







众所周知,Python有很对第三方模块,只要熟练应用这些模块即可完成各种任务,在开始采集数据之前需要存在一个目标站点,然后使用Python脚本进行质量数据采集。探测web质量需要用到Python的pycurl模块,它可以获取HTTP请求的状态码,DNS解析时间、建立连接时间、传输结束总时间,下载数据包大小,HTTP头部大小、平均下载速度等参数。从这些参数中可以了解web的服务质量如何,然后进行优化等操作。将获取的数据写到Excel表格中,这里使用的是Python的xlsxwrite模块,实现的思路是将获取的数据保存到一个文件里面,然后再去创建一个Excel表,将数据写入到表格中然后绘制图表,以此类推,文件里的数据会追加,之后创建的Excel表会被完全覆盖,当然创建Excel表格的模块会很多,这里不再细说。
Python脚本编写前的准备:
下载pycurl模块,直接双击安装即可。
xlsxwriter使用pip命令安装,此处需要注意环境变量是否配置。
1、由于pycurl是下载下来直接安装的,这里就不写了,比较简单。
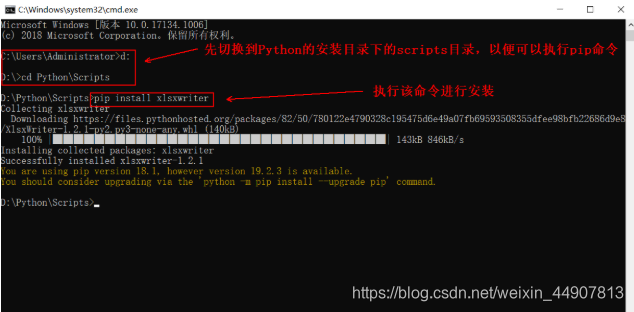
2、安装xlsxwriter模块(需可连接Internet)
3、采集数据的脚本如下:
# _._ coding:utf-8 _._
import os,sys
import pycurl
import xlsxwriter
URL="www.baidu.com" #探测目标的url,需要探测哪个目标,这里改哪个即可
c = pycurl.Curl() #创建一个curl对象
c.setopt(pycurl.URL, URL) #定义请求的url常量
c.setopt(pycurl.CONNECTTIMEOUT, 10) #定义请求连接的等待时间
c.setopt(pycurl.TIMEOUT, 10) #定义请求超时时间
c.setopt(pycurl.NOPROGRESS, 1) #屏蔽下载进度条
c.setopt(pycurl.FORBID_REUSE, 1) #完成交互后强制断开连接,不重用
c.setopt(pycurl.MAXREDIRS, 1) #指定HTTP重定向的最大数为1
c.setopt(pycurl.DNS_CACHE_TIMEOUT, 30)
#创建一个文件对象,以’wb’方式打开,用来存储返回的http头部及页面内容
indexfile = open(os.path.dirname(os.path.realpath(__file__))+"/content.txt","wb")
c.setopt(pycurl.WRITEHEADER, indexfile) #将返回的http头部定向到indexfile文件
c.setopt(pycurl.WRITEDATA, indexfile) #将返回的html内容定向到indexfile文件
c.perform()
NAMELOOKUP_TIME = c.getinfo(c.NAMELOOKUP_TIME) #获取DNS解析时间
CONNECT_TIME = c.getinfo(c.CONN 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









