




在大数据分析领域,随着数据量的迅猛增长,如何高效管理和利用数据成为了关键问题。Doris 作为一款强大的分析型数据库,其冷热分离功能为解决这一问题提供了有力的支持。本文将深入探讨 Doris 冷热分离的相关知识,包括其重要性、原理、使用方式、最佳实践以及常见问题解答等,帮助读者全面了解并掌握这一功能。
一、为什么需要冷热分离
随着业务的发展,数据量呈爆发式增长。企业不仅需要存储海量数据,还面临着如何在保证查询性能的同时降低存储成本的挑战。在这种情况下,冷热分离技术应运而生。
在许多业务场景中,数据的访问频率具有明显的时间特征。近期产生的数据通常会被频繁查询和分析,这些数据被称为热数据。而随着时间的推移,数据的访问频率逐渐降低,这些数据则成为冷数据。如果将所有数据都存储在高性能、高成本的存储介质上,无疑会造成资源的浪费。因此,冷热分离的核心目的就是将热数据和冷数据分开存储,热数据存储在高性能的存储介质中以保证查询性能,冷数据则存储在低成本的存储介质中以降低存储成本,从而实现查询性能和存储成本的平衡。
以日志分析场景为例,新产生的日志数据对于实时监控和故障排查至关重要,需要快速查询和分析,属于热数据。而历史日志数据虽然访问频率较低,但出于合规性和偶尔的数据分析需求,仍需要长期保存,这些就是冷数据。通过冷热分离,将近期的日志数据存储在 Doris 的本地存储中,保证实时查询的高性能,而将历史日志数据存储到对象存储等低成本存储介质中,既能满足数据保存需求,又能大幅降低存储成本。
二、Doris 冷热分离原理简介
Doris 的冷热分离功能主要基于存储策略和资源管理来实现。用户可以创建不同的存储资源,如基于对象存储(如 S3 兼容模式、AZURE 模式)或 HDFS 的资源,并通过创建存储策略来指定数据何时以及如何移动到不同的存储资源上。
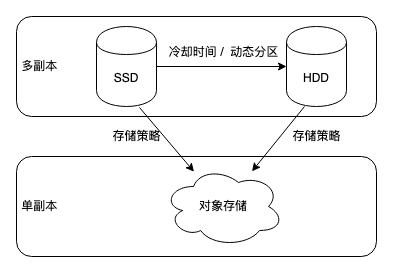
在 Doris 中,每个表或分区都可以绑定一个存储策略。当数据满足存储策略中定义的冷却条件(如达到指定的时间 TTL 或具体的冷却时间点)时,Doris 会自动将数据从本地存储迁移到指定的远程存储资源中,如对象存储。在查询时,Doris 会根据数据的存储位置,自动从相应的存储介质中读取数据。如果查询涉及到冷数据,Doris 会高效地从远程存储中获取数据并进行处理,同时结合本地缓存和优化的查询执行计划,尽量减少查询延迟,确保查询性能。
例如,创建一个存储策略,设置冷却时间为数据导入后的 1 天(即 cooldown_ttl = “1d”),并指定存储资源为一个 S3 兼容的对象存储资源。那么,在数据导入 Doris 一天后,符合条件的数据就会被自动迁移到该对象存储中。
三、使用方式
(一)基于对象存储
- S3 兼容模式:
CREATE RESOURCE "remote_s3"
PROPERTIES
(
"type" = "s3",
"s3.endpoint" = "bj.s3.com",
"s3.region" = "bj",
"s3.access_key" = "bbb",
"s3.secret_key" = "aaaa",
-- 以下为可选属性
"s3.root.path" = "prefix",
"s3.connection.maximum" = "50",
"s3.connection.request.timeout" = "3000",
"s3.connection.timeout" = "1000"
);
在创建 S3 兼容的存储资源时,需要指定关键的属性,如端点(s3.endpoint)、区域(s3.region)、访问密钥(s3.access_key)和秘密密钥(s3.secret_key)。可选属性如根路径(s3.root.path)可以用于在对象存储中指定一个特定的前缀路径来存储数据,连接最大数(s3.connection.maximum)等属性可以优化与对象存储的连接性能。
(1) 关于 path style:
Path style 和 Virtual hosted style:Virtual hosted style 是指将 Bucket 置于 Host Header 的访问方式。基于安全考虑,OSS 仅支持 virtual hosted 访问方式。所以在 S3 迁移至 OSS 后,客户端应用需要进行相应设置。部分 S3 工具默认使用 Path style,也需要进行相应配置,否则可能导致 OSS 报错,并禁止访问。可参考阿里云文档进行详细配置。
(2) AZURE 这类和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











