







docker
容器与虚拟机与实体机的区别:
①容器:一句话概括容器,容器就是将软件打包成标准化单元,以用于开发、交付和部署,容器镜像是轻量的、可执行的独立软件包 ,包含软件运行所需的所有内容:代码、运行时环境、系统工具、系统库和设置。
②虚拟机:通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统。
③实体机:即硬件意义上的个体,拥有独立的硬件和软件系统。
举例来说,实体机像一幢独立的房子,虚拟机像公寓中的一户(共享地基花园等),容器像胶囊旅馆的一个隔间(共享卫生间宽带等)。容器虚拟化的是操作系统而不是硬件,容器之间是共享同一套操作系统资源的,虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统。三者的隔离级别递增。
Docker:
使用Go语言进行开发实现,基于Linux内核的cgroup,namespace,以及AUFS类的Union FS等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术。由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。Docke最初实现是基于LXC。Docker在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容器的创建和维护。使得 Docker 技术比虚拟机技术更为轻便、快捷。
docker与传统虚拟机在架构上的区别:
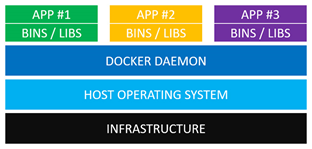
如图所示,分别为vm和docker的架构,其中:
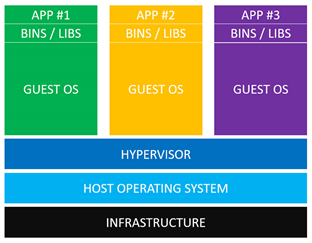
①基础设施(Infrastructure):它可以是你的个人电脑,数据中心的服务器,或者是云主机。
②主操作系统(Host Operating System):你的个人电脑之上,运行的可能是MacOS,Windows或者某个Linux发行版。
③虚拟机管理系统(Hypervisor):利用Hypervisor,可以在主操作系统之上运行多个不同的从操作系统。类型1的Hypervisor有支持MacOS的HyperKit,支持Windows的Hyper-V以及支持Linux的KVM。类型2的Hypervisor有VirtualBox和VMWare。
④从操作系统(Guest Operating System):在普通虚拟机中,假设需要运行3个相互隔离的应用,则需要使用Hypervisor启动3个从操作系统(虚拟机),由于虚拟机模拟了完整的硬件,因此会耗费巨大的磁盘空间、CPU和内存。
⑤各种依赖:每一个从操作系统都需要安装许多依赖。例如应用需要连接PostgreSQL,则需要安装libpq-dev;如果你使用Ruby的话,应该需要安装gems;如果使用其他编程语言,比如Python或者Node.js,都会需要安装对应的依赖库。
⑥应用(App):安装依赖之后,就可以在各个从操作系统分别运行应用了,这样各个应用就是相互隔离的。
⑦Docker守护进程(Docker Daemon):Docker守护进程取代了Hypervisor,它是运行在操作系统之上的后台进程,负责管理Docker容器。
由架构即可得知,Docker在体量和速度上相比较传统虚拟机都有极大的优势,关于docker与虚拟机的特性对比如图所示。
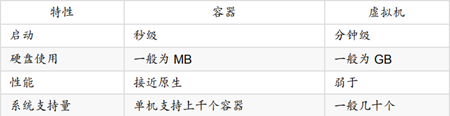
但docker与虚拟机并不冲突,它们可以共存。
docker思想:
即集装箱思想,将软件以及它运行安装所需的一切文件(代码、运行时、系统工具、系统库)打包到一起,这就保证了不管是在什么样的运行环境,总是能以相同的方式运行,就像集装箱一样,本身的颜色大小结构都是固定的,唯一变化的是其内容,并且各个集装箱之间是相互隔离的。docker下层的操作系统(有可能是虚拟机的从操作系统)即可类比为货轮,docker即集装箱。
docker与传统虚拟技术的区别:
①虚拟化技术依赖物理CPU和内存,是硬件级别的;而docker构建在操作系统上,利用操作系统的containerization技术,所以docker甚至可以在虚拟机上运行
②虚拟化系统一般都是指操作系统镜像,比较复杂,称为“系统”;而docker开源而且轻量,称为“容器”,单个容器适合部署少量应用,比如部署一个redis、一个memcached。
③传统的虚拟化技术使用快照来保存状态;而docker在保存状态上不仅更为轻便和低成本,而且引入了类似源代码管理机制,将容器的快照历史版本一一记录,切换成本很低。
