




 vCLIMB是一个针对视频类增量学习的基准,分析了深层模型在视频数据上的灾难性遗忘问题。文章提出了一种时间一致性正则化策略,以改善基于内存的方法在视频数据上的性能,尤其是在未修剪的视频上,能显著减少遗忘并提高24%的准确性。实验在多个数据集上展示了这种方法的有效性。
vCLIMB是一个针对视频类增量学习的基准,分析了深层模型在视频数据上的灾难性遗忘问题。文章提出了一种时间一致性正则化策略,以改善基于内存的方法在视频数据上的性能,尤其是在未修剪的视频上,能显著减少遗忘并提高24%的准确性。实验在多个数据集上展示了这种方法的有效性。
文章目录
vCLIMB: A Novel Video Class Incremental Learning Benchmark(cvpr2022 oral) - 论文链接
摘要
持续学习(CL)在视频域中探讨了不足。存在很少的工作包含在任务中划分不平衡的类分布,或者在不合适的数据集中研究问题。我们介绍了vCLIMB,这是一个新颖的视频持续学习基准。 vCLIMB是一个标准化测试平台,可分析视频持续学习中深层模型的灾难性忘记。与以前的工作不同,我们专注于按照一系列脱节任务进行训练的模型,并在整个任务中均匀分配类的数量。我们对vCLIMB中现有CL方法进行了深入的评估,并观察到视频数据中的两个独特挑战。在视频帧级别下选择在情景记忆中存储的实例。其次,未修剪的训练数据影响帧级采样策略的有效性。我们通过提出一个时间一致性正则化来解决这两个挑战,该正规化可以应用于基于内存的持续学习方法之上。我们的方法可显着提高基线,在未经修剪的持续学习任务最多可提高24%。
1.介绍
我们专注于CL:类增量学习(CIL)的特殊情况。借助庞大的视频数据,重要的是开发可以有效地从未修剪视频数据流中学习的模型。值得注意的是,很少有研究工作能够通过视频来解决持续的学习。首先,为了在使用内存的视频CIL方法之间进行公平的比较,我们将内存大小重新定义为帧总数。我们将其报告为表中的内存框架容量,以避免与图像CIL中定义的内存大小混淆。其次,由于细粒度的时间视频注释很昂贵(尤其是对于长视频),因此我们分析了在持续学习中使用修剪和未修剪的视频数据的效果。使用VCLIMB的数据拆分,我们通过调整知名的持续学习方法来建立一组初始基线。
1.1 主要贡献
(1)在视频动作识别中持续学习的标准化基准,该基准定义了三个视频数据集的训练协议和相关指标;这个新颖的持续学习设置包括修剪和未修剪视频的更现实的组合。 (2)我们从图像域到视频域重新提出并评估了四个基线方法。 (3)我们提出了一种基于一致性正则化的新型策略,该策略可以应用于基于内存的方法的顶部,以减少记忆消耗的同时改善性能。
