







Mysql相关面试题总结
写在前面
本文,我们一起来探讨一下Mysql相关知识,对Mysql的底层和调优进行梳理。如有错误或有补充,欢迎留言!!!关于Mysql的基本使用,以及增删改查的语句,这里就不做说明了。
Mysql存储引擎
mysql的存储引擎包括:MyISAM、InnoDB、BDB、MEMORY、MERGE、EXAMPLE、NDBCluster、ARCHIVE、CSV、BLACKHOLE、FEDERATED等。默认是InnoDB,本文主要围绕MyISAM、InnoDB这两种存储引擎进行讲解,其他存储引擎暂不讲解。
存储引擎是基于表的,也就是说,不同的表可以指定不同的存储引擎。
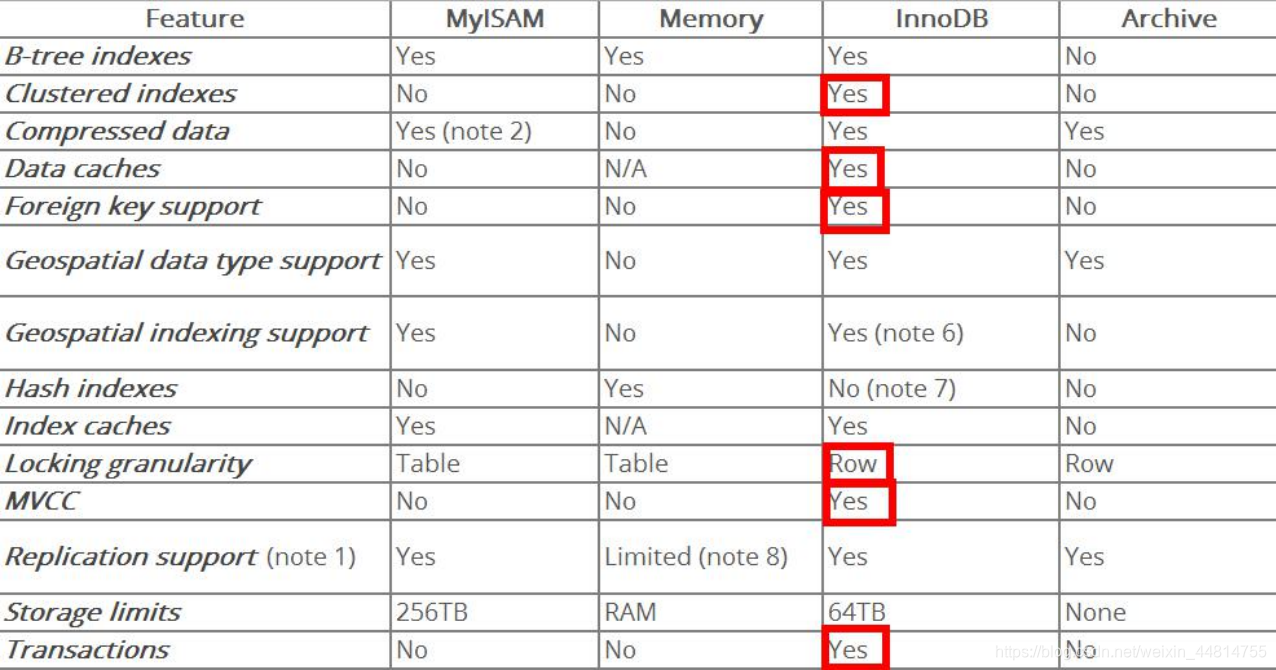
InnoDB与MyISAM对比
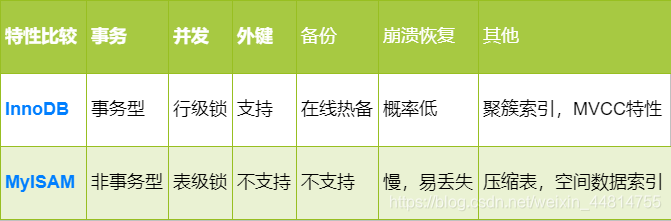
索引是什么
索引是帮助MySQL高效获取数据的排好序的数据结构。
简单点:索引是数据结构。
索引的结构有:二叉树,红黑树,HASH,BTree等。MySQL中BTree索引使用的是B树中的B+Tree。但是对于MyISAM、InnoDB这两种主要的存储引擎来说,具体实现是不一样的。
为什么是B+树
- B+树的磁盘读写代价更低:B+树节点不存储指针,只存储索引;
- B+树更加支持范围查找:只需要去遍历叶子节点就可以对整棵树遍历:
MyISAM“非聚簇索引”
MyISAM索引文件和数据文件是分离的。
例如有个teacher表,它的存储引擎是MyISAM,他会有两个文件,一个MYI,一个MYD,MYI存放的是索引,MYD文件存放的是data数据。
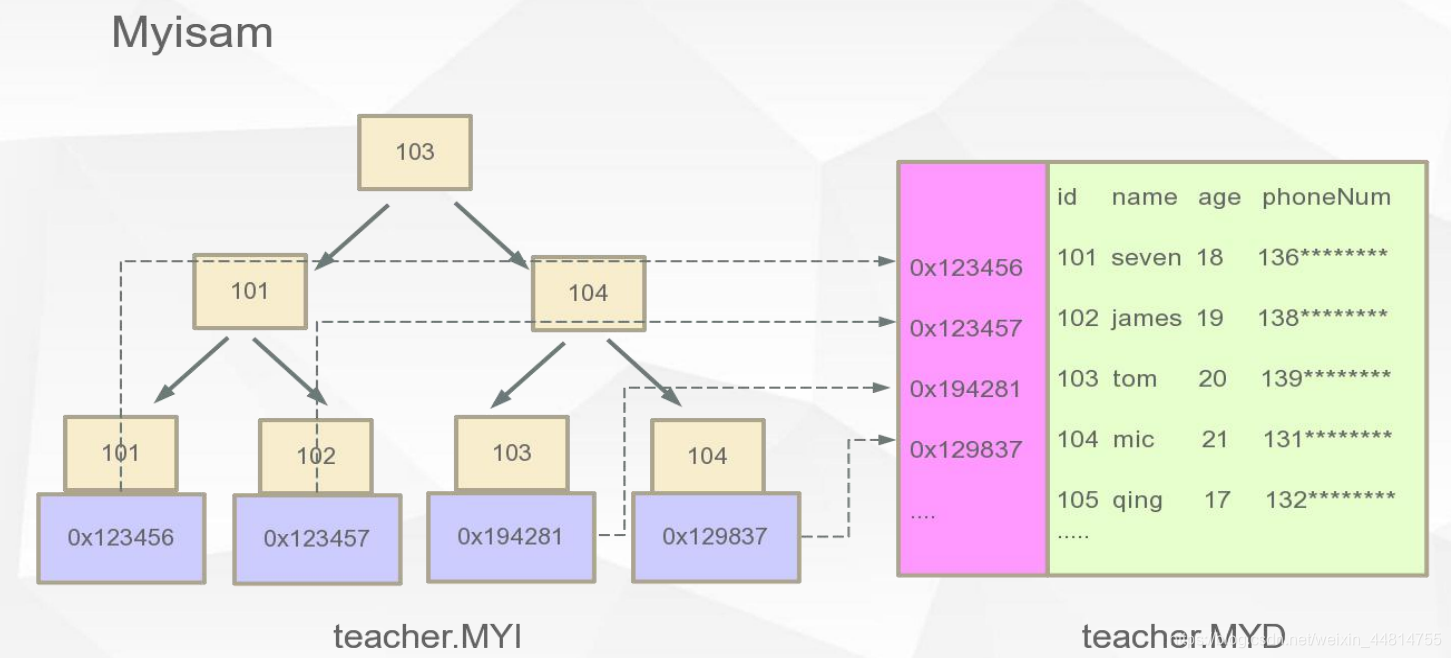
这个图有些问题,叶子节点会通过双向链表相连。
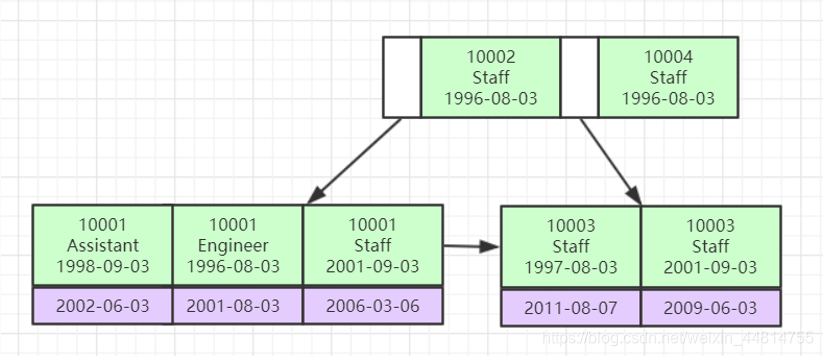
InnoDB“聚簇索引”
