







面试题
1、不考虑反射,String类型变量所指向内存空间中的内容是不能被改变的(√)
- 首先我们来看一下什么是不可变对象?
如果一个对象在创建之后就不能再改变它的状态,那么这个对象是不可变的;不能改变状态的意思是,不能改变对象内的 成员变量,包括基本数据类型变量的值不能改变,引用类型的变量不能指向其他的对象,引用类型指向的对象的状态也不能改变。
- final关键字的作用:
如果要创建一个不可变对象,关键一步就是要将所有的成员变量声明为final类型。所以下面简单回顾一下final关键字的作用:
final修饰类,表示该类不能被继承,俗称断子绝孙类,该类的所有方法自动地成为final方法;
final修饰方法,表示子类不可重写该方法;
final修饰基本数据类型变量,表示该变量为常量,值不能再修改;
final修饰引用类型变量,表示该引用在构造对象之后不能指向其他的对象,但该引用指向的对象的状态可以改变;
- String类不可变性的分析,先看下面这段代码:
String s = "abc"; //(1)
System.out.println("s = " + s);
s = "123"; //(2)
System.out.println("s = " + s);
// 打印结果为:
s = abc
s = 123
看到这里,你可能对String是不可变对象产生了疑惑,因为从打印结果可以看出,s的值的确改变了。其实不然,因为s只是一个String对象的引用,并不是String对象本身;当执行(1)处这行代码之后,会先在方法区的运行时常量池创建一个String对象"abc",然后在Java栈中创建一个String对象的引用s,并让s指向"abc";
当执行完(2)处这行代码之后,会在方法区的运行时常量池创建一个新的String对象"123",然后让引用s重新指向这个新的对象,而原来的对象"abc"还在内存中,并没有改变;
- String类不可变性的原理:
要理解String类的不可变性,首先看一下String类中都有哪些成员变量。在JDK1.8中,String的成员变量主要有以下几个:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[]; /** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L; /**
* Class String is special cased within the Serialization Stream Protocol.
*
* A String instance is written into an ObjectOutputStream according to
* <a href="{@docRoot}/../platform/serialization/spec/output.html">
* Object Serialization Specification, Section 6.2, "Stream Elements"</a>
*/
private static final ObjectStreamField[] serialPersistentFields = new ObjectStreamField[0];
- 首先可以看到,String类使用了final修饰符,表明String类是不可继承的;
- 然后,我们主要关注String类的成员变量value,value是char[]类型,因此String对象实际上是用这个字符数组进行封装的;
- 再看value的修饰符,使用了private,也没有提供setter方法,所以在String类的外部不能修改value,同时value也使用了final进行修饰,那么在String类的内部也不能修改value,但是上面final修饰引用类型变量的内容提到,这只能保证value不能指向其他的对象,但value指向的对象的状态是可以改变的;
- 通过查看String类源码可以发现,String类不可变,关键是因为SUN公司的工程师,在后面所有String的方法里都很小心的没有去动字符数组里的元素;
- 所以String类不可变的关键都在底层的实现,而不仅仅是一个final;
- String对象真的不可变吗?
- 上面提到,value虽然使用了final进行修饰,但是只能保证value不能指向其他的对象,但value指向的对象的状态是可以改变的;
- 也就是说,可以修改value指向的字符数组里面的元素。因为value是private类型的,所以只能使用反射来获取String对象的value属性,再去修改value指向的字符数组里面的元素。通过下面的代码进行验证:
String s = "Hello World";
System.out.println("s = " + s);//获取String类中的value属性
Field valueField = String.class.getDeclaredField("value");//改变value属性的访问权限
valueField.setAccessible(true);//获取s对象上的value属性的值
char[] value = (char[]) valueField.get(s);//改变value所引用的数组中的第6个字符
value[5] = '_';
System.out.println("s = " + s);
//打印结果为:
s = Hello World
s = Hello_World
在上述代码中,s始终指向同一个String对象,但是在反射操作之后,这个String对象的内容发生了变化。也就是说,通过反射是可以修改String这种不可变对象的;
- 为什么String要设计成不可变的?
