







普通卷积
可以直观的理解为一个带颜色小窗户(卷积核)在原始的输入图像一步一步的挪动,来通过加权计算得到输出特征。 如下图。
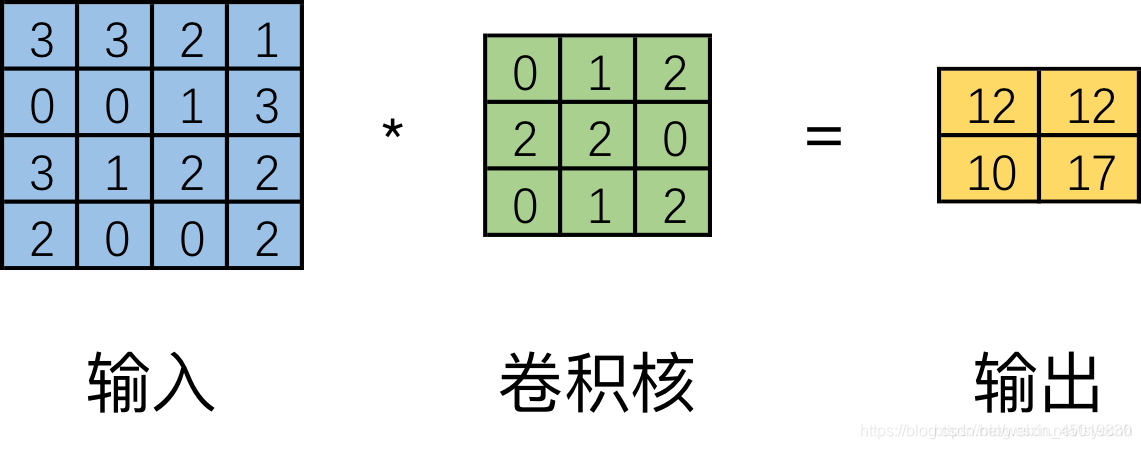
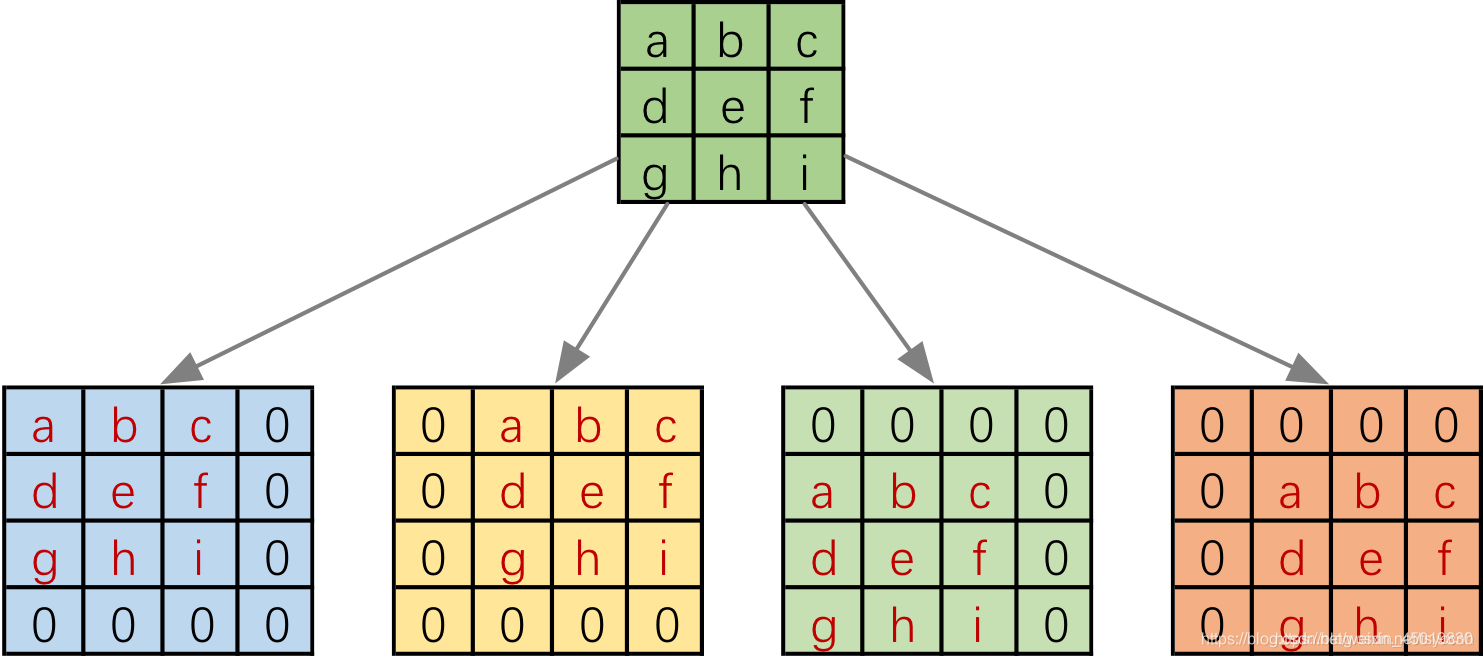
但是实际在计算机中计算的时候,并不是像这样一个位置一个位置的进行滑动计算,因为这样的效率太低了。计算机会将卷积核转换成等效的矩阵,将输入转换为向量。通过输入向量和卷积核矩阵的相乘获得输出向量。