







ES6学习笔记
ES6
1. 概览
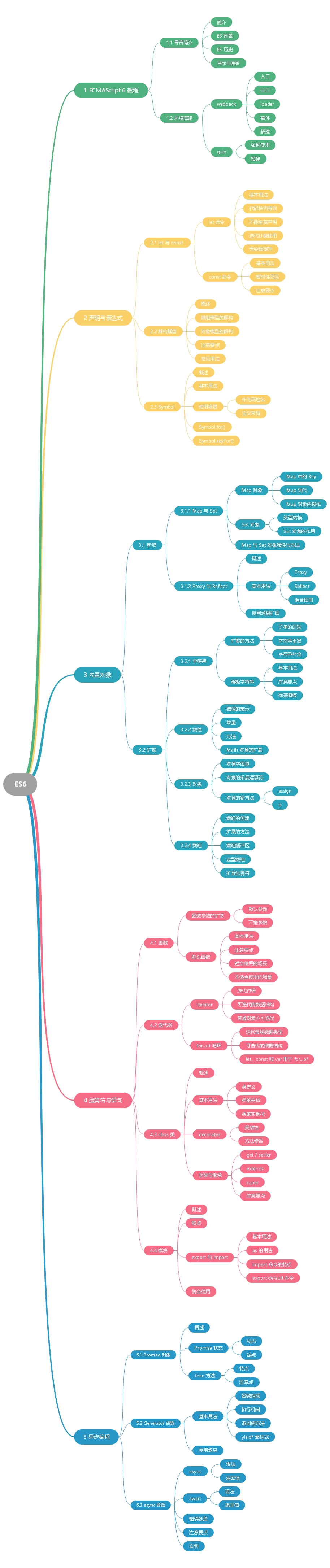
1. ECMAScript 6简介
1)ECMAScript 和 JavaScript 的关系
一个常见的问题是,ECMAScript 和 JavaScript 到底是什么关系?
要讲清楚这个问题,需要回顾历史。1996年11月,JavaScript 的创造者 Netscape 公司,决定将 JavaScript 提交给国际标准化组织ECMA,希望这种语言能够成为国际标准。次年,ECMA 发布262号标准文件(ECMA-262)的第一版,规定了浏览器脚本语言的标准,并将这种语言称为 ECMAScript,这个版本就是1.0版。
该标准从一开始就是针对 JavaScript 语言制定的,但是之所以不叫 JavaScript,有两个原因。一是商标,Java 是 Sun 公司的商标,根据授权协议,只有 Netscape 公司可以合法地使用 JavaScript 这个名字,且 JavaScript 本身也已经被 Netscape 公司注册为商标。二是想体现这门语言的制定者是 ECMA,不是 Netscape,这样有利于保证这门语言的开放性和中立性。
因此,ECMAScript 和 JavaScript 的关系是,前者是后者的规格,后者是前者的一种实现(另外的 ECMAScript 方言还有 Jscript 和 ActionScript)。日常场合,这两个词是可以互换的。
Node 是 JavaScript 的服务器运行环境(runtime)。
2. let和const命令
1)let
基本语法
ES6新增了let命令,用来声明变量。它的用法类似于var,但是所声明的变量,只在let命令所在的代码块内有效。
{
let a = 10;
var b = 1;
}
a // ReferenceError: a is not defined.
b // 1
上面代码在代码块之中,分别用let和var声明了两个变量。然后在代码块之外调用这两个变量,结果let声明的变量报错,var声明的变量返回了正确的值。这表明,let声明的变量只在它所在的代码块有效。
不存在变量提升
var命令会发生”变量提升“现象,即变量可以在声明之前使用,值为undefined。这种现象多多少少是有些奇怪的,按照一般的逻辑,变量应该在声明语句之后才可以使用。
为了纠正这种现象,let命令改变了语法行为,它所声明的变量一定要在声明后使用,否则报错。
// var 的情况
console.log(foo); // 输出undefined
var foo = 2;
// let 的情况
console.log(bar); // 报错ReferenceError
let bar = 2;
上面代码中,变量foo用var命令声明,会发生变量提升,即脚本开始运行时,变量foo已经存在了,但是没有值,所以会输出undefined。变量bar用let命令声明,不会发生变量提升。这表示在声明它之前,变量bar是不存在的,这时如果用到它,就会抛出一个错误。
暂时性死区
只要块级作用域内存在let命令,它所声明的变量就“绑定”(binding)这个区域,不再受外部的影响。
var tmp = 123;
if (true) {
tmp = 'abc'; // ReferenceError
let tmp;
}
上面代码中,存在全局变量tmp,但是块级作用域内let又声明了一个局部变量tmp,导致后者绑定这个块级作用域,所以在let声明变量前,对tmp赋值会报错。
ES6明确规定,如果区块中存在let和const命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。
不允许重复声明
let不允许在相同作用域内,重复声明同一个变量。
// 报错
function () {
let a = 10;
var a = 1;
}
// 报错
function () {
let a = 10;
let a = 1;
}
因此,不能在函数内部重新声明参数。
function func(arg) {
let arg; // 报错
}
function func(arg) {
{
let arg; // 不报错
}
}
ES6 的块级作用域
let实际上为 JavaScript 新增了块级作用域。
function f1() {
let n = 5;
if (true) {
let n = 10;
}
console.log(n); // 5
}
上面的函数有两个代码块,都声明了变量n,运行后输出5。这表示外层代码块不受内层代码块的影响。如果使用var定义变量n,最后输出的值就是10。
2)const命令
基本用法
const声明一个只读的常量。一旦声明,常量的值就不能改变。
const PI = 3.1415;
PI // 3.1415
PI = 3;
// TypeError: Assignment to constant variable.
