一个流想象成是无限增长的表格。
2.一致的 API。由于和 Spark SQL 共用大部分 API,对 Spaprk SQL 熟悉的用户很容易上手,代码也十分简洁。font color=red>同时批处理和流处理程序还可以共用代码,不需要开发两套不同的代码,显著提高了开发效率。
3.卓越的性能。Structured Streaming 在与 Spark SQL 共用 API 的同时,也直接使用了 Spark SQL 的 Catalyst 优化器和 Tungsten,数据处理性能十分出色。此外,Structured Streaming 还可以直接从未来 Spark SQL 的各种性能优化中受益。
4.多语言支持。Structured Streaming 直接支持目前 Spark SQL 支持的语言,包括 Scala,Java,Python,R 和 SQL。用户可以选择自己喜欢的语言进行开发。
1.2.4. 编程模型
●编程模型概述
一个流的数据源从逻辑上来说就是一个不断增长的动态表格,随着时间的推移,新数据被持续不断地添加到表格的末尾。
对动态数据源进行实时查询,就是对当前的表格内容执行一次 SQL 查询。
数据查询,用户通过触发器(Trigger)设定时间(毫秒级)。也可以设定执行周期。
一个流的输出有多种模式,既可以是基于整个输入执行查询后的完整结果,也可以选择只输出与上次查询相比的差异,或者就是简单地追加最新的结果。
这个模型对于熟悉 SQL 的用户来说很容易掌握,对流的查询跟查询一个表格几乎完全一样,十分简洁,易于理解
●核心思想

Structured Streaming最核心的思想就是将实时到达的数据不断追加到unbound table无界表,到达流的每个数据项(RDD)就像是表中的一个新行被附加到无边界的表中.这样用户就可以用静态结构化数据的批处理查询方式进行流计算,如可以使用SQL对到来的每一行数据进行实时查询处理;(SparkSQL+SparkStreaming=StructuredStreaming)
●应用场景
Structured Streaming将数据源映射为类似于关系数据库中的表,然后将经过计算得到的结果映射为另一张表,完全以结构化的方式去操作流式数据,这种编程模型非常有利于处理分析结构化的实时数据;
== ●WordCount图解==

