





文章目录
论文地址
ABSTRACT
深度学习最近非常流行,因为它在许多复杂数据驱动的应用中取得了惊人的成功,包括图像分类和语音识别。数据库社区多年来一直致力于数据驱动的应用程序,因此应该在支持这一新浪潮方面发挥主导作用。然而,数据库和深度学习在技术和应用方面都有所不同。本文讨论了这两个领域交叉点的研究问题。特别是,我们从数据库的角度讨论了深度学习系统可能的改进,并分析了可能从深度学习技术中受益的数据库应用程序。
1. INTRODUCTION
近年来,我们见证了许多基于数据驱动的机器学习应用程序的成功。这对数据库社区研究将机器学习技术集成到数据库系统和应用程序设计中起到促进作用。机器学习的一个分支,称为深度学习,由于其在语音识别、图像分类和自然语言处理(NLP)等多个领域的优异性能,近年来吸引了全世界的兴趣。深度学习的基础大约在二十年前以神经网络的形式建立起来。它最近的复兴主要是由三个因素推动的:巨大的计算能力,这减少了训练和部署新模型的时间,例如图形处理单元(GPU)使训练系统的运行速度比20世纪90年代快得多;大量(标记的)训练数据集(如ImageNet)能够获得更全面的领域知识;新的深度学习模型(如AlexNet)提高了捕获数据规律的能力。
自20世纪70年代以来,数据库研究人员一直致力于系统优化和大规模数据驱动应用,这与前两个因素密切相关。思考数据库与深度学习之间的关系是很自然的。首先,数据库社区是否可以为深度学习提供任何见解?研究表明,较大的训练数据集和较深的模型结构可以提高深度学习模型的准确性。然而,副作用是训练成本变得更高。从系统角度和理论角度提出了加快训练速度的方法。由于数据库社区在系统优化方面有着丰富的经验,因此讨论数据库技术在优化深度学习系统方面的适用性将是一个很好的时机。例如,分布式计算和内存管理是关键的数据库技术。它们也是深度学习的核心。
第二,是否有任何可以适应数据库问题的深度学习技术?深度学习产生于机器学习和计算机视觉社区。最近,它已成功应用于其他领域,如NLP。然而,很少有研究使用深度学习技术来解决数据库问题。这部分是因为传统的数据库问题-与索引、事务和存储管理一样,它们涉及的不确定性较少,而深度学习则擅长预测不确定事件。然而,数据库中也存在一些问题,如知识融合和众包,这些都是概率问题。在这些领域应用深度学习技术是可能的。本文将讨论查询接口、知识融合等具体问题。
本文的其余部分组织如下:第2节提供了关于深度学习模型和训练算法的背景信息;第3节讨论了数据库技术在优化深度学习系统中的应用。第4节描述了数据库中的研究问题,其中深度学习技术可能有助于提高性能。第5节给出了一些最终想法
2. BACKGROUND