④传统的虚拟化技术在构建系统的时候较为复杂,需要大量的人力;而docker可以通过Dockfile来构建整个容器,重启和构建速度很快。更重要的是Dockfile可以手动编写,这样应用程序开发人员可以通过发布Dockfile来指导系统环境和依赖,这样对于持续交付十分有利。
⑤Dockerfile可以基于已经构建好的容器镜像,创建新容器。Dockerfile可以通过社区分享和下载,有利于该技术的推广。Docker会像一个可移植的容器引擎那样工作。它把应用程序及所有程序的依赖环境打包到一个虚拟容器中,这个虚拟容器可以运行在任何一种 Linux服务器上。这大大地提高了程序运行的灵活性和可移植性,无论需不需要许可、是在公共云还是私密云、是不是裸机环境等等。
docker容器的特点:
①更高效的利用系统资源,由于容器不需要进行硬件虚拟以及运行完整操作系统等额外开销,Docker 对系统资源的利用率更高。无论是应用执行速度、内存损耗或者文件存储速度,都要比传统虚拟机技术更高效。因此,相比虚拟机技术,一个相同配置的主机,往往可以运行更多数量的应用。
②更快速的启动时间,传统的虚拟机技术启动应用服务往往需要数分钟,而 Docker 容器应用,由于直接运行于宿主内核,无需启动完整的操作系统,因此可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。
③一致的运行环境,开发过程中一个常见的问题是环境一致性问题。由于开发环境、测试环境、生产环境不一致,导致有些 bug 并未在开发过程中被发现。而 Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 「这段代码在我机器上没问题啊」 这类问题。
④持续交付和部署,对开发和运维(DevOps)人员来说,最希望的就是一次创建或配置,可以在任意地方正常运行。使用 Docker 可以通过定制应用镜像来实现持续集成、持续交付、部署。开发人员可以通过 Dockerfile 来进行镜像构建,并结合 持续集成(Continuous Integration) 系统进行集成测试,而运维人员则可以直接在生产环境中快速部署该镜像,甚至结合 持续部署(Continuous Delivery/Deployment) 系统进行自动部署。而且使用 Dockerfile 使镜像构建透明化,不仅仅开发团队可以理解应用运行环境,也方便运维团队理解应用运行所需条件,帮助更好的生产环境中部署该镜像。
⑤更轻松的迁移,由于 Docker 确保了执行环境的一致性,使得应用的迁移更加容易。Docker 可以在很多平台上运行,无论是物理机、虚拟机、公有云、私有云,甚至是笔记本,其运行结果是一致的。因此用户可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。
⑥更轻松的维护和扩展,Docker 使用的分层存储以及镜像的技术,使得应用重复部分的复用更为容易,也使得应用的维护更新更加简单,基于基础镜像进一步扩展镜像也变得非常简单。此外,Docker 团队同各个开源项目团队一起维护了一大批高质量的 官方镜像,既可以直接在生产环境使用,又可以作为基础进一步定制,大大的降低了应用服务的镜像制作成本。
docker容器的基础概念:
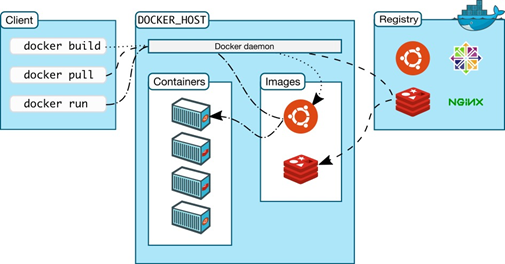
①C/S架构:Docker 在运行时分为 Docker 引擎(也就是服务端守护进程)和客户端工具。Docker 的引擎提供了一组 REST API,被称为 Docker Remote API,而如 docker 命令这样的客户端工具,则是通过这组 API 与 Docker 引擎交互,从而完成各种功能。因此,虽然表面上我们好像是在本机执行各种 docker 功能,但实际上,一切都是使用的远程调用形式在服务端(Docker 引擎)完成。也因为这种 C/S 设计,让我们操作远程服务器的 Docker 引擎变得轻而易举。如图所示。
②镜像(image):Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变。可以理解为类似操作系统的.iso文件,但其中不包含有关硬件的信息。
③容器(container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 命名空间。因此容器可以拥有自己的 root 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。每一个容器运行时,是以镜像为基础层,在其上创建一个当前容器的存储层,我们可以称这个为容器运行时读写而准备的存储层为 容器存储层。
容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。