如图所示,
第一行表示从socket不断接收数据,
第二行可以看成是之前提到的“unbound table",
第三行为最终的wordCounts是结果集。
当有新的数据到达时,Spark会执行“增量"查询,并更新结果集;
该示例设置为Complete Mode(输出所有数据),因此每次都将所有数据输出到控制台;
1.在第1秒时,此时到达的数据为"cat dog"和"dog dog",因此我们可以得到第1秒时的结果集cat=1 dog=3,并输出到控制台;
2.当第2秒时,到达的数据为"owl cat",此时"unbound table"增加了一行数据"owl cat",执行word count查询并更新结果集,可得第2秒时的结果集为cat=2 dog=3 owl=1,并输出到控制台;
3.当第3秒时,到达的数据为"dog"和"owl",此时"unbound table"增加两行数据"dog"和"owl",执行word count查询并更新结果集,可得第3秒时的结果集为cat=2 dog=4 owl=2;
这种模型跟其他很多流式计算引擎都不同。大多数流式计算引擎都需要开发人员自己来维护新数据与历史数据的整合并进行聚合操作。
然后我们就需要自己去考虑和实现容错机制、数据一致性的语义等。
然而在structured streaming的这种模式下,spark会负责将新到达的数据与历史数据进行整合,并完成正确的计算操作,同时更新result table,不需要我们去考虑这些事情。
第二章 Structured Streaming实战
2.1. 创建Source
spark 2.0中初步提供了一些内置的source支持。
Socket source (for testing): 从socket连接中读取文本内容。
File source: 以数据流的方式读取一个目录中的文件。支持text、csv、json、parquet等文件类型。
Kafka source: 从Kafka中拉取数据,与0.10或以上的版本兼容,后面单独整合Kafka
2.1.1. 读取Socket数据
●准备工作
nc -lk 9999
hadoop spark sqoop hadoop spark hive hadoop
●代码演示
package cn.itcast.structedstreaming
import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object WordCount {
def main(args: Array[String]): Unit = {
//1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.接收数据
val dataDF: DataFrame = spark.readStream
.option("host", "node01")
.option("port", 9999)
.format("socket")
.load()
//3.处理数据
import spark.implicits._
val dataDS: Dataset[String] = dataDF.as[String]
val wordDS: Dataset[String] = dataDS.flatMap(_.split(" "))
val result: Dataset[Row] = wordDS.groupBy("value").count().sort($"count".desc)
//result.show()
//Queries with streaming sources must be executed with writeStream.start();
result.writeStream
.format("console")//往控制台写
.outputMode("complete")//每次将所有的数据写出
.trigger(Trigger.ProcessingTime(0))//触发时间间隔,0表示尽可能的快
//.option("checkpointLocation","./ckp")//设置checkpoint目录,socket不支持数据恢复,所以第二次启动会报错,需要注掉
.start()//开启
.awaitTermination()//等待停止
}
}
2.1.2. 读取目录下文本数据
spark应用可以监听某一个目录,而web服务在这个目录上实时产生日志文件,这样对于spark应用来说,日志文件就是实时数据
Structured Streaming支持的文件类型有text,csv,json,parquet
●准备工作
在people.json文件输入如下数据:
{"name":"json","age":23,"hobby":"running"}
{"name":"charles","age":32,"hobby":"basketball"}
{"name":"tom","age":28,"hobby":"football"}
{"name":"lili","age":24,"hobby":"running"}
{"name":"bob","age":20,"hobby":"swimming"}
注意:文件必须是被移动到目录中的,且文件名不能有特殊字符
●需求
使用Structured Streaming统计年龄小于25岁的人群的爱好排行榜
●代码演示
package cn.itcast.structedstreaming
import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* {"name":"json","age":23,"hobby":"running"}
* {"name":"charles","age":32,"hobby":"basketball"}
* {"name":"tom","age":28,"hobby":"football"}
* {"name":"lili","age":24,"hobby":"running"}
* {"name":"bob","age":20,"hobby":"swimming"}
* 统计年龄小于25岁的人群的爱好排行榜
*/
object WordCount2 {
def main(args: Array[String]): Unit = {
//1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet
val spark: SparkSession =
SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
val Schema: StructType = new StructType()
.add("name","string")
.add("age","integer")
.add("hobby","string")
//2.接收数据
import spark.implicits._
// Schema must be specified when creating a streaming source DataFrame.
val dataDF: DataFrame =
spark.readStream.schema(Schema).json("D:\\data\\spark\\data")
//3.处理数据
val result: Dataset[Row] =
dataDF.filter($"age" < 25).groupBy("hobby").count().sort($"count".desc)
//4.输出结果
result.writeStream
.format("console")
.outputMode("complete")
.trigger(Trigger.ProcessingTime(0))
.start()
.awaitTermination()
}
}
2.2. 计算操作
获得到Source之后的基本数据处理方式和之前学习的DataFrame、DataSet一致,不再赘述
2.3. 输出
计算结果可以选择输出到多种设备并进行如下设定
1.output mode:以哪种方式将result table的数据写入sink
2.format/output sink的一些细节:数据格式、位置等。
3.query name:指定查询的标识。类似tempview的名字
4.trigger interval:触发间隔,如果不指定,默认会尽可能快速地处理数据
5.checkpoint地址:一般是hdfs上的目录。注意:Socket不支持数据恢复,如果设置了,第二次启动会报错 ,Kafka支持
2.3.1. output mode

