










DataWhale Task03:手搓一个Agent
-
教程地址:tiny-universe/content/TinyAgent at main · datawhalechina/tiny-universe (github.com)
-
代码就在 tinyAgent 文件夹里面
-
注册并申请 Google API Key:Serper - Dashboard
-
使用Google搜索功能的话需要去
serper官网申请一下token: https://serper.dev/dashboard, 然后在tools.py文件中填写你的key,这个key每人可以免费申请一个,且有2500次的免费调用额度,足够做实验用啦~

实现细节
Step 1: 构造大模型
Step 2: 构造工具
Step 3: 构造Agent
Step 4: 运行Agent
Step 1: 构造大模型
还是先创建一个BaseModel类,我们可以在这个类中定义一些基本的方法,比如chat方法和load_model方法,方便以后扩展使用其他模型
class BaseModel:
def __init__(self, path: str = '') -> None:
self.path = path
def chat(self, prompt: str, history: List[dict]):
pass
def load_model(self):
pass
定义了一个名为 BaseModel 的基类,主要用于模型管理。构造函数 __init__ 接受一个可选的字符串参数 path,用于存储模型路径。chat 方法接受一个字符串 prompt 和一个历史记录列表(history),但目前没有实现具体功能。load_model 用于加载模型
class InternLM2Chat(BaseModel):
def __init__(self, path: str = '') -> None:
super().__init__(path)
self.load_model()
def load_model(self):
print('================ Loading model ================')
self.tokenizer = AutoTokenizer.from_pretrained(self.path, trust_remote_code=True)
self.model = AutoModelForCausalLM.from_pretrained(self.path, torch_dtype=torch.float16, trust_remote_code=True).cuda().eval()
print('================ Model loaded ================')
def chat(self, prompt: str, history: List[dict], meta_instruction:str ='') -> str:
response, history = self.model.chat(self.tokenizer, prompt, history, temperature=0.1, meta_instruction=meta_instruction)
return response, history
这段代码定义了 InternLM2Chat 类,继承自 BaseModel。在 __init__ 方法中,调用父类构造函数并执行 load_model 方法以加载模型。load_model 方法打印加载信息,并使用 AutoTokenizer 和 AutoModelForCausalLM 从指定路径加载模型和分词器,设置为 CUDA 设备并切换到评估模式。
chat 方法接收一个提示 prompt、历史记录 history 和可选的元指令 meta_instruction,调用模型的 chat 方法生成响应,并返回生成的文本和更新的历史记录。
Step 2: 构造工具
tools.py文件中,构造一些工具
class Tools:
def __init__(self) -> None:
self.toolConfig = self._tools()
def _tools(self):
tools = [
{
'name_for_human': '谷歌搜索',
'name_for_model': 'google_search',
'description_for_model': '谷歌搜索是一个通用搜索引擎,可用于访问互联网、查询百科知识、了解时事新闻等。',
'parameters': [
{
'name': 'search_query',
'description': '搜索关键词或短语',
'required': True,
'schema': {'type': 'string'},
}
],
}
]
return tools
def google_search(self, search_query: str):
pass
这段代码定义了 Tools 类,用于配置和管理工具。构造函数 __init__ 初始化 toolConfig,调用私有方法 _tools 来获取工具配置。_tools 方法返回一个包含工具信息的字典列表,当前配置包括一个名为 “谷歌搜索” 的工具,其描述、参数及其要求也一并列出。
google_search 方法接受一个字符串类型的 search_query 参数,用于执行实际的搜索操作。
