




大家好,我是皮先生!!
今天给大家分享一些关于大模型面试常见的RAG(检索增强生成)相关面试题,希望对大家的面试有所帮助。
往期回顾:
大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题一)
大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题二)
目录
1.在使用RAG时候,有哪些优化策略?
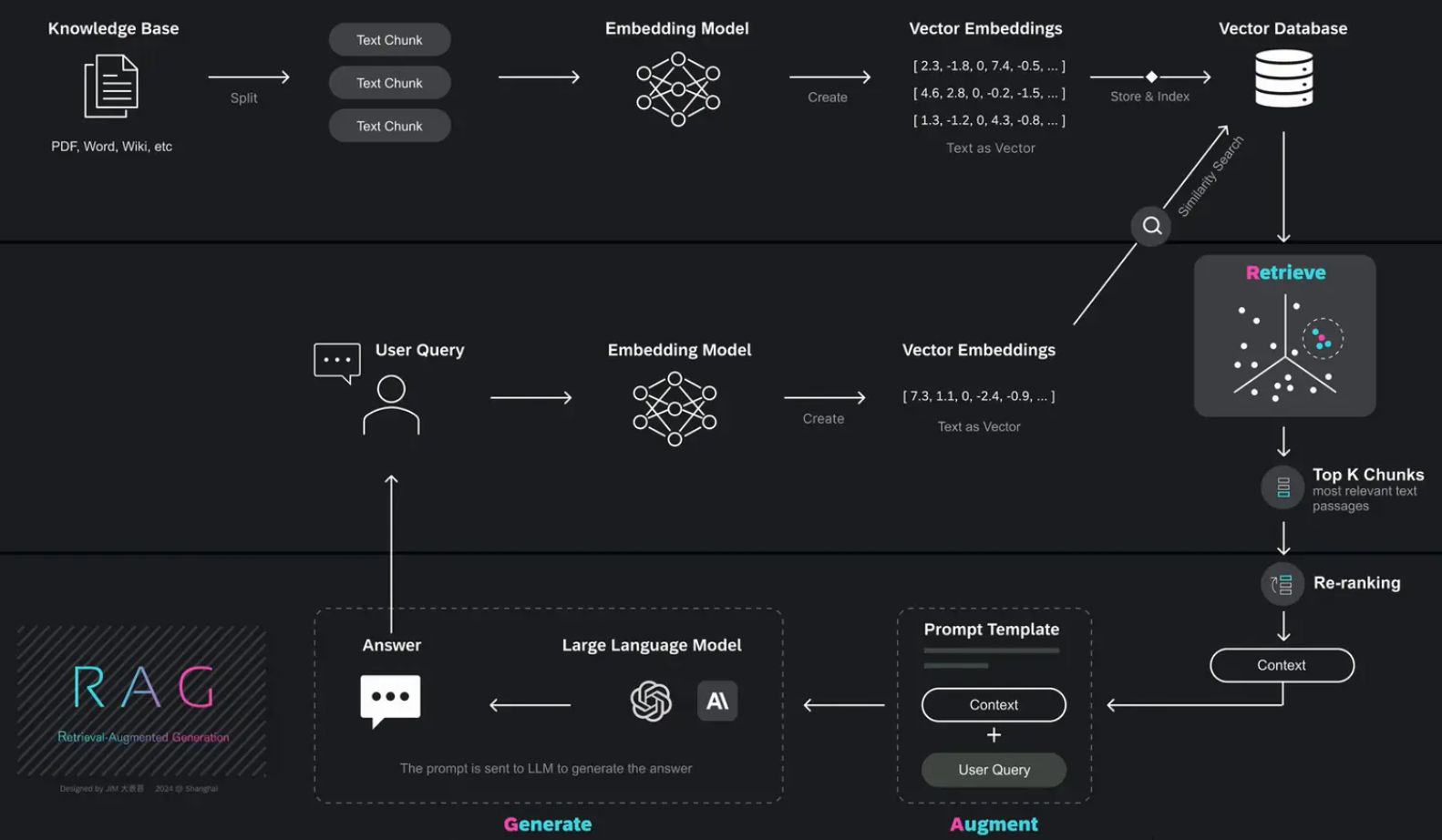 4.查询索引阶段(检索召回、重排)
4.查询索引阶段(检索召回、重排)
4.1.多级索引
- 元数据无法充分区分不同上下文类型的情况下,我们可以考虑进一步尝试多重索引技术。
- 多重索引技术的核心思想是将庞大的数据和信息需求按类别划分,并在不同层级中组织,以实现更有效的管理和检索。
- 这意味着系统不仅依赖于单一索引,而是建立了多个针对不同数据类型和查询需求的索引。
- 例如,可能有一个索引专门处理摘要类问题,另一个专门应对直接寻求具体答案的问题,还有一个专门针对需要考虑时间因素的问题。这种多重索引策略使RAG系统能够根据查询的性质和上下文,选择最合适的索引进行数据检索,从而提升检索质量和响应速度。
- 不过为了引入多重索引技术,我们还需配套加入多级路由机制。
- 多级路由机制确保每个查询被高效引导至最合适的索引。查询根据其特点(如复杂性、所需信息类型等)被路由至一个或多个特定索引。这不仅提升了处理效率,还优化了资源分配和使用,确保了对各类查询的精确匹配。
- 例如,对于查询“最新上映的科幻电影推荐",RAG系统可能首先将其路由至专门处理当前热点话题的索引,然后利用专注于娱乐和影视内容的索引来生成相关推荐。
