






Winows10 +darknet53+Yolo v3训练自己的模型并测试
Winows10 +darknet53+Yolo v3训练自己的模型并测试
系统环境:
Windows10,VS2015,CUDA10.1(匹配cudnn7.6.0),OpenCV3.4.0
一、测试官方代码
1、下载windows版yolov3源码:https://github.com/AlexeyAB/darknet
2、修改darknet.vcxproj文件
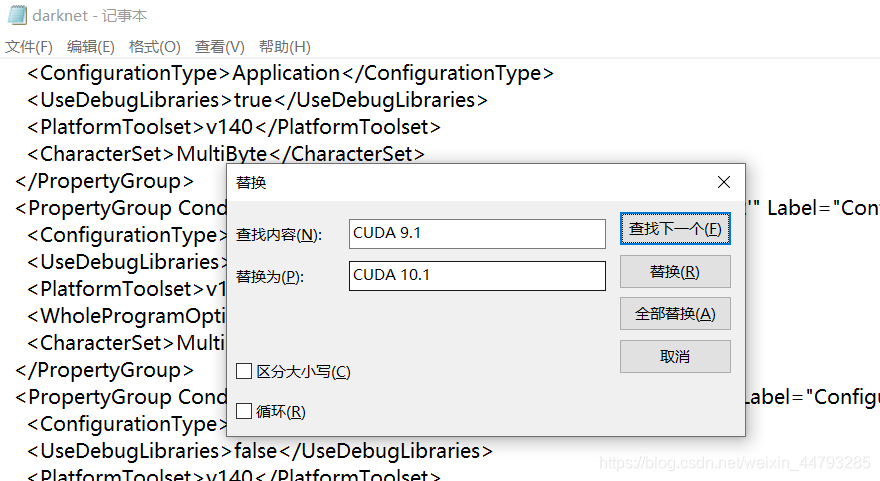
进入…\darknet-master\build\darknet目录,由于darknet.vcxproj 中使用的是CUDA 9.1,所以需要利用编辑器(记事本即可)打开darknet.vcxproj ,将所有CUDA 9.1修改为自己对应的CUDA版本.
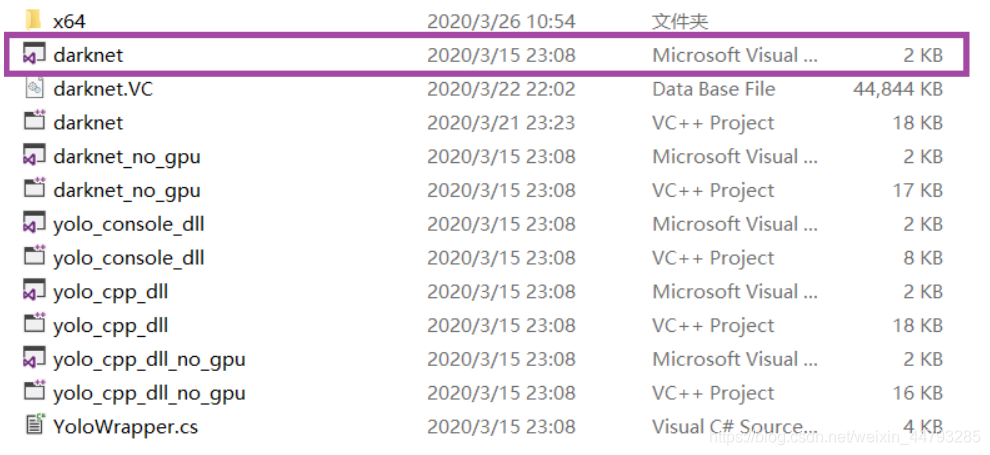
 3、在VS中打开解压后…\darknet-master\build\darknet目录下的darknet.sln(无gpu的打开darknet_no_gpu.sln),配置平台改为Release x64。
3、在VS中打开解压后…\darknet-master\build\darknet目录下的darknet.sln(无gpu的打开darknet_no_gpu.sln),配置平台改为Release x64。
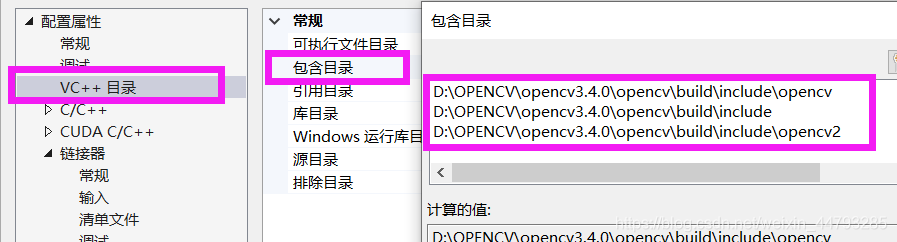
4、右击darknet文件,点属性。根据自己opencv安装目录和版本,添加包含目录、库目录和依赖项
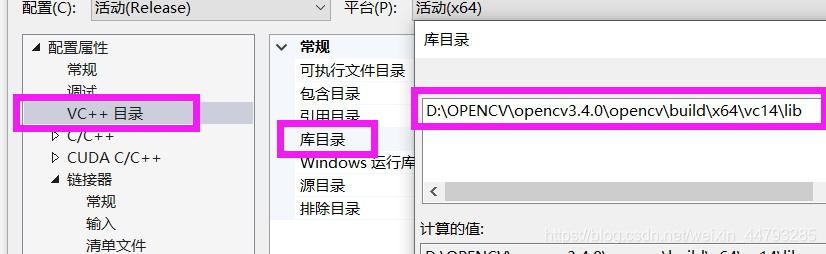