深度学习是指一组机器学习模型,试图通过多个特征转换层学习原始数据的高级抽象(或表示)。大型训练数据集和深层复杂结构增强了深层学习模型学习感兴趣任务的有效表示的能力。根据层间连接的类型,有三种流行的深度学习模型,即前馈模型(定向连接)、能量模型(无向连接)和递归神经网络(递归连接)。前馈模型,包括卷积神经网络(CNN),通过每一层传播输入特征以提取高级特征。CNN是许多计算机视觉任务的最先进模型。能量模型,包括深度信念网络(DBN)通常用于预训练其他模型,例如前馈模型。递归神经网络(RNN)广泛用于序列数据建模。机器翻译和语言建模是RNN的热门应用。
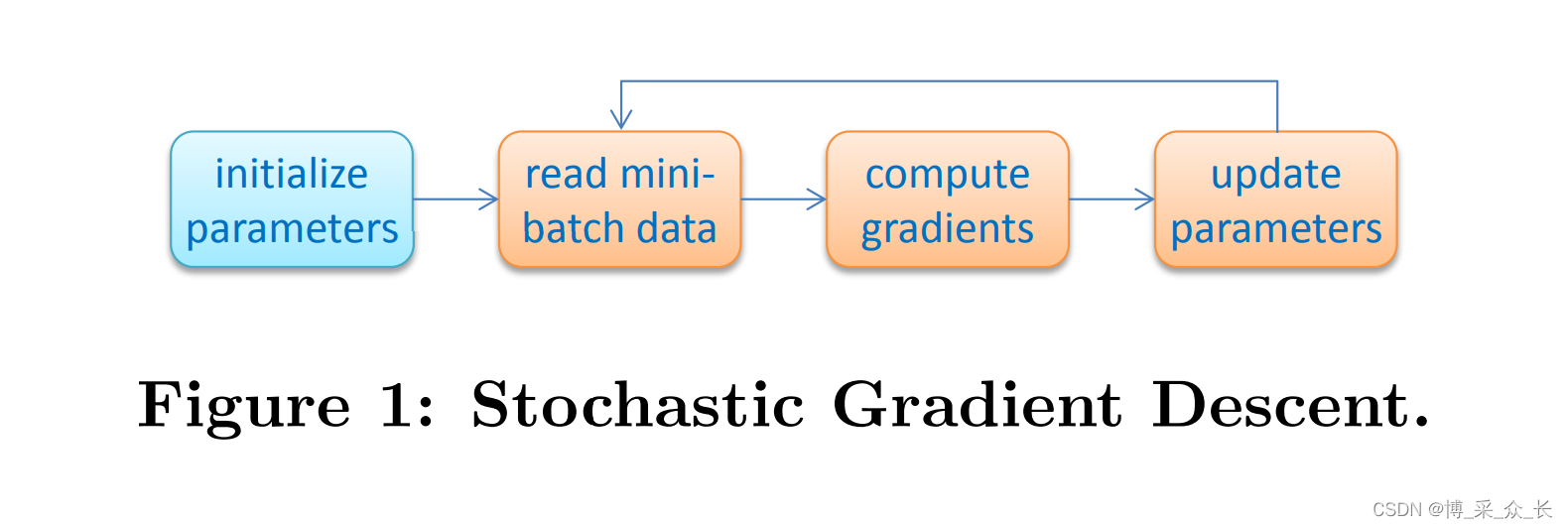
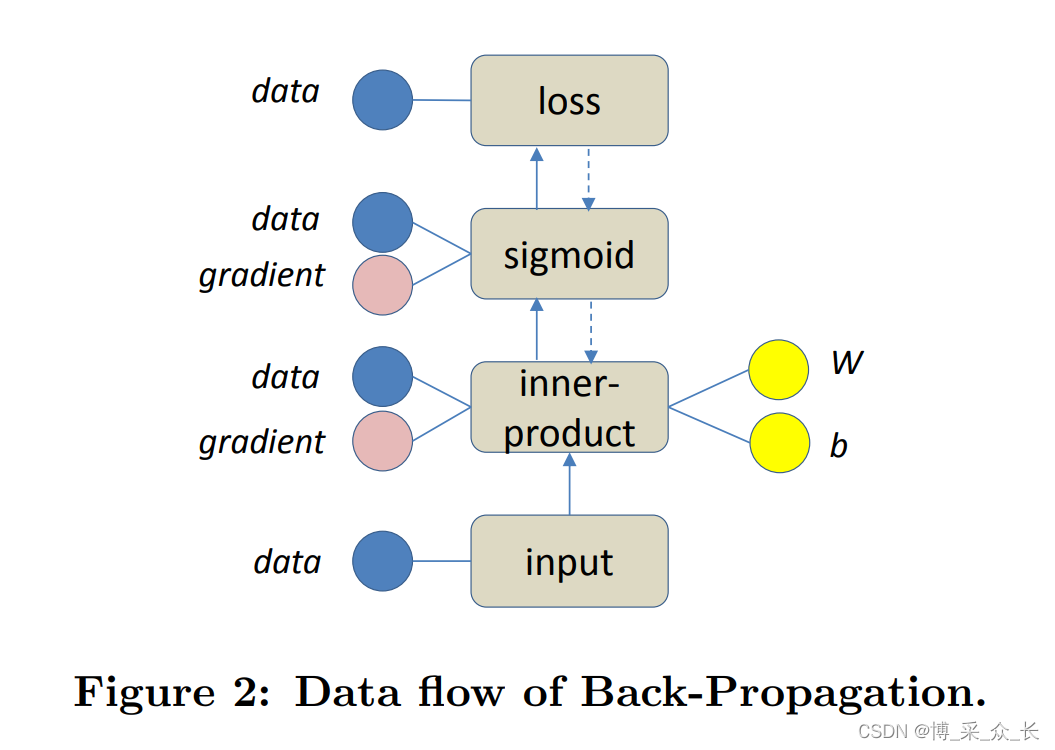
在部署深度学习模型之前,需要训练转换层中涉及的模型参数。训练结果证明是一个数值优化过程,以找到使预期输出和实际输出之间的差异(损失函数)最小化的参数值。随机梯度下降(SGD)是应用最广泛的训练算法。如图1所示,SGD使用随机值初始化参数,然后根据计算出的关于损失函数的梯度对其进行迭代优化。与上述三种模型类别相对应的梯度计算有三种常用算法:反向传播(BP)、对比散度(CD)和时间反向传播(BPTT)。通过将神经网络的层视为图的节点,可以通过按特定序列遍历图来评估这些算法。例如,BP算法如图2所示,其中一个简单的前馈模型通过沿实心箭头遍历来计算每个层的数据(特征),并沿虚线箭头来计算每个层的梯度和每个参数(W和b)。
3. DATABASES TO DEEP LEARNING
在本节中,我们将从数据库的角度讨论深度学习系统中使用的优化技术和研究机会。
3.1 Stand-alone Training
目前,提高深度学习模型训练速度的最有效方法是将Nvidia GPU与cuDNN库结合使用。
研究人员还在研究其他硬件,例如FPGA。除了利用硬件技术的进步外,操作调度和内存管理也是需要考虑的两个重要组成部分。
3.1.1 Operation Scheduling
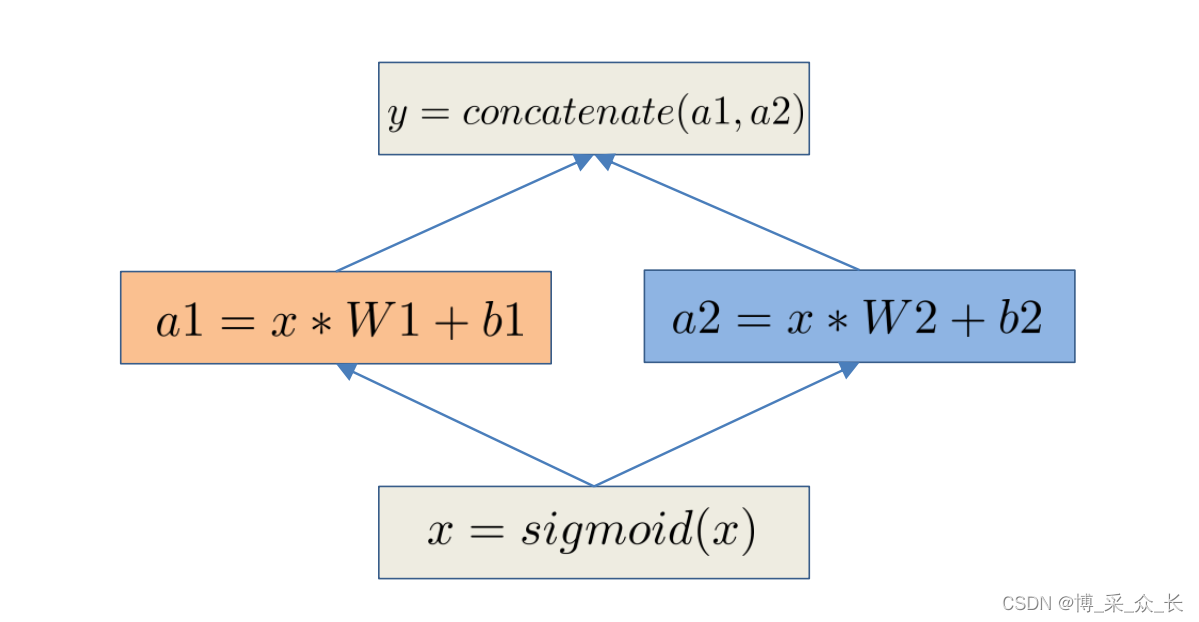
深度学习模型的训练算法通常涉及昂贵的线性代数运算,如图3所示,其中矩阵W1和W2可能大于4096∗4096,操作调度是首先检测操作的数据依赖性,然后将没有依赖性的操作放在执行器上,例如CUDA流和CPU线程。以图3中的操作为例,图3中的a1和a2可以并行计算,因为它们没有依赖关系。第一步可以基于数据流图静态完成,也可以通过分析读写操作的顺序动态完成。数据库在优化事务执行和查询计划方面也存在这种问题。深度学习系统应考虑这些解决方案。例如,数据库使用成本模型来估计查询计划。对于深度学习,我们还可以创建一个成本模型,在给定固定计算资源(包括执行器和内存)的情况下,为操作调度的第二步找到最佳操作放置策略。
3.1.2 Memory Management
