









0 回顾
用户级线程切换的核心就是,从一个栈变到两个栈,每个栈有自己的TCB,在切换的时候首先切换自己的TCB再切换栈,然后创建的时候就是将要切换的PC指针放到自己的栈中,然后再创建好TCB,将来在切换的时候,首先通过TCB一切换,再切换到相应的栈,然后从栈中弹出PC指针去执行。
- 为什么要讲线程?
- 本来要讲进程的切换,但是将进程的切换分为几个部分,切换指令,切换指令流以及切换资源,切换资源将会在内存管理当中进行,而切换指令流,实际上就是切换线程
- 进程必须在内核当中,所以切换进程实际上是切换内核级线程,但是切换用户级线程有助于对切换内核级线程的理解
- 为什么没有用户级进程,而进程都在内核里呢?
- 因为进程要分配资源,要访问内存,内存要访问文件,这些都是系统资源,计算机硬件,这些在用户态操作是不行的,必须到内核态才能操作
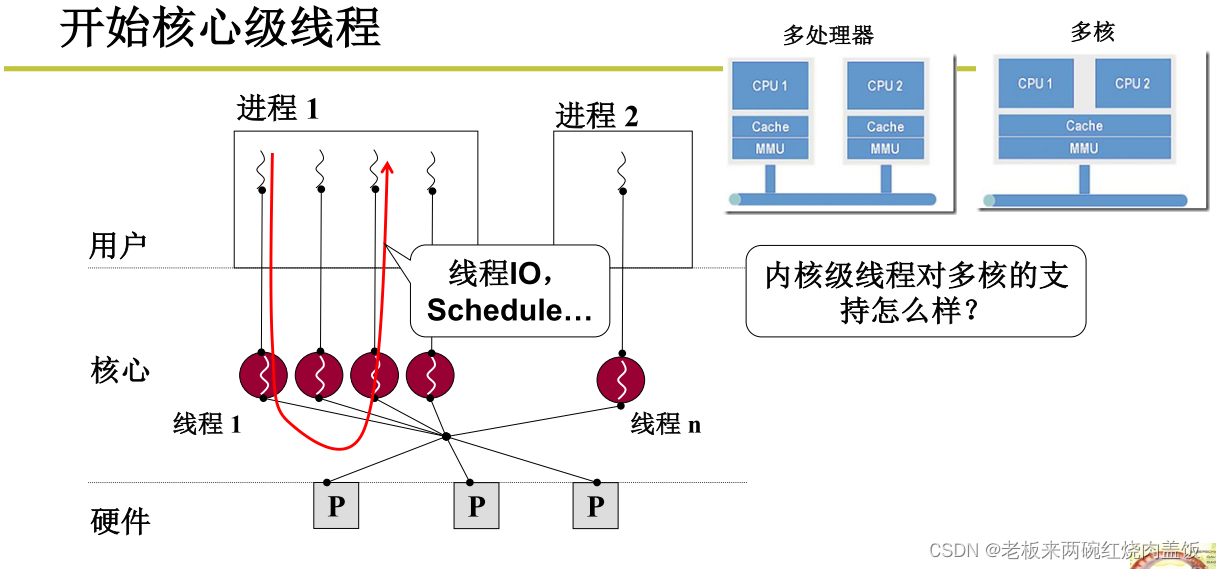
1 内核级线程
-
多处理器架构,每个处理器有自己的缓存、内存映射(MMU)
-
单个处理器多核架构,只有一套缓存+内存映射,有多个运算部件
-
这个架构仍然是现阶段个人PC最常见的
-
这不就正好对应了线程的概念吗?多个指令序列对应多个运算部件,一份资源对应一套缓存+内存映射
-
如果没有线程,只有多进程,那么MMU内存映射在多进程切换的时候就必须跟着切换,共享Cache、MMU就失去了意义
-
如果没有内核级线程,只有用户级线程,那么操作系统内核就无法感知这些线程,也就无法把这些线程分配到多个核上,多核就失去了意义
-
单处理器多核系统必须要实现内核级线程,因为只有进入到内核中,才可以将线程分配到不同的核心(运算部件)上
-
多核要想充分发挥作用,必须支持核心级线程
-
多核与多处理器的区别?