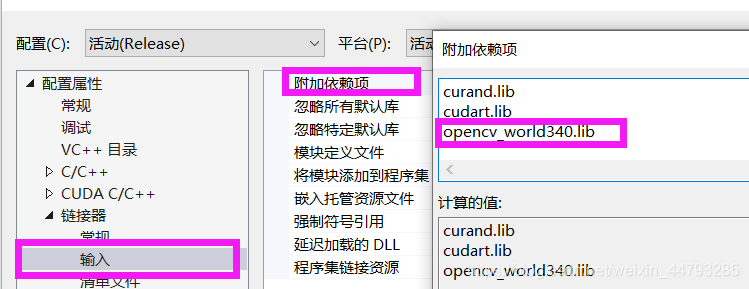
5、添加其他文件:在…\opencv\build\x64\vc14\bin目录下找到3个.dll文件复制粘贴到 …\darknet-master\build\darknet\x64 目录下。
6、生成darknet.exe:在VS中右击darknet文件,点击生成,等待一会没错误的话就可以在…\darknet-master\build\darknet\x64目录下生成darknet.exe。
7、下载作者预先训练好的模型:https://pjreddie.com/media/files/yolov3.weights;要是有百度网盘会员的话可以在网盘下载,链接:https://pan.baidu.com/s/1DCqU_7HY_6tK-gWaE6iwcQ 提取码:lhs9。下载好后直接放在…\darknet-master\build\darknet\x64下。
8、测试:打开…\darknet-master\build\darknet\x64,找到并双击darknet_yolo_v3.cmd会出现以下结果,表明成功编译。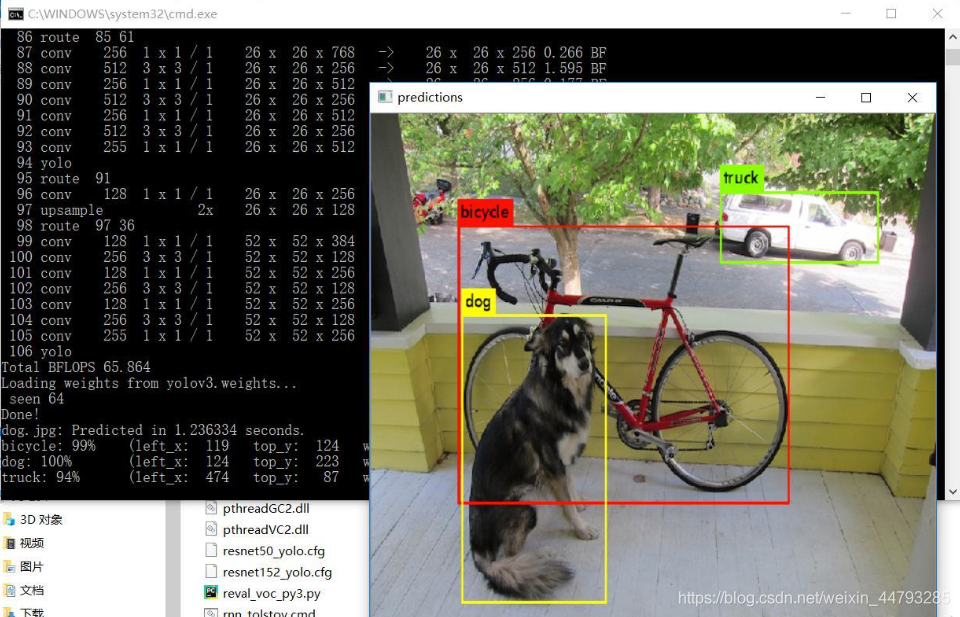
二、训练自己的模型
1、制作VOC数据集
1.1、安装labelimg,对图片进行标注,下载地址里面有使用教程。下载地址:链接https://pan.baidu.com/s/130MAFtIvuoC84kPgcckecQ提取码:z364
1.2、在…\darknet-master\build\darknet目录下新建一个文件夹,命名为:VOCdevkit2007,在其中创建如下文件夹: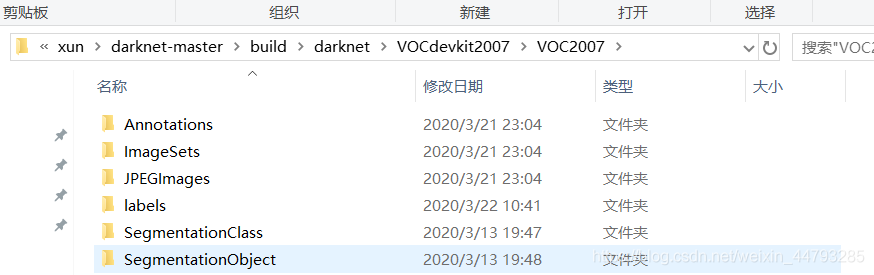
