




概念
在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
案例
需求
1.需求分析
去除日志中字段长度小于等于11的日志。
2.文件
案例分析
1.需求分析
按照需求设定规则,即可去除日志中字段长度小于等于11的日志。
2.输入数据
3.输出数据
输出文件中每行字段长度都大于11。
4.规则设定
在Map阶段对输入的数据根据规则进行过滤清洗
代码实现
1. 编写LogMapper类
package com.atguigu.mr.log;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
//获取一行
String line = value.toString();
//解析数据
boolean result = parseLog(line,context);
if (!result) {
return;
}
//解析过了,写数据
context.write(value, NullWritable.get());
}
private boolean parseLog(String line, Context context) {
//切割shuju
String[] fields = line.split(" ");
if (fields.length > 11) {
context.getCounter("map","ture").increment(1);
return true;
}else {
context.getCounter("map", "false").increment(1);
return false;
}
}
}
2. 编写LogDriver类
package com.atguigu.mr.log;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogDriver {
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "S:\\centos学习笔记\\input\\webinput", "S:\\centos学习笔记\\output\\weboutput" };
// 1 获取job信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 加载jar包
job.setJarByClass(LogDriver.class);
// 3 关联map
job.setMapperClass(LogMapper.class);
// 4 设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 设置reducetask个数为0
job.setNumReduceTasks(0);
// 5 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 提交
job.waitForCompletion(true);
}
}
结果截图
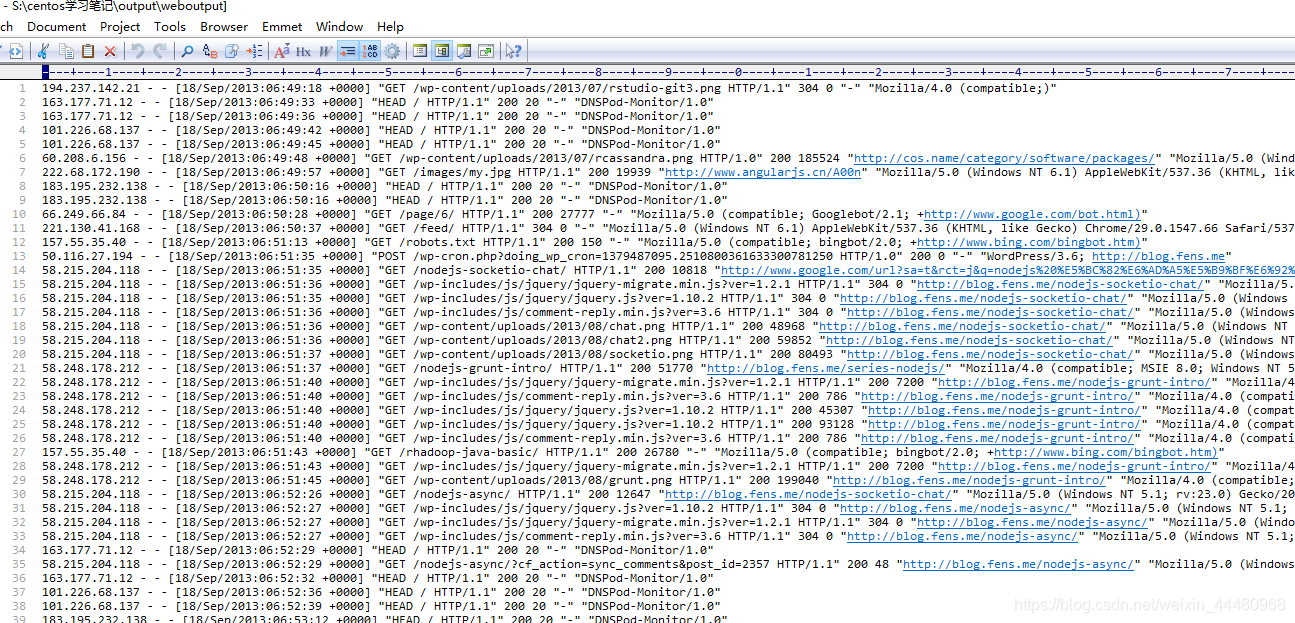
注:内容较多,只截取一部分


















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