-
多处理器:每个CPU有自己的一套缓存寄存器( c a c h e cache cache)和映射( M M U MMU MMU)
-
多核:多个执行序列共用一套缓存寄存器( c a c h e cache cache)和映射( M M U MMU MMU)
-
多个线程可以使用多个核,所以多线程到内核里才能充分利用这个内核
-
以上是并行(你执行的时候我也执行)( 同时触发交替执行 同时触发交替执行 同时触发交替执行),与并发不同
-
并发:有处理多个任务的能力,但不一定得同时执行( 同时触发交替执行,只有一套资源 同时触发交替执行,只有一套资源 同时触发交替执行,只有一套资源)
-
所以多个内核级线程可以同时让多核并行起来(如果是用户级线程,那么操作系统是看不到的,所以不能分配硬件资源,因为核是操作系统管理的)
-
所以多进程无法充分发挥多核的价值,用户级线程也无法发挥多核的价值
-
所以内核级线程是有其优点的,可以发挥多核的价值
-
问:多进程无法充分发挥多核的价值?(查阅资料,觉得老师讲的太绝对了点)
-
答:
- linux下并未对进程线程分别做抽象,都是利用task_struct来描述具体调度的一个单元
- 也就是说创建进程、线程的时候其实都是调用的clone
- 如果clone传参共享资源则为创建线程反之则为进程
- 所以“多进程在多核上的情况”,其关键就在于MMU是否共享
- 具体参考i7存储系统框图,每个core都有一个MMU
1.1 内核级线程与用户级线程有什么不同?

- 用户级线程是每一个用户都有自己的栈,内核级线程是有两套栈
- 进入内核态,创建内核级线程,这就需要内核栈
- 但是回到用户态,也可以创建线程,这就是用户栈
- 所以是两套栈
- ThreadCreate是系统调用,内核管理TCB,内核负责切换线程
- 只要TCB同时关联用户栈和内核栈,那么内核级线程在切换的时候,切换TCB,就做到了同时切换用户栈和内核栈(往下看就知道,实际上是TCB关联内核栈内核栈又保存了同一个线程的用户栈的地址)
- 用户级线程切换:根据TCB切,然后根据TCB切换用户栈
- 内核级线程切换:根据TCB来切换一套栈,内核栈要切,用户栈也要切
1.2 内核栈
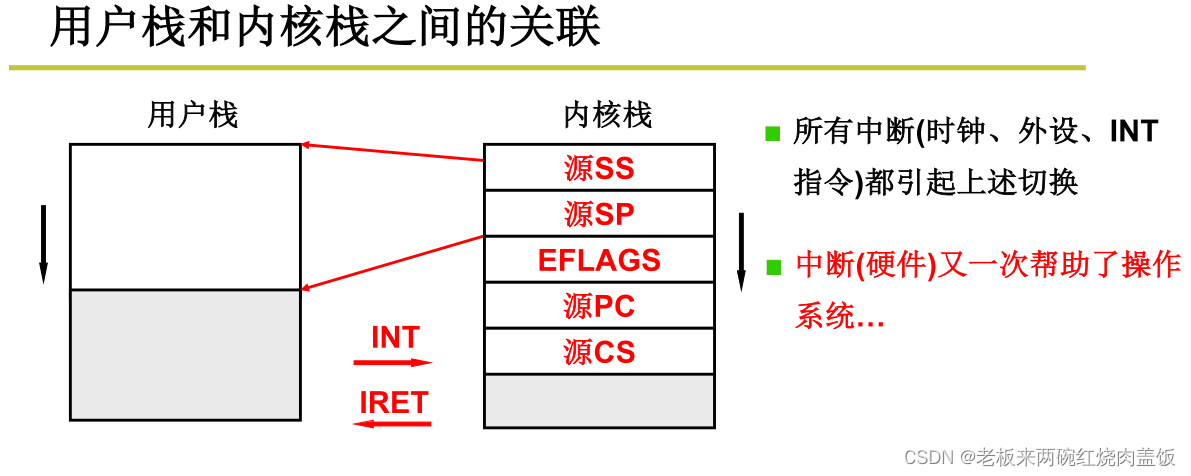
- 进入内核的时候,就要出内核栈
- 一旦有了中断,int,键盘鼠标之类的都会引起用户栈到内核栈的切换
- 只要一有中断,就启用内核栈
- 用户指令就是用户态,中断就是内核态
- 每个线程都对应一个用户栈和一个内核栈
- 进入内核要进行压栈,压什么呢?