上面代码表明改变常量的值会报错。
const声明的变量不得改变值,这意味着,const一旦声明变量,就必须立即初始化,不能留到以后赋值。
const foo;
// SyntaxError: Missing initializer in const declaration
上面代码表示,对于const来说,只声明不赋值,就会报错。
const的作用域与let命令相同:只在声明所在的块级作用域内有效。
if (true) {
const MAX = 5;
}
MAX // Uncaught ReferenceError: MAX is not defined
const命令声明的常量也是不提升,同样存在暂时性死区,只能在声明的位置后面使用。
if (true) {
console.log(MAX); // ReferenceError
const MAX = 5;
}
上面代码在常量MAX声明之前就调用,结果报错。
const声明的常量,也与let一样不可重复声明。
var message = "Hello!";
let age = 25;
// 以下两行都会报错
const message = "Goodbye!";
const age = 30;
本质
const实际上保证的,并不是变量的值不得改动,而是变量指向的那个内存地址不得改动。对于简单类型的数据(数值、字符串、布尔值),值就保存在变量指向的那个内存地址,因此等同于常量。但对于复合类型的数据(主要是对象和数组),变量指向的内存地址,保存的只是一个指针,const只能保证这个指针是固定的,至于它指向的数据结构是不是可变的,就完全不能控制了。因此,将一个对象声明为常量必须非常小心。
const foo = {};
// 为 foo 添加一个属性,可以成功
foo.prop = 123;
foo.prop // 123
// 将 foo 指向另一个对象,就会报错
foo = {}; // TypeError: "foo" is read-only
上面代码中,常量foo储存的是一个地址,这个地址指向一个对象。不可变的只是这个地址,即不能把foo指向另一个地址,但对象本身是可变的,所以依然可以为其添加新属性。
ES6 声明变量的六种方法
ES5 只有两种声明变量的方法:var命令和function命令。ES6除了添加let和const命令,后面章节还会提到,另外两种声明变量的方法:import命令和class命令。所以,ES6 一共有6种声明变量的方法。
3. 变量的解构赋值
1)数组的解构赋值
基本用法
ES6 允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构(Destructuring)。
以前,为变量赋值,只能直接指定值。
let a = 1;
let b = 2;
let c = 3;
ES6允许写成下面这样。
let [a, b, c] = [1, 2, 3];
上面代码表示,可以从数组中提取值,按照对应位置,对变量赋值。
2)对象的解构赋值
解构不仅可以用于数组,还可以用于对象。
let { foo, bar } = { foo: "aaa", bar: "bbb" };
foo // "aaa"
bar // "bbb"
对象的解构与数组有一个重要的不同。数组的元素是按次序排列的,变量的取值由它的位置决定;而对象的属性没有次序,变量必须与属性同名,才能取到正确的值。
let { bar, foo } = { foo: "aaa", bar: "bbb" };
foo // "aaa"
bar // "bbb"
let { baz } = { foo: "aaa", bar: "bbb" };
baz // undefined
上面代码的第一个例子,等号左边的两个变量的次序,与等号右边两个同名属性的次序不一致,但是对取值完全没有影响。第二个例子的变量没有对应的同名属性,导致取不到值,最后等于undefined。
如果变量名与属性名不一致,必须写成下面这样。
var { foo: baz } = { foo: 'aaa', bar: 'bbb' };
baz // "aaa"
let obj = { first: 'hello', last: 'world' };
let { first: f, last: l } = obj;
f // 'hello'
l // 'world'
字符串的解构赋值
字符串也可以解构赋值。这是因为此时,字符串被转换成了一个类似数组的对象。
const [a, b, c, d, e] = 'hello';
a // "h"
b // "e"
c // "l"
d // "l"
e // "o"
类似数组的对象都有一个length属性,因此还可以对这个属性解构赋值。
let {length : len} = 'hello';
len // 5
数值和布尔值的解构赋值
解构赋值时,如果等号右边是数值和布尔值,则会先转为对象。
let {toString: s} = 123;
s === Number.prototype.toString // true
let {toString: s} = true;
s === Boolean.prototype.toString // true
上面代码中,数值和布尔值的包装对象都有toString属性,因此变量s都能取到值。
解构赋值的规则是,只要等号右边的值不是对象或数组,就先将其转为对象。由于undefined和null无法转为对象,所以对它们进行解构赋值,都会报错。
let { prop: x } = undefined; // TypeError
let { prop: y } = null; // TypeError
用途
变量的解构赋值用途很多。
(1)交换变量的值
let x = 1;
let y = 2;
[x, y] = [y, x];
上面代码交换变量x和y的值,这样的写法不仅简洁,而且易读,语义非常清晰。
(2)从函数返回多个值
函数只能返回一个值,如果要返回多个值,只能将它们放在数组或对象里返回。有了解构赋值,取出这些值就非常方便。
// 返回一个数组
function example() {
return [1, 2, 3];
}
let [a, b, c] = example();
// 返回一个对象
function example() {
return {
foo: 1,
bar: 2
};
}
let { foo, bar } = example();
(3)函数参数的定义
解构赋值可以方便地将一组参数与变量名对应起来。
// 参数是一组有次序的值
function f([x, y, z]) { ... }
f([1, 2, 3]);
// 参数是一组无次序的值
function f({x, y, z}) { ... }
f({z: 3, y: 2, x: 1});
(4)提取JSON数据
解构赋值对提取JSON对象中的数据,尤其有用。
let jsonData = {
id: 42,
status: "OK",
data: [867, 5309]
};
let { id, status, data: number } = jsonData;
console.log(id, status, number);
// 42, "OK", [867, 5309]
上面代码可以快速提取 JSON 数据的值。
(5)函数参数的默认值
jQuery.ajax = function (url, {
async = true,
beforeSend = function () {},
cache = true,
complete = function () {},
crossDomain = false,
global = true,
// ... more config
}) {
// ... do stuff
};
指定参数的默认值,就避免了在函数体内部再写var foo = config.foo || 'default foo';这样的语句。
(6)遍历Map结构
任何部署了Iterator接口的对象,都可以用for...of循环遍历。Map结构原生支持Iterator接口,配合变量的解构赋值,获取键名和键值就非常方便。
var map = new Map();
map.set('first', 'hello');
map.set('second', 'world');
for (let [key, value] of map) {
console.log(key + " is " + value);
}
// first is hello
// second is world
如果只想获取键名,或者只想获取键值,可以写成下面这样。
// 获取键名
for (let [key] of map) {
// ...