每当结果表更新时,我们都希望将更改后的结果行写入外部接收器。
这里有三种输出模型:
1.Append mode:输出新增的行,默认模式。每次更新结果集时,只将新添加到结果集的结果行输出到接收器。仅支持添加到结果表中的行永远不会更改的查询。因此,此模式保证每行仅输出一次。例如,仅查询select,where,map,flatMap,filter,join等会支持追加模式。不支持聚合
2.Complete mode: 所有内容都输出,每次触发后,整个结果表将输出到接收器。聚合查询支持此功能。仅适用于包含聚合操作的查询。
3.Update mode: 输出更新的行,每次更新结果集时,仅将被更新的结果行输出到接收器(自Spark 2.1.1起可用),不支持排序
2.3.2. output sink

●使用说明
File sink 输出到路径
支持parquet文件,以及append模式
writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()
Kafka sink 输出到kafka内的一到多个topic
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()
Foreach sink 对输出中的记录运行任意计算。
writeStream
.foreach(...)
.start()
Console sink (for debugging) 当有触发器时,将输出打印到控制台。
writeStream
.format("console")
.start()
Memory sink (for debugging) - 输出作为内存表存储在内存中.
writeStream
.format("memory")
.queryName("tableName")
.start()
●官网示例代码
// ========== DF with no aggregations ==========
val noAggDF = deviceDataDf.select("device").where("signal > 10")
// Print new data to console
noAggDF.writeStream.format("console").start()
// Write new data to Parquet files
noAggDF.writeStream.format("parquet").option("checkpointLocation",
"path/to/checkpoint/dir").option("path", "path/to/destination/dir").start()
// ========== DF with aggregation ==========
val aggDF = df.groupBy("device").count()
// Print updated aggregations to console
aggDF.writeStream.outputMode("complete").format("console").start()
// Have all the aggregates in an in-memory table
aggDF.writeStream.queryName("aggregates").outputMode("complete").format("memory").start()
spark.sql("select * from aggregates").show()
// interactively query in-memory table
第三章 StructuredStreaming与其他技术整合
3.1. 整合Kafka
3.1.1. 官网介绍
http://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html

●Creating a Kafka Source for Streaming Queries
// Subscribe to 1 topic
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to multiple topics(多个topic)
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to a pattern(订阅通配符topic)
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
●Creating a Kafka Source for Batch Queries(kafka批处理查询)
// Subscribe to 1 topic
//defaults to the earliest and latest offsets(默认为最早和最新偏移)
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to multiple topics, (多个topic)
//specifying explicit Kafka offsets(指定明确的偏移量)
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.option("startingOffsets", """{"topic1":{"0":23,"1":-2},"topic2":{"0":-2}}""")
.option("endingOffsets", """{"topic1":{"0":50,"1":-1},"topic2":{"0":-1}}""")
.load()df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to a pattern, (订阅通配符topic)at the earliest and latest offsets
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
●注意:读取后的数据的Schema是固定的,包含的列如下:

●注意:下面的参数是不能被设置的,否则kafka会抛出异常:
group.id:kafka的source会在每次query的时候自定创建唯一的group id
auto.offset.reset :为了避免每次手动设置startingoffsets的值,structured streaming在内部消费时会自动管理offset。这样就能保证订阅动态的topic时不会丢失数据。startingOffsets在流处理时,只会作用于第一次启动时,之后的处理都会自动的读取保存的offset。
key.deserializer,value.deserializer,key.serializer,value.serializer 序列化与反序列化,都是ByteArraySerializer
enable.auto.commit:Kafka源不支持提交任何偏移量