- 压刚才用户态的ss和sp,cs和ip等,记录好现场,例如中断会保存现场
- 用户栈与内核栈之间的关联
- 从用户态进入内核态时(INT中断指令),需要在内核栈中先依次压入源SS、源SP、EFLAGS、源PC、源CS等内容
- 源SS和源SP是指向用户栈的指针,也就是说内核栈中存放了指向用户栈的指针
- 源PC和源CS是用户栈中的返回地址
- CS(Code Segment):代码段寄存器
- DS(Data Segment):数据段寄存器
- SS(Stack Segment):堆栈段寄存器
- SP(Stack Pointer ):栈指针
- ES(Extra Segment):附加段寄存器
- 从内核态返回用户态的时候(IRET中断返回指令),会从内核栈弹出这些信息,根据这些信息就可以恢复到用户栈
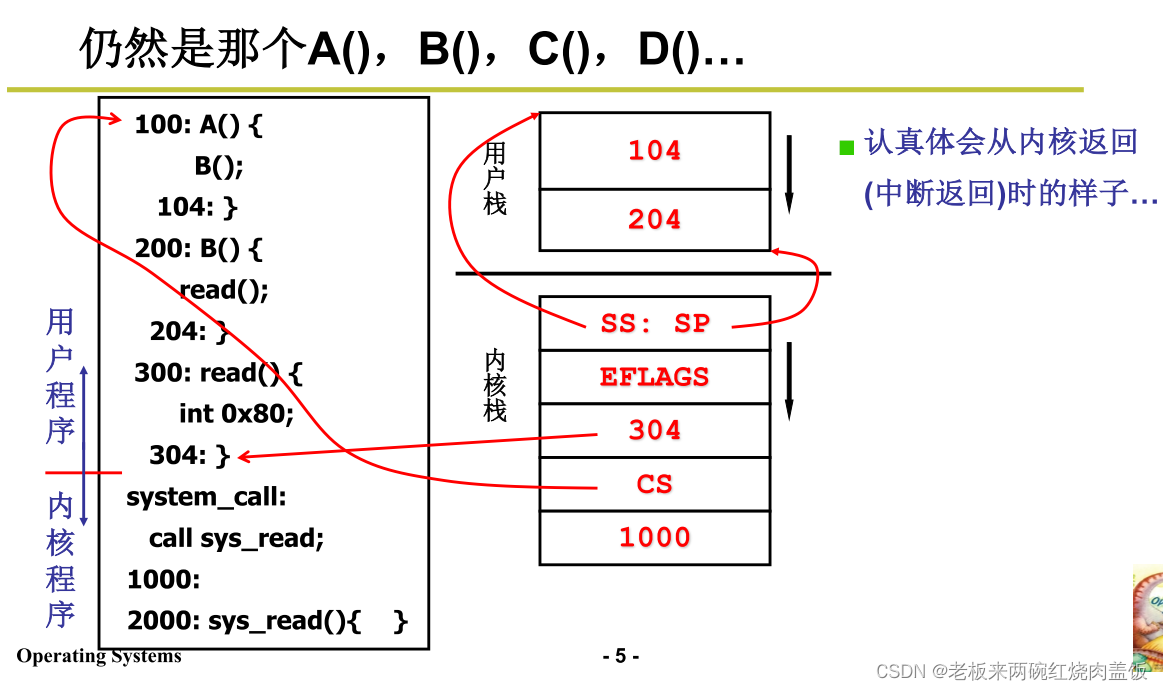
- 系统调用的例子说明用户栈和内核栈
- 如上图,内核栈按次序保存了
- SS:SP,指向用户栈的指针
- EFLAGS
- 304(IP),返回用户程序的偏移地址
- CS,返回用户程序的段基址100
- 系统调用返回(IRET)的时候,就会根据SS:SP切换回用户栈,根据CS:IP切换到用户程序的指令
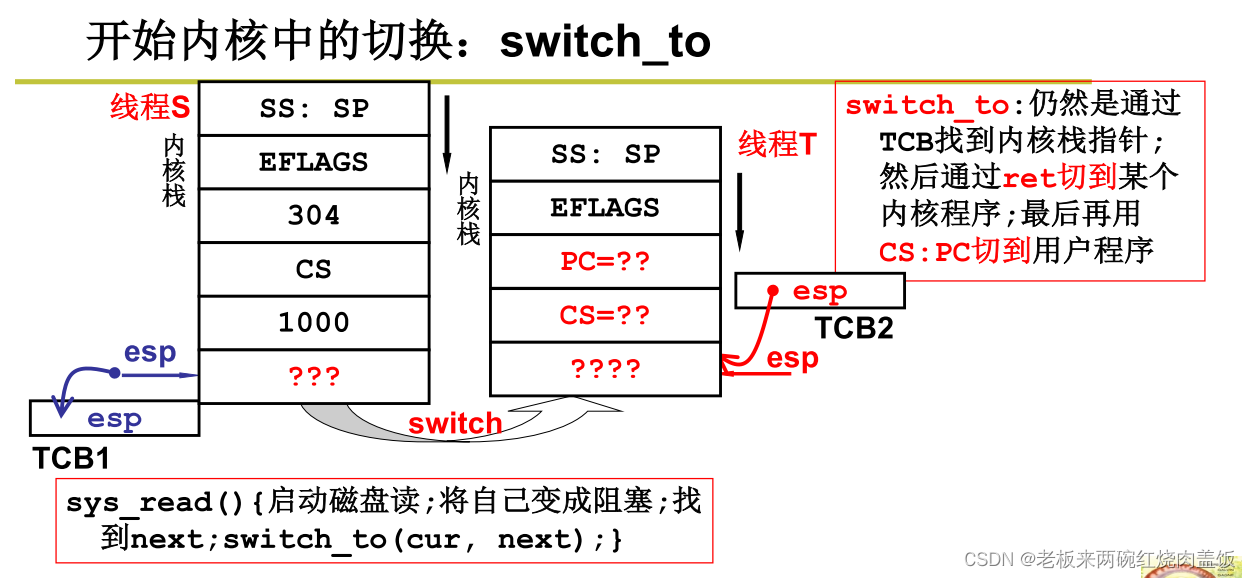
- 阻塞后找到下一个线程,next表示下一个线程的TCB,cur表示当前线程的TCB