}
// 获取键值
for (let [,value] of map) {
// ...
}
(7)输入模块的指定方法
加载模块时,往往需要指定输入哪些方法。解构赋值使得输入语句非常清晰。
const { SourceMapConsumer, SourceNode } = require("source-map");
4. 字符串的扩展
5. 正则的扩展
6. 数值的扩展
Math对象的扩展
ES6在Math对象上新增了17个与数学相关的方法。所有这些方法都是静态方法,只能在Math对象上调用。
Math.trunc()
Math.trunc方法用于去除一个数的小数部分,返回整数部分。
Math.trunc(4.1) // 4
Math.trunc(4.9) // 4
Math.trunc(-4.1) // -4
Math.trunc(-4.9) // -4
Math.trunc(-0.1234) // -0
对于非数值,Math.trunc内部使用Number方法将其先转为数值。
Math.trunc('123.456')
// 123
对于空值和无法截取整数的值,返回NaN。
Math.trunc(NaN); // NaN
Math.trunc('foo'); // NaN
Math.trunc(); // NaN
对于没有部署这个方法的环境,可以用下面的代码模拟。
Math.trunc = Math.trunc || function(x) {
return x < 0 ? Math.ceil(x) : Math.floor(x);
};
Math.sign()
Math.sign方法用来判断一个数到底是正数、负数、还是零。
它会返回五种值。
- 参数为正数,返回+1;
- 参数为负数,返回-1;
- 参数为0,返回0;
- 参数为-0,返回-0;
- 其他值,返回NaN。
Math.sign(-5) // -1
Math.sign(5) // +1
Math.sign(0) // +0
Math.sign(-0) // -0
Math.sign(NaN) // NaN
Math.sign('foo'); // NaN
Math.sign(); // NaN
对于没有部署这个方法的环境,可以用下面的代码模拟。
Math.sign = Math.sign || function(x) {
x = +x; // convert to a number
if (x === 0 || isNaN(x)) {
return x;
}
return x > 0 ? 1 : -1;
};
Math.cbrt()
Math.cbrt方法用于计算一个数的立方根。
Math.cbrt(-1) // -1
Math.cbrt(0) // 0
Math.cbrt(1) // 1
Math.cbrt(2) // 1.2599210498948734
对于非数值,Math.cbrt方法内部也是先使用Number方法将其转为数值。
Math.cbrt('8') // 2
Math.cbrt('hello') // NaN
对于没有部署这个方法的环境,可以用下面的代码模拟。
Math.cbrt = Math.cbrt || function(x) {
var y = Math.pow(Math.abs(x), 1/3);
return x < 0 ? -y : y;
};
Math.clz32()
JavaScript的整数使用32位二进制形式表示,Math.clz32方法返回一个数的32位无符号整数形式有多少个前导0。
Math.clz32(0) // 32
Math.clz32(1) // 31
Math.clz32(1000) // 22
Math.clz32(0b01000000000000000000000000000000) // 1
Math.clz32(0b00100000000000000000000000000000) // 2
上面代码中,0的二进制形式全为0,所以有32个前导0;1的二进制形式是0b1,只占1位,所以32位之中有31个前导0;1000的二进制形式是0b1111101000,一共有10位,所以32位之中有22个前导0。
clz32这个函数名就来自”count leading zero bits in 32-bit binary representations of a number“(计算32位整数的前导0)的缩写。
左移运算符(<<)与Math.clz32方法直接相关。
Math.clz32(0) // 32
Math.clz32(1) // 31
Math.clz32(1 << 1) // 30
Math.clz32(1 << 2) // 29
Math.clz32(1 << 29) // 2
对于小数,Math.clz32方法只考虑整数部分。
Math.clz32(3.2) // 30
Math.clz32(3.9) // 30
对于空值或其他类型的值,Math.clz32方法会将它们先转为数值,然后再计算。
Math.clz32() // 32
Math.clz32(NaN) // 32
Math.clz32(Infinity) // 32
Math.clz32(null) // 32
Math.clz32('foo') // 32
Math.clz32([]) // 32
Math.clz32({}) // 32
Math.clz32(true) // 31
Math.imul()
Math.imul方法返回两个数以32位带符号整数形式相乘的结果,返回的也是一个32位的带符号整数。
Math.imul(2, 4) // 8
Math.imul(-1, 8) // -8
Math.imul(-2, -2) // 4
如果只考虑最后32位,大多数情况下,Math.imul(a, b)与a * b的结果是相同的,即该方法等同于(a * b)|0的效果(超过32位的部分溢出)。之所以需要部署这个方法,是因为JavaScript有精度限制,超过2的53次方的值无法精确表示。这就是说,对于那些很大的数的乘法,低位数值往往都是不精确的,Math.imul方法可以返回正确的低位数值。
(0x7fffffff * 0x7fffffff)|0 // 0
上面这个乘法算式,返回结果为0。但是由于这两个二进制数的最低位都是1,所以这个结果肯定是不正确的,因为根据二进制乘法,计算结果的二进制最低位应该也是1。这个错误就是因为它们的乘积超过了2的53次方,JavaScript无法保存额外的精度,就把低位的值都变成了0。Math.imul方法可以返回正确的值1。
Math.imul(0x7fffffff, 0x7fffffff) // 1