Step 3: 构造Agent
在Agent.py文件中,构造一个Agent类,这个Agent是一个React范式的Agent,我们在这个Agent类中,实现了text_completion方法,这个方法是一个对话方法,我们在这个方法中,调用InternLM2模型,然后根据React的Agent的逻辑,来调用Tools中的工具。
def build_system_input(self):
tool_descs, tool_names = [], []
for tool in self.tool.toolConfig:
tool_descs.append(TOOL_DESC.format(**tool))
tool_names.append(tool['name_for_model'])
tool_descs = '\n\n'.join(tool_descs)
tool_names = ','.join(tool_names)
sys_prompt = REACT_PROMPT.format(tool_descs=tool_descs, tool_names=tool_names)
return sys_prompt
这段代码定义了 build_system_input 方法,用于构建系统输入的提示。首先,初始化 tool_descs 和 tool_names 列表。然后,遍历 self.tool.toolConfig 中的每个工具,使用 TOOL_DESC 格式化工具描述并添加到 tool_descs,同时提取工具名称并添加到 tool_names。
接着,使用换行符连接 tool_descs,并用逗号连接 tool_names。最后,利用 REACT_PROMPT 格式化字符串构建系统提示,并返回该提示。
Agent的结构是一个React的结构,提供一个system_prompt,使得大模型知道自己可以调用那些工具,并以什么样的格式输出。
Agent代码的简易实现,每个函数的具体实现可以在tinyAgent/Agent.py中查看
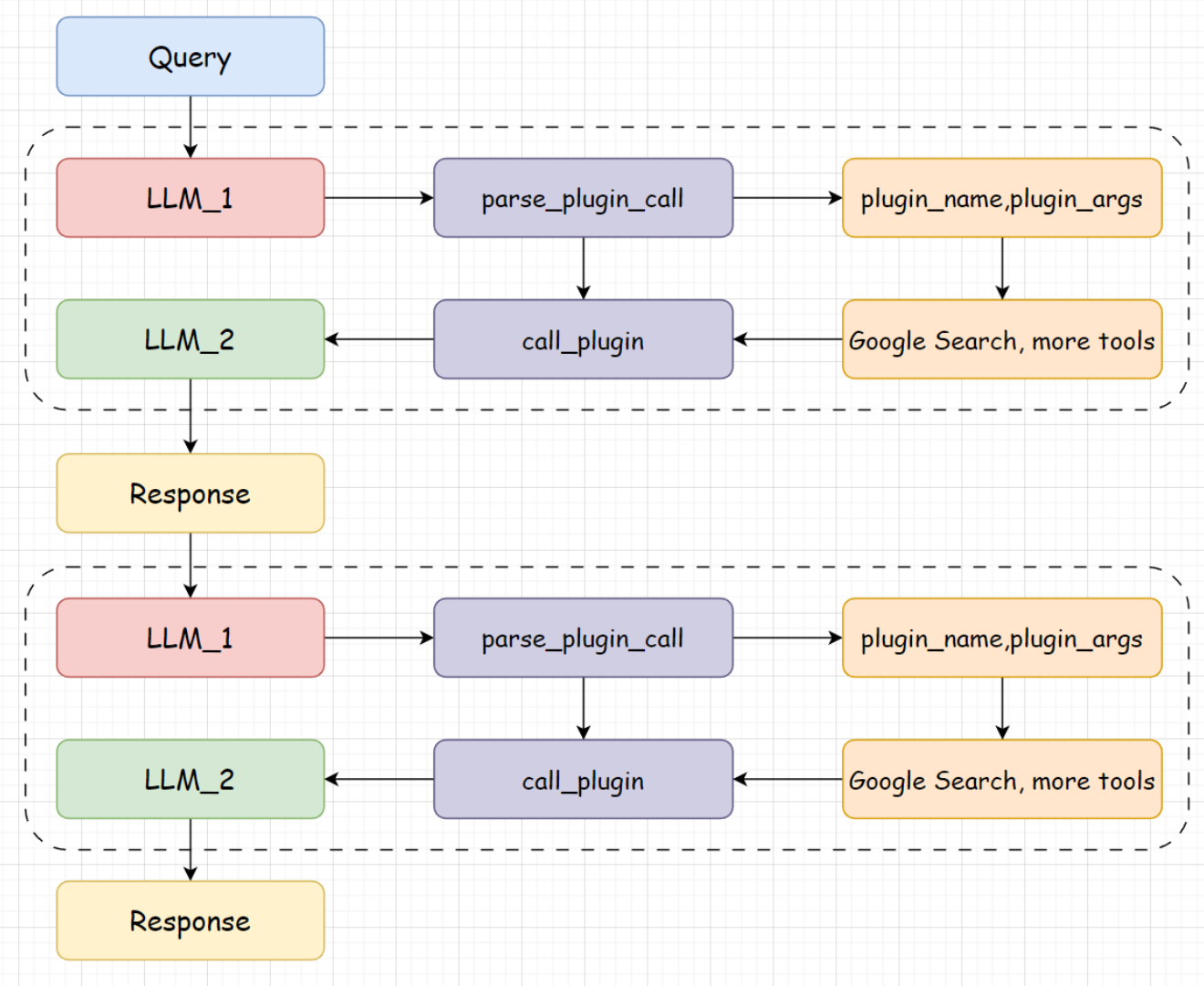
Step 4: 运行Agent
使用了InternLM2-chat-7B模型, 如果你想要Agent运行的更加稳定,可以使用它的big cup版本InternLM2-20b-chat,这样可以提高Agent的稳定性.
from Agent import Agent
agent = Agent('/root/share/model_repos/internlm2-chat-20b')
response, _ = agent.text_completion(text='你好', history=[])
print(response)
# Thought: 你好,请问有什么我可以帮助你的吗?
# Action: google_search
# Action Input: {'search_query': '你好'}
# Observation:Many translated example sentences containing "你好" – English-Chinese dictionary and search engine for English translations.
# Final Answer: 你好,请问有什么我可以帮助你的吗?
response, _ = agent.text_completion(text='周杰伦是哪一年出生的?', history=_)
print(response)
# Final Answer: 周杰伦的出生年份是1979年。
response, _ = agent.text_completion(text='周杰伦是谁?', history=_)
print(response)
# Thought: 根据我的搜索结果,周杰伦是一位台湾的创作男歌手、钢琴家和词曲作家。他的首张专辑《杰倫》于2000年推出,他的音乐遍及亚太区和西方国家。
# Final Answer: 周杰伦是一位台湾创作男歌手、钢琴家、词曲作家和唱片制作人。他于2000年推出了首张专辑《杰伦》,他的音乐遍布亚太地区和西方国家。他的音乐风格独特,融合了流行、摇滚、嘻哈、电子等多种元素,深受全球粉丝喜爱。他的代表作品包括《稻香》、《青花瓷》、《听妈妈的话》等。
response, _ = agent.text_completion(text='他的第一张专辑是什么?', history=_)
print(response)
# Final Answer: 周杰伦的第一张专辑是《Jay》。
展示了如何使用 Agent 类进行一系列的文本生成任务。
-
初始化 Agent: 创建
Agent的实例,指定模型路径。 -
文本完成调用:
- 第一次调用
text_completion方法,输入文本 “你好”,并传入空的历史记录。模型处理后返回响应。 - 输出的格式包括思考过程、执行的动作(如
google_search)、输入参数和最终答案。
- 第一次调用
-
连续调用:
- 第二次调用传入 “周杰伦是哪一年出生的?”,并使用上一次调用的历史记录。
- 第三次和第四次调用依次传入 “周杰伦是谁?” 和 “他的第一张专辑是什么?”,每次都传入更新后的历史记录。
-
响应结构: 每次响应都包含思考内容和最终答案,这表明模型可能在根据先前的结果调整其输出。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