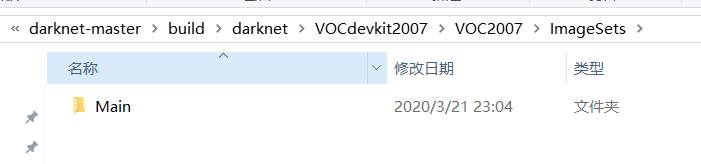
其中,JPEGImages用来存放原始图片,Annotations用来存放标注后所有的.xml文件。
1.3、使用代码在ImageSets\Main目录下生成test.txt(测试集)、train.txt(训练集)、val.txt(验证集)、trainval.txt(训练验证集,由train.txt和val.txt组成)。VOC2007中, test大概是整个数据集的50%,trainval是整个数据集剩下的50%;train大概是trainval的50%,val是trainval剩下的50%。所占比例可在代码中修改,以Python为例(其中trainval是整个数据集的70%):
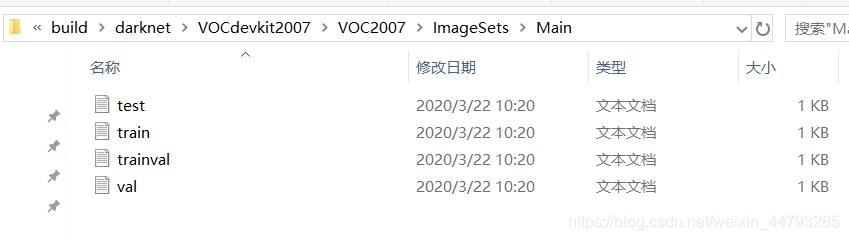 生成文件的代码如下:
生成文件的代码如下:
import os
import random
trainval_percent = 0.7 # trainval占总数的比例
train_percent = 0.5 # train占trainval的比例
xmlfilepath = r'E:\xun\darknet-master\build\darknet\VOCdevkit2007\VOC2007\Annotations'
txtsavepath = r'E:\xun\darknet-master\build\darknet\VOCdevkit2007\VOC2007\ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(txtsavepath + r'\trainval.txt', 'w')