Math.fround()
Math.fround方法返回一个数的单精度浮点数形式。
Math.fround(0) // 0
Math.fround(1) // 1
Math.fround(1.337) // 1.3370000123977661
Math.fround(1.5) // 1.5
Math.fround(NaN) // NaN
对于整数来说,Math.fround方法返回结果不会有任何不同,区别主要是那些无法用64个二进制位精确表示的小数。这时,Math.fround方法会返回最接近这个小数的单精度浮点数。
对于没有部署这个方法的环境,可以用下面的代码模拟。
Math.fround = Math.fround || function(x) {
return new Float32Array([x])[0];
};
Math.hypot()
Math.hypot方法返回所有参数的平方和的平方根。
Math.hypot(3, 4); // 5
Math.hypot(3, 4, 5); // 7.0710678118654755
Math.hypot(); // 0
Math.hypot(NaN); // NaN
Math.hypot(3, 4, 'foo'); // NaN
Math.hypot(3, 4, '5'); // 7.0710678118654755
Math.hypot(-3); // 3
上面代码中,3的平方加上4的平方,等于5的平方。
如果参数不是数值,Math.hypot方法会将其转为数值。只要有一个参数无法转为数值,就会返回NaN。
7. 数组的扩展
Array.from()
Array.from方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(包括ES6新增的数据结构Set和Map)。
下面是一个类似数组的对象,Array.from将它转为真正的数组。
let arrayLike = {
'0': 'a',
'1': 'b',
'2': 'c',
length: 3
};
// ES5的写法
var arr1 = [].slice.call(arrayLike); // ['a', 'b', 'c']
// ES6的写法
let arr2 = Array.from(arrayLike); // ['a', 'b', 'c']
实际应用中,常见的类似数组的对象是DOM操作返回的NodeList集合,以及函数内部的arguments对象。Array.from都可以将它们转为真正的数组。
Array.of()
Array.of方法用于将一组值,转换为数组。
Array.of(3, 11, 8) // [3,11,8]
Array.of(3) // [3]
Array.of(3).length // 1
这个方法的主要目的,是弥补数组构造函数Array()的不足。因为参数个数的不同,会导致Array()的行为有差异。
Array() // []
Array(3) // [, , ,]
Array(3, 11, 8) // [3, 11, 8]
上面代码中,Array方法没有参数、一个参数、三个参数时,返回结果都不一样。只有当参数个数不少于2个时,Array()才会返回由参数组成的新数组。参数个数只有一个时,实际上是指定数组的长度。
Array.of基本上可以用来替代Array()或new Array(),并且不存在由于参数不同而导致的重载。它的行为非常统一。
Array.of() // []
Array.of(undefined) // [undefined]
Array.of(1) // [1]
Array.of(1, 2) // [1, 2]
Array.of总是返回参数值组成的数组。如果没有参数,就返回一个空数组。
Array.of方法可以用下面的代码模拟实现。
function ArrayOf(){
return [].slice.call(arguments);
}
数组实例的find()和findIndex()
数组实例的find方法,用于找出第一个符合条件的数组成员。它的参数是一个回调函数,所有数组成员依次执行该回调函数,直到找出第一个返回值为true的成员,然后返回该成员。如果没有符合条件的成员,则返回undefined。
[1, 4, -5, 10].find((n) => n < 0)
// -5
上面代码找出数组中第一个小于0的成员。
[1, 5, 10, 15].find(function(value, index, arr) {
return value > 9;
}) // 10
上面代码中,find方法的回调函数可以接受三个参数,依次为当前的值、当前的位置和原数组。
数组实例的findIndex方法的用法与find方法非常类似,返回第一个符合条件的数组成员的位置,如果所有成员都不符合条件,则返回-1。
[1, 5, 10, 15].findIndex(function(value, index, arr) {
return value > 9;
}) // 2
这两个方法都可以接受第二个参数,用来绑定回调函数的this对象。
另外,这两个方法都可以发现NaN,弥补了数组的IndexOf方法的不足。
[NaN].indexOf(NaN)
// -1
[NaN].findIndex(y => Object.is(NaN, y))
// 0
上面代码中,indexOf方法无法识别数组的NaN成员,但是findIndex方法可以借助Object.is方法做到。
 数组实例的includes()
数组实例的includes()
Array.prototype.includes方法返回一个布尔值,表示某个数组是否包含给定的值,与字符串的includes方法类似。该方法属于ES7,但Babel转码器已经支持。
[1, 2, 3].includes(2); // true
[1, 2, 3].includes(4); // false
[1, 2, NaN].includes(NaN); // true
该方法的第二个参数表示搜索的起始位置,默认为0。如果第二个参数为负数,则表示倒数的位置,如果这时它大于数组长度(比如第二个参数为-4,但数组长度为3),则会重置为从0开始。
[1, 2, 3].includes(3, 3); // false
[1, 2, 3].includes(3, -1); // true
没有该方法之前,我们通常使用数组的indexOf方法,检查是否包含某个值。
if (arr.indexOf(el) !== -1) {
// ...