深度学习模型越来越大,已经占据了大量的存储空间。例如,由于内存大小限制,VGG模型无法在普通GPU卡上训练。已经提出了许多减少内存消耗的方法。CUDA现在支持更短的数据表示,例如16位浮点。内存共享是节省内存的有效方法。以图3为例,sigmoid函数的输入和输出共享相同的变量,因此具有相同的内存空间。此类操作称为“就地”操作。最近,有两种方法被提出来权衡内存的计算时间。在GPU和CPU之间交换内存解决了GPU内存小和型号大的问题,方法是将变量交换到CPU,然后手动交换回来。另一种方法是丢弃一些变量以释放内存,并在必要时根据静态数据流图重新计算它们。
内存管理是数据库界的一个热门话题,对内存数据库进行了大量的研究,包括局部性、分页和缓存优化。更详细地说,分页策略对于决定何时以及交换哪个变量很有用。此外,数据库中的故障恢复类似于删除和重新计算方法,因此可以考虑数据库中的日志记录技术。如果记录了所有操作(和执行时间),那么我们就可以在没有静态数据流图的情况下进行运行时分析。其他技术,包括垃圾收集和内存池,对于深度学习系统也很有用,特别是对于GPU内存管理。
3.2 Distributed Training
分布式训练是加快深度学习模型训练速度的自然解决方案。通常使用参数服务器体系结构,其中工作人员计算参数梯度,服务器在从工作人员接收梯度后更新参数值。分布式训练有两种基本的并行方案,即数据并行和模型并行。在数据并行性中,为每个工作者分配一个数据分区和一个模型副本,而在模型并行性中,为每个工作者分配一个模型和整个数据集的分区。数据库社区在分布式环境方面有着悠久的工作历史,从并行数据库和对等系统到云计算。在以下段落中,我们将讨论与分布式训练产生的数据库相关的一些研究问题。
3.2.1 Communication and Synchronization
鉴于深度学习模型有大量参数,工作人员和服务器之间的通信开销可能是训练系统的瓶颈,尤其是当工作人员在GPU上运行时,这会减少计算时间。此外,对于大型集群,工作线程之间的同步可能非常重要。因此,研究单节点多GPU训练和大型集群训练的有效通信协议非常重要。可能的研究方向包括:a)压缩传输参数和梯度;b) 以优化的拓扑结构组织服务器,以减少每个节点的通信负担,例如树状结构和AllReduce结构(全对全连接);c) 使用更高效的网络硬件,如RDMA。
3.2.2 Concurrency and Consistency
并发性和一致性是数据库中的关键概念。对于深度学习模型的分布式训练,它们也很重要。目前,现有系统中都采用了声明式编程(如Theano和TenforFlow)和命令式编程(如Caffe和SINGA)来实现并发。大多数深度学习系统直接使用线程和锁。其他并发实现方法,如actor模型(擅长故障恢复)、协程和通信顺序进程,尚未得到探讨。
顺序一致性(来自同步训练)和最终一致性(来自异步训练)通常用于分布式深度学习。这两种方法都存在可伸缩性问题。最近,有研究使用值有界一致性模型来训练凸模型(深度学习模型是非线性和非凸的)。研究人员开始研究一致性模型对分布式训练的影响。关于如何为分布式训练提供灵活的一致性模型,以及每个一致性模型如何影响系统的可伸缩性,包括通信开销,还有很多研究要做。
