




🌈 个人主页:(时光煮雨)
🔥 高质量专栏:vulnhub靶机渗透测试
👈 希望得到您的订阅和支持~
💡 创作高质量博文(平均质量分95+),分享更多关于网络安全、Python领域的优质内容!(希望得到您的关注~)
前言
Scrapy 是一个功能强大的 Python 爬虫框架,专门用于抓取网页数据并提取信息。
Scrapy常被用于数据挖掘、信息处理或存储历史数据等应用。
Scrapy 内置了许多有用的功能,如处理请求、跟踪状态、处理错误、处理请求频率限制等,非常适合进行高效、分布式的网页爬取。
与简单的爬虫库(如 requests 和 BeautifulSoup)不同,Scrapy 是一个全功能的爬虫框架,具有高度的可扩展性和灵活性,适用于复杂和大规模的网页抓取任务。
Scrapy 官网:https://scrapy.org/。
Scrapy 特点与介绍:https://www.runoob.com/w3cnote/scrapy-detail.html。
Scrapy 架构图(绿线是数据流向):
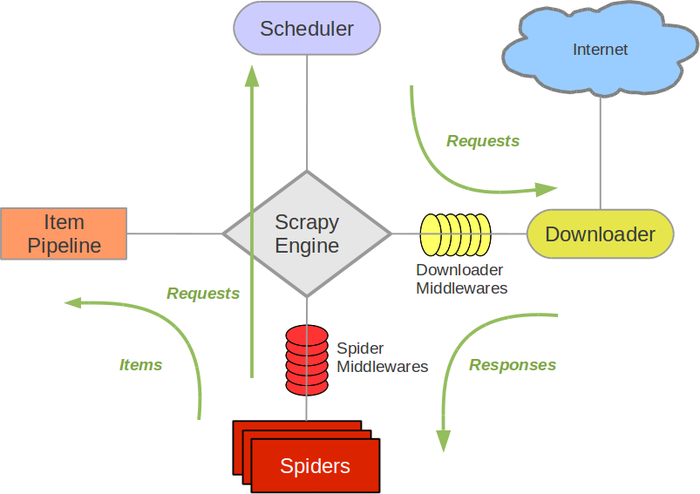
Scrapy 的工作基于以下几个核心组件:
- Spider:爬虫类,用于定义如何从网页中提取数据以及如何跟踪网页的链接。
- Item:用来定义和存储抓取的数据。相当于数据模型。
- Pipeline:用于处理抓取到的数据,常用于清洗、存储数据等操作。
- Middleware:用来处理请求和响应,可以用于设置代理、处理 cookies、用户代理等。
- Settings:用来配置 Scrapy 项目的各项设置,如请求延迟、并发请求数等。
🥛一、Scrapy 项目结构
在使用 Scrapy 之前,你需要先安装它,我们使用 pip 安装:
pip install scrapy
Scrapy 项目是一个结构化的目录,其中包含多个文件夹和模块,旨在帮助你组织爬虫的代码。
Scrapy 使用命令行工具来创建和管理爬虫项目。你可以使用以下命令创建一个新的 Scrapy 项目:
scrapy startproject test_scrapy_project_001
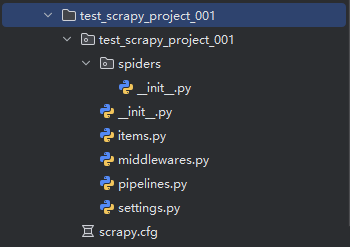
这将创建一个名为 test_scrapy_project_001 的项目,项目结构大致如下:
test_scrapy_project_001/
scrapy.cfg # 项目的配置文件
test_scrapy_project_001/ # 项目源代码文件夹
__init__.py
items.py # 定义抓取的数据结构
middlewares.py # 定义中间件
pipelines.py # 定义数据处理管道
settings.py # 项目的设置文件
spiders/ # 存放爬虫代码的文件夹
__init__.py
myspider.py # 自定义的爬虫代码
如图所示:
☕二、编写一个简单的 Scrapy 爬虫
以下是一个基本的 Scrapy 爬虫示例,展示了如何从网页中抓取数据。
🍼2.1.创建爬虫项目
我们创建一个爬虫项目:
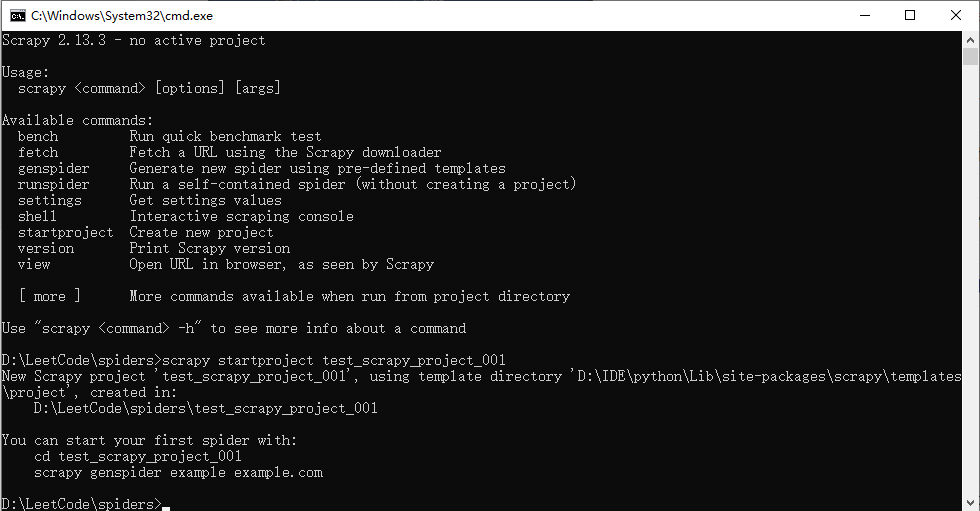
scrapy startproject test_scrapy_project_001
执行以上命令,如果成功会输出:
Scrapy 2.13.3 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
