





文章目录
论文地址
Abstract
优化配置对于数据库管理系统(DBMS)实现高性能至关重要。由于每个工作负载具有不同的模式和不同的资源需求,因此没有适用于不同工作负载的通用配置。配置、工作负载和系统性能之间存在关系。如果配置无法适应工作负载的动态变化,则DBMS的整体性能可能会显著下降,除非经验丰富的管理员不断重新配置DBMS。在本教程中,我们重点介绍了自主的工作负载感知性能调优,它有望随着工作负载的变化自动、连续地调优配置。我们综述了三个研究方向,包括1)工作负载分类、2)工作负载预测和3)基于工作负载的调优。前两个主题涉及获得准确的工作负载信息的问题,而第三个主题涉及如何正确使用工作负载信息来优化性能的问题。我们还确定了研究挑战和开放问题,并给出了在商业产品(如Amazon Redshift)中利用工作负载信息进行数据库调优的真实示例。我们将在演示中演示Amazon Redshift中的工作负载感知性能调优。
索引项工作量、分类、预测自治、DBMS、调优。
I. MOTIVATION
数据库配置,例如物理和逻辑设计以及资源分配(例如CPU、内存和IO资源),对于DBMS实现高性能至关重要。然而,数据的快速增长和时变工作负载的高度复杂性使得配置任务极具挑战性,尤其是当组织将其DBMS移动到云环境中的托管服务时。一个理想的解决方案是自治DBMS,它可以通过适应工作负载的变化来自动、不断地调整自身。
自治DBMS的行为可以使用以下公式描述,该公式演示了一种工作负载感知性能调优机制:
在配置包括硬件设置、软件设置、数据库物理和逻辑设计等的情况下,工作负载特征包括工作负载类型、工作负载转移、工作负载模式(例如,周期模式和到达模式),性能由一个指标(响应时间、吞吐量、可靠性等)或其组合来衡量。
然而,在自主DBMS的工作负载感知性能调优方法上存在(至少)三个重大挑战:(i)工作负载的多样性和异构性:DBMS可能有大量实例,每个实例可能包含各种类型的工作负载。不同类型具有不同的特性,例如,事务性工作负载由短时间运行的事务组成,这些事务修改了很少的记录,而分析性工作负载通常是处理大量数据的长时间运行的只读查询。(ii)工作负载的动态特征:随着新用户和应用程序的出现越来越频繁,工作负载的大小和模式可能会随着时间的推移而不断变化。例如,数据库可能会扩展到更多用户,从而以不可预测的方式向工作负载添加大量查询。当先前优化的配置无法满足传入查询的要求时,DBMS的性能可能会迅速下降。(iii)工作负载对性能的复杂影响:很难量化用于更改工作负载的硬件资源量,并确定给定工作负载对性能的影响程度。此外,搜索给定工作负载的最佳配置通常是一个NP难问题,因为解决方案位于高维连续空间。
表一总结了自治DBMS的工作负载感知性能调优的类别和文献。主要有三个主题:(i)工作量分类,(ii)工作量预测,和(iii)工作量调整。其目标是使DBMS能够通过分析不断变化的工作负载并为已识别的工作负载类型做出最佳决策,连续自动地调整数据库的配置。在本教程中,我们将首先提供自治DBMS的工作负载感知性能调优的概述和激励示例。接下来,我们将通过介绍每个类别的基本特征,介绍用于分类工作负载的不同类别、工作负载预测和工作负载感知调整方法。最后,我们将重点介绍用于工作负载感知调优的实际应用程序和系统,并确定研究挑战。
