






基于集成学习方法Random Forest、Adaboost、GBDT、LightGBM、XGBoost的调参、建模、评估实现kaggle竞赛员工离职案例分析(2)
引言
接上一篇,本篇将会使用集成方法建模学习

3. adaboost模型分类
贝叶斯调参
from sklearn.ensemble import AdaBoostClassifier
from bayes_opt import BayesianOptimization
from sklearn.model_selection import cross_val_score
weak_classifier = DecisionTreeClassifier(criterion='gini',max_features= 0.9,splitter= 'best')
def rf_cv(n_estimators,learning_rate):
val = cross_val_score(
AdaBoostClassifier(base_estimator=weak_classifier,
n_estimators=int(n_estimators),
learning_rate=learning_rate
),
X_train, y_train, scoring='roc_auc', cv=5
).mean()
return val
rf_bo = BayesianOptimization(rf_cv,{'n_estimators': (10, 250),'learning_rate':(0.1,1.5)})
rf_bo.maximize()
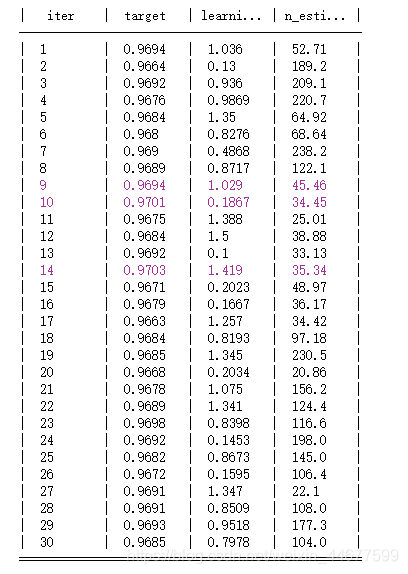
adaboost模型分类
# 这里需要注意基分类器不能更加细化,防止过拟合。
adaboost_model = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(criterion='gini',max_features= 0.9,splitter= 'best'),learning_rate= 0.8258,n_estimators=147)
adaboost_model.fit(X_train,y_train)
roc_auc_score(y_test,adaboost_model.predict(X_test))
0.9738830247104178
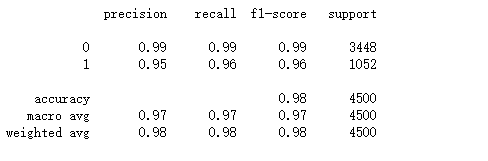
F1 分数
print(classification_report(y_test,adaboost_model.predict(X_test)))
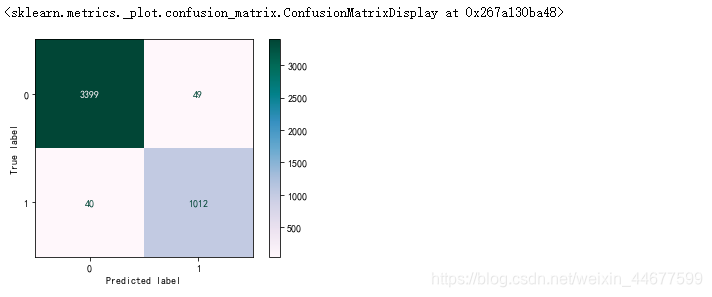
混淆矩阵
from sklearn.metrics import plot_confusion_matrix
plot_confusion_matrix(estimator=adaboost_model,X=X_test,y_true=y_test,cmap='PuBuGn')
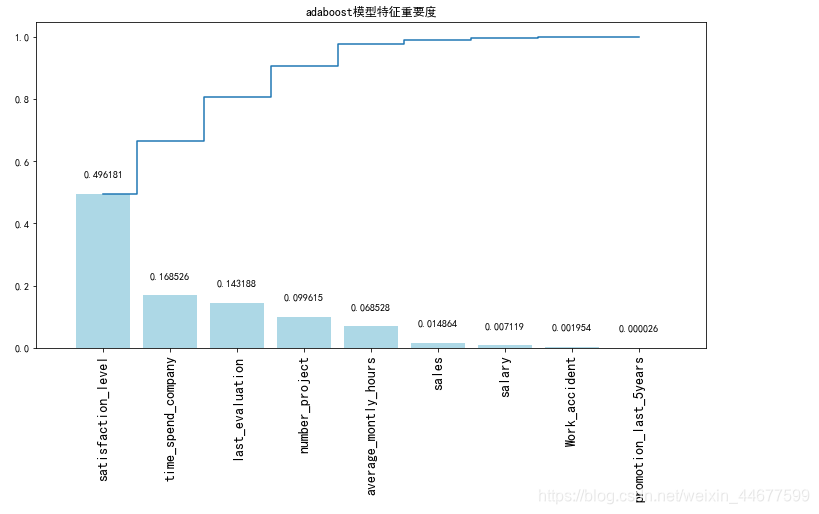
adaboost获取特征重要性
importances = adaboost_model.feature_importances_
# 获取特征名称
feat_names = x.columns
# 排序
indices = np.argsort(importances)[::-1]
# 绘图
plt.figure(figsize=(12,6))
plt.title("adaboost模型特征重要度")
plt.bar(range(len(indices)), importances[indices], color='lightblue', align="center")
