







Selenium介绍
Selenium 是一个用于Web应用程序测试的工具,Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等,它在python的领域里的引用能使初学者大大的省去解析网页中代加密的一些麻烦。
*特别适合小白练手
Selenium安装
1.首先要下载一个python的环境,最新的python环境里有继承好的pip工具包(这块知识见python官网操作)
2.下载浏览器的驱动(我这边以谷歌浏览器,你们也可以下载其他的)
打开https://npm.taobao.org/mirrors/chromedriver链接(这个是谷歌浏览器的驱动),先找到自身浏览器的版本进行下载,找自身浏览器版本方法见下图1,图2

图1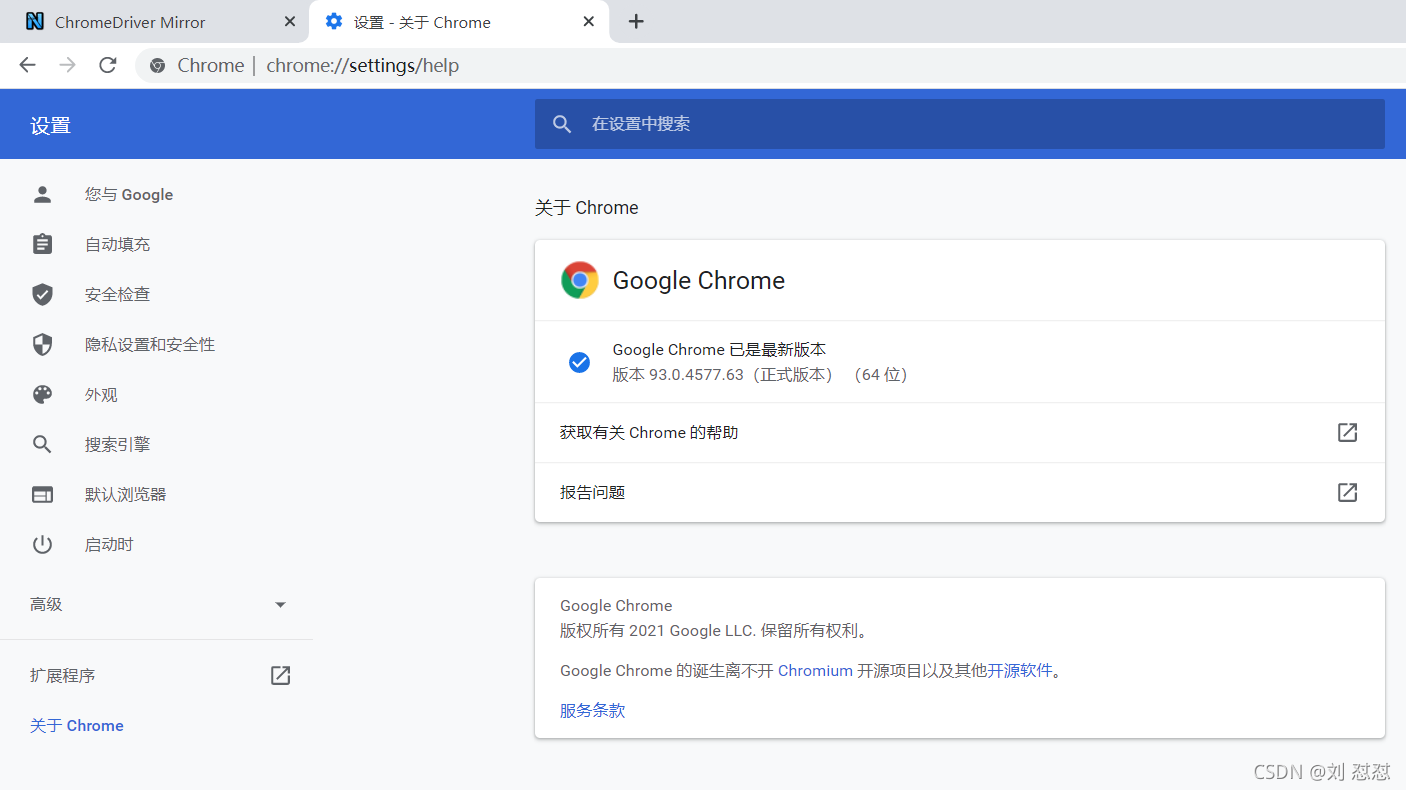
图2
我这里的是93.0.4577.63接着在驱动下载页面下载自己的版本的驱动,(如果没有自己的版本就找这个版本之前的一个) 见下图3