- 找到TCB,根据TCB切换用户栈,然后根据栈里面的东西一弹,就切换了PC指针
- 现在的切换与用户态切换一样,仍然是用TCB找到栈指针,这个时候的指针应该是内核栈(因为进入了内核),找到了内核栈的指针,也就是说刚才在线程S当中执行,所以应该把esp指向当前的TCB当中,即cur,在下一个线程中会找到esp然后存入next当中
- 用当前的S线程的TCB,把当前S的栈顶地址esp存下来
- 存下来之后,进入到next下一个线程T
- 这时要把T线程的TCB中的栈顶地址拿出来赋给esp寄存器,这样才能把T线程的栈利用起来
- 总的来说
- 先调用next(),调度找到下一个占用CPU的内核级线程T(拿到了线程T的TCB)
- switch_to()中做了什么
-
- 在进入switch_to().之前,将s的返回地址压入S的内核栈中
-
- 切换TCB(TCBcur:=物理寄存器esp,物理寄存器esp=TCBnext)
-
- switch to()结束,则从T的内核栈中弹出一个地址,并跳转到这个地址,去执行T的内核代码
- 接着,T的内核代码不断运行,伴随着一些栈的操作,直到碰到RET指令(这就是老师PPT上的第二级切换),这个时候就根据内核栈中的CSIP切换回线程T的用户程序(用户态),根据SS:SP切换回用户栈
- 所以真正线程T的代码是在用户态的
- 疑问:这里举得是系统调用的例子,如果是其它中断,例如时间片到了触发的中断,会有细节上的区别吗?