2. 相关工作
持续学习到类增量学习相关介绍。CIL方法可以分为两个广泛的类别:基于正则化和基于内存的方法。
2.1 基于正则化方法
这些值通常在每个任务的末尾更新并存储在一个重要的矩阵中。松弛权重巩固(EWC)[17]使用Fisher信息矩阵来进行估计。内存感知突触(MAS)[1]通过测量参数的小变化如何影响模型的输出,以自我监督的方式估算每个参数的重要性。这些方法包括正则化因子λ,该因子控制了先前学习的任务的相关性。对于一个很大的因素,该模型将优先考虑当前任务。
2.2 基于内存的方法
我们专注于两种代表性方法,这些方法已证明可以与高分辨率图像数据集合作。增量分类器和表示学习(ICARL)[27]结合了排练和蒸馏策略。在训练期间,它选择了遵循样例平均最近规则的选择最具代表性的实例。偏置校正方法(BIC)[38]遵循ICARL的实例抽样方法,但使用偏置校正层增强了分类层。偏差校正可以减轻新任务中大量数据与以前任务的相对稀缺数据之间的不平衡,这仅在内存中可用。
2.3 一致性正则化
一致性正则化技术用于确保模型的输出对于各种增强是不变的,这在半监督学习中很常见。并且已经证明这种方法可以改善一些样本的生成。我们的工作调查了视频持续学习中的灾难性遗忘,并提出了一致性损失,以帮助记忆重放的方法大大减轻这种阻碍。
2.4 视频中的持续学习
Zhao等, [44]提出了一种时空知识转移策略,以减轻灾难性遗忘。同时工作[26]估计了特征通道的子集,该特征通道对先前任务的预测有最大的贡献,并引入了一个时序掩膜,该掩膜在学习新任务时保持该子集稳定。它还包括蒸馏损失,该蒸馏损失只允许在学习新任务时更新最不相关的功能图。最后,Ma等人,[24]还通过将连续任务中的特征空间正规化来解决类增量视频分类问题。
尽管现有工作引导了视频数据中持续学习的研究,但它们都使用不同的评估协议,使方法之间的直接比较变得困难。此外,这些作品建议用大量相同的数据分布(最多是总计的一半)预处理模型,如表1所示。这种安排对于持续学习是不自然的解开灾难性遗忘的影响。相反,我们的基准提出了更具挑战性和现实的设置。我们的拆分最多包含20个任务,每个任务都有平衡的类。此外,vCLIMB包括三个视频数据集,这可以在更多样化的情况下研究持续学习问题。最后,以前的作品没有对视频持续学习设置提供详细的分析。在我们的基准测试中,我们提供了广泛的经验评估,以分析单个部分并确定视频中连续学习的独特属性,包括记忆大小和采用未修剪的视频配置。
3. vCLIMB:一个视频类增量学习框架
