









DataWhale Task01:LLama3模型讲解
附上原link:https://github.com/datawhalechina/tiny-universe/tree/main/content/Qwen-blog
视频地址:https://meeting.tencent.com/user-center/shared-record-info?id=0be29bb2-0648-4aeb-9baa-c9dc91dfc7a6&is-single=false&record_type=2&from=3
区别:tiny-llama3重点在于一个完整的模型训练体验,而qwen-blog偏重当前decoder架构下llm各个模块的讲解
Qwen(千问)模型架构:
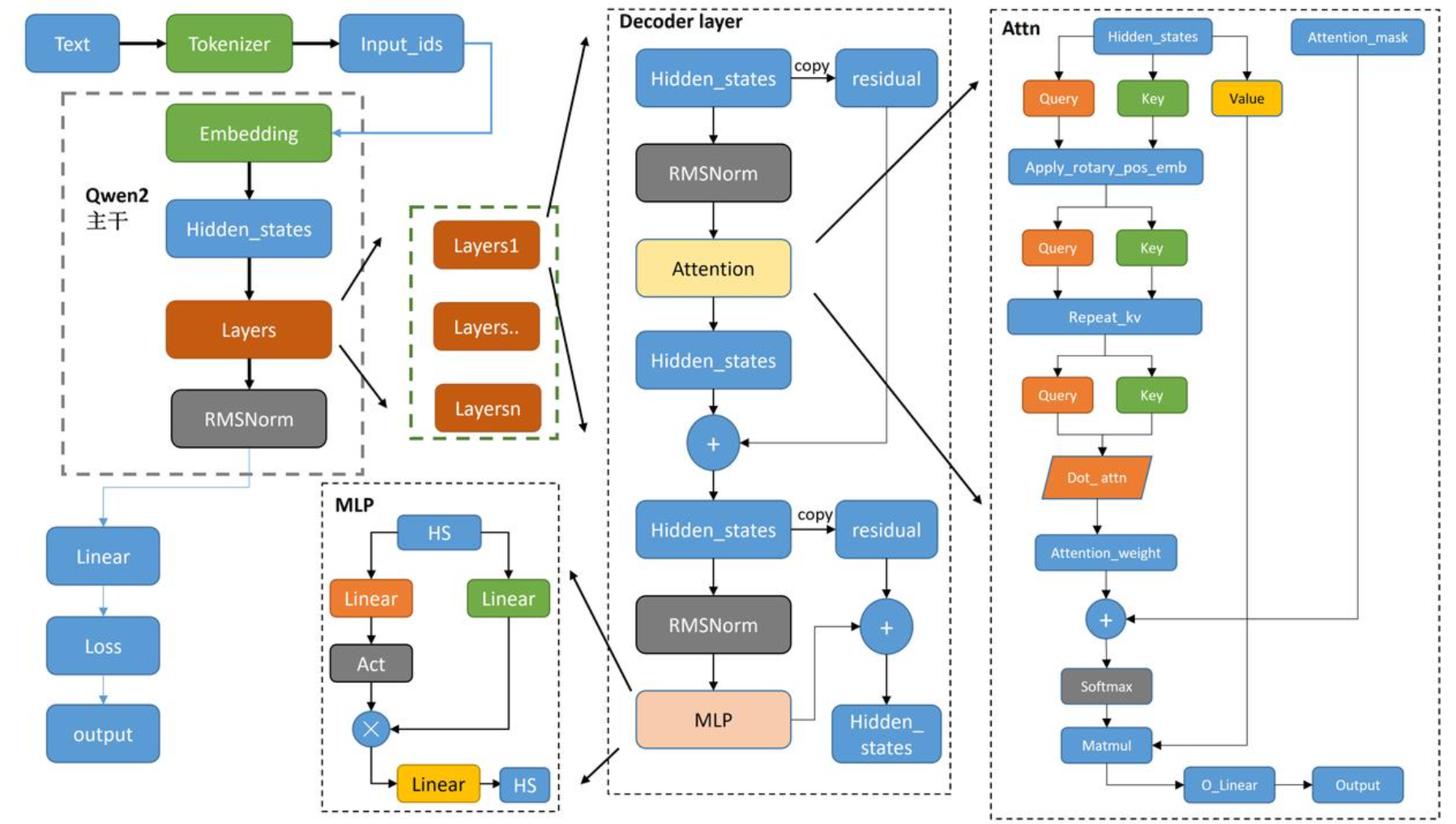
Qwen整体介绍:
一开始就是我们输入的自然文本。我们输入了自然文本,然后经过这个Tokenizer变成了一些索引
input_ids。如果说我的词表可能是1到10000,它就是把我的子词变成了1、1000或者是997这样子的一堆的这个
索引数字。在索引数字通过Embedding把它变成对于每一个数字都有高维的解释。变成一个hidden
states的解释变成了初始化的size。