输出的向量经过整形便可得到我们的二维输出特征。具体的操作如下图所示。由于我们的3x3卷积核要在输入上不同的位置卷积4次,所以通过补零的方法将卷积核分别置于一个4x4矩阵的四个角落。这样我们的输入可以直接和这四个4x4的矩阵进行卷积,而舍去了滑动这一操作步骤。
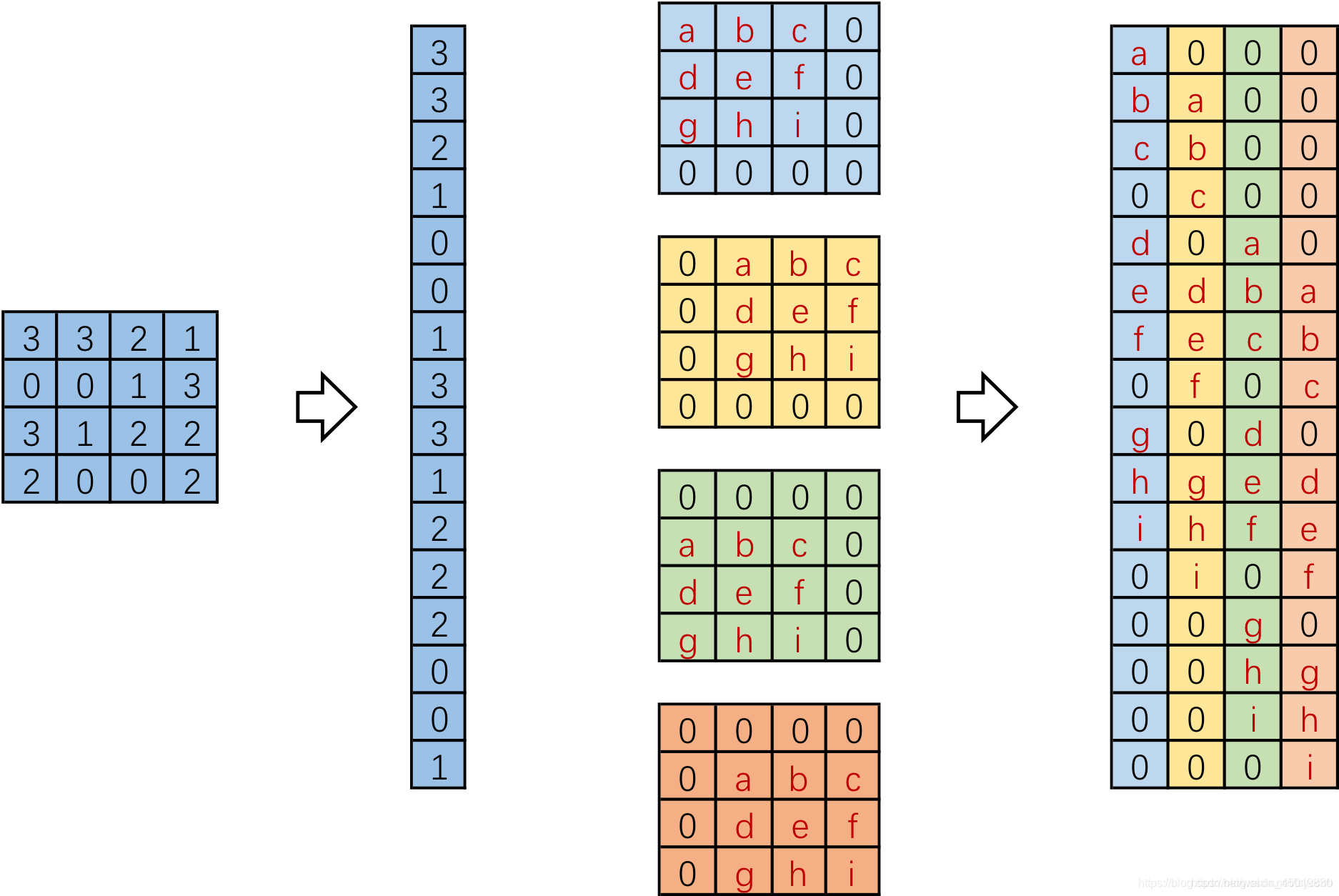
进一步的,我们将输入拉成长向量,四个4x4卷积核也拉成长向量并进行拼接,如下图。
我们记向量化的图像为I,向量化的卷积矩阵为C, 输出特征向量为 O
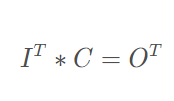