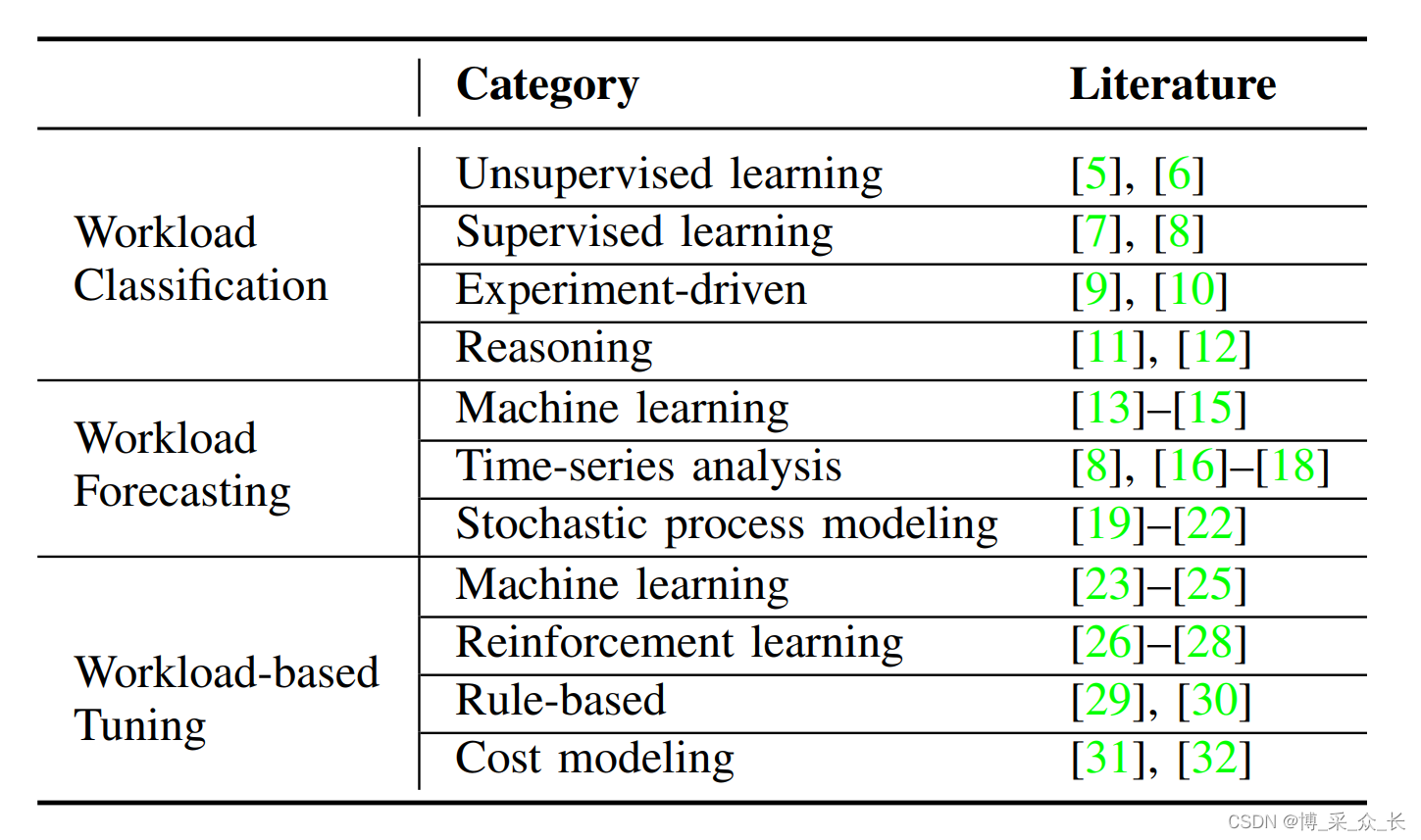
据我们所知,这是第一篇讨论自主DBMS负载感知性能调优方面最先进的研究和行业趋势的教程。以前的教程只关注数据库优化的一个方面(例如,自适应复制和分区、参数优化),而不考虑工作负载信息。另一方面,本教程重点介绍如何获取工作负载信息,并根据估计的工作负载调整DBMS。
II. TUTORIAL CONTENTS
本教程按六个部分的顺序组织,其内容总结如下。
A. Section I: Motivation and background
在本教程开始时,我们将回顾自主数据库调优的挑战,特别是云环境中时变工作负载的高度复杂性。自治DBMS需要根据动态工作负载信息进行自我调整,以获得最佳性能。
B. Section II: Workload Classification
实现自治DBMS的第一个也是关键的一步是能够准确地对工作负载进行分类,因为工作负载类型是数据库性能调优的重要标准。工作负载的类型可能包括在线分析处理(OLAP)、在线事务处理(OLTP)、决策支持系统(DSS)、商业智能(BI),甚至混合和交互工作负载(例如,同时运行并相互交互的混合快速事务和复杂分析查询)。
现有的分类方法可分为以下四类:(i)无监督学习:该方法的目的是通过利用一些度量(例如距离函数、资源使用)来衡量工作负载之间的相似性,将工作负载分组为一般类。例如聚类和半离散分解。(ii)监督学习:工作负荷分类可以通过机器学习模型来解决,例如分类回归树和决策树归纳。(iii)实验驱动:该方法利用实验技术,如规划实验和实验采样,识别工作负载类型并相应地重新配置资源。(iv)推理:工作量分类也可以通过与存储在案例库中的现有解决方案进行推理来解决。这种方法被称为基于案例的推理(CBR),它可以适应新的案例,并且不需要重新训练数据。
C. Section III: Workload Forecasting
现实世界中的数据库工作负载通常是动态变化的。为了完全自治,DBMS必须能够通过基于历史数据预测工作负载变化来处理动态工作负载。估计的工作量特征和变化可能包括:(i)查询的预期到达率,(ii)每个查询的运行时间,(iii)结构和周期模式,(iv)工作量变化,(v)下一个事务或查询,(vi)每个查询的内存使用情况等。
现有方法可分为以下三类,可用于预测上述特征:
- Machine learning: 工作量预测可以被视为一个分类或回归问题,其中数据驱动方法直接从观察数据预测工作量变化。代表性模型包括集成学习、深度Q网络和基于LSTM的自动编码器。
- Time-series analysis: 短期和长期工作负荷都可以视为一个时间序列,其未来值和周期可以通过时间序列分析技术进行估计,时间序列分析技术可以分为两个主要领域:
– 时域分析使用稀疏周期自回归(SPAR)、移动平均(MA)、多项式回归(PR)和自回归积分移动平均(ARIMA)等技术。
– 频域分析利用离散傅立叶变换(DFT)和区间分析等方法将工作量序列转移到频域,以发现一些复杂的周期模式。 - Stochastic process modeling: 与时间序列分析不同,随机过程模型侧重于工作负载的概率属性,例如马尔可夫属性。