3.1.2. 整合环境准备
●启动kafka
/export/servers/kafka/bin/kafka-server-start.sh -daemon
/export/servers/kafka/config/server.properties
●向topic中生产数据
/export/servers/kafka/bin/kafka-console-producer.sh --broker-list node01:9092 --topic spark_kafka
代码实现
package cn.itcast.structedstreaming
import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object KafkaStructuredStreamingDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession =
SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
//2.连接Kafka消费数据
val dataDF: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node01:9092")
.option("subscribe", "spark_kafka")
.load()
//3.处理数据
//注意:StructuredStreaming整合Kafka获取到的数据都是字节类型,所以需要按照官网要求,
//转成自己的实际类型
val dataDS: Dataset[String] = dataDF.selectExpr("CAST(value AS STRING)").as[String]
val wordDS: Dataset[String] = dataDS.flatMap(_.split(" "))
val result: Dataset[Row] = wordDS.groupBy("value").count().sort($"count".desc)
result.writeStream
.format("console")
.outputMode("complete")
.trigger(Trigger.ProcessingTime(0))
.option("truncate",false)//超过长度的列不截断显示,即完全显示
.start()
.awaitTermination()
}
}
3.2. 整合MySQL
3.2.1. 简介
●需求
我们开发中经常需要将流的运算结果输出到外部数据库,例如MySQL中,但是比较遗憾Structured Streaming API不支持外部数据库作为接收器
如果将来加入支持的话,它的API将会非常的简单比如:
format(“jdbc”).option(“url”,“jdbc:mysql://…”).start()
但是目前我们只能自己自定义一个JdbcSink,继承ForeachWriter并实现其方法
●参考网站

3.2.2. 代码演示
package cn.itcast.structedstreaming
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.SparkContext
import org.apache.spark.sql._
import org.apache.spark.sql.streaming.Trigger
object JDBCSinkDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession =
SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
//2.连接Kafka消费数据
val dataDF: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node01:9092")
.option("subscribe", "spark_kafka")
.load()
//3.处理数据
//注意:StructuredStreaming整合Kafka获取到的数据都是字节类型,所以需要按照官网要求,转成自己的实际类型
val dataDS: Dataset[String] = dataDF.selectExpr("CAST(value AS STRING)").as[String]
val wordDS: Dataset[String] = dataDS.flatMap(_.split(" "))
val result: Dataset[Row] = wordDS.groupBy("value").count().sort($"count".desc)
val writer = new JDBCSink("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "root")
result.writeStream
.foreach(writer)
.outputMode("complete")
.trigger(Trigger.ProcessingTime(0))
.start()
.awaitTermination()
}
class JDBCSink(url:String,username:String,password:String) extends ForeachWriter[Row] with Serializable{
var connection:Connection = _ //_表示占位符,后面会给变量赋值
var preparedStatement: PreparedStatement = _
//开启连接
override def open(partitionId: Long, version: Long): Boolean = {
connection = DriverManager.getConnection(url, username, password)
true
}
/*
CREATE TABLE `t_word` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(255) NOT NULL,
`count` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `word` (`word`)
) ENGINE=InnoDB AUTO_INCREMENT=26 DEFAULT CHARSET=utf8;
*/
//replace INTO `bigdata`.`t_word` (`id`, `word`, `count`) VALUES (NULL, NULL, NULL);
//处理数据--存到MySQL
override def process(row: Row): Unit = {
val word: String = row.get(0).toString
val count: String = row.get(1).toString
println(word+":"+count)
//REPLACE INTO:表示如果表中没有数据这插入,如果有数据则替换
//注意:REPLACE INTO要求表有主键或唯一索引
val sql = "REPLACE INTO `t_word` (`id`, `word`, `count`) VALUES (NULL, ?, ?);"
preparedStatement = connection.prepareStatement(sql)
preparedStatement.setString(1,word)
preparedStatement.setInt(2,Integer.parseInt(count))
preparedStatement.executeUpdate()
}
//关闭资源
override def close(errorOrNull: Throwable): Unit = {
if (connection != null){
connection.close()
}
if(preparedStatement != null){
preparedStatement.close()
}
}
}
}
Spark到这也就结束了,以后博主会给你们更新在工作中遇到的各种BUG,以及分享给你们一些在工作中的经验。
















 4687
4687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