然后hiedden_states经过decoder,它会分成了不同的layers。在每一个layers层里面,它会有一系列的操作。看着也很简单,就是把hidden_states copy一份 copy一份参差的,然后经过这个正则化(RMSNorm),经过这个自注意力模块(Attention),然后得到这个输出的hidden_states,然后再跟这个残差(residual)进行相加。再进行一个参差、复制。再进行一个正则化,然后再送入我们这个MLP多层感知机,然后最后再进行一个参差相加,最后得到输出。
每一层都是这个样子,那么就是循环这些层数。循环出来之后,经过一个RMSNorm,经过一个正则化。然后最终输出我们下游的任务层(Linear、Loss、output)。
Qwen2Config中包含一些自定义的超参数,例如
vocab_size 词表是多少
hidden_size 隐藏层是多少维度
intermediate_size 中间隐藏层是多少维度
``num_hidden_layers layer三件套:attn+MLP+`norm
num_attention_heads 多头注意力
max_position_embedding 有多少个最大位置嵌入信息
类似于dict可以调用里面的超参数:config.pad_token_id
input_ids是什么
其实也就是toencode进行了引l的东西,其实它就是一个子词的检索。如果我有一段自然文本,然后去经过子词嵌入的话,它会生成这个词标里边的这个索引就是这个索引是1万5000多,那可能就会里面是一个1或者是1000,就是从0到15000多中间的这个整数代表的是每一个子词的索引。
首先是通过随机整数,然后。在子词里面。零到子词表的最大数里面。去采集一个4到30,其实就是给他人工制造
了一个random的输入。把这个input_ids喂到我们已经赋值过相关参数的纤维模型里面。然后最后得到我们输出
Qwen2DeconderLayer
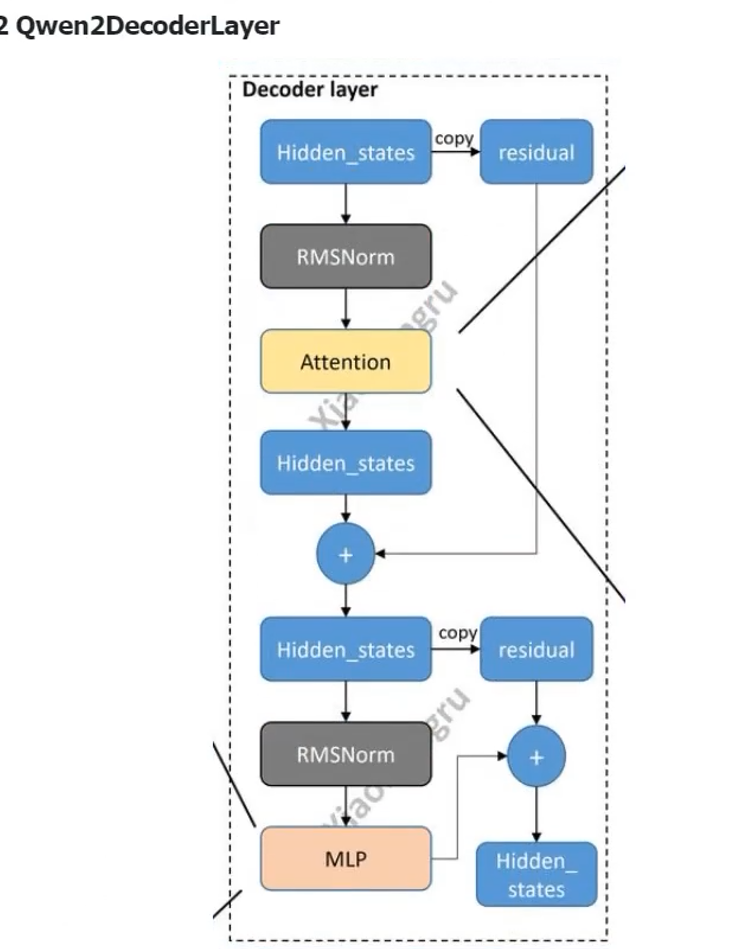
Decoder layer
首先从hidden_states然后residual copy一个residual是参差,在后面,我们就把hidden_states进行一个RMSNorm。然后到了我们这个self attention这个层面。在这个attention里面,它就是一个很平平无奇的multi head self attention。
Qwen2Attention
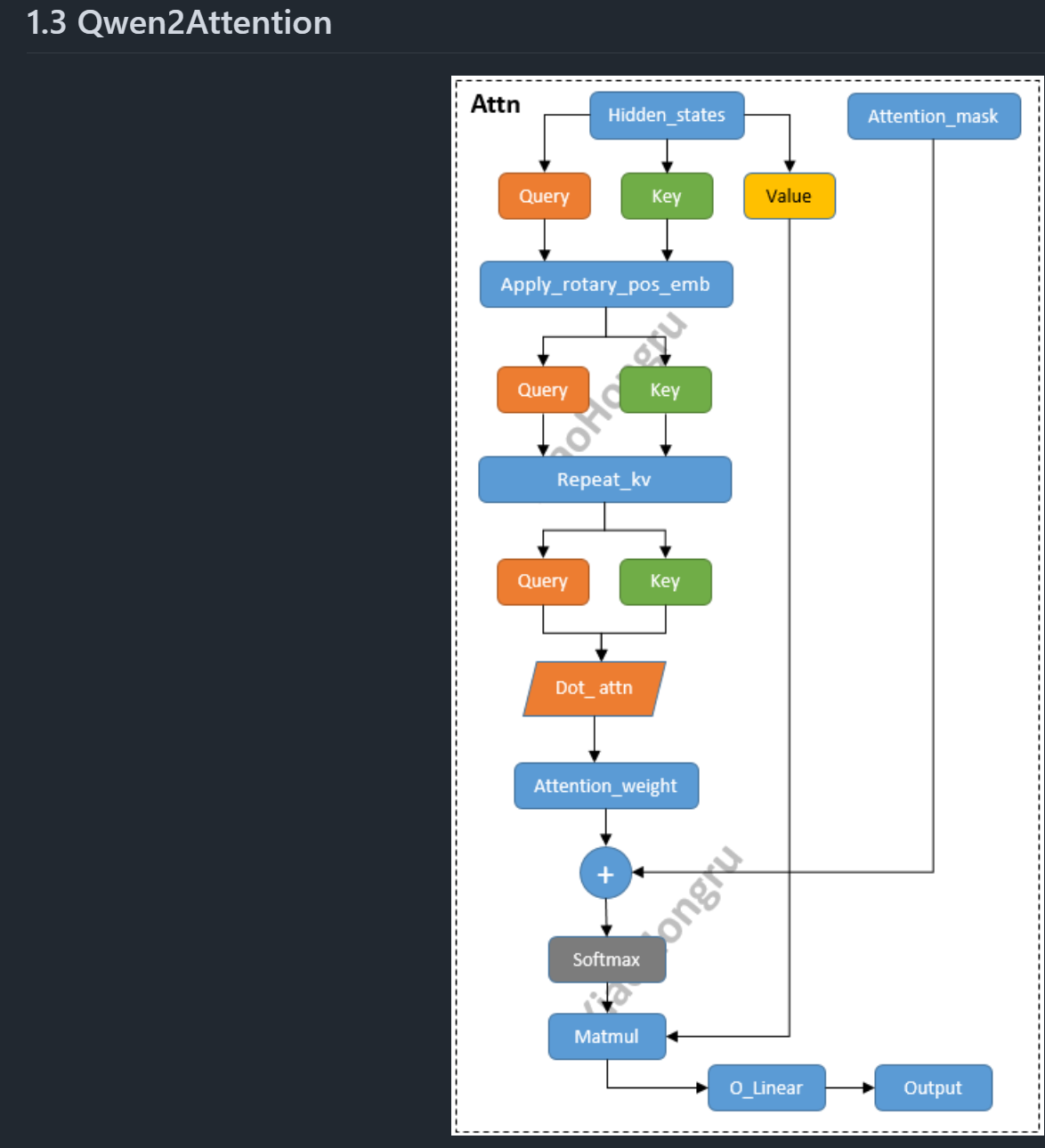