数据文件本身就是索引文件
表数据文件本身就是按B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录
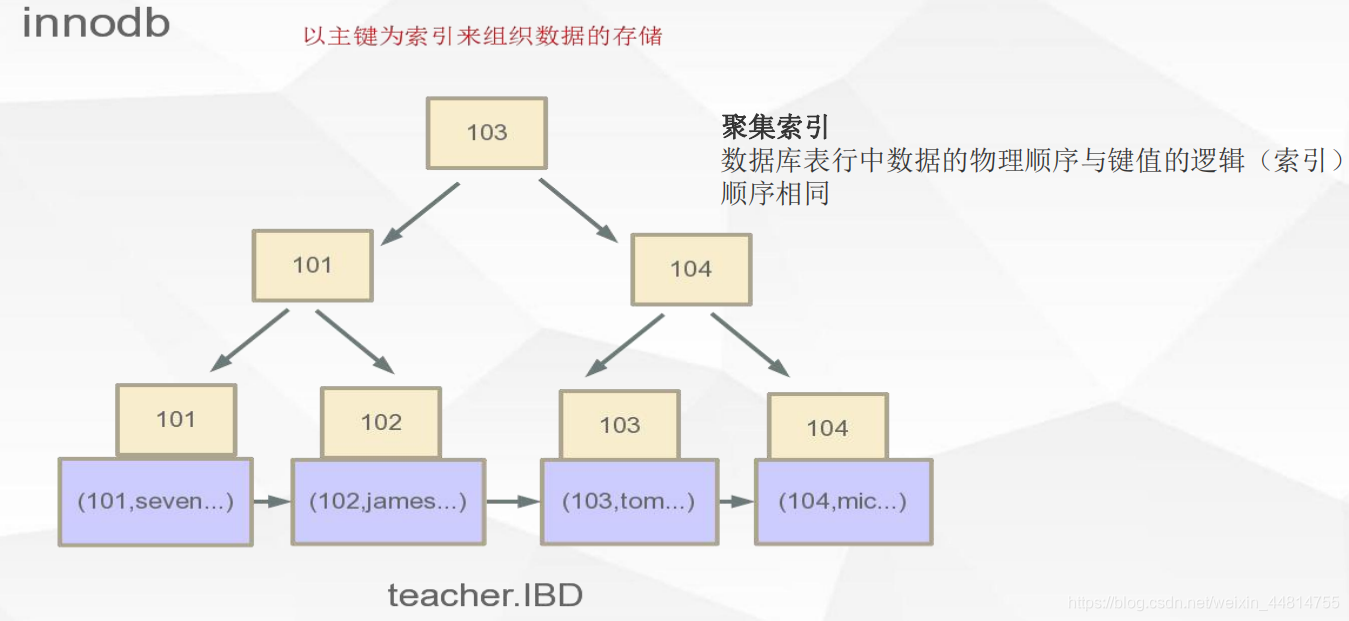
同上图,叶子节点不是通过单向链表相连,而是双向链表。
没有主键,更新或删除表中特定行很困难,因为没有安全的方法保证只设计相关的行。
辅助索引
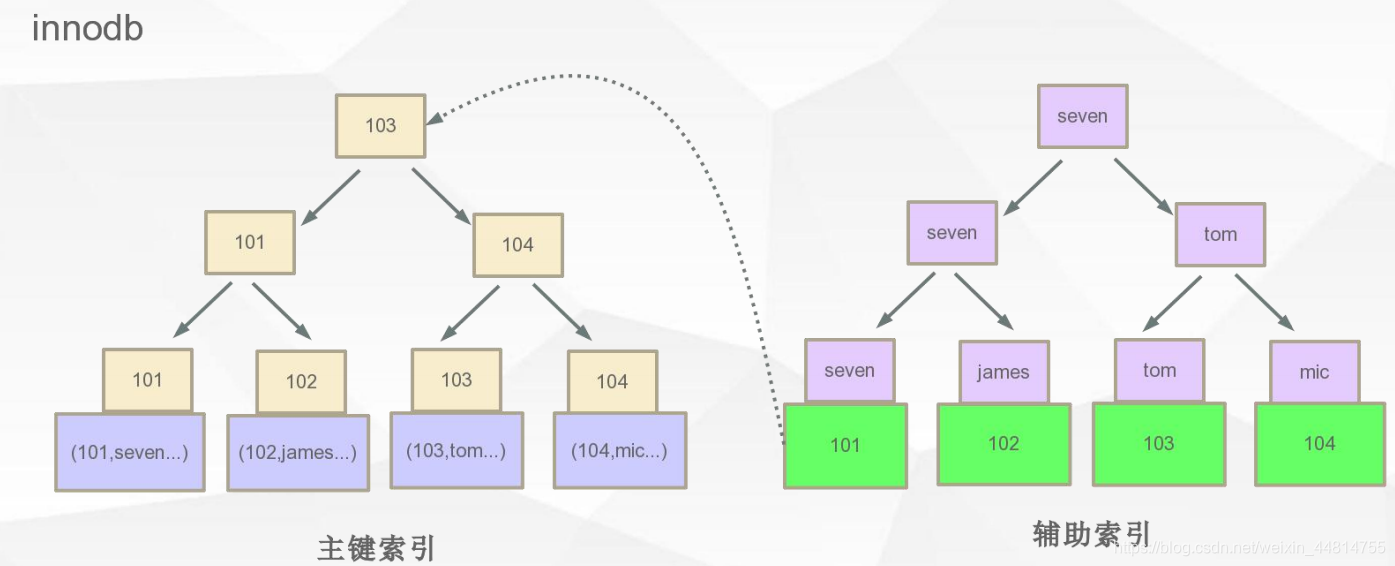
innodb辅助索引,叶子节点不存储具体的数据,只存储主键的值。
为什么非主键索引结构叶子节点存储的是主键值?
- 一致性:两份文件都有具体信息,增删改操作就必须考虑一致性问题。
- 节约存储空间
联合索引
- 最左前缀原则
创建复合索引时应该将最常用(频率)作限制条件的列放在最左边,依次递减。
谈谈Explain
使用EXPLAIN关键字可以模拟优化器执行SQL语句,从而知道MySQL是 如何处理你的SQL语句的。分析你的查询语句或是结构的性能瓶颈 。
例如输入一条SQL语句:
explain select * from actor;
会出现下面的一张表:

- id列:id列的编号是 select 的序列号,id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行;
- select_type列:select_type 表示对应行是简单还是复杂的查询,总共的类别分别是,simple:简单查询;primary:复杂查询中最外层的 select;subquery:包含在 select 中的子查询(不在 from 子句中);derived:包含在 from 子句中的子查询;union:在 union 中的第二个和随后的 select;union result:从 union 临时表检索结果的 select;
- table列:这一列表示 explain 的一行正在访问哪个表;