D. Section IV: Workload-based Tuning and Scheduling
1) 基于工作负载的优化:最佳数据库物理和逻辑设计以及资源分配受到工作负载动态变化的严重影响。这是因为数据库(物理/逻辑)状态、工作负载和数据库资源之间存在某种关系。给定工作负载类型和变化,然后需要一个模型来决定调优操作。必须解决两个关键问题:1)如何提取和利用工作负载信息,以及2)如何找到最佳的调优操作(例如,哪种索引最有效,以及未来工作负载需要多少硬件资源)。
现有方法可分为以下四类:(i)机器学习:这些方法利用机器学习模型对查询进行编码并做出调整决策。例如深度神经网络、前馈神经网络和成对深度神经网络。(ii)强化学习:通过强化学习方法,如深度Q学习、深度确定性策略梯度和尝试出错策略,可以自然地调整数据库配置。(iii)基于规则:基于数据库引擎的领域知识或人类专家的经验,引入转换规则建模和规则层次,以确定资源需求或工作负载的最佳物理设计。(iv)成本建模:这些方法建立准确的预测模型,以评估不同配置的预期执行成本。代表作品包括[31]和[32]。
相应的调优任务包括两个主要方面:(i)数据库设计。根据工作负载的变化,数据库需要改进物理设计,如索引、物化视图、分区和存储,以实现最佳性能。有时,数据库还必须根据工作负载信息重新设计模式。(ii)资源供应。为了支持尚未在生产环境中部署的新工作负载,数据库必须估计所需的硬件资源,包括CPU、RAM、磁盘I/O、缓冲池大小和页面大小等。
2) 工作负载调度:工作负载调度旨在确定查询的执行顺序,也是一项关键且具有挑战性的任务。它会对查询性能和资源利用率产生重大影响。当前关于工作负载调度的技术包括基于机器学习的技术(如SmartQueue)和基于推理的技术(如Qshuffler)。
E. Section V: Real-World Applications
工作负载感知的性能调优广泛应用于像Amazon Redshift这样的云数据库中。Redshift在每个集群上训练预测模型,以便决策对于该集群服务的工作负载是最优的。为了具有更好的预测质量并考虑漂移,定期刷新底层模型。这些模型预测了工作负载中每个查询的查询执行时间和内存使用情况。有了这些知识,工作负载管理器(WLM)可以明智地做出调度和资源分配决策。例如,WLM为查询分配适当的内存量,以充分利用资源,并在执行时间方面将短期运行的查询安排在较长的查询之前。此外,当具有大量资源使用的长时间运行的查询阻止传入的短查询时,WLM将抢占长时间运行的查询,为短查询腾出空间。此外,当工作量很大且当前集群资源得到充分利用时,WLM将自动将查询扩展到新集群。
Amazon Redshift还通过监视查询模式来决定最佳的物理数据组织。分发密钥顾问使用组合优化技术推荐最佳数据分发,以最小化集群节点之间的网络通信。
F. Section VI: Open Problems
在本节中,我们将总结一些必须解决的开放问题,以确保工作负载感知调优的有效性:
- Robust workload classification and forecasting: 如何为有问题的工作负载(例如,嘈杂的工作负载模式)实现稳健的分类器和预测器。