总的来说,多级索引和路由技术可以进一步帮助我们对大规模数据进行高效处理和精准信息提取,从而提升用户体验和系统的整体性能。
4.2.索引/查询算法
- 我们可以利用索引筛选数据,但说到底我们还是要从筛选后的数据中检索出相关的文本向量。
- 由于向量数据量庞大且复杂,寻找绝对的最优解变得计算成本极高,有时甚至是不可行的。加之,大模型本质上并不是完全确定性的系统,这些模型在搜索时追求的是语义上的相似性--一种合理的匹配即可。从应用的角度来看,这种方法是合理的。
- 例如,在推荐系统中,用户不太可能察觉到或关心是否每个推荐的项目都是绝对的最佳匹配;
- 他们更关心的是推荐是否总体上与他们的兴趣相符。
- 因此查找与查询向量完全相同的项通常不是目标,而是要找到“足够接近“或“相似”的项,这便是最近邻搜索(ApproximateNearest Neighbor Search,ANNS)。这样做不仅能满足需求,还为检索优化提供了巨大的优化潜力。
下面会介绍一些常见的向量搜索算法以便大家在具体使用场景中进行取舍。
a.聚类
- 当我们在网上购物时,通常不会在所有商品中盲目搜索,而是会选择进入特定的商品分类。
- 比如“电子产品“或“服饰”,在一个更加细分的范畴内寻找心仪的商品。这个能帮我们大大缩小搜索范围。
- 同样这种思路,聚类算法可以帮我们实现这个范围的划定。就比如说我们可以用K-means算法把向量分为数个簇,当用户进行查询的时候,我们只需找到距离查询向量最近的簇,然后再这个簇中进行搜索。
- 当然聚类的方法并不保证一定正确,如下图,查询距离黄色簇的中心点更近,但实际上距离查询向量最近的,即最相似的点在紫色类。
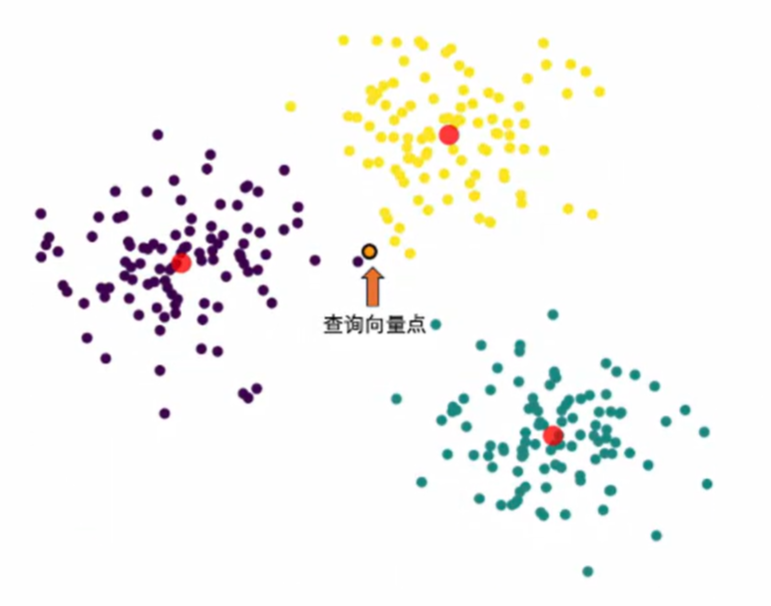