- type列:这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL。一般来说,得保证查询达到range级别,最好达到ref;
- possible_keys列:这一列显示查询可能使用哪些索引来查找;
- key列:这一列显示mysql实际采用哪个索引来优化对该表的访问;
- key_len列:这一列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列;
- ref列:这一列显示了在key列记录的索引中,表查找值所用到的列或常量;
- rows列:这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数;
- Extra列:这一列展示的是额外信息。 常见的有:Using index,Using where,Using where Using index,NULL,Using index condition,Using temporary,Using filesort。
个人见解:Explain对于Java开发工程师来说,了解就好,公司里有个专门的职位叫DBA,他们可能对这个使用的较多。而且概念复杂,需要长时间的使用才能了解其中的原理,Java开发着重还是要知道,索引和事务这两块内容。(如有不同见解,欢迎留言,评论)
优化技巧
- 全值匹配;
- 最佳左前缀法则: 如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列;
- 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描;
- 存储引擎不能使用索引中范围条件右边的列;
- 尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少select *语句;
- mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描;
- is null,is not null 也无法使用索引;
- like以通配符开头(’$abc…’)mysql索引失效会变成全表扫描操作;
- 字符串不加单引号索引失效;
- 少用or,用它连接时很多情况下索引会失效;
还有一些具体的优化技巧,可以看我上传的资料。
SQL优化军规
Mysql事务
事务的四大特性:ACID
- 原子性(Atomicity) :最小的工作单元,整个工作单元要么一起提交成功,要么全部失败回滚 ;
- 一致性(Consistency) :事务中操作的数据及状态改变是一致的,即写入资料的结果必须完全符合预设的规则, 不会因为出现系统意外等原因导致状态的不一致;
- 隔离性(Isolation) :一个事务所操作的数据在提交之前,对其他事务的可见性设定(一般设定为不可见);
- 持久性(Durability) :事务所做的修改就会永久保存,不会因为系统意外导致数据的丢失。
事务并发带来的问题
- 脏读:在事务A修改数据之后提交数据之前,这时另一个事务B来读取数据,如果不加控制,事务B读取到A修改过数据,之后A又对数据做了修改再提交,则B读到的数据是脏数据,此过程称为脏读Dirty Read。
- 不可重复读:一个事务内在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了变更、或者某些记录已经被删除了。
- 幻读:事务A在按查询条件读取某个范围的记录时,事务B又在该范围内插入了新的满足条件的记录,当事务A再次按条件查询记录时,会产生新的满足条件的记录(幻行 Phantom Row)
不可重复读与幻读有什么区别?
- 不可重复读的重点是修改:在同一事务中,同样的条件,第一次读的数据和第二次读的「数据不一样」。(因为中间有其他事务提交了修改)