- Tuning with inaccurate workload information: 即使工作量预测可能不准确,如何提高性能。
- Online update of tuning models: 如何在实际工业环境(例如,在云中)中部署新数据后,有效地重新培训和更新模型。
III. TUTORIAL ORGANIZATION
本教程计划3小时,分为以下几个部分:
Motivation (5’)
我们激发了对多个应用程序/场景进行工作负载感知性能调优的需求。
Workload classification (30’)
我们介绍了工作负荷分类的关键方法,并比较了不同类别之间的差异。
Workload forecasting (30’)
我们展示了如何使用工作量预测方法来预测各种参数。
Workload-aware tuning and scheduling (60’)
我们总结了基于工作负载的调优和工作负载调度的关键方法。
Real application and demonstration (30’)
我们讨论了工作负载感知性能调优的一些实际应用,并给出了一个演示来展示工作负载感知调优的流程。
Open problems (15’)
最后,我们讨论了工作负载感知调优的开放问题和挑战。
Summary (10’)
我们总结了本教程,并给出了对工作负载感知调优的批判性想法。
IV. GOALS OF THE TUTORIAL
A. Learning Outcomes
本教程的主要学习成果包括:(1)工作量感知调优的动机和背景。(2) 关于工作负载分类、工作负载预测和基于工作负载的调优的工作负载感知调优方法概述。(3) 比较这三个工作负载感知调优主题的特性、优势和应用。(4) 实现工作负载感知自治DBMS的附加信息,以及对研究挑战和开放问题的讨论。(5) 工作负载感知调优的实际演示。
B. Intended Audience
本教程面向从数据库系统研究人员到行业从业者的广泛受众,重点关注自动数据库调优。数据库工作负载和配置方面的基本知识足以学习本教程。有一些机器学习和强化学习技术的背景会很有用。
V. TUTORIAL PRESENTERS
Zhengtong Yan 是赫尔辛基大学的博士生。他的研究课题包括多模型自治数据库和跨模型查询优化。
Jiaheng Lu 是赫尔辛基大学的教授。他的主要研究兴趣在于数据库系统,特别是来自真实生活、海量数据存储库和Web的高效数据处理挑战。他写了四本关于Hadoop和NoSQL数据库的书,在SIGMOD、VLDB、TODS和TKDE等网站上发表了100多篇论文。
Naresh Chainani 是Amazon Web Services(AWS)的高级软件开发经理,负责查询处理、查询性能、分布式系统和工作负载管理。他热衷于构建易于使用的高性能数据库,并拥有多项论文和专利。
Chunbin Lin 是亚马逊网络服务(AWS)的软件工程师,他正在从事AWS红移。他在加州大学圣地亚哥分校完成了计算机科学博士学位。他的研究兴趣是分布式数据库管理和大查询分析。他在SIGMOD、VLDB、VLDB J和TODS等网站上发表了30多篇论文。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