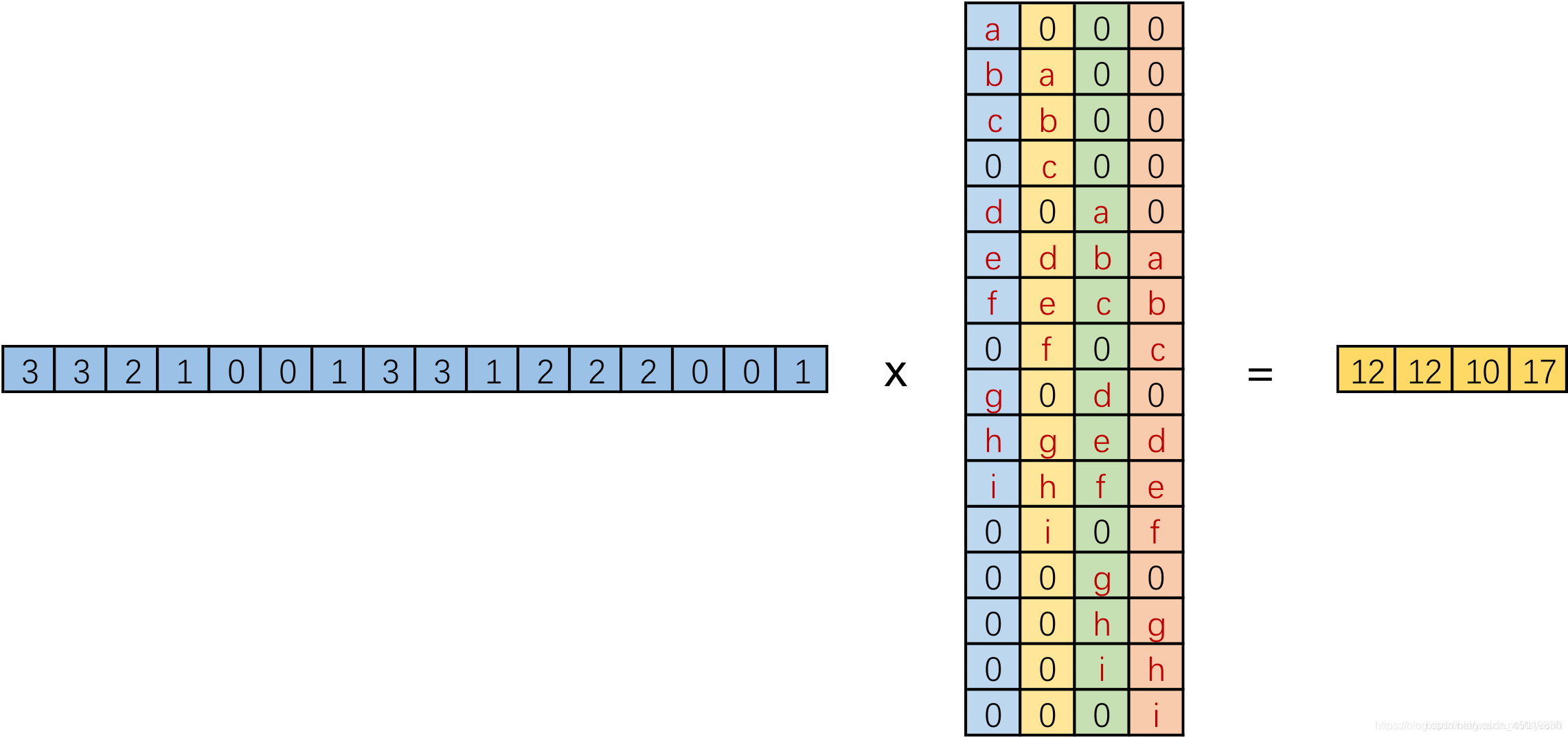
我们将一个1x16的行向量乘以16x4的矩阵,得到了1x4的行向量。那么反过来将一个1x4的向量乘以一个4x16的矩阵是不是就能得到一个1x16的行向量呢? 没错,这便是转置卷积的思想。
转置卷积
在数学上,转置卷积的操作也非常简单,把正常卷积的操作反过来即可。
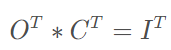