# 添加数据标签
for a, b in zip(range(len(indices)), importances[indices]):
plt.text(a, b + 0.05, '%f' % b, ha='center', va='bottom', fontsize=10)
plt.step(range(len(indices)), np.cumsum(importances[indices]), where='mid', label='Cumulative')
plt.xticks(range(len(indices)), feat_names[indices], rotation='vertical',fontsize=14)
plt.xlim([-1, len(indices)])
plt.show()
4.GBDT模型分类
贝叶斯调参
from sklearn.ensemble import GradientBoostingClassifier
def rf_cv(n_estimators,learning_rate):
val = cross_val_score(
GradientBoostingClassifier(
n_estimators=int(n_estimators),
learning_rate=learning_rate
),
X_train, y_train, scoring='roc_auc', cv=10
).mean()
return val
rf_bo = BayesianOptimization(rf_cv,{'n_estimators': (10, 250),'learning_rate':(0.1,1.5)})
rf_bo.maximize()
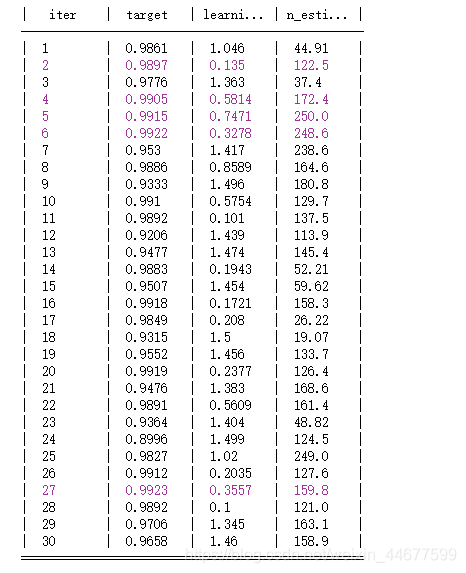
GBDT模型分类
gbdt_model=GradientBoostingClassifier(n_estimators=249,learning_rate=0.3278)
gbdt_model.fit(X_train,y_train)
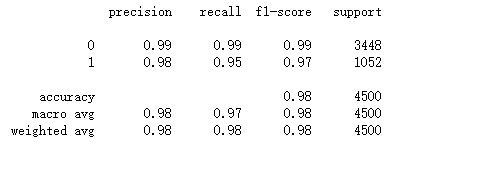
print(roc_auc_score(y_test,gbdt_model.predict(X_test)))
print(classification_report(y_test,gbdt_model.predict(X_test)))
0.9738510449657266
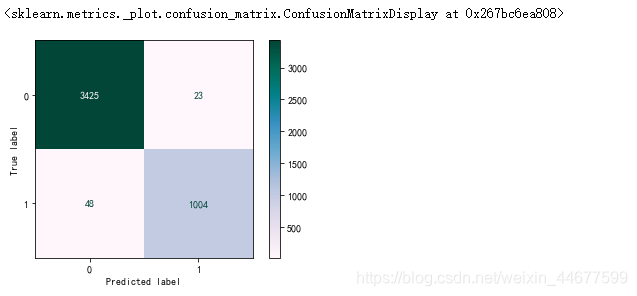
绘制混淆矩阵
from sklearn.metrics import plot_confusion_matrix
plot_confusion_matrix(estimator=gbdt_model,X=X_test,y_true=y_test,cmap='PuBuGn')
5. LightGBM分类(未调参)
import lightgbm as lgb
from sklearn.metrics import accuracy_score
lgb_param = {
'boosting_type': 'gbdt', # 设置提升类型
'objective': 'binary', # 目标函数
'metric': { 'auc'}, # 评估函数
'num_leaves': 31, # 叶子节点数
'learning_rate': 0.36, # 学习速率
'feature_fraction': 0.9, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'verbose': 1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
# 数据格式转换
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# 参数设置
boost_round = 50 # 迭代次数