按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化。所有的文件写入操作,都应该使用数据卷(Volume)、或者绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此,使用数据卷后,容器删除或者重新运行之后,数据却不会丢失。
④仓库(Repository):仓库(Repository)是集中存放镜像文件的场所。有时候会把仓库和仓库注册服务器(Registry)混为一谈,并不严格区分。实际上,仓库注册服务器上往往存放着多个仓库,每个仓库中又包含了多个镜像,每个镜像有不同的标签(tag)。
仓库分为公开仓库(Public)和私有仓库(Private)两种形式。最大的公开仓库是 Docker Hub,存放了数量庞大的镜像供用户下载。
仓库的概念跟github的概念类似,也分别提供了公开服务与私有服务,注意用户设为私有的镜像与私有Docker Registry服务并不相同,这点也与github类似。
⑤数据卷(Volume):是一个可供一个或多个容器使用的特殊目录,它绕过 UFS,可以提供很多有用的特性:
Ⅰ数据卷可以在容器之间共享和重用
Ⅱ对数据卷的修改会立马生效
Ⅲ对数据卷的更新,不会影响镜像
Ⅳ数据卷默认会一直存在,即使容器被删除
注:数据卷的使用,类似于 Linux 下对目录或文件进行 mount,镜像中的被指定为挂载点的目录中的文件会隐藏掉,能显示看的是挂载的数据卷。
⑥docker中的分层存储:因为镜像包含操作系统完整的 root 文件系统,其体积往往是庞大的,因此在 Docker 设计时,就充分利用 Union FS 的技术,将其设计为分层存储的架构。所以严格来说,镜像并非是像一个 ISO 那样的打包文件,镜像只是一个虚拟的概念,其实际体现并非由一个文件组成,而是由一组文件系统组成,或者说,由多层文件系统联合组成。
镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
⑦Dockerfile:Dockerfile 是一个文本文件,其内包含了一条条的指令(Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建,要注意,这并不是在写 Shell 脚本,而是在定义每一层该如何构建,Union FS 是有最大层数限制的,比如AUFS,曾经是最大不得超过42层,现在是不得超过127层。
注:可以使用&&与\符号将多行输入连为一层,关于dockerfile的命令如图所示。

⑧镜像构建上下文(Context):当构建镜像的时候,若需要将一些本地文件复制进镜像,用户会指定构建镜像上下文的路径,docker build 命令得知这个路径后,会将路径下的所有内容打包,然后上传给 Docker 引擎。这样 Docker 引擎收到这个上下文包后,展开就会获得构建镜像所需的一切文件。
COPY 这类指令中的源文件的路径都是相对路径。
一般来说,应该会将 Dockerfile 置于一个空目录下,或者项目根目录下。如果该目录下没有所需文件,那么应该把所需文件复制一份过来。在默认情况下,如果不额外指定Dockerfile,会将上下文目录下的名为 Dockerfile 的文件作为 Dockerfile。
关于Docker各要素之间的关系和部分命令如图所示。
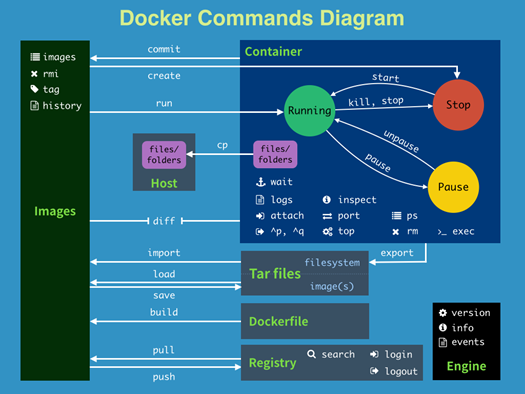
Docker特性:
①文件系统隔离:每个进程容器运行在完全独立的根文件系统里。
②资源隔离:可以使用cgroup为每个进程容器分配不同的系统资源,例如CPU和内存。
③网络隔离:每个进程容器运行在自己的网络命名空间里,拥有自己的虚拟接口和IP地址。
④写时复制:采用写时复制方式创建根文件系统,这让部署变得极其快捷,并且节省内存和硬盘空间。
⑤日志记录:Docker将会收集和记录每个进程容器的标准流(stdout/stderr/stdin),用于实时检索或批量检索。
⑥变更管理:容器文件系统的变更可以提交到新的映像中,并可重复使用以创建更多的容器。无需使用模板或手动配置。
⑦交互式Shell:Docker可以分配一个虚拟终端并关联到任何容器的标准输入上,例如运行一个一次性交互shell。
Dockerfile、Docker镜像和Docker容器的关系详解
Dockerfile 是软件的原材料,Docker 镜像是软件的交付品,而 Docker 容器则可以认为是软件的运行态。从应用软件的角度来看,Dockerfile、Docker 镜像与 Docker 容器分别代表软件的三个不同阶段,Dockerfile 面向开发,Docker 镜像成为交付标准,Docker 容器则涉及部署与运维,三者缺一不可,合力充当 Docker 体系的基石。
简单来讲,Dockerfile构建出Docker镜像,通过Docker镜像运行Docker容器。
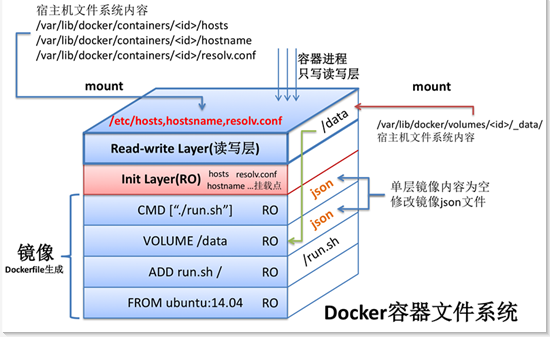
①Dockerfile与Docker镜像