这里需要注意的是这两个操作并不是可逆的,对于同一个卷积核,经过转置卷积操作之后并不能恢复到原始的数值,保留的只有原始的形状。
深度可分离卷积
假设我们的背景,输入图片格式是:12x12x3。即图片大小12*12,3通道(RGB)。滤波器窗口大小是5x5x3。这样的话,得到的输出图像大小是8x8x1(padding模式是valid)。
我们来对比一下普通卷积和深度可分离卷积。
(1) 普通卷积
仅提取一个属性时,滤波器个数为1.
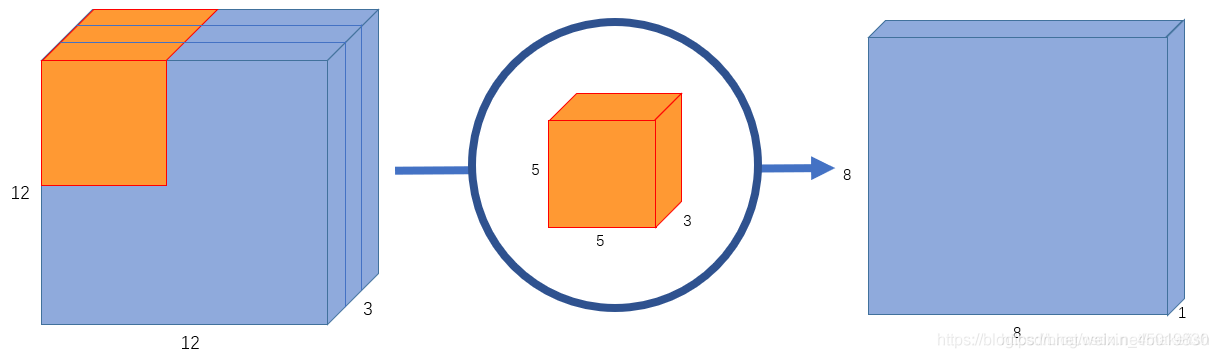
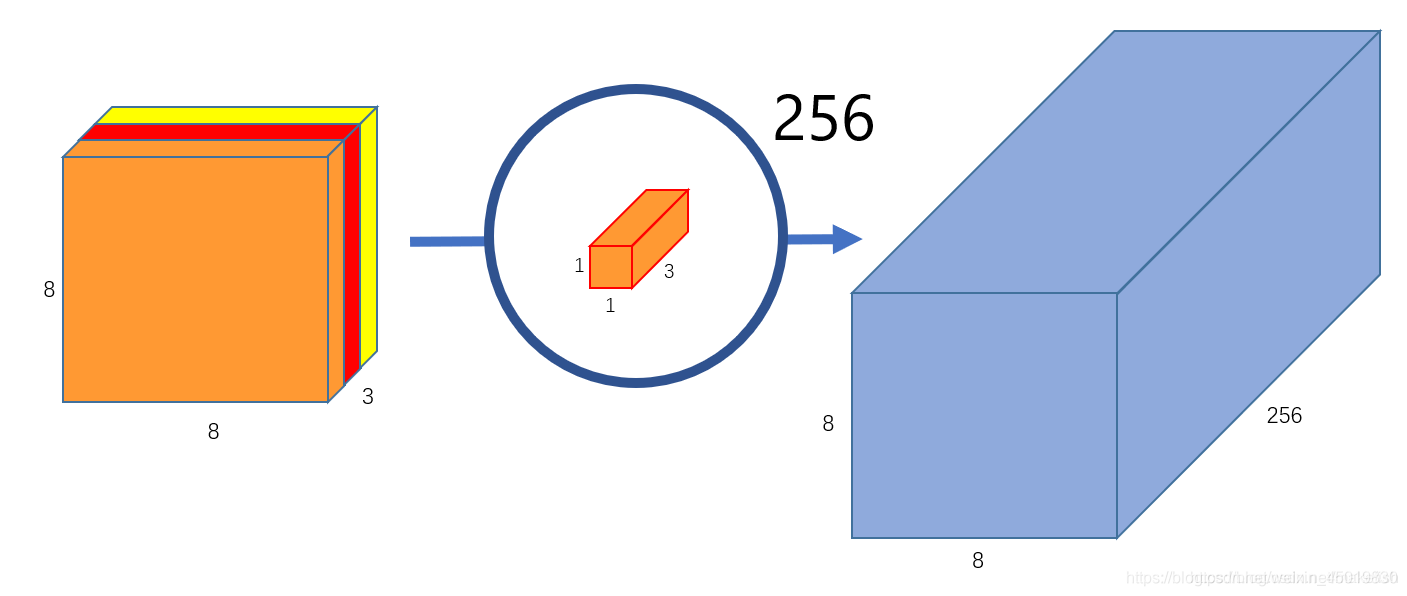