early_stop_rounds = 10 # 验证数据若在early_stop_rounds轮中未提高,则提前停止
# 模型训练:加入提前停止的功能
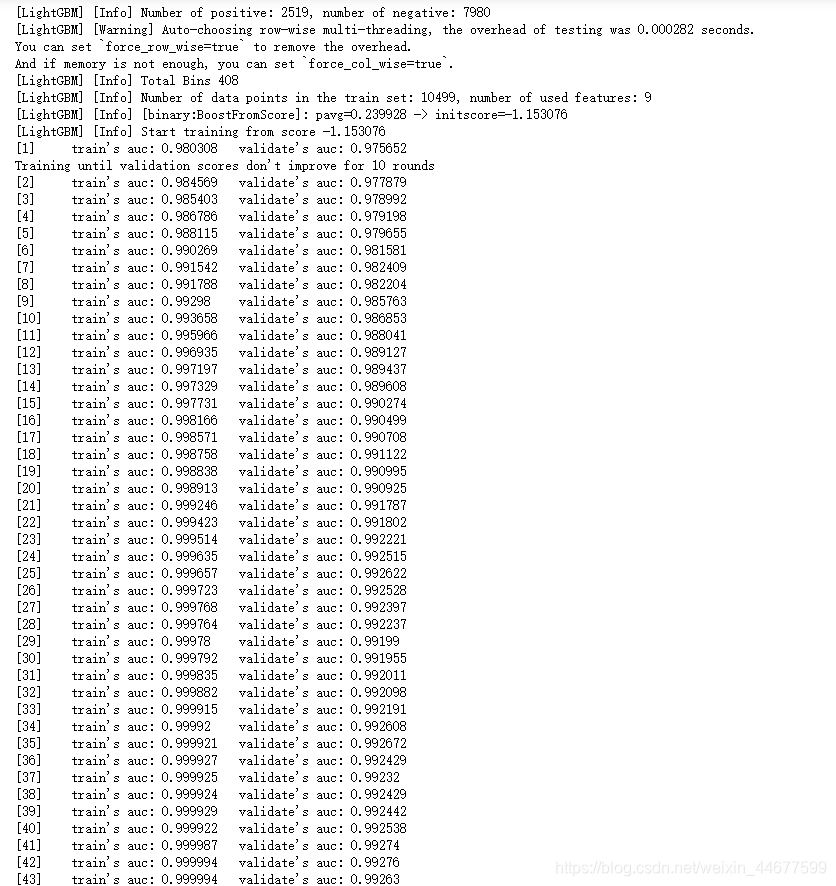
results = {}
gbm = lgb.train(lgb_param,
lgb_train,
num_boost_round= boost_round,
valid_sets=(lgb_eval, lgb_train),
valid_names=('validate','train'),
early_stopping_rounds = early_stop_rounds,
evals_result= results)
模型评估
lgb.plot_metric(results,xlim=(0,50),ylim=(0.975, 1))
plt.show()
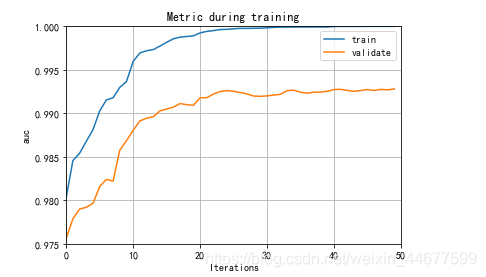
F1 分数
predictions_lgbm_prob = gbm.predict(X_test, num_iteration=gbm.best_iteration)
predictions_lgbm_01 = np.where(predictions_lgbm_prob > 0.5, 1, 0)
print(roc_auc_score(y_test,predictions_lgbm_01))
print(classification_report(y_test,predictions_lgbm_01))
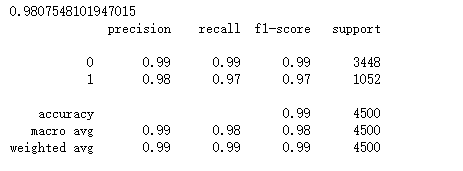
绘制重要的特征
lgb.plot_importance(gbm,importance_type = "split")
plt.show()
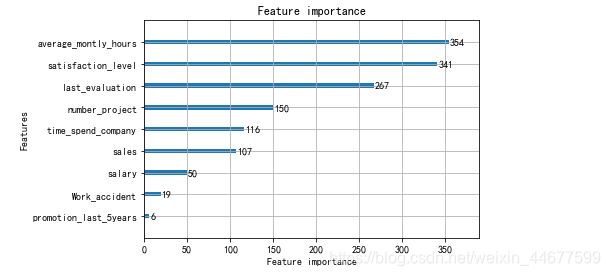
6. XGBoost分类
XGBoost调参
最佳迭代次数:n_estimators
from sklearn.model_selection import GridSearchCV
cv_params = {'n_estimators': [200,280,350]}
other_params = {'learning_rate': 0.1, 'n_estimators': 100, 'max_depth': 5, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1,'tree_method': 'gpu_hist' }
model = xgb.XGBClassifier(**other_params)
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=4)
optimized_GBM.fit(X_train, y_train)
evalute_result = optimized_GBM.cv_results_['mean_test_score']
print('每轮迭代运行结果:{0}'.format(evalute_result))
print('参数的最佳取值:{0}'.format(optimized_GBM.best_params_))
print('最佳模型得分:{0}'.format(optimized_GBM.best_score_))
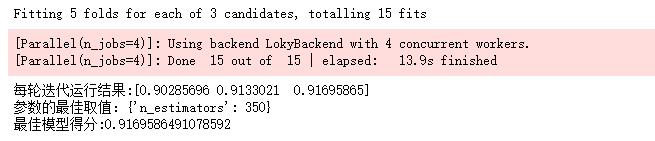
max_depth 和 min_weight 参数调优
cv_params = {'max_depth': [4,9,10], 'min_child_weight': [1,6]}
other_params = {'learning_rate': 0.1, 'n_estimators': 528, 'max_depth': 5, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1 ,'tree_method': 'gpu_hist'}
