







读取数据,pd.read_csv默认生成DataFrame对象,需将其转换成Series对象
DataFrame和Series是pandas中最常见的2种数据结构。DataFrame可以理解为Excel中的一张表,Series可以理解为一张Excel表的一行或一列数据。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
# 读取数据,pd.read_csv默认生成DataFrame对象,需将其转换成Series对象
df=pd.read_excel("H:\\wait_data\\shuidi-PV.xlsx")
print(type(df))
# <class 'pandas.core.frame.DataFrame'>
train=df[:365]
test=df[366:]
print("train",len(train),type(train),"test",len(test),type(test))
# train 365 <class 'pandas.core.frame.DataFrame'> test 63 <class 'pandas.core.frame.DataFrame'>
print(df["date"].dtype) # dtype指的是具体的数据(例如:23是int64类型)是什么类型
# datetime64[ns] (excel中是什么类型,仍旧是什么类型)
print(type(df["date"])) # type指的是数据的集合(例如:存放23的列表类型是Series)是什么类型
# <class 'pandas.core.series.Series'>
df["timestamp"]=pd.to_datetime(df["date"],format='%d-%m-%Y')
df.index=df["timestamp"]
df=df.resample("D").mean()
train["timestamp"]=pd.to_datetime(train["date"],format='%d-%m-%Y')
train.index=train["timestamp"]
train=train.resample("D").mean()
test["timestamp"]=pd.to_datetime(test["date"],format='%d-%m-%Y')
test.index=test["timestamp"]
test=test.resample("D").mean()
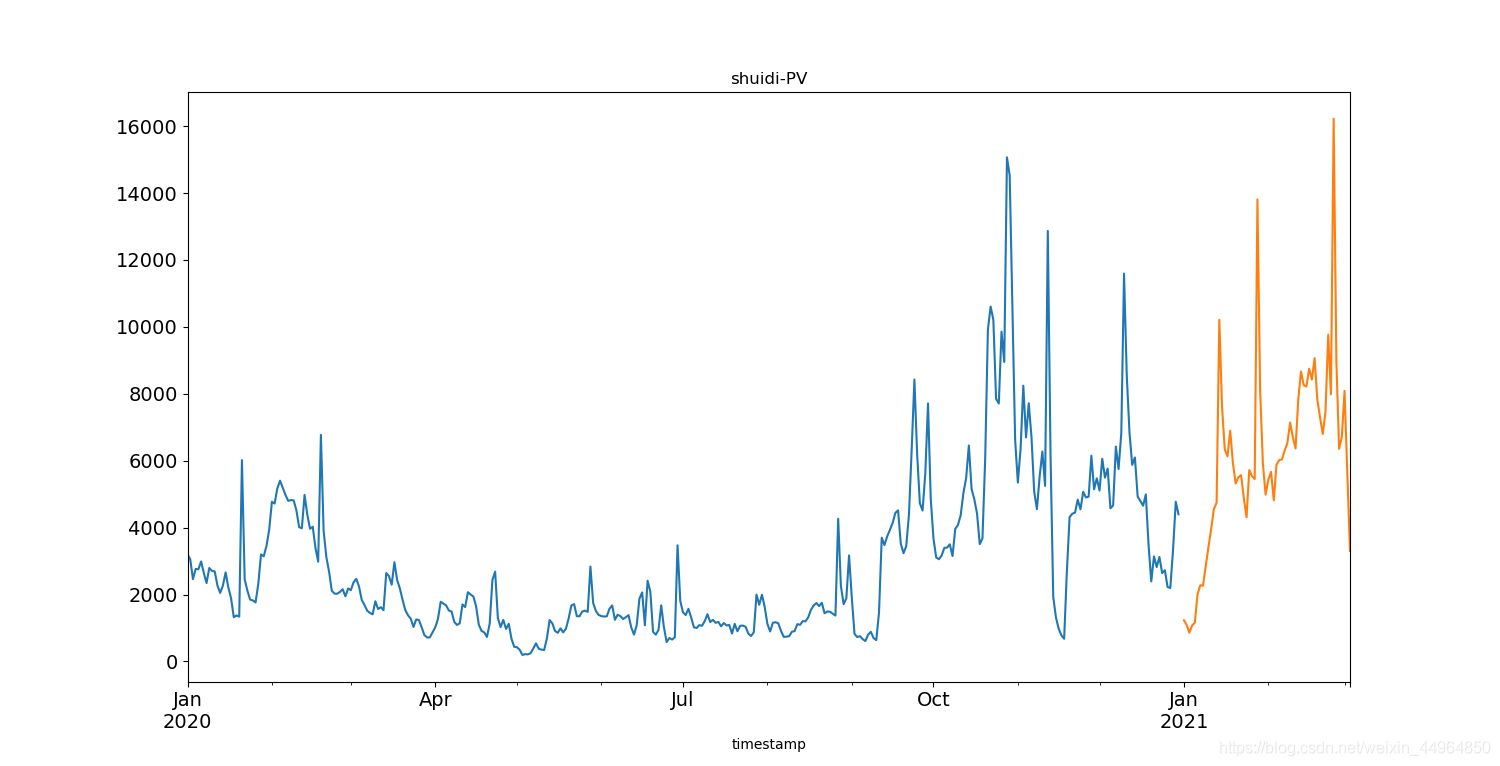
train.PV.plot(figsize=(15,8),title="shuidi-PV",fontsize=14)
test.PV.plot(figsize=(15,8),title="shuidi-PV",fontsize=14)
plt.show()
输出为:训练和测试数据同表
sm.tsa.seasonal_decompose(train["PV"]).plot()
re=sm.tsa.stattools.adfuller(train["PV"]) # ADF检验
print(re)
# (-2.7348366597716742(ADF Test result值), 0.068201554590168(P值), 8, 356, {'1%': -3.448853029339765, '5%': -2.869693115704379, '10%': -2.571113512498422}(置信区间ADF值), 5846.891857248393)
plt.show()
-
1%、%5、%10不同程度拒绝原假设的统计值和ADF Test result的比较,ADF Test result同时小于1%、5%、10%即说明非常好地拒绝该假设,本数据中,adf结果为-2.73, 大于1%,5%level的统计值。所以是不平稳的,需要进行一阶差分后,再进行检验。
-
P-value是否非常接近0,接近0,则是平稳的,否则,不平稳。本数据中,P值结果为0.068, 不接近于0,所以是不平稳的,需要进行一阶差分后,再进行检验。
输出为:
如果不平稳,则做差分:
train_diff=np.diff(train["PV"]) # 默认一阶差分,且是列差分。
# train_diff=train["PV"].diff(periods=2).dropna() # 二阶差分
print("train_diff",len(train_diff),type(train_diff))
re_diff=sm.tsa.stattools.adfuller(train_diff)
print(re_diff)
# train_diff 363 <class 'pandas.core.series.Series'> (-5.111613979032971, 1.328441936429616e-05, 17, 345, {'1%': -3.4494474563375737, '5%': -2.8699542285903887, '10%': -2.5712527305187987}, 5846.136303373881)
直至平稳。














 6645
6645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