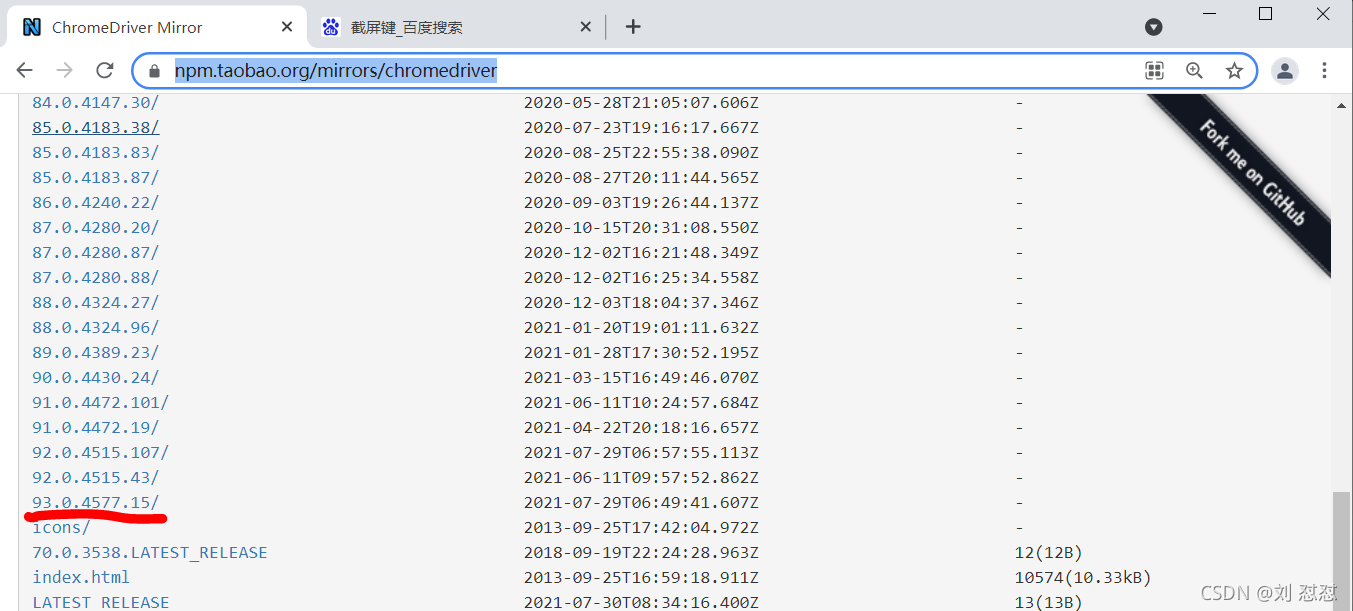
图3
下载好后把解压好的包安装在自己的python环境下。
找python环境目录的方法:1.打开python--------右击----选择运行 图4 做记号的就是我的路径
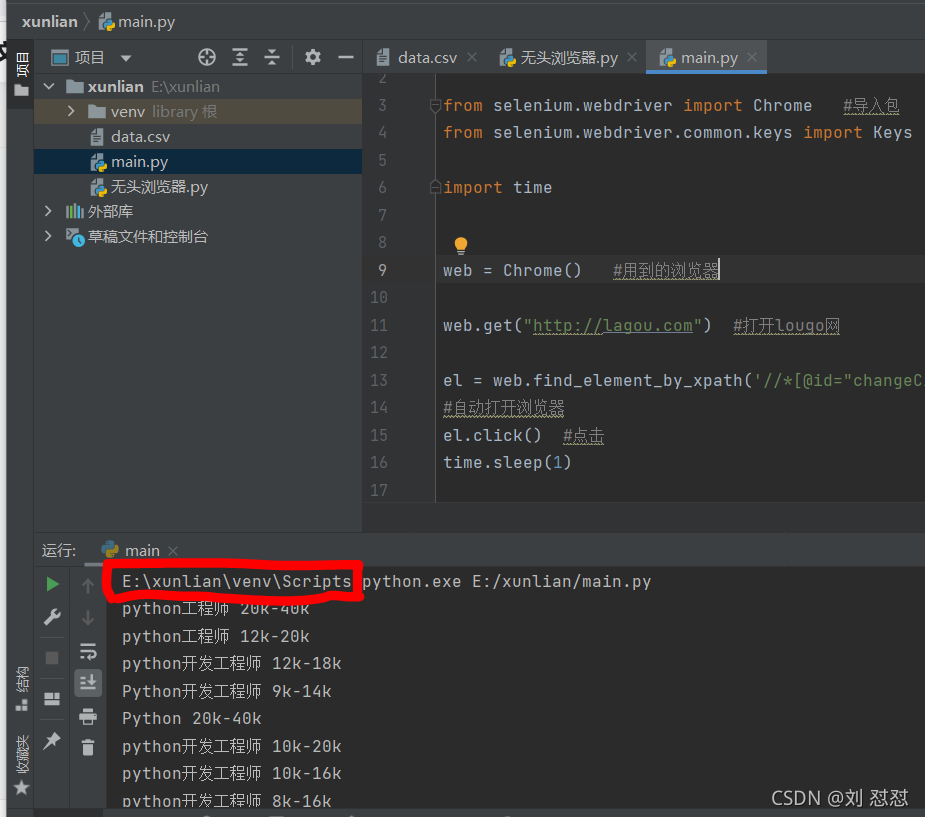
图4
把下好的复制到相应的路径下就可以了如图5
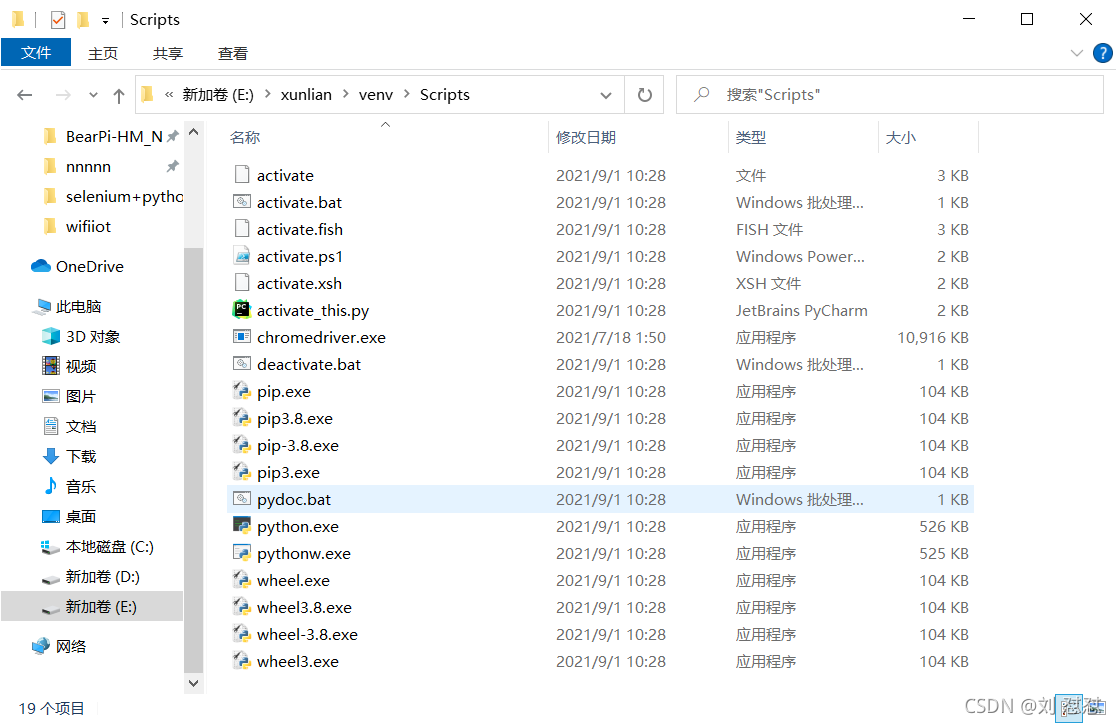
图5
电影榜单的抓取
工具:PyCharm 2021.2
python编译环境:python3.8
首先导入需要的依赖包 在python终端中打入
pip install selenium解析网页:
首先打开网址https://www.endata.com.cn/BoxOffice/BO/Year/index.html 按F12打开代码解释器
进行一个解析,我们测试代码是否能自动的打开浏览器