1.3 四个问号

- 能从中断返回的代码意思是这里放了一个csip,这个csip指向某个中断返回程序
- 然后这里终端程序调用ret,会先返回到这四个问号指向的中断返回程序
- 而这个中断处理程序内又有一个iret,当执行了中断处理程序的iret后,程序才真正的被返回会用户栈
- 综上,利用中断进入内核,找到TCB,进入内核栈,内核栈的切换,再返回iret指令,把用户栈给切换过来,所以是从一套栈切换到另一套栈,这是两套栈的操作
1.4 五段论
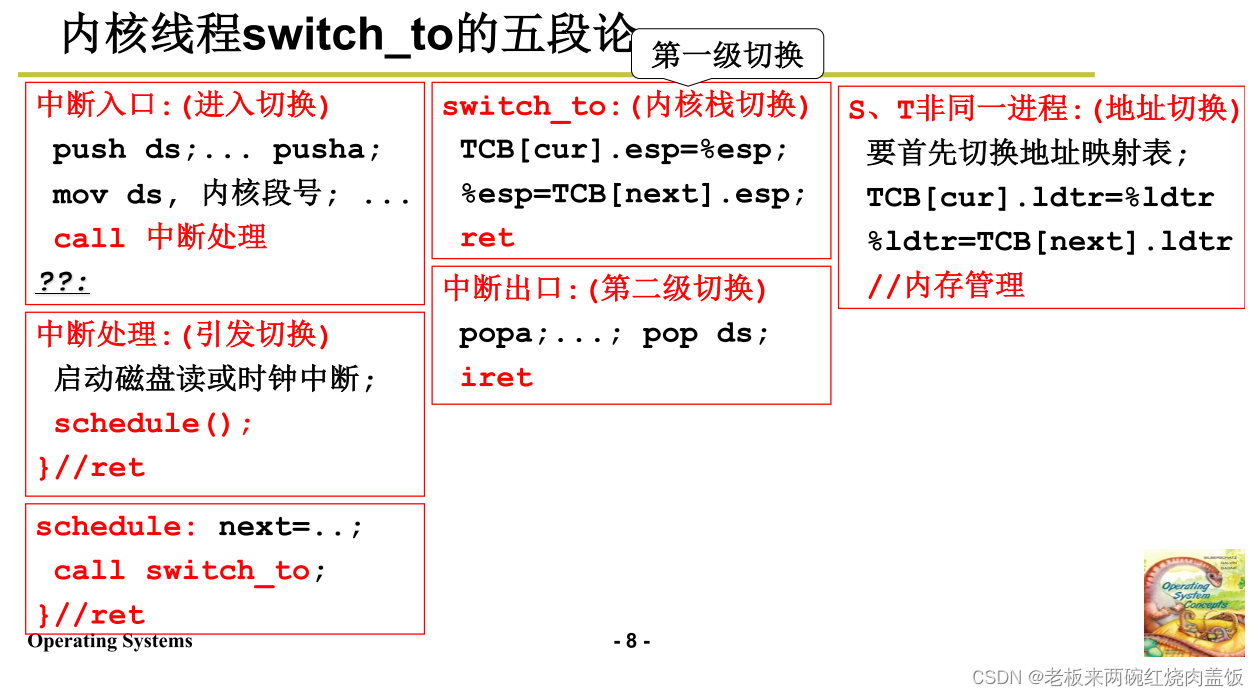
- 内核线程switch_to的五段论
- 这一段和上一段讲的实际上是一回事情,算是总结和补充
- 从用户代码到内核代码,可能是主动的系统调用,也可能是时钟中断(时间片轮转)等情况,不过本质上都是中断
- 在系统调用进入阻塞或者时间片轮转等情况下,会调用schedule()
- schedule()会首先调用next(),进行调度,找到下一个占用CPU的内核级线程
- schedule()然后调用switch_to(),进行内核级线程的切换(第一级切换)
- 在切换后的线程的内核态下执行指令,直到iret指令,会回到用户态(第二级切换)