}
indexOf方法有两个缺点,一是不够语义化,它的含义是找到参数值的第一个出现位置,所以要去比较是否不等于-1,表达起来不够直观。二是,它内部使用严格相当运算符(===)进行判断,这会导致对NaN的误判。
[NaN].indexOf(NaN)
// -1
includes使用的是不一样的判断算法,就没有这个问题。
[NaN].includes(NaN)
// true
下面代码用来检查当前环境是否支持该方法,如果不支持,部署一个简易的替代版本。
const contains = (() =>
Array.prototype.includes
? (arr, value) => arr.includes(value)
: (arr, value) => arr.some(el => el === value)
)();
contains(["foo", "bar"], "baz"); // => false
另外,Map和Set数据结构有一个has方法,需要注意与includes区分。
- Map结构的
has方法,是用来查找键名的,比如Map.prototype.has(key)、WeakMap.prototype.has(key)、Reflect.has(target, propertyKey)。 - Set结构的
has方法,是用来查找值的,比如Set.prototype.has(value)、WeakSet.prototype.has(value)。
8. 函数的扩展
扩展运算符
含义
扩展运算符(spread)是三个点(...)。它好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列。
console.log(...[1, 2, 3])
// 1 2 3
console.log(1, ...[2, 3, 4], 5)
// 1 2 3 4 5
[...document.querySelectorAll('div')]
// [<div>, <div>, <div>]
该运算符主要用于函数调用。
function push(array, ...items) {
array.push(...items);
}
function add(x, y) {
return x + y;
}
var numbers = [4, 38];
add(...numbers) // 42
上面代码中,array.push(...items)和add(...numbers)这两行,都是函数的调用,它们的都使用了扩展运算符。该运算符将一个数组,变为参数序列。
扩展运算符与正常的函数参数可以结合使用,非常灵活。
function f(v, w, x, y, z) { }
var args = [0, 1];
f(-1, ...args, 2, ...[3]);
扩展运算符的应用
(1)合并数组
扩展运算符提供了数组合并的新写法。
// ES5
[1, 2].concat(more)
// ES6
[1, 2, ...more]
var arr1 = ['a', 'b'];
var arr2 = ['c'];
var arr3 = ['d', 'e'];
// ES5的合并数组
arr1.concat(arr2, arr3);
// [ 'a', 'b', 'c', 'd', 'e' ]
// ES6的合并数组
[...arr1, ...arr2, ...arr3]
// [ 'a', 'b', 'c', 'd', 'e' ]
(2)与解构赋值结合
扩展运算符可以与解构赋值结合起来,用于生成数组。
// ES5
a = list[0], rest = list.slice(1)
// ES6
[a, ...rest] = list
下面是另外一些例子。
const [first, ...rest] = [1, 2, 3, 4, 5];
first // 1
rest // [2, 3, 4, 5]
const [first, ...rest] = [];
first // undefined
rest // []:
const [first, ...rest] = ["foo"];
first // "foo"
rest // []
如果将扩展运算符用于数组赋值,只能放在参数的最后一位,否则会报错。
const [...butLast, last] = [1, 2, 3, 4, 5];
// 报错
const [first, ...middle, last] = [1, 2, 3, 4, 5];
// 报错
(3)函数的返回值
JavaScript的函数只能返回一个值,如果需要返回多个值,只能返回数组或对象。扩展运算符提供了解决这个问题的一种变通方法。
var dateFields = readDateFields(database);
var d = new Date(...dateFields);
上面代码从数据库取出一行数据,通过扩展运算符,直接将其传入构造函数Date。
(4)字符串
扩展运算符还可以将字符串转为真正的数组。
[...'hello']
// [ "h", "e", "l", "l", "o" ]
上面的写法,有一个重要的好处,那就是能够正确识别32位的Unicode字符。
'x\uD83D\uDE80y'.length // 4
[...'x\uD83D\uDE80y'].length // 3
上面代码的第一种写法,JavaScript会将32位Unicode字符,识别为2个字符,采用扩展运算符就没有这个问题。因此,正确返回字符串长度的函数,可以像下面这样写。
function length(str) {
return [...str].length;
}
length('x\uD83D\uDE80y') // 3
凡是涉及到操作32位Unicode字符的函数,都有这个问题。因此,最好都用扩展运算符改写。
let str = 'x\uD83D\uDE80y';
str.split('').reverse().join('')
// 'y\uDE80\uD83Dx'
[...str].reverse().join('')
// 'y\uD83D\uDE80x'
上面代码中,如果不用扩展运算符,字符串的reverse操作就不正确。
(5)实现了Iterator接口的对象
任何Iterator接口的对象,都可以用扩展运算符转为真正的数组。
var nodeList = document.querySelectorAll('div');
var array = [...nodeList];
上面代码中,querySelectorAll方法返回的是一个nodeList对象。它不是数组,而是一个类似数组的对象。这时,扩展运算符可以将其转为真正的数组,原因就在于NodeList对象实现了Iterator接口。
对于那些没有部署Iterator接口的类似数组的对象,扩展运算符就无法将其转为真正的数组。
let arrayLike = {
'0': 'a',
'1': 'b',
'2': 'c',
length: 3
};
// TypeError: Cannot spread non-iterable object.