3.2.3 Fault Tolerance
数据库系统通过日志记录(例如,命令日志)和检查点具有良好的耐用性。当前的深度学习系统主要基于检查点文件从崩溃中恢复训练。然而,频繁的检查点将产生巨大的开销。与在事务中强制执行严格一致性的数据库系统相比,深度学习训练系统使用的SGD算法可以容忍一定程度的不一致性。因此,日志记录不是必须的。如何利用SGD的特性和系统架构来有效地实现容错是一个有趣的问题。考虑到分布式训练将复制模型状态,因此可以从副本中恢复,而不是检查点文件。可以采用健壮的框架(或并发模型)如actor模型来实现这种故障恢复。
3.3 Existing Systems
表1列出了现有系统在上述优化方面的总结。许多研究人员已经通过特别的优化扩展了Caffe,包括内存交换和通信优化。然而,官方版本没有得到很好的优化。同样,Torch本身也为分布式培训提供了有限的支持。Mxne对内存和操作调度都进行了优化。Theano通常用于独立培训。TensorFlow具有基于数据流图进行上述静态优化的潜力。
我们正在从1.0版开始优化Apache孵化器SINGA系统。对于独立培训,探索运行时操作调度的成本模型。将使用内存池实现内存优化,包括丢弃、交换和垃圾收集。OpenCL支持在各种硬件上运行SIGA,包括GPU、FPGA和ARM。对于分布式培训,SINGA(V0.3)在灵活的并行性和一致性方面做了大量工作,因此重点将放在通信和容错的优化上,这在几乎所有系统中都是缺失的。

4. DEEP LEARNING TO DATABASES
深度学习应用程序,如计算机视觉和NLP,可能与数据库应用程序非常不同。然而,深度学习的核心思想,即特征(或表征)学习,适用于广泛的应用。直观地说,一旦我们对实体(例如图像、单词、表行或列)有了有效的表示,我们就可以计算实体相似度、按表聚类、训练预测模型,并用不同的模式重新检索数据等。下面我们将重点介绍一些可适用于数据库应用程序的深入学习模型。
4.1 Query Interface
几十年来,自然语言查询接口一直受到诱惑,因为它们非常受欢迎,特别是对于非专家数据库用户。然而,对于数据库系统来说,解释(或理解)自然语言查询的语义是一个挑战。最近,深度学习模型在NLP任务中取得了最先进的性能。此外,RNN已被证明能够学习结构化输出。作为一种解决方案,我们可以应用RNN模型来解析自然语言查询以生成SQL查询,并使用现有的数据库方法对其进行优化。例如,可以应用启发式规则来更正生成的SQL查询中的语法错误。挑战在于需要大量(标记的)训练样本来训练模型。一种可能的解决方案是用一个小数据集训练一个基线模型,并根据用户的反馈逐步完善它。例如,用户可以帮助更正生成的SQL查询,这些反馈基本上可以作为后续训练的标记数据。
4.2 Query Plans