- 需要注意如果S和T不属于同一进程,还需要切换资源,例如内存映射等,这个在内存管理里面讲
- linux0.11实际上是没有线程的,但是有进程的切换
- 内核级线程的切换再加上资源的切换(内存映射表)就是进程的切换,原理是差不多的,所以可以通过iux0.11的进程切换代码来学习
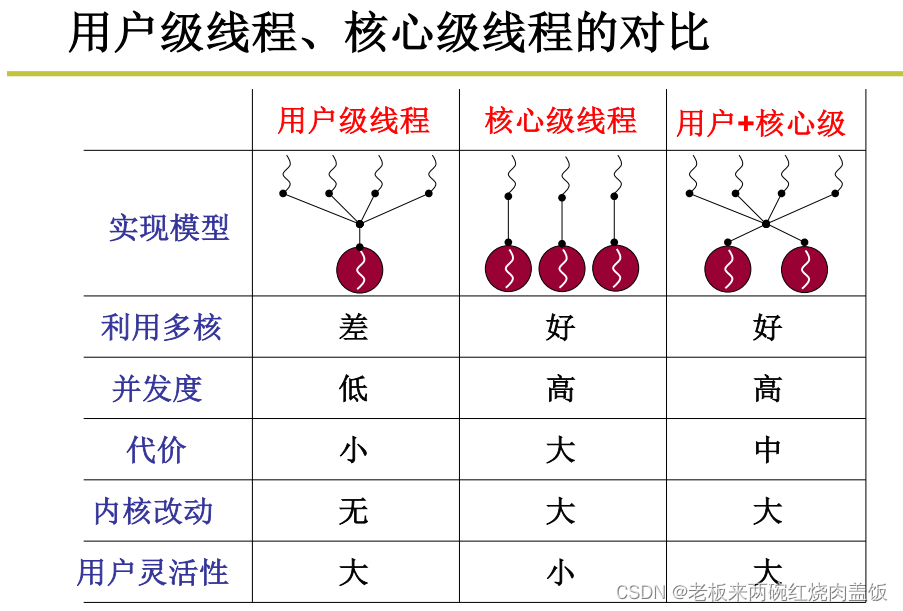
- 用户级线程、核心级线程的对北比,用户级线程和核心级线程搭配的效果最好
- 代价指的是,进入内核,会消耗系统资源?例如用户级线程完全不需要进入内核,也就不需要额外的内核数据结构,用户想起多少个用户级线程都行,就像浏览器想开多少个标签都行,如果用内核级线程来启动刘览器标签,那么启动多了之后就卡了
- 用户灵活性,用户级线程可以由用户自己实现调度,自己决定什么时候切换,而核心级线程的调度与切换是在内核中提前写好的
2 用户级,内核级线程的对比
3 总结
加油















 3515
3515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









