







由于Scrapy爬虫教程【一】所爬的网站已经更换页面了,所以爬不到数据了,现在更新Scrapy爬虫教程【二】,这次新添加了保存至mysql数据库教程,方便大家学习。
创建数据库
这里使用的是mysql数据库+可视化工具Navicat,没有装的同学可以去百度教程装一下。
创建数据库51job,再创建表jobinfo,内容如下: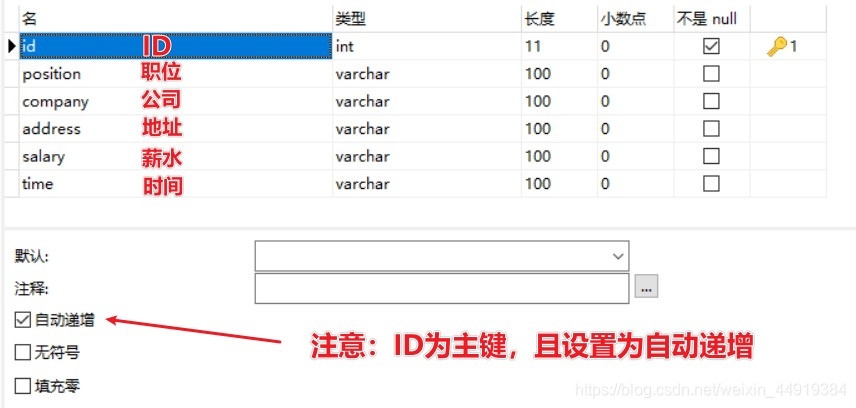
通过python操作Mysql数据库
(1)首先安装Mysql的第三方库pymysql:pip install pymysql,如果pip安装失败的话,可以参考离线安装第三方库教程【教程地址】,这里就不做演示了。
(2)创建insert.py文件,将数据插入至Mysql数据库。
下面展示 代码。
import pymysql
def insert():
# 插入数据到mysql数据库步骤
# 1、连接数据库Connect
connect = pymysql.Connect(host="localhost",user="root",password="tqa123",port=3306,db="51job",charset="utf8")
# 2、SQL语句
sql = "INSERT INTO jobinfo (position,company,address,salary,time) VALUES ('%s','%s','%s','%s','%s')"
# 3、获取SQL执行器(游标)
cursor = connect.cursor()
# 4、执行SQL语句
cursor.execute(sql % ('.NET Winform软件工程师','驰亚科技','上海','0.9-1.8万/月','07-30'))
# 5、提交到数据库
connect.commit()
# 6、关闭资源
cursor.close()
connect.close()
if __name__ == '__main__':
# 调用insert方法
insert()
执行之后,再看看数据库,发现成功插入到数据库中:
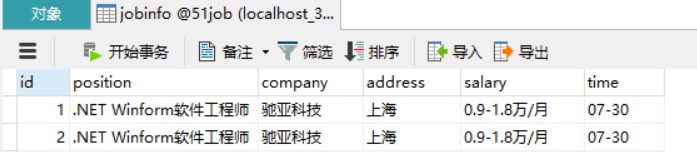
通过Scrapy爬虫框架直接保存至Mysql数据库
(1)打开items.py文件,将我们要获取的(id、position、company、address、salary、time)封装成一个对象。
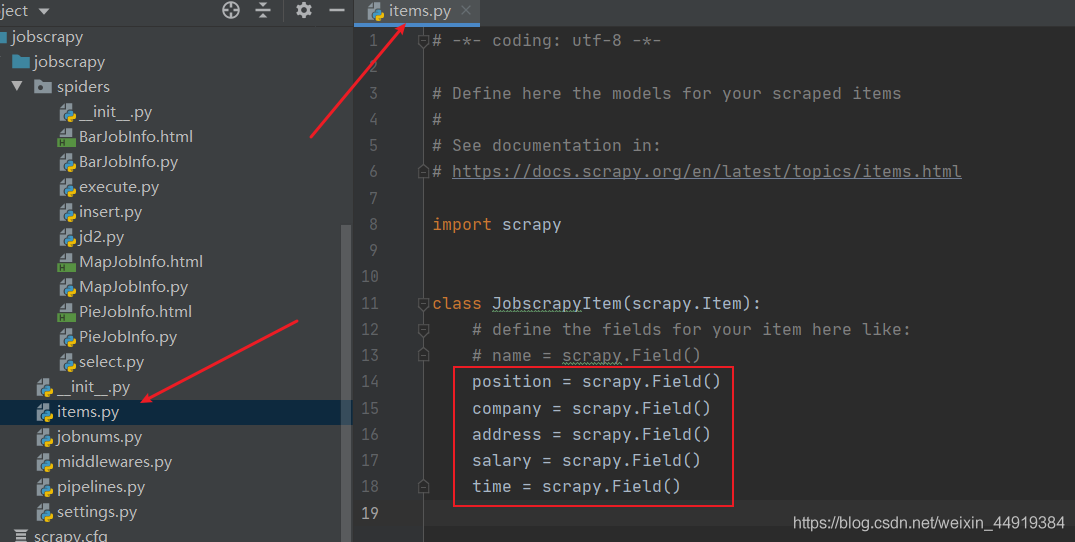
(2)由于教程【一】的网站页面更新了,在这里我们将教程【一】中的文件做一下修改:
A:首先将jobscrapy文件夹下的jd.py名字改成jd2.py,jd2.py的功能是【获取数据、封装数据、返回数据】
B:将jd2.py里面的内容修改为一下代码:
# -*- coding: utf-8 -*-
import scrapy
import re
import json
from jobscrapy.items import JobscrapyItem
class JdSpider(scrapy.Spider):
name = 'jd2'
allowed_domains = ['search.51job.com']
# 这个是只爬取一个页面用的url
# start_urls = ['https://search.51job.com/list/000000,000000,0000,32,9,99,%25E8%25BD%25AF%25E4%25BB%25B6%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=']
# 这个是爬取五个页面用的url
start_urls = []
for i in range(5):
url = f"https://search.51job.com/list/000000,000000,0000,32,9,99,%25E8%25BD%25AF%25E4%25BB%25B6%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,{i + 1}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare="
start_urls.append(url)
def parse(self, response):
# 获取网页的全部源代码
a = response.text
# 从源代码中取出window.__SEARCH_RESULT__ = 后面的内容,到</script>结束
b = re.findall('window.__SEARCH_RESULT__ = (.*)</script>',a)[0]
# 将字符串转换为json格式
c = json.loads(b)
# 获取所有的招聘信息,是列表
d = c['engine_search_result']
for e in d:
position = e['job_name']
company = e['company_name']
address = e['workarea_text'].split("-")[0]
salary = e['providesalary_text']
time = e['updatedate']