from selenium.webdriver import Chrome
web = Chrome()
web.get("https://www.endata.com.cn/BoxOffice/BO/Year/index.html")
经过测试是能打开需要的网址的,接着我们要爬的是每一年度第一的观影榜单,我们利用xpath进行一个定位。
sel_el = web.find_element_by_xpath('//*[@id="OptionDate"]')#定位一个下拉列表xpath不会定位的见下图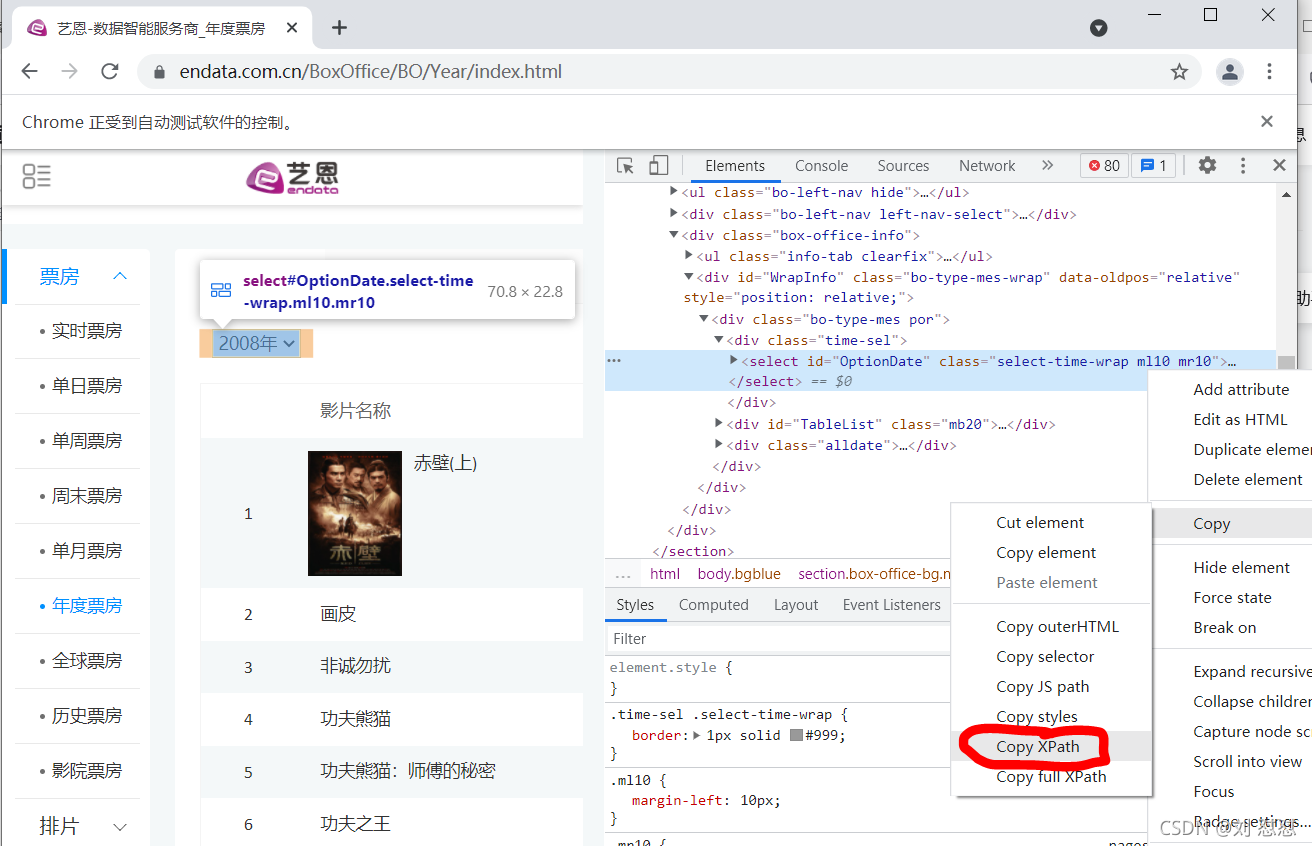
定位到的位置
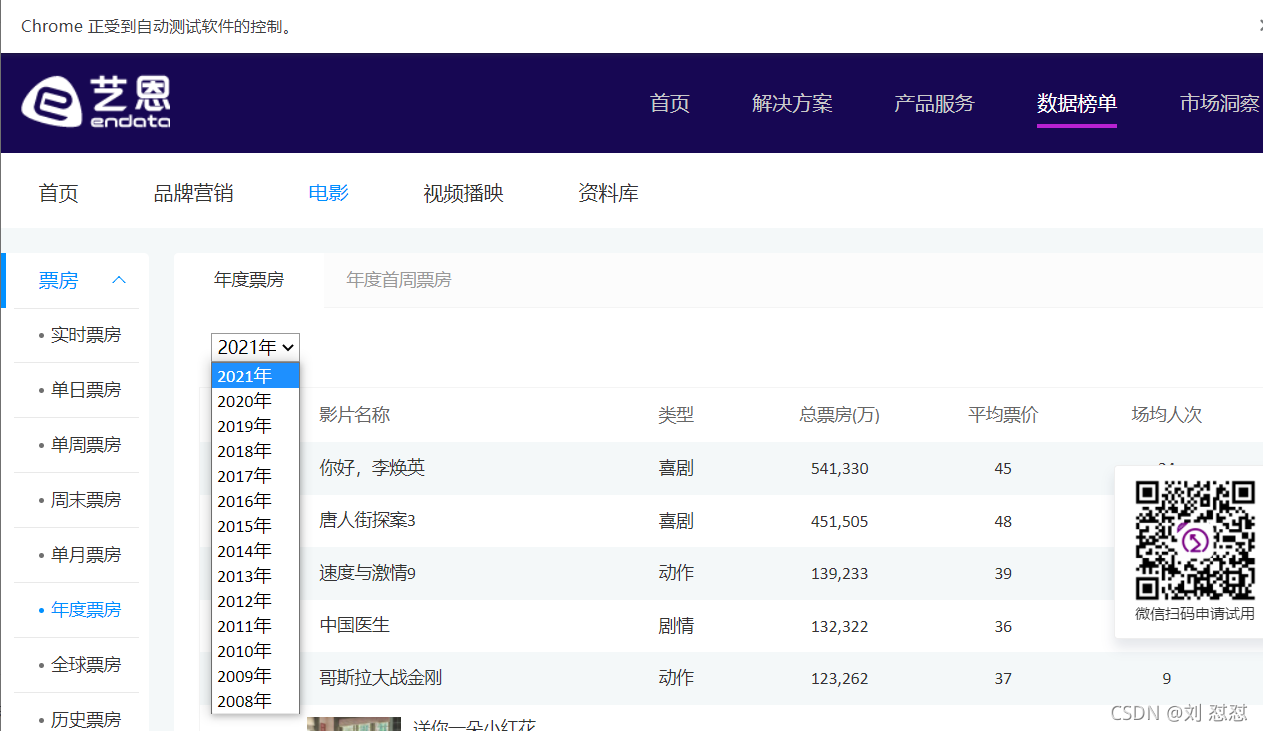
我们观察到这里有一个下拉列表,我们需要对下拉列表进行一个封装然后根据索引(这里直接根据options)进行一个遍历查找(这块涉及到前端知识点下拉列表)
sel = Select(sel_el)