如果希望获取图片更多的属性,譬如要提取256个属性,则需要256个滤波器。
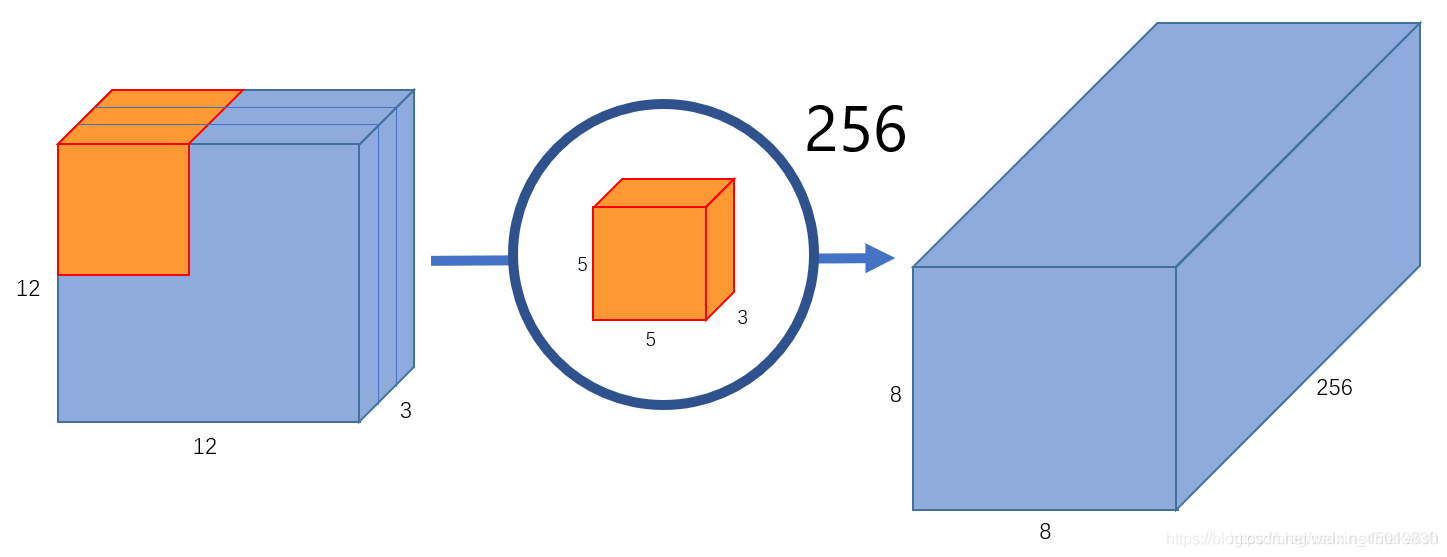
正常卷积的问题在于,它的卷积核是针对图片的所有通道设计的(通道的总数就是depth)。那么,每要求增加检测图片的一个属性,卷积核就要增加一个。所以正常卷积,卷积参数的总数=属性的总数x卷积核的大小。
(2) 深度可分离卷积
深度可分离卷积的方法有所不同。正常卷积核是对3个通道同时做卷积。也就是说,3个通道,在一次卷积后,输出一个数。