model = xgb.XGBClassifier(**other_params)
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=4)
optimized_GBM.fit(X_train, y_train)
evalute_result = optimized_GBM.cv_results_['mean_test_score']
print('每轮迭代运行结果:{0}'.format(evalute_result))
print('参数的最佳取值:{0}'.format(optimized_GBM.best_params_))
print('最佳模型得分:{0}'.format(optimized_GBM.best_score_))

gamma参数调优
cv_params = {'gamma': [0,0.1,0.5]}
other_params = {'learning_rate': 0.1, 'n_estimators': 1150, 'max_depth': 9, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
model = xgb.XGBClassifier(**other_params)
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=4)
optimized_GBM.fit(X_train, y_train)
evalute_result = optimized_GBM.cv_results_['mean_test_score']
print('每轮迭代运行结果:{0}'.format(evalute_result))
print('参数的最佳取值:{0}'.format(optimized_GBM.best_params_))
print('最佳模型得分:{0}'.format(optimized_GBM.best_score_))

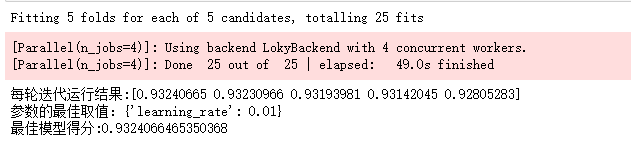
调整subsample 和 colsample_bytree 参数
cv_params = {'subsample': [0.75,0.8, 0.85], 'colsample_bytree': [0.85, 0.9,0.95]}
other_params = {'learning_rate': 0.1, 'n_estimators': 1150, 'max_depth':9, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
model = xgb.XGBClassifier(**other_params)
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=4)
optimized_GBM.fit(X_train, y_train)
evalute_result = optimized_GBM.cv_results_['mean_test_score']
print('每轮迭代运行结果:{0}'.format(evalute_result))
print('参数的最佳取值:{0}'.format(optimized_GBM.best_params_))
print('最佳模型得分:{0}'.format(optimized_GBM.best_score_))
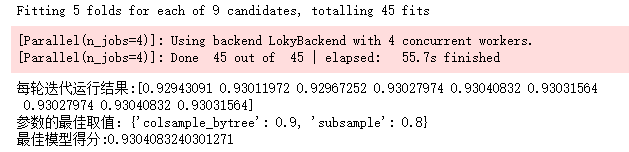
reg_alpha以及reg_lambda调参
cv_params = {'reg_alpha': [0.1, 0.2], 'reg_lambda': [1,1.5]}