let arr = [...arrayLike];
上面代码中,arrayLike是一个类似数组的对象,但是没有部署Iterator接口,扩展运算符就会报错。这时,可以改为使用Array.from方法将arrayLike转为真正的数组。
(6)Map和Set结构,Generator函数
扩展运算符内部调用的是数据结构的Iterator接口,因此只要具有Iterator接口的对象,都可以使用扩展运算符,比如Map结构。
let map = new Map([
[1, 'one'],
[2, 'two'],
[3, 'three'],
]);
let arr = [...map.keys()]; // [1, 2, 3]
Generator函数运行后,返回一个遍历器对象,因此也可以使用扩展运算符。
var go = function*(){
yield 1;
yield 2;
yield 3;
};
[...go()] // [1, 2, 3]
上面代码中,变量go是一个Generator函数,执行后返回的是一个遍历器对象,对这个遍历器对象执行扩展运算符,就会将内部遍历得到的值,转为一个数组。
如果对没有iterator接口的对象,使用扩展运算符,将会报错。
var obj = {a: 1, b: 2};
let arr = [...obj]; // TypeError: Cannot spread non-iterable object
箭头函数
基本用法
ES6允许使用“箭头”(=>)定义函数。
var f = v => v;
上面的箭头函数等同于:
var f = function(v) {
return v;
};
如果箭头函数不需要参数或需要多个参数,就使用一个圆括号代表参数部分。
var f = () => 5;
// 等同于
var f = function () { return 5 };
var sum = (num1, num2) => num1 + num2;
// 等同于
var sum = function(num1, num2) {
return num1 + num2;
};
如果箭头函数的代码块部分多于一条语句,就要使用大括号将它们括起来,并且使用return语句返回。
var sum = (num1, num2) => { return num1 + num2; }
由于大括号被解释为代码块,所以如果箭头函数直接返回一个对象,必须在对象外面加上括号。
var getTempItem = id => ({ id: id, name: "Temp" });
箭头函数可以与变量解构结合使用。
const full = ({ first, last }) => first + ' ' + last;
// 等同于
function full(person) {
return person.first + ' ' + person.last;
}
箭头函数使得表达更加简洁。
const isEven = n => n % 2 == 0;
const square = n => n * n;
上面代码只用了两行,就定义了两个简单的工具函数。如果不用箭头函数,可能就要占用多行,而且还不如现在这样写醒目。
箭头函数的一个用处是简化回调函数。
// 正常函数写法
[1,2,3].map(function (x) {
return x * x;
});
// 箭头函数写法
[1,2,3].map(x => x * x);
另一个例子是
// 正常函数写法
var result = values.sort(function (a, b) {
return a - b;
});
// 箭头函数写法
var result = values.sort((a, b) => a - b);
下面是rest参数与箭头函数结合的例子。
const numbers = (...nums) => nums;
numbers(1, 2, 3, 4, 5)
// [1,2,3,4,5]
const headAndTail = (head, ...tail) => [head, tail];
headAndTail(1, 2, 3, 4, 5)
// [1,[2,3,4,5]]
使用注意点
箭头函数有几个使用注意点。
(1)函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象。
(2)不可以当作构造函数,也就是说,不可以使用new命令,否则会抛出一个错误。
(3)不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用Rest参数代替。
(4)不可以使用yield命令,因此箭头函数不能用作Generator函数。
上面四点中,第一点尤其值得注意。this对象的指向是可变的,但是在箭头函数中,它是固定的。
function foo() {
setTimeout(() => {
console.log('id:', this.id);
}, 100);
}
var id = 21;
foo.call({ id: 42 });
// id: 42
上面代码中,setTimeout的参数是一个箭头函数,这个箭头函数的定义生效是在foo函数生成时,而它的真正执行要等到100毫秒后。如果是普通函数,执行时this应该指向全局对象window,这时应该输出21。但是,箭头函数导致this总是指向函数定义生效时所在的对象(本例是{id: 42}),所以输出的是42。
箭头函数可以让setTimeout里面的this,绑定定义时所在的作用域,而不是指向运行时所在的作用域。下面是另一个例子。
function Timer() {
this.s1 = 0;
this.s2 = 0;
// 箭头函数
setInterval(() => this.s1++, 1000);
// 普通函数
setInterval(function () {
this.s2++;
}, 1000);
}
var timer = new Timer();
setTimeout(() => console.log('s1: ', timer.s1), 3100);
setTimeout(() => console.log('s2: ', timer.s2), 3100);
// s1: 3
// s2: 0
上面代码中,Timer函数内部设置了两个定时器,分别使用了箭头函数和普通函数。前者的this绑定定义时所在的作用域(即Timer函数),后者的this指向运行时所在的作用域(即全局对象)。所以,3100毫秒之后,timer.s1被更新了3次,而timer.s2一次都没更新。
箭头函数可以让this指向固定化,这种特性很有利于封装回调函数。下面是一个例子,DOM事件的回调函数封装在一个对象里面。
var handler = {
id: '123456',
init: function() {
document.addEventListener('click',
event => this.doSomething(event.type), false);
},
doSomething: function(type) {
console.log('Handling ' + type + ' for ' + this.id);
}
};
上面代码的init方法中,使用了箭头函数,这导致这个箭头函数里面的this,总是指向handler对象。否则,回调函数运行时,this.doSomething这一行会报错,因为此时this指向document对象。
this指向的固定化,并不是因为箭头函数内部有绑定this的机制,实际原因是箭头函数根本没有自己的this,导致内部的this就是外层代码块的this。正是因为它没有this,所以也就不能用作构造函数。
所以,箭头函数转成ES5的代码如下。
// ES6
function foo() {
setTimeout(() => {
console.log('id:', this.id);
}, 100);
}
// ES5
function foo() {
var _this = this;
setTimeout(function () {
console.log('id:', _this.id);
}, 100);
}
上面代码中,转换后的ES5版本清楚地说明了,箭头函数里面根本没有自己的this,而是引用外层的this。
请问下面的代码之中有几个this?