D:\LeetCode\spiders>scrapy startproject test_scrapy_project_001
New Scrapy project 'test_scrapy_project_001', using template directory 'D:\IDE\python\Lib\site-packages\scrapy\templates\project', created in:
D:\LeetCode\spiders\test_scrapy_project_001
You can start your first spider with:
cd test_scrapy_project_001
scrapy genspider example example.com
生成的项目结构如下:
然后进入该目录:
cd test_scrapy_project_001
接下来通过 scrapy genspider 命令来创建一个爬虫:
scrapy genspider douban_spider movie.douban.com
执行完命令后,会新创建一个"douban_spider.py"的文件,目录结构如下:
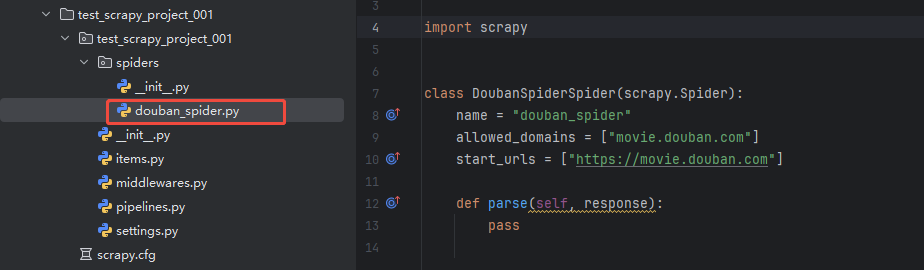
douban_spider.py文件的默认代码:
import scrapy
class DoubanSpiderSpider(scrapy.Spider):
name = "douban_spider"
allowed_domains = ["movie.douban.com"]
start_urls = ["https://movie.douban.com"]
def parse(self, response):
pass
代码说明:
- name:定义爬虫的名称,必须是唯一的。
- allowed_domains:限制爬虫的访问域名,防止爬虫爬取其他域名的网页。
- start_urls:定义爬虫的起始页面,爬虫将从这些页面开始抓取。
- parse:parse 方法是每个爬虫的核心部分,用于处理响应并提取数据。它接收一个 response 对象,表示服务器返回的页面内容。
🍼2.2.编写爬虫代码
🍵2.2.1.注意事项
编写爬虫代码前我们需要注意几个点:
- 豆瓣等网站可能会检测爬虫行为,建议设置 USER_AGENT 和 DOWNLOAD_DELAY 来模拟正常用户行为。
- 在爬取数据时,请遵守目标网站的 robots.txt 文件规定,避免对服务器造成过大压力。
- 如果频繁爬取,可能会触发 IP 封禁。
🍵2.2.2.修改 settings.py 配置
在 settings.py 中添加以下配置,以模拟浏览器请求并绕过反爬虫机制:
# 设置 User-Agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
# 不遵守 robots.txt 规则
ROBOTSTXT_OBEY = False
# 设置下载延迟,避免过快请求
DOWNLOAD_DELAY = 2
# 启用自动限速扩展
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 2
AUTOTHROTTLE_MAX_DELAY = 5
在爬虫代码中,添加自定义请求头(如 User-Agent 和 Referer),以进一步模拟
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