- 有一些缓解这个问题的方法,例如增加聚类的数量,并指定搜索多个簇。
- 然而,任何提高结果质量的方法都不可避免地会增加搜索的时间和资源成本。
- 实际上,质量和速度之间存在着一种权衡关系。我们需要在这两者之间找到一个最优的平衡点,或者找到一个适合特定应用场景的平衡。不同的算法也对应着不同的平衡。
b.位置敏感哈希
- 沿着缩小搜索范围的思路,位置敏感哈希算法是另外一种实现的策略。
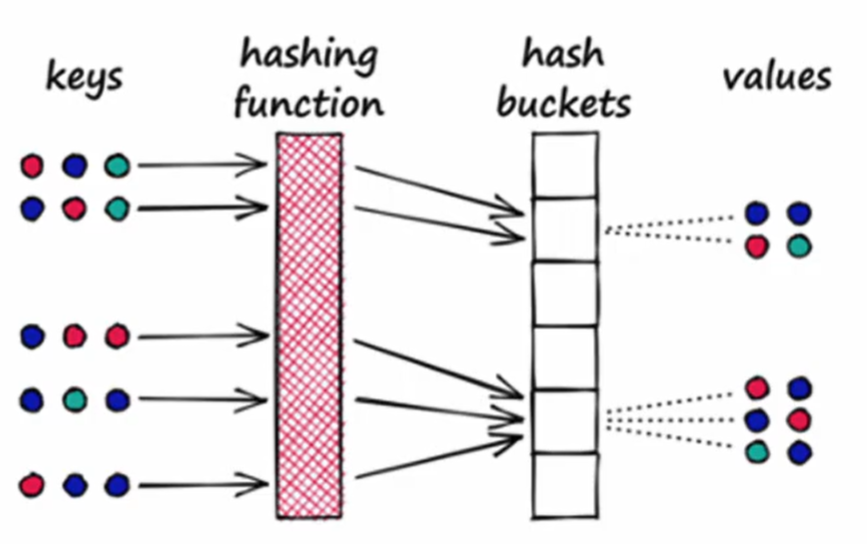
- 在传统的哈希算法中,我们通常希望每个输入对应一个唯一的输出值,并努力减少输出值的重复。。
- 然而,在位置敏感哈希算法中,我们的目标恰恰相反,我们需要增加输出值碰撞的概率。
- 这种碰撞正是分组的关键,哈希值相同的向量将被分配到同一个组中,也就是同一个“桶"里。此外,这种哈希函数还需满足另一个条件:空间上距离较近的向量更有可能被分入同一个桶。这样在进行搜索时,只需获取目标向量的哈希值,找到相应的桶,并在该桶内进行搜索即可。
c.量化乘积
- 上面我们介绍了两种牺牲搜索质量来提高搜索速度的方法,但除了搜索速度外,内存开销也是一个巨大挑战。
- 在实际应用场景中,每个向量往往都有上千个维度,数据数量可达上亿。每条数据都对应着一个实际的信息,因此不可能删除数据来减少内存开销,那唯一的选择只能是把每个数据本身大小缩减。
- 有一种乘积量化的方法可以帮我们完成这点。
- 图像有一种有损压缩的方法是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2244
2244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