- 幻读的重点在于新增或者删除:在同一事务中,同样的条件,第一次和第二次读出来的「记录数不一样」。(因为中间有其他事务提交了插入/删除)
事务的隔离级别

不同的隔离级别带来的问题
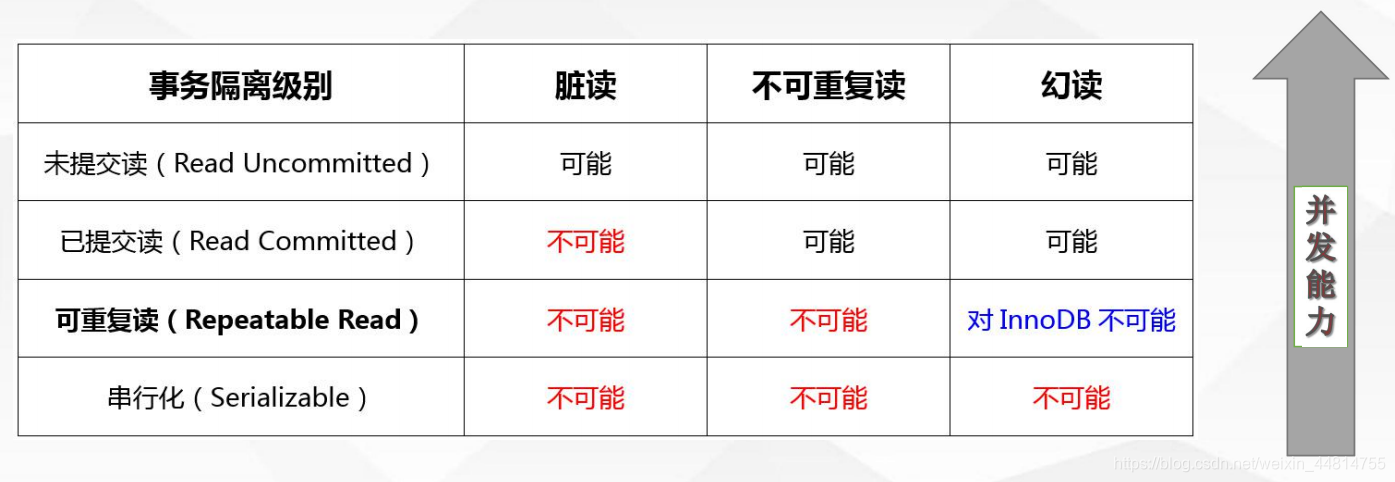
注意:Innodb在可重复读这个隔离级别下,使用的是Next-Key Lock算法,因此可以避免幻读的产生。
锁
表锁和行锁:
- 锁定粒度:表锁 > 行锁
- 加锁效率:表锁 > 行锁
- 冲突概率:表锁 > 行锁
- 并发性能:表锁 < 行锁
Mysql Innodb锁的类型
- 共享锁/读锁(行锁)Shared Locks
- 排他锁/写锁(行锁)Exclusive Locks
- 意向共享锁(表锁):Intention Shared Locks
- 意向排它锁(表锁):Intention Exclusive Locks
意向锁(IS、IX)是InnoDB数据操作之前自动加的,不需要用户干预。
意义:当事务想去进行锁表时,可以先判断意向锁是否存在,存在时则可快速返回该表不能启用表锁(相当于一个标记) - 自增锁:AUTO-INC Locks
针对自增列自增长的一个特殊的表级别锁
行锁的算法:
- 记录锁 Record Locks:记录锁锁定索引记录;
- 间隙锁 Gap Locks:间隙锁锁定间隔,防止间隔中被其他事务插入;
- 临键锁 Next-key Locks:临键锁锁定索引记录+间隔,防止幻读;
innodb行锁到底锁了什么
InnoDB的行锁是通过给索引上的索引项加锁来实现的。
只有通过索引条件进行数据检索,InnoDB才使用行级锁,否则,InnoDB 将使用表锁(锁住索引的所有记录)
MVCC?
Multiversion concurrency control (多版本并发控制)
并发访问(读或写)数据库时,对正在事务内处理的数据做多版本的管理。以达到用来避免写操作的堵塞,从而引发读操作的并发问题。
在Mysql中MVCC是在Innodb存储引擎中得到支持的,Innodb为每行记录都实现了三个隐藏字段:
- DB_TRX_ID 数据行的版本号
- DB_ROLL_PTR 删除版本号
- 隐藏的ID
Undo log和Redo log
-
undo log指事务开始之前,在操作任何数据之前,首先将需操作的数据备份到一个地方 (Undo Log)。
Undo Log实现事务原子性: 事务处理过程中如果出现了错误或者用户执行了 ROLLBACK语句,Mysql可以利用Undo Log中的备份 将数据恢复到事务开始之前的状态。
Undo log实现多版本并发控制: 事务未提交之前,Undo保存了未提交之前的版本数据,Undo 中的数据可作为数据旧版本快照供其他并发事务进行快照读。
快照读:SQL读取的数据是快照版本,也就是历史版本,普通的SELECT就是快照读。 innodb快照读,数据的读取将由 cache(原本数据) + undo(事务修改过的数据) 两部分组成。
当前读:SQL读取的数据是最新版本。通过锁机制来保证读取的数据无法通过其他事务进行修改 。UPDATE、DELETE、INSERT、SELECT … LOCK IN SHARE MODE、SELECT … FOR UPDATE都是当前读。 -
redo log又称重做日志文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。
Redo Log实现事务持久性: 防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的未入磁盘数据进行持久化这一特性。
数据库范式
数据库三大范式(1NF、2NF、3NF)
简单点:
- 每一列只有一个单一的值,不可再拆分;
- 每一行都有主键能进行区分 ;
- 每一个表都不包含其他表已经包含的非主键信息。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