深度可分离卷积分为两步:
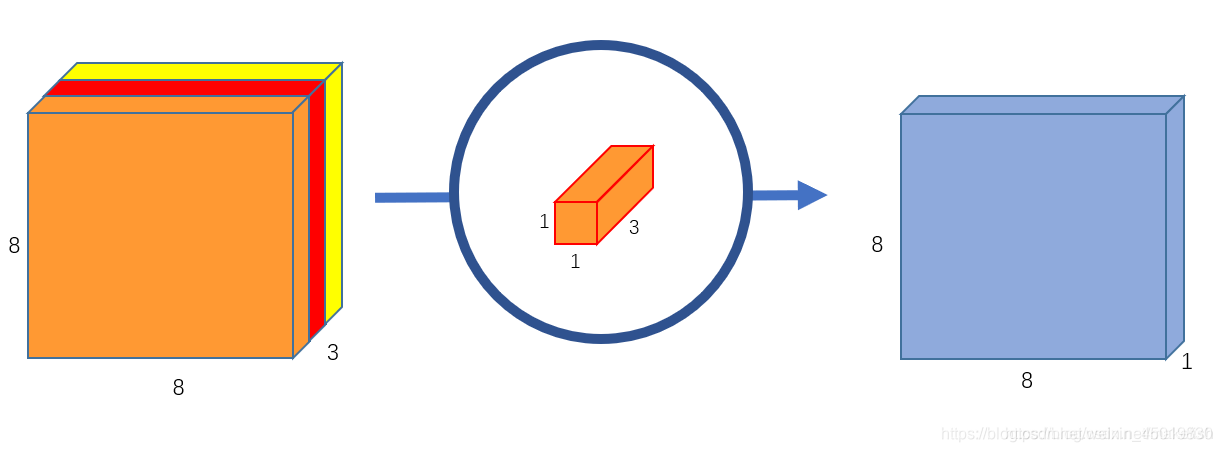
第一步用三个卷积对三个通道分别做卷积,这样在一次卷积后,输出3个数。这输出的三个数,再通过一个1x1x3的卷积核(pointwise核),得到一个数。所以深度可分离卷积其实是通过两次卷积实现的。
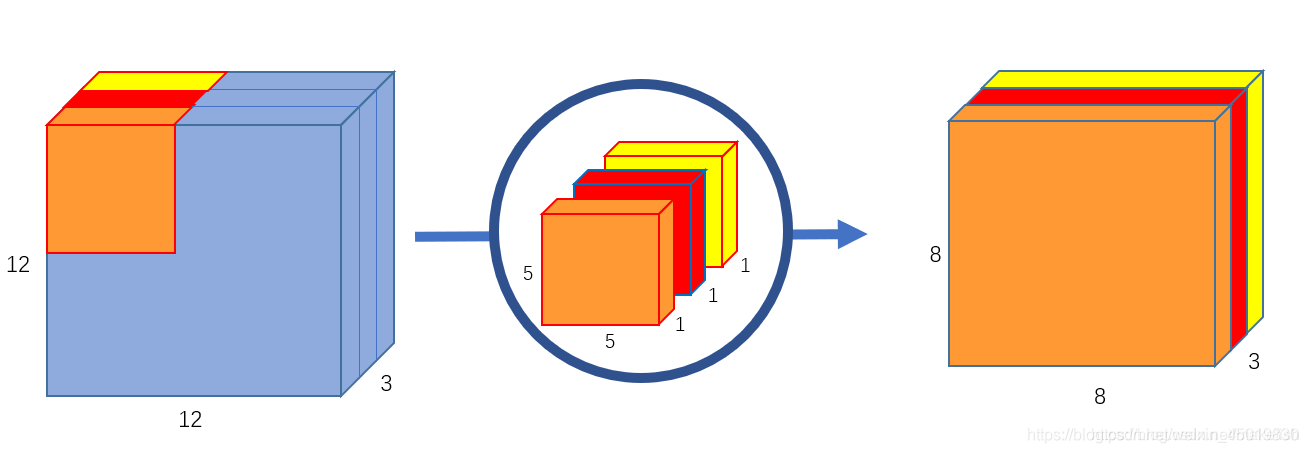
第二步对三个通道分别做卷积,输出三个通道的属性:
如果要提取更多的属性,则需要设计更多的1x1x3卷积核心就可以(图片引用自原网站。感觉应该将8x8x256那个立方体绘制成256个8x8x1,因为他们不是一体的,代表了256个属性):
(3)总结
通过例子对比可分离卷积和普通卷积的区别
假设一个3×3大小的filter,其输入通道为16,输出通道为32
普通卷积的参数: (3×3×16)×32=4068
可分离卷积: 先考虑区域,即每个通道对应一个3×3×1大小的filter, 然后考虑通道对应32个1×1×16大小的filter 参数计算: (3×3×1)×16 + (1×1×16)×32=656
显然深度卷积参数少!