other_params = {'learning_rate': 0.1, 'n_estimators': 1150, 'max_depth':9, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.9, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
model = xgb.XGBClassifier(**other_params)
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=4)
optimized_GBM.fit(X_train, y_train)
evalute_result = optimized_GBM.cv_results_['mean_test_score']
print('每轮迭代运行结果:{0}'.format(evalute_result))
print('参数的最佳取值:{0}'.format(optimized_GBM.best_params_))
print('最佳模型得分:{0}'.format(optimized_GBM.best_score_))
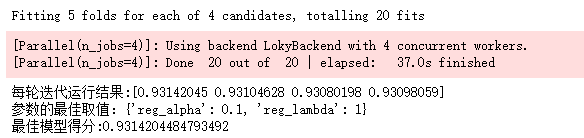
learning_rate,一般要调小学习率来测试
cv_params = {'learning_rate': [0.01, 0.05, 0.07, 0.1, 0.2]}
other_params = {'learning_rate': 0.1, 'n_estimators': 1150, 'max_depth':9, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.9, 'gamma': 0, 'reg_alpha': 0.1, 'reg_lambda': 1}
model = xgb.XGBClassifier(**other_params)
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=4)
optimized_GBM.fit(X_train, y_train)
evalute_result = optimized_GBM.cv_results_['mean_test_score']
print('每轮迭代运行结果:{0}'.format(evalute_result))
print('参数的最佳取值:{0}'.format(optimized_GBM.best_params_))
print('最佳模型得分:{0}'.format(optimized_GBM.best_score_))
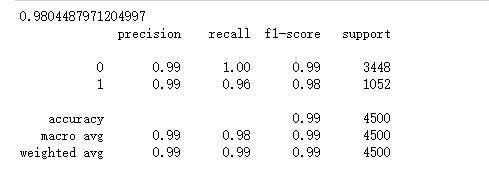
Xgboost分类
xgg_model = XGBClassifier(learning_rate=0.1, n_estimators=280, max_depth=25, min_child_weight=1, seed=0,
subsample=0.8, colsample_bytree=0.9, gamma=0, reg_alpha=0.1, reg_lambda=1)
xgg_model.fit(X_train, y_train)

# 对测试集进行预测
ans = xgg_model.predict(X_test)
print(roc_auc_score(y_test,ans))
print(classification_report(y_test,ans))
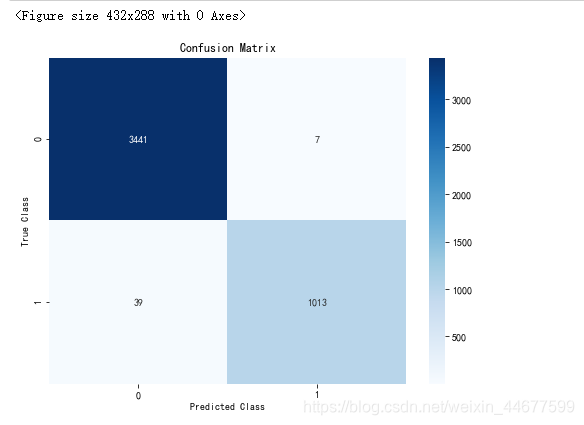
混淆矩阵
plt.figure()
cm = confusion_matrix(y_test,ans)
plt.figure(figsize=(8,6))
sns.heatmap(cm, annot = True, fmt='d', cmap="Blues", vmin = 0.2)
