







3.0.逻辑回归解决多元分类
1)题目:
在本次练习中,你将使用逻辑回归和神经网络来识别手写数字(从0到9)。今天,自动手写数字识别被广泛使用,从识别信封上的邮政编码到识别银行支票上的金额。这个练习将向您展示如何将您所学的方法用于此分类任务。在第一部分中,将扩展以前的逻辑回归,并将其应用于one-vs-all分类。
关于数据:本次的数据是以.mat格式储存的,mat格式是matlab的数据存储格式,按照矩阵保存,与numpy数据格式兼容,适合于各种数学运算,因此这次主要使用numpy进行运算。ex3data1中有5000个训练样例,其中每个训练样例是一个20像素×20像素灰度图像的数字,每个像素由一个浮点数表示,该浮点数表示该位置的灰度强度。每个20×20像素的网格被展开成一个400维的向量。这些每个训练样例都变成数据矩阵X中的一行。这就得到了一个5000×400矩阵X,其中每一行都是手写数字图像的训练样例。训练集的第二部分是一个包含训练集标签的5000维向量y,“0”的数字标记为“10”,而“1”到“9”的数字按自然顺序标记为“1”到“9”。
数据集链接: https://pan.baidu.com/s/1cEgQIvehUcLxZ0WVhxcPuQ 提取码: xejn
2)知识点概括:
- 西瓜书上说多元分类的基本思路为拆解法,即将多分类任务拆为若干个二分类任务求解。最经典的拆分策略有三种:一对一(OvO)、一对其余(OvR)和多对多(MvM)。我们这里用的是One-vs-all,也就是一对其余。
- 大概意思是把每个分类分别当做1,不是这个分类的当做0,进行上次作业中的逻辑回归的二分类任务,除了这一点其余完全和上次作业类似。如果具体算法忘了可以参考
吴恩达|机器学习作业2.1正则化的Logistic回归
3)大致步骤:
首先用scio.loadmat读取mat数据,分别将训练样例和训练集标签设置为x和y。再从x中随机选择100行数据进行可视化。之后再分别计算不带正则化和带正则化的代价函数和梯度,这里可以直接用ex2.1中写好的函数。然后进行一对多分类,利用for循环对每种数字习得一个带正则的逻辑回归分类器,然后将10个分类器的参数组成一个参数矩阵all_theta返回。最后得到一个5000乘10的预测概率矩阵,找到每一行的概率最大的值,看这个值的位置,得到预测的类别,再和期望值y进行比较,得到精度。
4)关于Python:
- scipy.io库可以进行mat格式的数据读写,读取mat后,data为dict格式,主要另外添加了一些附加头信息。
- np.random.choice只能从一维数组里面随机选,可能是因为我自己没有找到从高维数组里面选的函数(要是某位大神看到可以留言教一下我~),因此先用np.random.permutation产生一个随机打乱的数组而不重新洗牌x(shuffle函数是重新洗牌),再进行选取。
- plt.figure( ) 相当于创建了一个画布,括号里面代表了画布的编号,使用subplot( nrows, ncols ) 可以在画布上划分为nrows * ncols个子图,imshow可以在每个子图上画出数字,注意这里reshape了每个训练样例之后需要进行转置,图像才能显示正常,可能和数据有关。
- 我之前一直以为array和matrix可以通用,因为都可以返回shape,但是在写一对多分类函数时发现不行,(401, ) 和 (401,1) 不是一样的,前面一种情况一般是对一维数组求shape,这时对它求转置是不起作用的,如果想要转置的话必须换成矩阵的格式,可以用np.mat转换。
- np.unravel_index( )的作用是返回查找值的坐标,np.argmax( ) 的作用是返回矩阵中的最大值,因此套用起来np.unravel_index(np.argmax(prob[i,:]), prob[i,:].shape)就可以查找第i行的最大值并返回它所在的位置坐标。
5)代码与结果:
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as scio #读取mat文件
import scipy.optimize as opt
data = scio.loadmat('ex3data1.mat')
x = data['X']
y = data['y']
'''数据可视化'''
s = np.random.permutation(x) #随机重排,但不打乱x中的顺序
a = s[:100,:] #选前100行,(100, 400)
#定义可视化函数
def displayData(x):
plt.figure()
n = np.round(np.sqrt(x.shape[0])).astype(int)
#定义10*10的子画布
fig, a = plt.subplots(nrows=n, ncols=n, sharex=True, sharey=True, figsize=(6, 6))
#在每个子画布中画出一个数字