ftest = open(txtsavepath + r'\test.txt', 'w')
ftrain = open(txtsavepath + r'\train.txt', 'w')
fval = open(txtsavepath + r'\val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()1.4、将VOC数据集转换成yolo3所需要的txt文件
将…\darknet-master\scripts目录下的voc_label.py文件拷贝到…\darknet-master\build\darknet\VOCdevkit2007目录下,并重命名为voc_label_mine.py,打开进行如下修改。
# 第7行修改所需sets
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
# 第9行修改为自己的类别,我这里就一个,所以改为
classes = ["egg"]
# 第26、27行修改路径,可改为绝对路径
in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOC%s/labels/%s.txt'%(year, image_id), 'w')
# 第48、49、50行修改路径,可改为绝对路径
if not os.path.exists('VOC%s/labels/'%(year)):
os.makedirs('VOC%s/labels/'%(year))
image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
# 第53行修改路径,可改为绝对路径
list_file.write('%s/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))完成后就会生成如下文件,其中txt文件中为对应图片的绝对路径,labels文件中为所有图片的xml文件转成的txt文件:
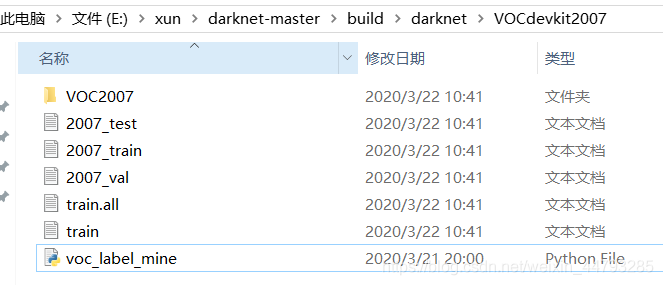
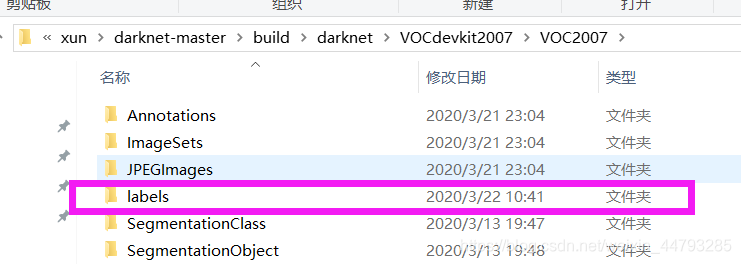
2、下载预训练权重darknet53.conv.74,下载完成后放在…\darknet-master\build\darknet\x64路径下。
链接:https://pan.baidu.com/s/1iqdxq5rCwpevUjDjZVD9Zw 提取码:zn8u
3、修改文件
3.1、修改voc.data
打开…\darknet-master\build\darknet\x64\data中的voc.data,修改自己的类别,我的是一个,所以class=1;修改train和valid对应的路径,backup就是最后训练好的权重存放位置。

3.2、修改voc.names
打开…\darknet-master\build\darknet\x64\data中的voc.names,替换成自己的类。

3.3、修改yolov3-voc.cfg
打开…\darknet-master\build\darknet\x64中的yolov3-voc.cfg,并重命名为yolov3-egg.cfg.做如下修改:
一共需要改三处,每处有三个地方需要修改,每次都是先修改[yolo]下的classes为对应的类别数,再修改[yolo]对应上面 [convolutional]下的filters为(classes+5)*3 random=1 # 多尺度输出为1,显存小时改为0关闭。