# print(position, company, address, salary, time)
# 将零散的数据封装成item对象
item = JobscrapyItem()
item['position'] = position
item['company'] = company
item['address'] = address
item['salary'] = salary
item['time'] = time
# 返回数据
yield item
(3)打开Pipelines.py,该文件的功能是【接收数据,处理数据—保存到数据】,在里面新建一个类MysqlPipeline:
# 自定义mysql数据处理类
class MysqlPipeline:
# 连接数据库
def __init__(self):
self.connect = pymysql.Connect(host="localhost",user="root",password="tqa123",port=3306,db="51job",charset="utf8")
self.cursor = self.connect.cursor()
# 开始处理数据 item就是传递过来的数据
def process_item(self,item,spider):
sql = "INSERT INTO jobinfo (position,company,address,salary,time) VALUES ('%s','%s','%s','%s','%s')"
self.cursor.execute(sql % (item['position'],item['company'],item['address'],item['salary'],item['time']))
self.connect.commit()
# 关闭资源
def close_spider(self,spider):
self.cursor.close()
self.connect.close()
(4)打开Settings.py,设置为如下: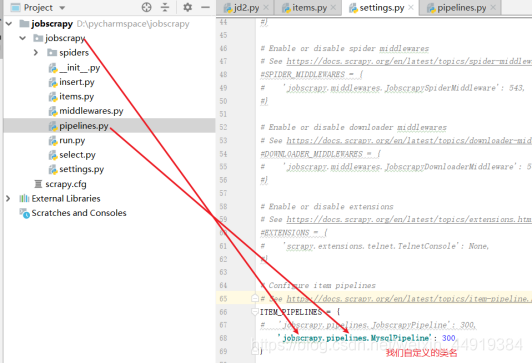
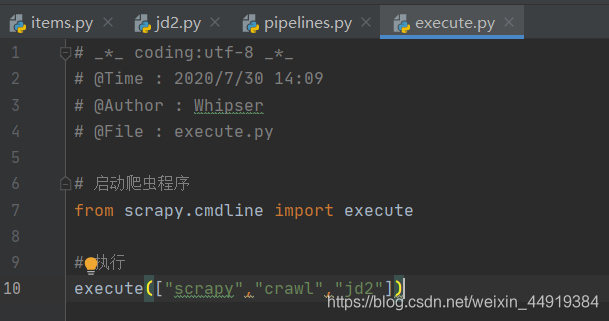
(5)将execute.py文件的“jd”修改为“jd2”,然后执行爬虫程序。
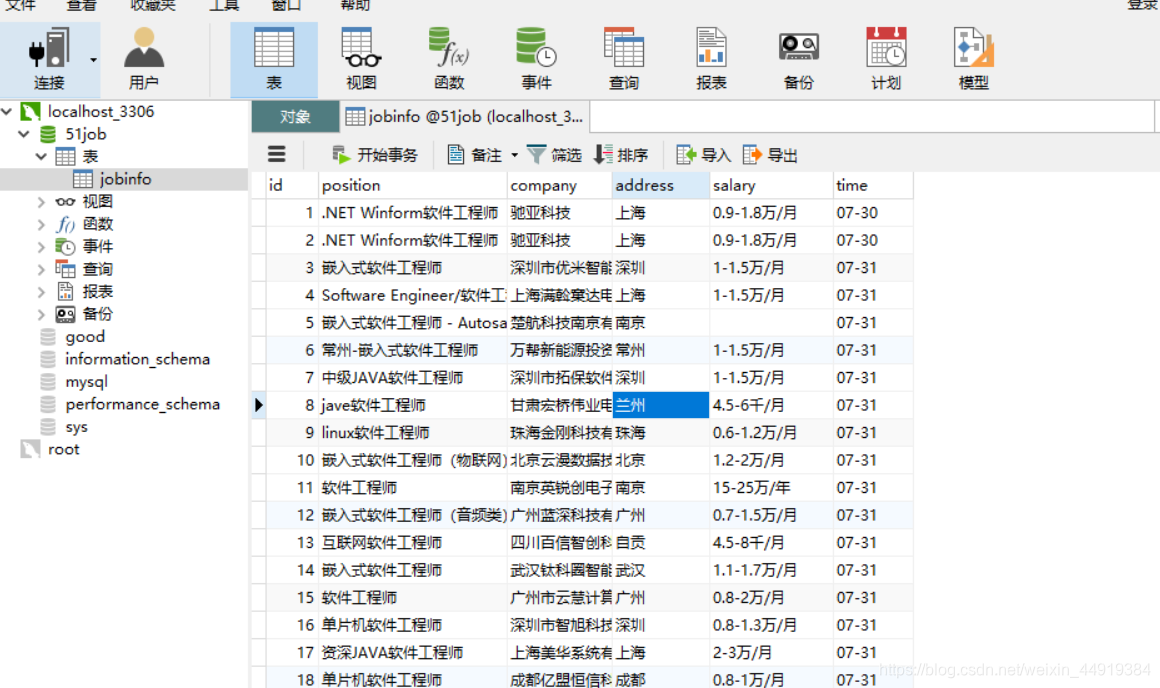
(6)查看爬取到的数据
转载请注明出处















 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