- 如果仅仅是提取一个属性,深度可分离卷积的方法,不如正常卷积。
分组卷积(Group convolution)
(1) 介绍
在说明分组卷积之前我们用一张图来体会一下一般的卷积操作。
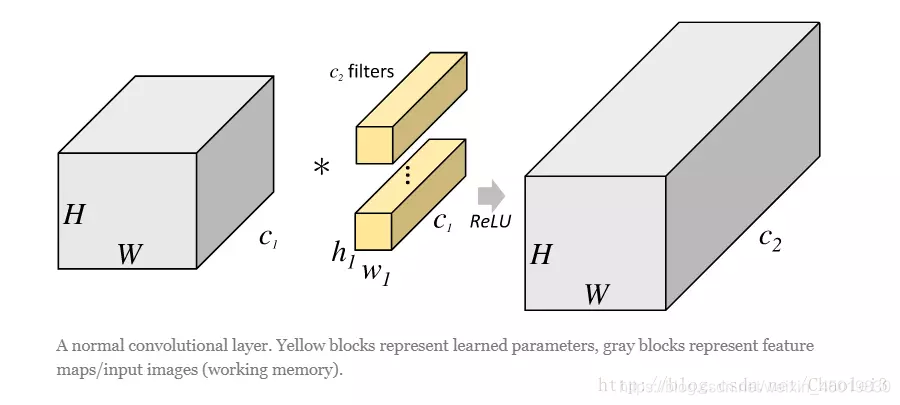
从上图可以看出,一般的卷积会对输入数据的整体一起做卷积操作,即输入数据:H1×W1×C1;而卷积核大小为h1×w1,一共有C2个,然后卷积得到的输出数据就是H2×W2×C2。这里我们假设输出和输出的分辨率是不变的。主要看这个过程是一气呵成的,这对于存储器的容量提出了更高的要求。
但是分组卷积明显就没有那么多的参数。先用图片直观地感受一下分组卷积的过程。对于上面所说的同样的一个问题,分组卷积就如下图所示。
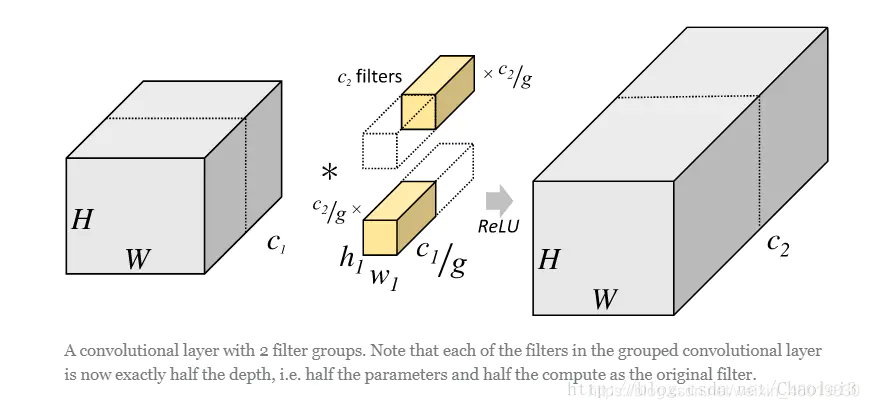
可以看到,图中将输入数据分成了2组(组数为g),需要注意的是,这种分组只是在深度上进行划分,即某几个通道编为一组,这个具体的数量由(C1/g)决定。因为输出数据的改变,相应的,卷积核也需要做出同样的改变。即每组中卷积核的深度也就变成了(C1/g),而卷积核的大小是不需要改变的,此时每组的卷积核的个数就变成了(C2/g)个,而不是原来的C2了。然后用每组的卷积核同它们对应组内的输入数据卷积,得到了输出数据以后,再用concatenate的方式组合起来,最终的输出数据的通道仍旧是C2。也就是说,分组数g决定以后,那么我们将并行的运算g个相同的卷积过程,每个过程里(每组),输入数据为H1×W1×C1/g,卷积核大小为h1×w1×C1/g,一共有C2/g个,输出数据为H2×W2×C2/g。
(2) 分组卷积具体的例子
从一个具体的例子来看,Group conv本身就极大地减少了参数。比如当输入通道为256,输出通道也为256,kernel size为3×3,不做Group conv参数为256×3×3×256。实施分组卷积时,若group为8,每个group的input channel和output channel均为32,参数为8×32×3×3×32,是原来的八分之一。而Group conv最后每一组输出的feature maps应该是以concatenate的方式组合。
Alex认为group conv的方式能够增加 filter之间的对角相关性,而且能够减少训练参数,不容易过拟合,这类似于正则的效果。
参考:
https://www.jianshu.com/p/20150e44bde8
https://blog.csdn.net/evergreenswj/article/details/92764387














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