plt.title('Confusion Matrix')
plt.ylabel('True Class')
plt.xlabel('Predicted Class')
plt.show()
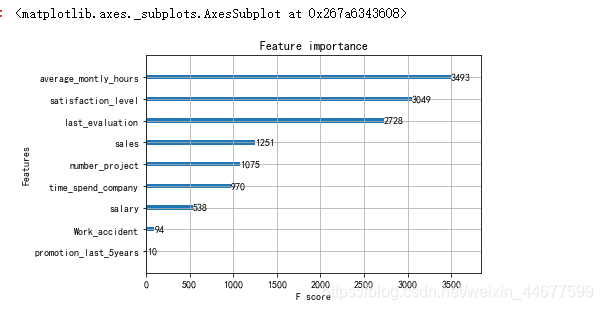
特征重要度
xgb.plot_importance(xgg_model)
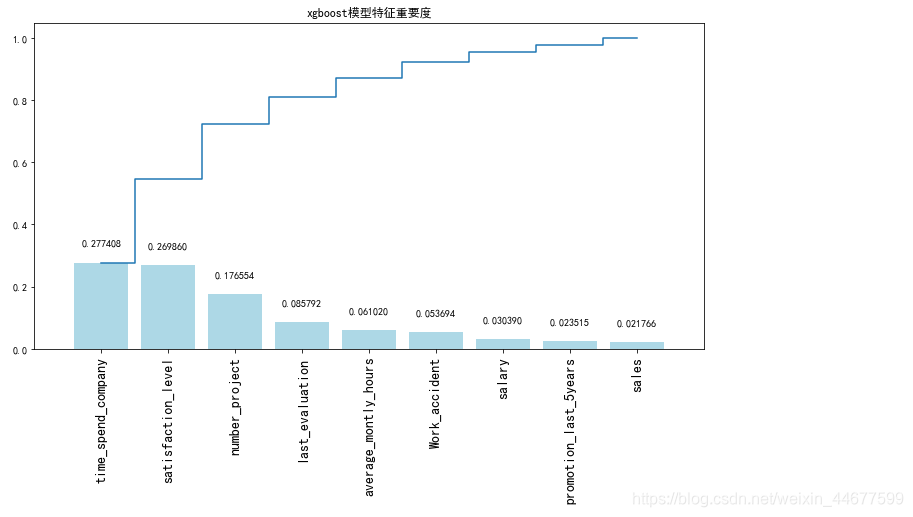
importances = xgg_model.feature_importances_
# 获取特征名称
feat_names = x.columns
# 排序
indices = np.argsort(importances)[::-1]
# 绘图
plt.figure(figsize=(12,6))
plt.title("xgboost模型特征重要度")
plt.bar(range(len(indices)), importances[indices], color='lightblue', align="center")
# 添加数据标签
for a, b in zip(range(len(indices)), importances[indices]):
plt.text(a, b + 0.05, '%f' % b, ha='center', va='bottom', fontsize=10)
plt.step(range(len(indices)), np.cumsum(importances[indices]), where='mid', label='Cumulative')
plt.xticks(range(len(indices)), feat_names[indices], rotation='vertical',fontsize=14)
plt.xlim([-1, len(indices)])
plt.show()
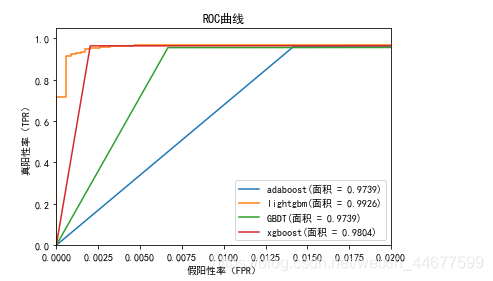
比较adaboost,lightgbm,GBDT,xgboost
ROC曲线
# 计算ROC曲线
ad_fpr, ad_tpr, ad_thresholds = roc_curve(y_test, adaboost_model.predict(X_test))
gb_fpr, gb_tpr, gb_thresholds = roc_curve(y_test, gbm.predict(X_test))
gbdt_fpr, gbdt_tpr, gbdt_thresholds = roc_curve(y_test, gbdt_model.predict(X_test))
xg_fpr, xg_tpr, xg_thresholds = roc_curve(y_test, xgg_model.predict(X_test))
plt.figure()
# adaboost ROC
plt.plot(ad_fpr, ad_tpr, label='adaboost(面积 = %0.4f)' % roc_auc_score(y_test,adaboost_model.predict(X_test)))
# lightgbm ROC
plt.plot(gb_fpr, gb_tpr, label='lightgbm(面积 = %0.4f)' % roc_auc_score(y_test,gbm.predict(X_test)))
# GBDT ROC
plt.plot(gbdt_fpr, gbdt_tpr, label='GBDT(面积 = %0.4f)' % roc_auc_score(y_test,gbdt_model.predict(X_test)))
# xgboost ROC
plt.plot(xg_fpr, xg_tpr, label='xgboost(面积 = %0.4f)' % roc_auc_score(y_test,xgg_model.predict(X_test)))