for row in range(n):
for column in range(n):
a[row, column].imshow(x[10 * row + column].reshape(20,20).T, cmap='gray')
plt.xticks([]) #去掉坐标轴
plt.yticks([])
plt.show()
displayData(a)
'''计算代价函数和梯度'''
#sigmoid函数
def sigmoid(x):
return 1/(1+np.exp(-x))
#原本代价函数
def cost_func(theta, x, y):
m = y.size
return -1/m*(y@np.log(sigmoid(x@theta))+(1-y)@np.log(1-sigmoid(x@theta)))
#正则化的代价函数,不惩罚第一项theta[0]
def cost_reg(theta, x, y, l=0.1):
m = y.size
theta_ = theta[1:] #选取第二项以后的
return cost_func(theta, x, y) + l/(2*m)*np.sum(theta_*theta_)
#原本的梯度
def gradient_func(theta, x, y):
m = y.size
return 1/m*((sigmoid(x@theta))-y).T@x
#正则化的的梯度,不惩罚第一项theta[0]
def gradient_reg(theta, x, y, l=0.1):
theta_ = l/(y.size)*theta
theta_[0] = 0 #第一项不惩罚设为0
return gradient_func(theta, x, y) + theta_
'''一对多分类'''
def one_vs_all(x, y, l, K=10):
all_theta = np.zeros((x.shape[1], K)) #应该是(10, 401)
for i in range(K):
iteration_y = np.array([1 if j==i+1 else 0 for j in y]) #第0列到第9列分别对应类别1到10
p = opt.fmin_ncg(f=cost_reg, fprime=gradient_reg, x0=all_theta[:, i:i+1], args=(x, iteration_y), maxiter=400)
all_theta[:, i:i+1] = np.mat(p).T
return all_theta
#为x添加了一列常数项 1 ,以计算截距项(常数项)
x = np.column_stack((np.ones(x.shape[0]), x))
lmd = 0.1
all_theta = one_vs_all(x, y, l=lmd)
'''预测与评价'''
#预测的概率矩阵 (5000, 10)
def probability(x, theta):
return sigmoid(x@theta)
#预测的y值
def predict(prob):
y_predict = np.zeros((prob.shape[0],1))
for i in range(prob.shape[0]):
#查找第i行的最大值并返回它所在的位置,再加1就是对应的类别
y_predict[i] = np.unravel_index(np.argmax(prob[i,:]), prob[i,:].shape)[0]+1
return y_predict
#精度
def accuracy(y_predict, y=y):
m = y.size
count = 0
for i in range(y.shape[0]):
if y_predict[i] == y[i]:
j = 1
else:
j = 0
count = j+count #计数预测值和期望值相等的项
return count/m
prob = probability(x, all_theta)
y_predict = predict(prob)
accuracy(y_predict)
print ('accuracy = {0}%'.format(accuracy(y_predict) * 100))
下图为随机选取100个训练样本可视化之后的图像,和作业里的那个图还是有点差别,颜色我调不到那个颜色。gray_r又太浅了。。

这是采用牛顿共轭梯度的结果,不知道为什么只有第一次和最后一次是显示优化成功,其余均不收敛,但是这种情况下最后的精度还有94.46%,和Andrew Ng给出来的94.9%差不多,也不知道这个结果可不可信。。。
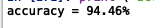















 1453
1453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