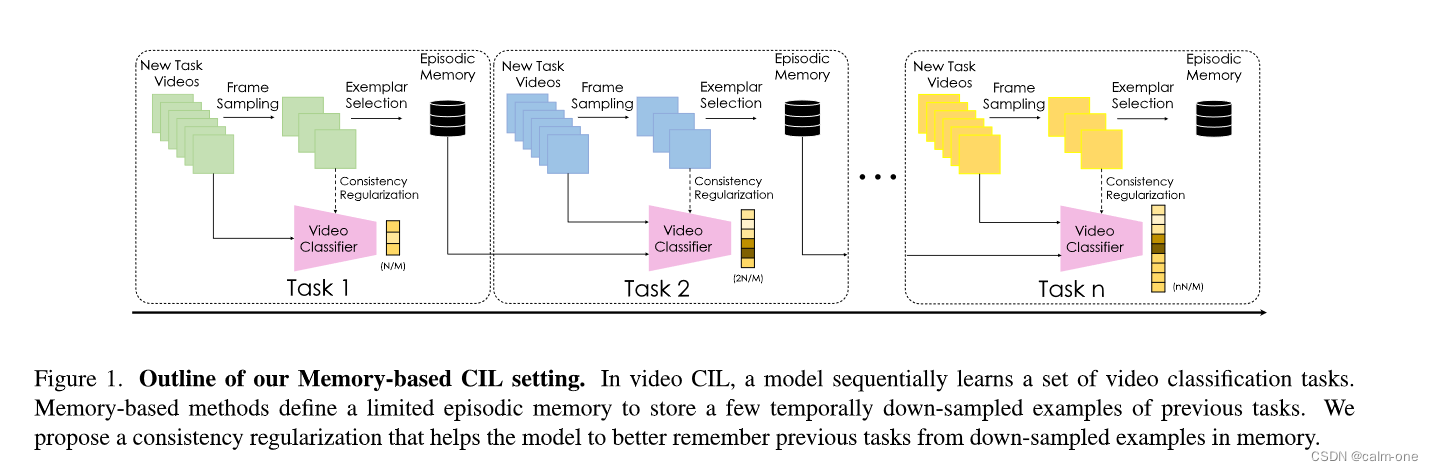
【问题定义】与图片域类似,在一系列任务中训练单个神经网络,每个任务中包含当前的训练数据,我们在单个任务中优化网络参数最大化平均准确率
【数据集和任务】UCF01、Kinetics、ActivityNet.同时在修剪的ActivityNet以及未修建的ActivityNet。我们为每个数据集创建两个不同的任务序列。第一个序列包含十个任务,第二个序列包含二十个任务。
【视频持续学习评价指标】最终的平均准确性(ACC)和向后遗忘(BWF)。
3.1 视频持续学习特有的挑战
视频CIL带来了独特的挑战。 (1)在图像域中开发的基于内存的方法无法扩展存储全分辨率视频,因此需要新的方法来选择代表性帧以存储在内存中。 (2)未修剪的视频的背景框架包含较少有用的信息,从而使选择过程更具挑战性。 (3)时间信息是视频数据所独有的,基于内存和正则化的方法都需要减轻遗忘,同时还可以从此时间维度中整合关键信息。这些挑战为VCLIMB的设计选择提供了信息。
【重新定义内存尺寸】重新定义内存大小。与类增量学习(CIL)的图像基准不同,我们的视频实例包含一个时间维度,其大小可能显示出很大的可变性。为了偏爱方法之间的公平比较,我们根据存储的帧来定义工作记忆大小。
【CIL的未修剪视频数据】在未修剪的分类环境中,感兴趣的动作可能在视频中的任何时间发生,其边界尚不清楚。此问题公式在图像分类域中没有直接的对应物。 ActivityNet的注释方案使我们能够分析此场景,以进行类增量学习。在ActivityNet中,视频包含一个或多个时间段,定义了动作实例的发生,而未标记的段则构成了一个背景集,该背景集未发生相关操作
【基线】我们实施和评估这四种连续的学习方法作为基准[1、17、27、38],因为它们被广泛使用且易于可扩展到视频域。我们还与基于天真的内存策略进行比较,该策略选择了随机的样本以创建内存。作为视频CIL基准测试的一部分,我们提供了这些方法的实现。
3.2 具有时间一致性正则化的较强基线
【时间一致性损失】在培训新任务时,每个视频(X)将通过时间下采样具有增强版本(Xd)。我们使用X和Xd对来计算网络f的单个正向通道的一致性损失Lc
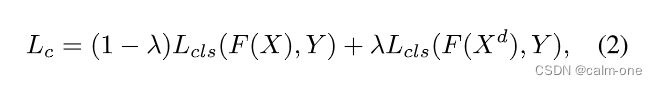
4.实验评估