首先,我们结合上图来看看Dockerfile与Docker镜像之间的关系。
FROM ubuntu:14.04:设置基础镜像,此时会使用基础镜像 ubuntu:14.04 的所有镜像层,为简单起见,图中将其作为一个整体展示。
ADD run.sh /:将 Dockerfile 所在目录的文件 run.sh 加至镜像的根目录,此时新一层的镜像只有一项内容,即根目录下的 run.sh。
VOLUME /data:设定镜像的 VOLUME,此 VOLUME 在容器内部的路径为 /data。需要注意的是,此时并未在新一层的镜像中添加任何文件,即构建出的磁层镜像中文件为空,但更新了镜像的 json 文件,以便通过此镜像启动容器时获取这方面的信息。
CMD ["./run.sh"]:设置镜像的默认执行入口,此命令同样不会在新建镜像中添加任何文件,仅仅在上一层镜像 json 文件的基础上更新新建镜像的 json 文件。
因此,通过以上分析,以上的Dockerfile可以构建出一个新的镜像,包含4个镜像层,每一条命令会和一个镜像层对应,镜像之间会存在父子关系。图中很清楚的表明了这些关系。
②Docker镜像与Docker容器
Docker镜像是Docker容器运行的基础,没有Docker镜像,就不可能有Docker容器,这也是Docker的设计原则之一。静态的镜像转换为动态的容器的两个关键点:
Ⅰ转化的依据,是每个镜像的json文件,Docker可以通过解析Docker镜像的json的文件,获知应该在这个镜像之上运行什么样的进程,应该为进程配置怎么样的环境变量,此时也就实现了静态向动态的转变。
Ⅱ转化工作的执行,Docker守护进程手握Docker镜像的json文件,为容器配置相应的环境,并真正运行Docker镜像所指定的进程,完成Docker容器的真正创建。
Docker容器运行起来之后,Docker镜像json文件就失去作用了。此时Docker镜像的绝大部分作用就是:为Docker容器提供一个文件系统的视角,供容器内部的进程访问文件资源。
所有的Docker镜像层对于容器来说,都是只读的,容器对于文件的写操作绝对不会作用在镜像中,其原因为:Docker守护进程会在Docker镜像的 最上层之上,再添加一个可读写层,容器所有的写操作都会作用到这一层中。而如果Docker容器需要写底层Docker镜像中的文件,那么此时就会涉及一 个叫Copy-on-Write的机制,即aufs等联合文件系统保证:首先将此文件从Docker镜像层中拷贝至最上层的可读写层,然后容器进程再对读 写层中的副本进行写操纵。对于容器进程来讲,它只能看到最上层的文件。
docker 的四种网络模式
host模式
如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。
但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
container模式
Container模式指定新创建的容器和已经存在的一个容器共享一个Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过lo网卡设备通信。
none模式
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。
bridge模式
bridge模式是Docker默认的网络设置,此模式会为每一个容器分配Network Namespace、设置IP等,并将一个主机上的Docker容器连接到一个虚拟网桥上。
celery
Distributed Task Queue,分布式任务队列,其本身由python开发,非常易于集成到python的web框架中。
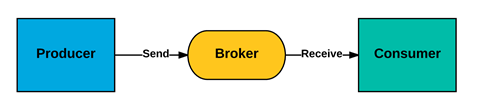
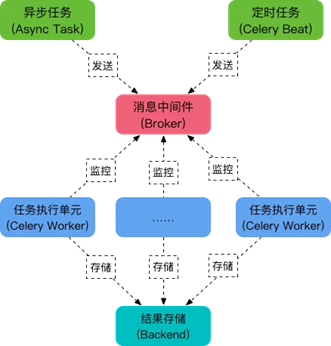
celery的核心角色:Task,就是任务,有异步任务和定时任务。Broker,中间人,接收生产者发来的消息即Task,将任务存入队列。任务的消费者是Worker。Celery本身不提供队列服务,推荐用Redis或RabbitMQ实现队列服务。Worker,执行任务的单元,它实时监控消息队列,如果有任务就获取任务并执行它。Beat,定时任务调度器,根据配置定时将任务发送给Broler。Backend,用于存储任务的执行结果。如图所示为celery官方对于各角色的支持。

celery的定位:celery即一个实现了生产者消费者模型的框架,其Task对应producer,worker对应consumer,broker即对应broker,其在该模型的基础上做的工作是:
①celery封装了task的产生和发送过程,其将producer的producing过程封装为简单的函数接口,并且封装了task send to broker的细节,即封装了producer与broker的交互细节;