在Java中,将String设计成不可变的是综合考虑到内存、同步、数据结构及安全等各种因素的结果,下文将为各种因素做一个小结。
- 1、运行时常量池的需要
String s = "abc";
执行上述代码时,JVM首先在运行时常量池中查看是否存在String对象“abc”,如果已存在该对象,则不用创建新的String对象“abc”,而是将引用s直接指向运行时常量池中已存在的String对象“abc”;如果不存在该对象,则先在运行时常量池中创建一个新的String对象“abc”,然后将引用s指向运行时常量池中创建的新String对象;
String s1 = "abc";
String s2 = "abc";
执行上述代码时,在运行时常量池中只会创建一个String对象"abc",这样就节省了内存空间。
- 2、同步
因为String对象是不可变的,所以是多线程安全的,同一个String实例可以被多个线程共享。这样就不用因为线程安全问题而使用同步;
- 3、允许String对象缓存hashcode
查看上文JDK1.8中String类源码,可以发现其中有一个字段hash,String类的不可变性保证了hashcode的唯一性,所以可以用hash字段对String对象的hashcode进行缓存,就不需要每次重新计算hashcode。所以Java中String对象经常被用来作为HashMap等容器的键。
- 4、安全性
如果String对象是可变的,那么会引起很严重的安全问题。比如,数据库的用户名、密码都是以字符串的形式传入来获得数据库的连接,或者在socket编程中,主机名和端口都是以字符串的形式传入。因为String对象是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变String引用指向的对象的值,造成安全漏洞。
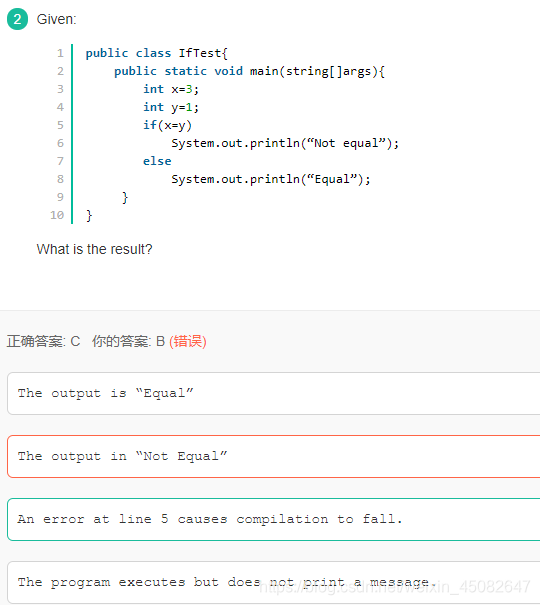
1、Java中,赋值是有返回值的 ,赋什么值,就返回什么值。比如这题,x=y,返回y的值,所以括号里的值是1。
2、Java跟C的区别,C中赋值后会与0进行比较,如果大于0,就认为是true;而Java不会与0比较,而是直接把赋值后的结果放入括号;
3、以下描述错误的一项是(C)?
A、程序计数器是一个比较小的内存区域,用于指示当前线程所执行的字节码执行到了第几行,是线程隔离的;
B、原则上讲,所有的对象都是在堆区上分配内存,是线程之间共享的;
C、方法区用于存储JVM加载的类信息、常量、静态变量,即使编译器编译后的代码等数据,是线程隔离的;
D、Java方法执行内存模型,用于存储局部变量,操作数栈,动态链接,方法出口等信息,是线程隔离的;
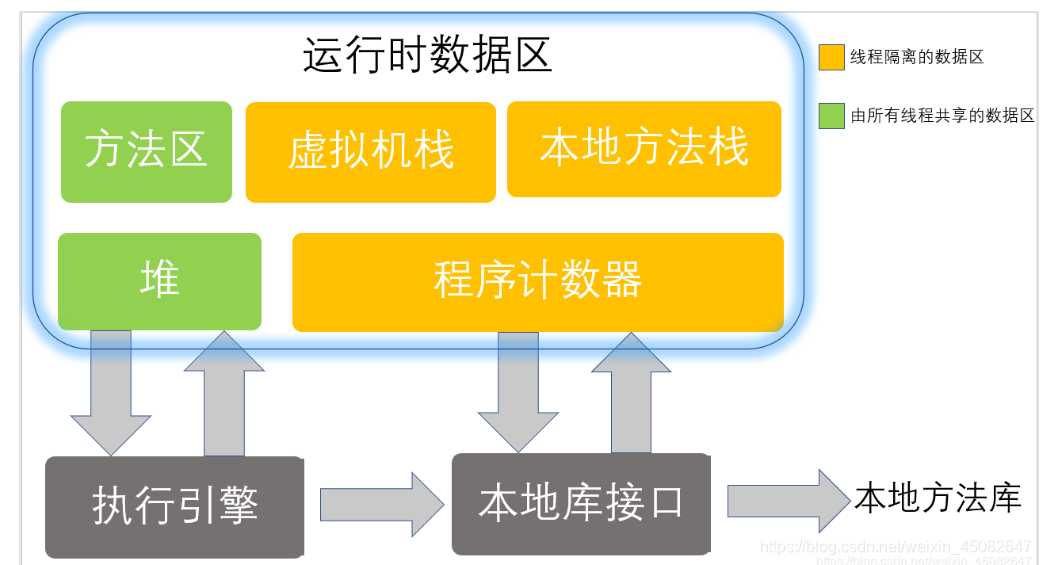
【总结】:
-
JAVA的JVM的内存主要可分为3个区:堆(heap)、栈(stack)和方法区(method)和栈区,每个线程包含一个栈区,栈中只保存方法中(不包括对象的成员变量)的基础数据类型和自定义对象的引用(不是对象),对象都存放在堆区中,每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问;
-
栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令);
-
堆区:存储的全部是对象实例,每个对象都包含一个与之对应的class的信息(class信息存放在方法区)。JVM只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身,几乎所有的对象实例和数组都在堆中分配。
-
方法区:又叫静态区,跟堆一样,被所有的线程共享。它用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
4、下面有关JAVA异常类的描述,说法错误的是?(D)
A、异常的继承结构:基类为Throwable,Error和Exception继承Throwable,RuntimeException和IOException等继承Exception;
B、非RuntimeException一般是外部错误(非Error),其必须被 try{}catch语句块所捕获;
C、Error类体系描述了Java运行系统中的内部错误以及资源耗尽的情形,Error不需要捕捉;
D、RuntimeException体系包括错误的类型转换、数组越界访问和试图访问空指针等等,必须被 try{}catch语句块所捕获;
【总结】:
- 异常是指程序运行时(非编译)所发生的非正常情况或错误,当程序违反了语音规则,jvm就会将出现的错误表示一个异常抛出;
- 异常也是java 的对象,定义了基类 java、lang、throwable作为异常父类。 这些异常类又包括error和exception。
- 两大类error类异常主要是运行时逻辑错误导致,一个正确程序中是不应该出现error的。当出现error一般JVM会终止。
- exception表示可恢复异常,包括编译期异常和运行时异常。