查询计划优化是一个传统的数据库问题。当前大多数数据库系统都使用复杂的启发式和成本模型来生成查询计划。根据文献[17],参数化SQL查询模板的每个查询计划都有一个最优性区域。只要SQL查询的参数在这个区域内,最优查询计划就不会改变。换句话说,查询计划对输入参数的微小变化不敏感。因此,我们可以训练一个查询规划器,它从一组成对的SQL查询和可选计划中学习,为新的(类似)查询生成(类似)计划。为了进一步阐述,我们可以学习一个RNN模型,该模型接受SQL查询元素和元数据(如缓冲区大小和主键)作为输入,并生成一个表示查询计划的树结构。强化学习(如AlphaGo)也可以用于在线训练模型,使用执行时间和内存占用作为奖励。请注意,纯粹基于深度学习模型的方法可能不是很有效。特别是,训练数据集可能不全面,无法包含所有查询模式,例如,训练数据集中可能缺少一些谓词。要解决这些问题,更好的方法是将数据库解决方案与深度学习相结合。
4.3 Crowdsourcing and Knowledge Bases
许多众包和知识库应用涉及实体提取、消歧和融合问题,其中实体可以是数据库中的一行、图形中的一个节点等。随着NLP中深度学习模型的发展,考虑对这些问题进行深度学习是很合适的。特别是,我们可以学习实体的表示,然后使用所学习的表示进行实体关系推理和相似度计算。
4.4 Spatial and Temporal Data
空间和时间数据是数据库系统中常见的数据类型,通常用于趋势分析、进展建模和预测分析。空间数据通常通过将移动对象映射到矩形块来处理。如果我们将每个块视为一幅图像的一个像素,那么可以利用深度学习模型(如CNN)来提取相邻块之间的空间位置。例如,如果我们有移动物体的实时位置数据(如GPS数据),我们可以学习CNN模型来捕捉附近区域的密度关系,以预测未来时间点的交通拥堵。当时间数据被建模为时间矩阵上的特征时,可以设计深度学习模型(例如RNN)来建模时间依赖性并预测未来时间点的发生情况。一个特别的例子是基于历史医疗记录的疾病进展建模,医生希望估计已知疾病的某种严重程度的发病。
5. CONCLUSIONS
在本文中,我们讨论了数据库和深度学习。数据库有许多优化系统性能的技术,而深度学习擅长学习数据驱动应用程序的有效维护。我们注意到这两个“不同”领域共享一些提高系统性能的常用技术,如内存优化和并行。我们讨论了使用数据库技术对深度学习系统的一些可能改进,并研究了在数据库应用程序中应用深度学习技术的问题。让我们不要错过为未来激动人心的挑战做出贡献的机会!
6. ACKNOWLEDGEMENT
我们要感谢斯里瓦斯塔瓦的宝贵意见。这项工作得到了国家研究基金会(新加坡总理府)的支持,该基金会的竞争性研究计划(CRP奖项编号:NRF-CRP8-2011-08)。张美慧获得了SUTD启动再搜索拨款的支持,项目编号为SRG ISTD 2014 084。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