4、开始训练
打开cmd,cd到…\darknet-master\build\darknet\x64目录下,在此目录下新建results文件夹,输入命令:darknet.exe detector train data/voc.data yolov3-egg.cfg darknet53.conv.74
每迭代1000次在results文件夹中生成一个权重文件。
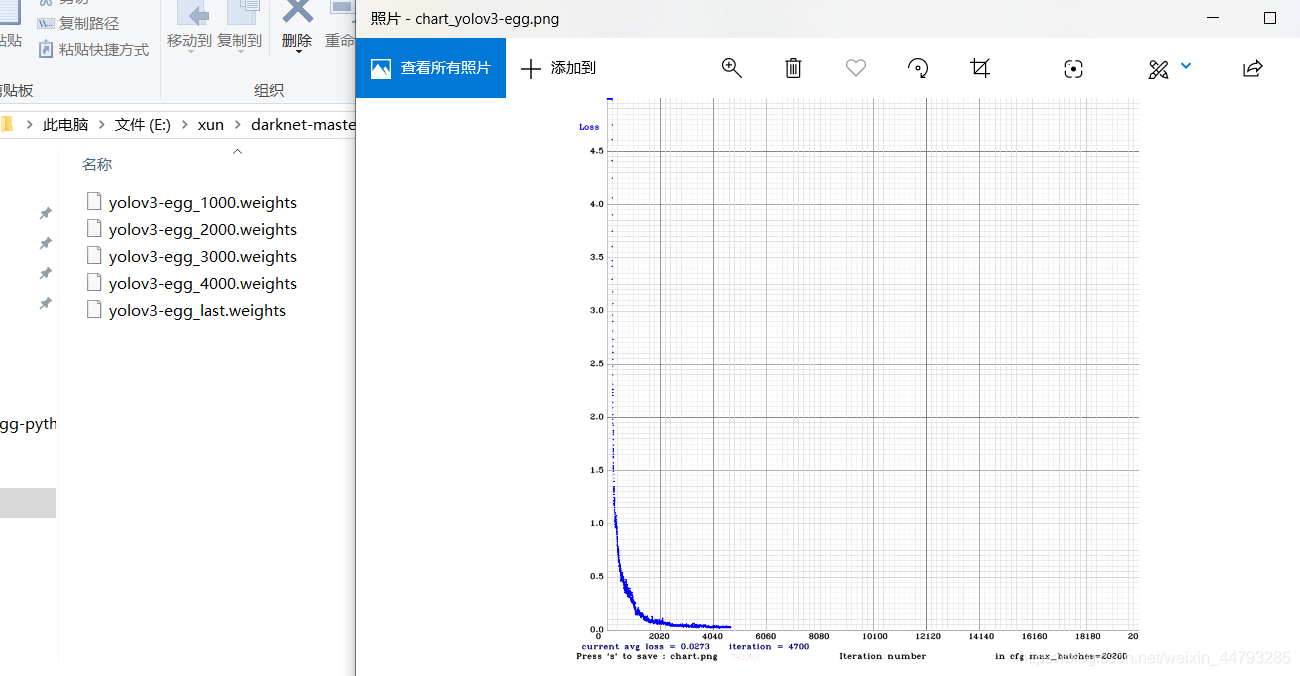
5、测试
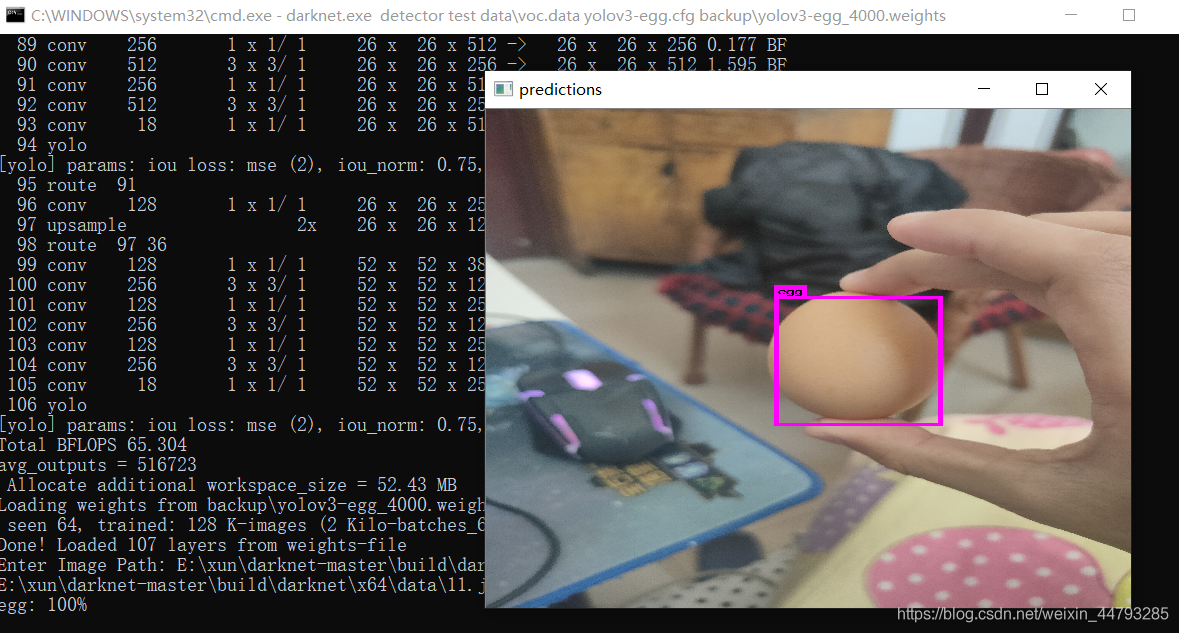
5.1、测试图片:打开cmd,cd到…\darknet-master\build\darknet\x64目录下,输入命令:darknet.exe detector test data\voc.data yolov3-egg.cfg results\yolov3-egg_last.weights
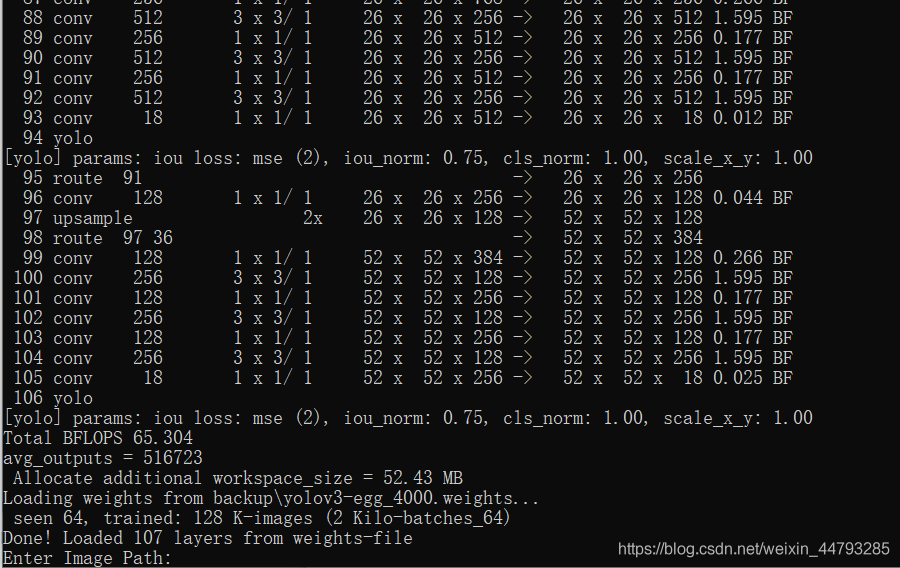
按照提示输入要检测图片的绝对路径:
5.2、测试摄像头:打开cmd,cd到…\darknet-master\build\darknet\x64目录下,输入命令:darknet.exe detector demo data\voc.data yolov3-egg.cfgresults\yolov3-egg_3000.weights -c 0














 4866
4866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