②其broker即消息队列,消息队列其实可以有多个,只要支持AMQP协议即可(关于RabbitMQ、AMQP见前文),celery本身复用了消息队列的机制,并且封装了一部分细节(如消息以什么形式存储在MQ中,多个MQ的创建,消息被消费后是否还存在);
③celery封装了consumer从broker获取信息的receive过程,即封装了worker与broker的交互细节(如worker如何监控MQ,任务以什么规则分发,如何实现并发等);
④celery封装了rabbitMQ的rpc机制,即backend角色的相关功能与实现过程;
⑤具体的task、worker内容与其运行环境由用户提供,broker的具体实现者也由用户提供,官方推荐为RabbitMQ或Redis;
⑥上述所有封装的细节都提供了函数接口或配置接口用于控制,如可以控制broker和backend的实现者,任务的发送机制(异步、定时),结果的获取,设计工作流(signature)等。
celery的一些特性:
①监视,整条流水线的监视时间由职程发出,并用于内建或外部的工具告知你集群的工作状况——而且是实时的。
②工作流,一系列功能强大的称为“Canvas”的原语(Primitive)用于构建或简单、或复杂的工作流。包括分组、连锁、分割等等。
③时间和速率限制,你可以控制每秒/分钟/小时执行的任务数,或任务的最长运行时间, 并且可以为特定职程或不同类型的任务设置为默认值。
④计划任务,你可以指定任务在若干秒后或在 datetime 运行,或你可以基于单纯的时间间隔或支持分钟、小时、每周的第几天、每月的第几天以及每年的第几月的 crontab 表达式来使用周期任务来重现事件。
⑤自动重载入,在开发中,职程可以配置为在源码修改时自动重载入。
⑥自动扩展,根据负载自动重调职程池的大小或用户指定的测量值,用于限制共享主机/云环境的内存使用,或是保证给定的服务质量。
⑦资源泄露保护,–maxtasksperchild 选项用于控制用户任务泄露的诸如内存或文件描述符这些易超出掌控的资源。
⑧用户组件,每个职程组件都可以自定义,并且额外组件可以由用户定义。职程是用 “bootsteps” 构建的——一个允许细粒度控制职程内构件的依赖图。
celery支持的一些方法举例(详情可参celery官方文档)
①任务调用:task.delay(),task,apply_async(可指定等待时间,任务开始时间,超时时间,重试策略,自定义发布者,交换机,队列,路由键等)
②工作流与子任务:将任务通过signature包装成对象后,其支持下述函数:
chain : 调用链, 前面的执行结果, 作为参数传给后面的任务, 直到全部完成, 类似管道
group : 一次创建多个(一组)任务
chord : 等待任务全部完成时添加一个回调任务
map/starmap : 每个参数都作为任务的参数执行一遍, map 的参数只有一个, starmap 支持多个参数
chunks : 将任务分块;
③beat服务,可实现定时任务,任务调度等;
④celery还支持信号系统,任务绑定与日志系统等。
本文大部分内容引自下述链接:
https://www.cnblogs.com/kex1n/p/6933039.html
https://www.jianshu.com/p/50f48eb25215
http://dockone.io/article/6051
https://blog.csdn.net/qq_37788081/article/details/79044119
https://blog.csdn.net/jingzhunbiancheng/article/details/80994909
http://m.elecfans.com/article/648468.html
https://www.jsdaima.com/blog/177.html
https://blog.csdn.net/S_gy_Zetrov/article/details/78161154
https://blog.csdn.net/shnsuohaonan/article/details/80651439
https://yeasy.gitbooks.io/docker_practice/content/introduction/
https://blog.51cto.com/steed/2292346?source=dra
http://docs.jinkan.org/docs/celery/getting-started/introduction.html















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