# 绘图
plt.xlim([0.0, 0.02])
plt.ylim([0.0, 1.05])
plt.xlabel('假阳性率(FPR)')
plt.ylabel('真阳性率(TPR)')
plt.title('ROC曲线')
plt.legend(loc="lower right")
plt.show()
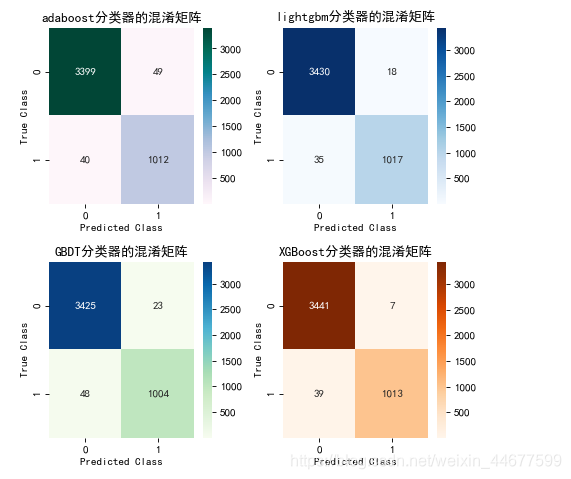
比较混淆矩阵
plt.figure(figsize=(6,6), dpi=80)
plt.figure(1)
ax1 = plt.subplot(221)
c1 = confusion_matrix(y_test,adaboost_model.predict(X_test))
sns.heatmap(c1,annot = True, fmt='d', cmap='PuBuGn', vmin = 0.2)
plt.title('adaboost分类器的混淆矩阵')
plt.ylabel('True Class')
plt.xlabel('Predicted Class')
ax2 = plt.subplot(222)
c2 = confusion_matrix(y_test,predictions_lgbm_01)
sns.heatmap(c2,annot = True, fmt='d', cmap='Blues', vmin = 0.2)
plt.title('lightgbm分类器的混淆矩阵')
plt.ylabel('True Class')
plt.xlabel('Predicted Class')
ax3 = plt.subplot(223)
c3 = confusion_matrix(y_test,gbdt_model.predict(X_test))
sns.heatmap(c3,annot = True, fmt='d', cmap='GnBu', vmin = 0.2)
plt.title('GBDT分类器的混淆矩阵')
plt.ylabel('True Class')
plt.xlabel('Predicted Class')
ax4 = plt.subplot(224)
c4 = confusion_matrix(y_test,xgg_model.predict(X_test))
sns.heatmap(c4,annot = True, fmt='d', cmap='Oranges', vmin = 0.2)
plt.title('XGBoost分类器的混淆矩阵')
plt.ylabel('True Class')
plt.xlabel('Predicted Class')
plt.tight_layout()
多数/硬投票
from sklearn.ensemble import VotingClassifier
eclf = VotingClassifier(estimators=[('adaboost', adaboost_model), ('GBDT', gbdt_model), ('XGBoost', xgg_model)], voting='hard')
for clf, label in zip([adaboost_model, gbdt_model,xgg_model,eclf], ['adaboost', 'GBDT', 'XGBoost', 'Ensemble']):
scores = cross_val_score(clf, X_test, y_test, cv=5, scoring='accuracy')
print("Accuracy: %0.5f (+/- %0.5f) [%s]" % (scores.mean(), scores.std(), label))















 1546
1546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