它就是一份的话,先复制三份,那一份。Ok那么我先进入三个线性层,然后得到了查询,包括这个键,包括这个值。然后得到三份。进行转置操作,让它能够让他能够把这个形状确认到了是一个后续可以运行的这个进行
矩阵乘法的这样一个张量的形式。

reshape进行多头处理。也都是工程的代码。
这是past_key_value,这是召回的一个机制。
GQA的操作:

repeatKV是GQA的实现操作,但是在这个地方不设置GQA的,因为现在n_kv_heads与n_heads参数是相等的。其实在llama2、千问,它在小数据的模型,比如说7b或者是1.5B这样的模型,它都一般都是不会使用GQA的。然后llama3的时候,他才是把小模型也使用了GKV的操作。传统的话,之前的话一般都是大模型70B或者是更大的模型一般才会上GQA。
- 定义初始张量
- 之后进行扩展key,value的操作
在GQA中,key和value都要比query小group倍,但是为在后续做矩阵乘法时方便,我们需要先把key和value的head利用expand扩展张量到和query相同的维度。方便后续计算。 - 矩阵乘法得到
score与output后面就是征程的kqv相乘了
hidden_states:归一化 不改变:
为什么要用expand之后再reshape而不能直接用tensor自带的repeat?
expand方法用于对张量进行扩展,但不实际分配新的内存。它返回的张量与原始张量共享相同的数据repeat方法通过实际复制数据来扩展张量。它返回的新张量不与原始张量共享数据,扩展后的张量占用了更多的内存。
Qwen2RMSNorm

- x是层的输入的
hidden_state - wi 表示的是
hidden_state的最后一个维度的值 - n 表示上面输入的最后一个维度的数量。
- ϵ 表示是很小的数,防止除0。
MLP
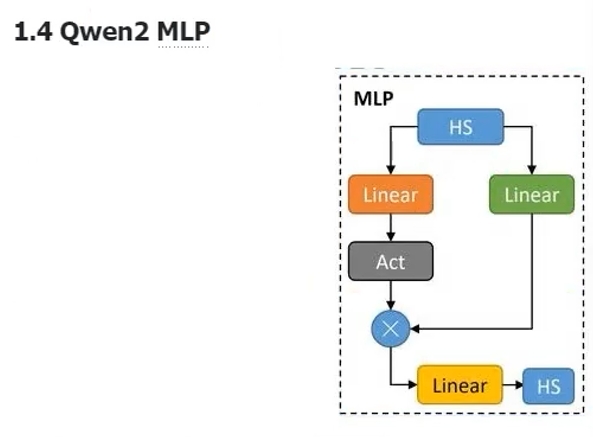

我们现在是HS(hidden_states),我传进去的就是X。先进行一个Linear,然后再进行一个变形的Linear,进入两个linear,
(up_proj,gate_proj),然后我们再进行一个激活函数(act_fn),然后这两个再点乘,然后再进行一个linear
变换成之后的操作。然后那么输出我们可以看一下这个X的形状;

它的维数都是不会变的,models里面它一般是不会改变形状的张量的形状一般是不会改变的。
最后再把output进行一个原子的存储。
至此Deconder linear就出来了。
Linear和Linear之间它其实还有一个还有操作是:把模型的最后一层输出的hidden_states当做目前的
Linear,然后再扔进下一个循环去训练,因为是串行,把上一个的输出当做下一个的输入。
- 设置了模型的两个属性:
padding_idx(用于指定填充标记的索引),vocab_size(词汇表的大小) - 初始化了模型的嵌入层、解码器层、归一化层
- 嵌入层(
nn.Embedding):模型使用嵌入层将输入的标记映射成密集的向量表示。 - 解码器层(
nn.ModuleList()):模型包含多个解码器层,这些层都是由 `Qwen2DecoderLayer`` 定义 - 归一化层
Qwen2RMSNorm:归一化层使用的是 Root Mean Square Layer Normalization - 设置了是否使用
gradient_checkpoint主要是用来节省显存 - 调用
post_init()完成一些初始化和准备检查的代码
















 7436
7436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