function foo() {
return () => {
return () => {
return () => {
console.log('id:', this.id);
};
};
};
}
var f = foo.call({id: 1});
var t1 = f.call({id: 2})()(); // id: 1
var t2 = f().call({id: 3})(); // id: 1
var t3 = f()().call({id: 4}); // id: 1
上面代码之中,只有一个this,就是函数foo的this,所以t1、t2、t3都输出同样的结果。因为所有的内层函数都是箭头函数,都没有自己的this,它们的this其实都是最外层foo函数的this。
除了this,以下三个变量在箭头函数之中也是不存在的,指向外层函数的对应变量:arguments、super、new.target。
function foo() {
setTimeout(() => {
console.log('args:', arguments);
}, 100);
}
foo(2, 4, 6, 8)
// args: [2, 4, 6, 8]
上面代码中,箭头函数内部的变量arguments,其实是函数foo的arguments变量。
另外,由于箭头函数没有自己的this,所以当然也就不能用call()、apply()、bind()这些方法去改变this的指向。
(function() {
return [
(() => this.x).bind({ x: 'inner' })()
];
}).call({ x: 'outer' });
// ['outer']
上面代码中,箭头函数没有自己的this,所以bind方法无效,内部的this指向外部的this。
长期以来,JavaScript语言的this对象一直是一个令人头痛的问题,在对象方法中使用this,必须非常小心。箭头函数”绑定”this,很大程度上解决了这个困扰。
嵌套的箭头函数
箭头函数内部,还可以再使用箭头函数。下面是一个ES5语法的多重嵌套函数。
function insert(value) {
return {into: function (array) {
return {after: function (afterValue) {
array.splice(array.indexOf(afterValue) + 1, 0, value);
return array;
}};
}};
}
insert(2).into([1, 3]).after(1); //[1, 2, 3]
上面这个函数,可以使用箭头函数改写。
let insert = (value) => ({into: (array) => ({after: (afterValue) => {
array.splice(array.indexOf(afterValue) + 1, 0, value);
return array;
}})});
insert(2).into([1, 3]).after(1); //[1, 2, 3]
下面是一个部署管道机制(pipeline)的例子,即前一个函数的输出是后一个函数的输入。
const pipeline = (...funcs) =>
val => funcs.reduce((a, b) => b(a), val);
const plus1 = a => a + 1;
const mult2 = a => a * 2;
const addThenMult = pipeline(plus1, mult2);
addThenMult(5)
// 12
如果觉得上面的写法可读性比较差,也可以采用下面的写法。
const plus1 = a => a + 1;
const mult2 = a => a * 2;
mult2(plus1(5))
// 12
箭头函数还有一个功能,就是可以很方便地改写λ演算。
// λ演算的写法
fix = λf.(λx.f(λv.x(x)(v)))(λx.f(λv.x(x)(v)))
// ES6的写法
var fix = f => (x => f(v => x(x)(v)))
(x => f(v => x(x)(v)));
上面两种写法,几乎是一一对应的。由于λ演算对于计算机科学非常重要,这使得我们可以用ES6作为替代工具,探索计算机科学。
绑定
this
箭头函数可以绑定this对象,大大减少了显式绑定this对象的写法(call、apply、bind)。但是,箭头函数并不适用于所有场合,所以ES7提出了“函数绑定”(function bind)运算符,用来取代call、apply、bind调用。虽然该语法还是ES7的一个提案,但是Babel转码器已经支持。
函数绑定运算符是并排的两个双冒号(::),双冒号左边是一个对象,右边是一个函数。该运算符会自动将左边的对象,作为上下文环境(即this对象),绑定到右边的函数上面。
foo::bar;
// 等同于
bar.bind(foo);
foo::bar(...arguments);
// 等同于
bar.apply(foo, arguments);
const hasOwnProperty = Object.prototype.hasOwnProperty;
function hasOwn(obj, key) {
return obj::hasOwnProperty(key);
}
如果双冒号左边为空,右边是一个对象的方法,则等于将该方法绑定在该对象上面。
var method = obj::obj.foo;
// 等同于
var method = ::obj.foo;
let log = ::console.log;
// 等同于
var log = console.log.bind(console);
由于双冒号运算符返回的还是原对象,因此可以采用链式写法。
// 例一
import { map, takeWhile, forEach } from "iterlib";
getPlayers()
::map(x => x.character())
::takeWhile(x => x.strength > 100)
::forEach(x => console.log(x));
// 例二
let { find, html } = jake;
document.querySelectorAll("div.myClass")
::find("p")
::html("hahaha");
9. 对象的扩展
Object.is()
ES5比较两个值是否相等,只有两个运算符:相等运算符(==)和严格相等运算符(===)。它们都有缺点,前者会自动转换数据类型,后者的NaN不等于自身,以及+0等于-0。JavaScript缺乏一种运算,在所有环境中,只要两个值是一样的,它们就应该相等。
ES6提出“Same-value equality”(同值相等)算法,用来解决这个问题。Object.is就是部署这个算法的新方法。它用来比较两个值是否严格相等,与严格比较运算符(===)的行为基本一致。
Object.is('foo', 'foo')
// true
Object.is({}, {})
// false
不同之处只有两个:一是+0不等于-0,二是NaN等于自身。
+0 === -0 //true
NaN === NaN // false
Object.is(+0, -0) // false
Object.is(NaN, NaN) // true
ES5可以通过下面的代码,部署Object.is。
Object.defineProperty(Object, 'is', {
value: function(x, y) {
if (x === y) {
// 针对+0 不等于 -0的情况
return x !== 0 || 1 / x === 1 / y;
}
// 针对NaN的情况
return x !== x && y !== y;
},
configurable: true,
enumerable: false,
writable: true
});
10. Symbol