现在,我们继续对VCLIMB中类持续学习任务进行实验评估。在本节中,我们首先讨论在视频域中连续学习的图像方法重新实现的详细信息。然后,我们在VCLIMB基准中包含的三个数据集上对这些基线方法进行经验评估:UFC101 [33],动力学[6]和ActivityNet [5]。对于ActivityNet数据集,我们还在修剪和未修剪的视频注释的情况下评估CIL任务。此外,我们在所有以前的方案和数据集中评估了提出的正则化方法的有效性。
4.1 视频类增量学习基线
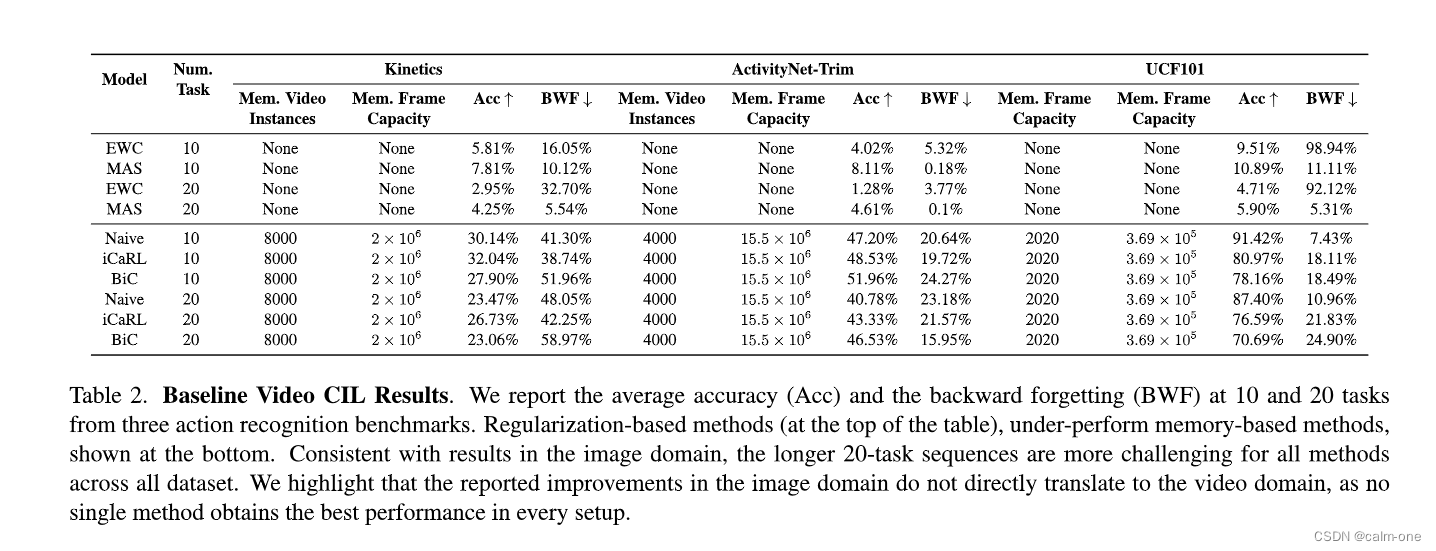
VCLIMB中的数据集的规模不同,因此我们根据其帧总数为每个数据集设置了不同的工作内存限制。对于每个数据集,我们对两种不同的拆分进行实验:10任任务拆分和20任任务拆分。在表2中,我们报告了使用每种方法的最佳超参数获得的结果。与图像类增量学习[14]一致,基于正则化的方法EWC [17]和MAS [1]显着落后于基于重播的方法,而与数据集的难度或任务数量无关。这是因为正则化方法仅对模型参数进行惩罚,因此在学习新任务和忘记旧任务之间经历了不可避免的权衡。如果使用较大的正则化参数来强调学习新任务,则忘记了增加,并且旧任务的平均准确性受到损害。如果使用较小的正则化参数来强调记住旧任务,则较新任务的准确性会受到损害。考虑到视频CIL的困难,这种局限性突出了将来探索更复杂的无内存方法策略的重要性。
【任务数量和遗忘】
我们观察到,较长(20任任务)序列是一个更具挑战性的设置,在三个数据集中的任何方法中,对于任何方法,平均精度始终均较低。遵循这种趋势,所有基于内存的方法忘记了更多,因为序列中的任务数量增加。与图像域类似,评估长长的任务序列会加剧CIL方法的缺点,因此适合于减轻遗忘的策略的研究。我们构成了10任任务和20任任务场景之间的遗忘差距,这是一个重要的研究方向。
【视频中记忆大小的相关性】
4.2 从下采样视频中记忆
主要从一下几个部分进行实验分析:
【Kinetics中一致性正则化】
【修剪的ActivityNet中一致性正则化】
【内存中多少帧应该被存储】
【UCF101中帧采样】
【UCF101视频类增量学习】
【未修剪视频的类增量学习】
【为什么一致性正则化有效】
5.总结
在本文中,我们建议和分析VCLIMB,这是视频动作识别的持续学习基准。我们公开并解决未研究的准确性下降,这是由基于内存的视频CIL模型所经历的,是由框架子采样引起的。在我们的实验中,我们均匀地对框架进行采样,并利用一致性损失显着缓解准确性下降,在CIL未修剪的视频分类中最多可减少24%。我们认为,探索非均匀抽样策略是另一个有希望的方向,但是我们为将来的工作留下了探索。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