for i in range(len(sel.options)):
sel.select_by_index(i)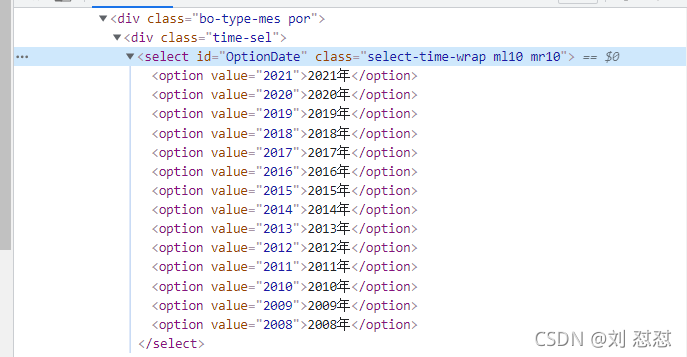
最后找到你要爬取的内容,我这爬取的是电影名称和票房
table = web.find_element_by_xpath('//*[@id="TableList"]/table/tbody/tr[1]/td[2]/a/p').text
piaofang = web.find_element_by_xpath('//*[@id="TableList"]/table/tbody/tr[1]/td[4]').text把爬取的内容保存到当前目录文件下,最后一部进行代码段的整合
整合代码段:
import time
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.select import Select
web =Chrome()