- 编译期异常是最常见异常比如 io异常sql异常,都发生在编译阶段,这类通过try、catch捕捉;
- 而运行时异常,编译器没有强制对其进行捕捉和处理,常见的运行异常包括:空指针异常、类型转换异常、数组越界异常、数组存储异常、缓冲区溢出异常、算术异常等;

- final:
可以修饰类,成员变量,成员方法:
修饰类,类不能被重写;
修饰成员变量,变量是常量;
修饰成员方法,方法不能被改写
-
finally:是异常处理的一部分,用于释放资源,其中代码一定会被执行。特殊情况,在执行到finally之前JVM退出了,则不能被执行(比如在finally块之前遇到
System.exit(0);语句)。 -
finalize:是Object的一个方法,用于垃圾回收;
6、Java7特性中,abstract class 和 interface 有什么区别。
【总结:】
1、抽象类可以有构造,只不过不能new。
2、接口中可以有变量,但是无论你怎么写,最后都是public static final的。
3、抽象类中可以有静态方法,接口中也可以有。
扩展:
1、接口中可以有非抽象的方法,比如default方法(Java 1.8)
2、接口中可以有带方法体的方法。(Java 1.8)
3、接口中的方法默认是public的。
算法题——打家劫舍



首先明确:
- 相邻的节点不能偷,也就是选择爷爷偷,儿子就不能偷了,但是孙子可以偷;
- 二叉树只有左右两个孩子,一个爷爷最多 2 个儿子,4 个孙子
- 根据以上条件,可以得出单个节点的钱该怎么算:
偷 4 个孙子的钱 + 爷爷的钱 VS 偷 2 个儿子的钱哪个组合钱多,就当做当前节点能偷的最大钱数。这就是动态规划里面的最优子结构;
public int rob(TreeNode root) {
if (root == null) return 0;
//爷爷的钱
int money = root.val;
if (root.left != null) {
//爷爷的左子树的孩子的钱
money += (rob(root.left.left) + rob(root.left.right));
}
if (root.right != null) {
//爷爷的右子树的孩子的钱
money += (rob(root.right.left) + rob(root.right.right));
}
//比较爷爷的钱 + 孙子的钱 与 两个儿子的钱
return Math.max(money, rob(root.left) + rob(root.right));
}
- 最后展示一下别人的优秀解法:终极解法
上面两种解法用到了孙子节点,计算爷爷节点能偷的钱还要同时去计算孙子节点投的钱,虽然有了记忆化,但是还是有性能损耗;我们换一种办法来定义此问题
每个节点可选择偷或者不偷两种状态,根据题目意思,相连节点不能一起偷,当前节点选择偷时,那么两个孩子节点就不能选择偷了;当前节点选择不偷时,两个孩子节点只需要拿最多的钱出来就行(两个孩子节点偷不偷没关系);
我们使用一个大小为 2 的数组来表示 int[] res = new int[2],0 代表不偷,1 代表偷,任何一个节点能偷到的最大钱的状态可以定义为:
当前节点选择不偷:
当前节点能偷到的最大钱数 = 左孩子能偷到的钱 + 右孩子能偷到的钱
root[0] = Math.max(rob(root.left)[0], rob(root.left)[1]) + Math.max(rob(root.right)[0], rob(root.right)[1])
当前节点选择偷:
当前节点能偷到的最大钱数 = 左孩子选择自己不偷时能得到的钱 + 右孩子选择不偷时能得到的钱 + 当前节点的钱数
root[1] = rob(root.left)[0] + rob(root.right)[0] + root.val;
代码:
public int rob(TreeNode root) {
int[] result = robInternal(root);
return Math.max(result[0], result[1]);
}
public int[] robInternal(TreeNode root) {
if (root == null)
return new int[2];
int[] result = new int[2];
int[] left = robInternal(root.left);
int[] right = robInternal(root.right);
result[0] = Math.max(left[0], left[1]) + Math.max(right[0], right[1]);
result[1] = left[0] + right[0] + root.val;
return result;
}














 1242
1242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









