







由于Maven是依赖JDK使用的,所以我们的电脑上需要安装 JDK1.7 + 版本 并且配置好环境变量,我这边使用的是 JDK8 相关版本。然后再配置Maven的
好啦,废话讲完,上干货
- JDK配置环境变量,右击此电脑,选择并点击属性,然后点击高级系统设置,再点击环境变量,最后点击新建进行配置,(变量名是JAVA_HOME,变量值是JDK的安装路径)
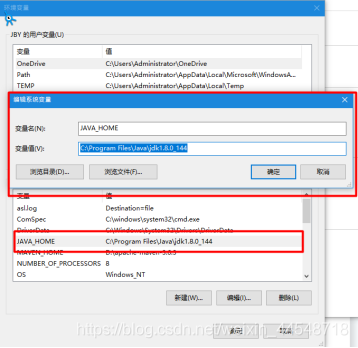
2.双击下图Path,进入里面之后点击新建(新建两个,参数是%USERPROFILE%\.dnx\bin和%JAV
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