web.get("https://www.endata.com.cn/BoxOffice/BO/Year/index.html")
with open('data.csv', 'w', encoding='utf-8') as f: #打开文件,进行写入
sel_el = web.find_element_by_xpath('//*[@id="OptionDate"]')#定位一个下拉列表
#对元素进行包装
sel = Select(sel_el)
for i in range(len(sel.options)): #前端的下拉列表的
sel.select_by_index(i)
time.sleep(2) #进行一个2s的休眠
table = web.find_element_by_xpath('//*[@id="TableList"]/table/tbody/tr[1]/td[2]/a/p').text #定位要找的东西位置
piaofang = web.find_element_by_xpath('//*[@id="TableList"]/table/tbody/tr[1]/td[4]').text
nianfen = web.find_element_by_xpath('//*[@id="OptionDate"]/option[1]').text
f.write(table)
f.write('\r')
f.write(piaofang)
f.write('\r\n')
f.close()
web.close()
print("爬取完毕")
效果展示:
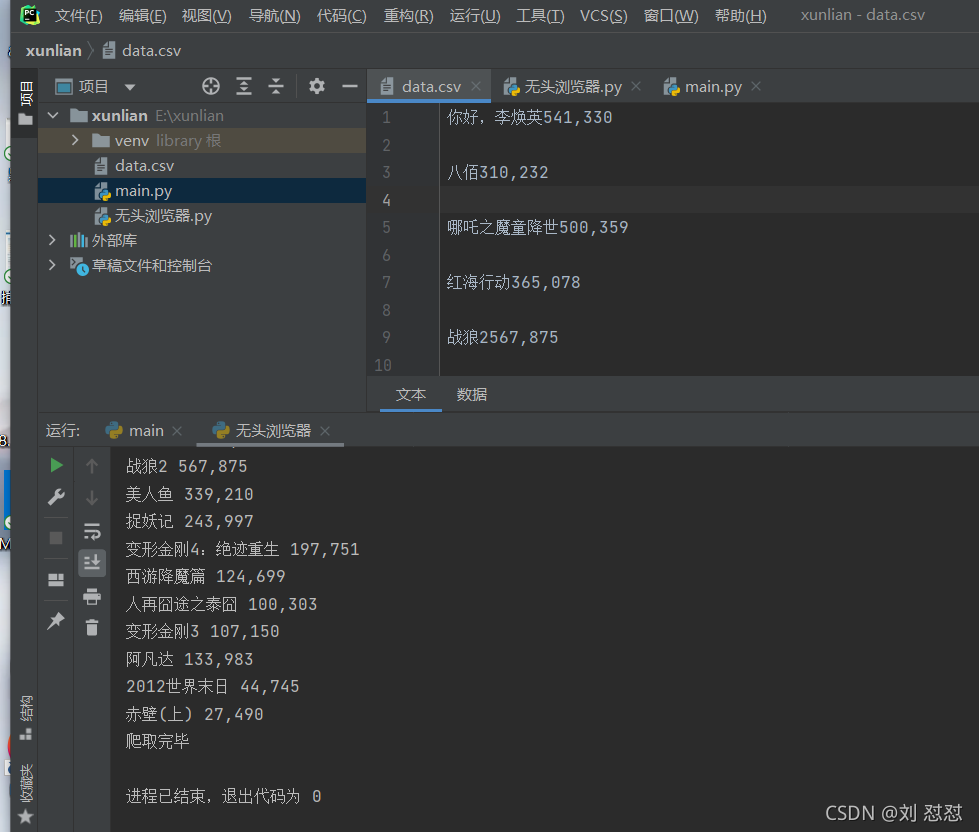
总结:
安装驱动有不明白的地方可以提出来哦,让我们一起努力一起学习,有那写的不对的还请各位大佬指正,感觉写的还行的,给个小赞,小编也有写下去的动力
💖💖💖💖💖💖

💖💖💖💖💖💖💖















 2636
2636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