ES5的对象属性名都是字符串,这容易造成属性名的冲突。比如,你使用了一个他人提供的对象,但又想为这个对象添加新的方法(mixin模式),新方法的名字就有可能与现有方法产生冲突。如果有一种机制,保证每个属性的名字都是独一无二的就好了,这样就从根本上防止属性名的冲突。这就是ES6引入Symbol的原因。
11. Set和Map数据结构
Set
ES6 提供了新的数据结构 Set。它类似于数组,但是成员的值都是唯一的,没有重复的值。
Set 本身是一个构造函数,用来生成 Set 数据结构。
const s = new Set();
[2, 3, 5, 4, 5, 2, 2].forEach(x => s.add(x));
for (let i of s) {
console.log(i);
}
// 2 3 5 4
// 去除数组的重复成员
[...new Set(array)]
WeakSet
WeakSet结构与Set类似,也是不重复的值的集合。但是,它与Set有两个区别。
首先,WeakSet的成员只能是对象,而不能是其他类型的值。
其次,WeakSet中的对象都是弱引用,即垃圾回收机制不考虑WeakSet对该对象的引用,也就是说,如果其他对象都不再引用该对象,那么垃圾回收机制会自动回收该对象所占用的内存,不考虑该对象还存在于WeakSet之中。这个特点意味着,无法引用WeakSet的成员,因此WeakSet是不可遍历的。
var ws = new WeakSet();
ws.add(1)
// TypeError: Invalid value used in weak set
ws.add(Symbol())
// TypeError: invalid value used in weak set
上面代码试图向WeakSet添加一个数值和Symbol值,结果报错,因为WeakSet只能放置对象。
Map
遍历方法
Map原生提供三个遍历器生成函数和一个遍历方法。
keys():返回键名的遍历器。values():返回键值的遍历器。entries():返回所有成员的遍历器。forEach():遍历Map的所有成员。
需要特别注意的是,Map的遍历顺序就是插入顺序。
下面是使用实例。
let map = new Map([
['F', 'no'],
['T', 'yes'],
]);
for (let key of map.keys()) {
console.log(key);
}
// "F"
// "T"
for (let value of map.values()) {
console.log(value);
}
// "no"
// "yes"
for (let item of map.entries()) {
console.log(item[0], item[1]);
}
// "F" "no"
// "T" "yes"
// 或者
for (let [key, value] of map.entries()) {
console.log(key, value);
}
// 等同于使用map.entries()
for (let [key, value] of map) {
console.log(key, value);
}
11. Proxy
Proxy 用于修改某些操作的默认行为,等同于在语言层面做出修改,所以属于一种“元编程”(meta programming),即对编程语言进行编程。
Proxy 可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。Proxy 这个词的原意是代理,用在这里表示由它来“代理”某些操作,可以译为“代理器”。
12. Reflect
实例:使用 Proxy 实现观察者模式
观察者模式(Observer mode)指的是函数自动观察数据对象,一旦对象有变化,函数就会自动执行。
const person = observable({
name: '张三',
age: 20
});
function print() {
console.log(`${person.name}, ${person.age}`)
}
observe(print);
person.name = '李四';
// 输出
// 李四, 20
上面代码中,数据对象person是观察目标,函数print是观察者。一旦数据对象发生变化,print就会自动执行。
13. Promise
基本用法
ES6规定,Promise对象是一个构造函数,用来生成Promise实例。
下面代码创造了一个Promise实例。
var promise = new Promise(function(resolve, reject) {
// ... some code
if (/* 异步操作成功 */){
resolve(value);
} else {
reject(error);
}
});
Promise.resolve()
有时需要将现有对象转为Promise对象,Promise.resolve方法就起到这个作用。
var jsPromise = Promise.resolve($.ajax('/whatever.json'));
上面代码将jQuery生成的deferred对象,转为一个新的Promise对象。
Promise.resolve等价于下面的写法。
Promise.resolve('foo')
// 等价于
new Promise(resolve => resolve('foo'))
14. Iterator和for…of循环
JavaScript原有的for...in循环,只能获得对象的键名,不能直接获取键值。ES6提供for...of循环,允许遍历获得键值。
var arr = ['a', 'b', 'c', 'd'];
for (let a in arr) {
console.log(a); // 0 1 2 3
}
for (let a of arr) {
console.log(a); // a b c d
}
15. Generator 函数的语法
16. Generator 函数的异步应用
17. aysnc
基本用法
async函数返回一个 Promise 对象,可以使用then方法添加回调函数。当函数执行的时候,一旦遇到await就会先返回,等到异步操作完成,再接着执行函数体内后面的语句。
下面是一个例子。
async function getStockPriceByName(name) {
var symbol = await getStockSymbol(name);
var stockPrice = await getStockPrice(symbol);
return stockPrice;
}
getStockPriceByName('goog').then(function (result) {
console.log(result);
});
上面代码是一个获取股票报价的函数,函数前面的async关键字,表明该函数内部有异步操作。调用该函数时,会立即返回一个Promise对象。
下面是另一个例子,指定多少毫秒后输出一个值。
function timeout(ms) {
return new Promise((resolve) => {
setTimeout(resolve, ms);
});
}
async function asyncPrint(value, ms) {
await timeout(ms);
console.log(value);
}
asyncPrint('hello world', 50);
上面代码指定50毫秒以后,输出hello world。
由于async函数返回的是 Promise 对象,可以作为await命令的参数。所以,上面的例子也可以写成下面的形式。
async function timeout(ms) {
await new Promise((resolve) => {
setTimeout(resolve, ms);
});
}
async function asyncPrint(value, ms) {
await timeout(ms);
console.log(value);
}
asyncPrint('hello world', 50);
参考文档
ES6全套教程














 1701
1701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









